Docker背后:使用Linux Namespaces隔离系统的原理
通过使用诸如Docker, Linux Containers这样的工具,将Linux进程隔离到独立的系统环境中已经成为一件非常容易的事情。由于不需要使用传统的虚拟机,Docker使得大量不同的应用能够运行在一个单独的linux物理机器上,并且任何两个应用之间不会互相干扰。对于PaaS运营商来说,像Docker这样的技术是巨大的福音。但是这些神奇技术究竟是怎样实现的呢?
这些容器工具主要依赖于Linux内核中的组件和特性。有一些特性是最近才引入的,另外一些还要求你自己向Linux内核中打patch。幸运的是,使用Linux namepaces的特性已经在2008年随内核的2.6.24版本发布了。
如果你熟悉chroot的话,你应该对于Linux命名空间能做什么以及怎么使用已经有了一个大致的概念。就像chroot允许进程将任意指定的目录作为系统的根目录(对于其他的进程不可见)一样,Linux命名空间允许进程修改操作系统的其他资源并且对于未在同一命名空间的进程不可见。这些资源包括进程树(process tree)、网络接口(network interfaces)、挂载点(mount points),进程间通信(inter-process communication)等。
为什么要使用命名空间实现进程隔离?
对于单机来说,单个系统环境不会出现任何问题。但是,对于服务器来说,由于同时运行了很多服务,就必须尽可能地隔离这些服务,从而保证这些服务之间的安全和稳定。想象一下,当一台运行了大量服务的服务器被入侵了,入侵者可能从一个服务进入,并进一步侵入其他服务,甚至损坏整台服务器。命名空间可以提供一种安全的环境,从而杜绝这种风险。
通过使用命名空间,你甚至可以在服务器上安全地运行任何未知来源的程序。比如像HackerRank, TopCoder, Codeforces这类在线编程竞赛的网站,他们需要运行和验证竞赛者提交的程序,但在大多数情况下,这些网站并不能提前判断竞赛者所提交代码的真正用意(可能包含病毒)。通过namespace将这些程序隔离在单独的系统环境中,单个程序可以被测试和验证并且不影响整个系统。类似地,在线持续集成服务(比如Drone.io)从你的代码库中自动抽取代码并在其服务器上执行测试脚本,这时,命名空间可以保证这些服务安全的运行。
Docker这类基于命名空间的工具同样可以使PaaS运营商更加高效的利用系统资源。Heroku和Google App Engine通过该类工具实现了不同web server应用在同一机器上的隔绝,他们能够保证每一个应用(由大量不同的用户部署)正常运行,并且不会互相影响、冲突,不用担心某一个应用过度占用系统资源。由于有了进程隔离,我们甚至可以实现在隔离的系统环境中运行不同的软件栈。
如果你之前用过Docker这类工具,你应该已经知道这些工具可以将进程隔离在不同的“容器”中。在Docker容器中运行进程就像在虚拟机中运行这些进程一样,只不过这些容器比虚拟机要轻量的多。虚拟机通常是在宿主机上模拟硬件层,并在模拟的硬件层上运行其他的操作系统,这种方式太重了。Docker容器不一样,通过使用宿主操作系统的一些特性(包括命名空间)便可以实现与虚拟机相似的隔离效果。
进程命名空间(PID Namespace)
起初,LInux kernel只是维护一个单独的进程树(process tree)。这棵树包含了当前运行的所有进程的引用。对于某一个进程来说,如果拥有足够权限并满足相应的条件便能够侦听另外一个进程甚至杀死该进程。
随着Linux命名空间的引入,系统中可以同时存在多个嵌套的进程树,每个进程树能够包含完全隔绝的一组进程。隶属于某个进程树中的进程不能侦听或杀死其他进程树中的进程。事实上,一个进程树中的进程甚至无法知道其他兄弟进程树或者父进程树中的进程的存在。
当Linux启动时,只会运行一个进程ID(PID)为1的进程。这个进程是进程树的根节点,并会负责系统的初始化,比如进行适当的维护工作、开启正确的服务或后台程序。在进程树中,所有的其他进程会在该进程之下启动。通过使用PID命名空间,进程可以生成一个新的进程树(新的PID命名空间),该进程树拥有自己的PID为1的进程。创建该进程树的进程仍然存在于父命名空间中的原进程树中,由他创建的子进程成为了新PID命名空间中进程树的根节点。
通过PID命名空间隔绝,子命名空间中的进程无法知道父命名空间中进程的存在。但是,父命名空间中的进程能够看到子命名空间中的进程,就像这些进程是父命名空间中的普通进程一样。因此,子命名空间中的进程除了在当前命名空间中的PID(从1开始)外,还有一个在父命名空间中的PID。
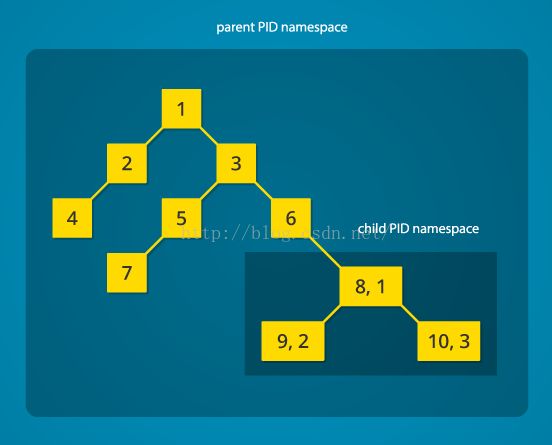
进一步的,可以创建一串嵌套的子命名空间:一个进程创建一个在子命名空间中的子进程,子进程继续在孙命名空间中创建孙进程,等等。
随着PID命名空间的引入,单个进程可以拥有多个PID(当前命名空间中的PID,父空间中的PID,依次类推)。在Linux源码中,可以看到struct pid,该结构体之前用来记录唯一的pid,目前新的版本中,该结构体已经可以记录多个pid了。
struct upid {
int nr; // the PID value
struct pid_namespace *ns; // namespace where this PID is relevant
// ...
};
struct pid {
// ...
int level; // number of upids
struct upid numbers[0]; // array of upids
};#define _GNU_SOURCE
#include
#include
#include
#include
#include
static char child_stack[1048576];
static int child_fn() {
printf("PID: %ld\n", (long)getpid());
return 0;
}
int main() {
pid_t child_pid = clone(child_fn, child_stack+1048576, CLONE_NEWPID | SIGCHLD, NULL);
printf("clone() = %ld\n", (long)child_pid);
waitpid(child_pid, NULL, 0);
return 0;
} clone() = 5304
PID: 1虽然上面这段程序很短,但是这后面发生了很多事情。clone()函数通过克隆当前的进程来创建了一个新的进程,并且在child_fn()处启动。同时,它为新进程创建了一个新的进程树。
为了证明新进程已被隔离,我们将static int child_fn()函数中的内容按如下修改:
static int child_fn() {
printf("Parent PID: %ld\n", (long)getppid());
return 0;
}clone() = 11449
Parent PID: 0可以看到,在新进程中打印出的父进程PID为0。这说明新进程认为自己没有父进程,证明新进程已经与父进程隔离了。我们将CLONE_NEWPID参数从clone()函数调用中去处,再运行一次该程序:
pid_t child_pid = clone(child_fn, child_stack+1048576, SIGCHLD, NULL);这一次,输出的父进程PID不再为0:
clone() = 11561
Parent PID: 11560目前,我们只进行了第一步。这些进程依然没有与其他一些共享资源进行隔离,比如网络接口:如果上面程序生成的子进程在端口80进行监听,其他的所有的进程便不能再监听端口80了。
网络命名空间(Linux Network Namespace)
网络命名空间能够让这些进程之间看见完全不同的网络接口。甚至loopback接口在每个网络命名空间中也可以不同。
将进程隔绝在自有的网络空间中需要在调用clone()函数时传入CLONE_NEWNET参数:
#define _GNU_SOURCE
#include
#include
#include
#include
#include
static char child_stack[1048576];
static int child_fn() {
printf("New `net` Namespace:\n");
system("ip link");
printf("\n\n");
return 0;
}
int main() {
printf("Original `net` Namespace:\n");
system("ip link");
printf("\n\n");
pid_t child_pid = clone(child_fn, child_stack+1048576, CLONE_NEWPID | CLONE_NEWNET | SIGCHLD, NULL);
waitpid(child_pid, NULL, 0);
return 0;
} 输出:
Original `net` Namespace:
1: lo: mtu 65536 qdisc noqueue state UNKNOWN mode DEFAULT group default
link/loopback 00:00:00:00:00:00 brd 00:00:00:00:00:00
2: enp4s0: mtu 1500 qdisc pfifo_fast state UP mode DEFAULT group default qlen 1000
link/ether 00:24:8c:a1:ac:e7 brd ff:ff:ff:ff:ff:ff
New `net` Namespace:
1: lo: mtu 65536 qdisc noop state DOWN mode DEFAULT group default
link/loopback 00:00:00:00:00:00 brd 00:00:00:00:00:00 输出说明了什么?物理以太网设备enp4s0属于全局网络命名空间,因此“ip”工具在该命名空间中运行时能将其信息打印出来。但是,在新的网络命名空间中,该物理网络接口并不可见。此外,loopback接口在原来的网络命名空间中是active的,但是在新的子命名空间中状态是“down”。
为了使子命名空间中的网络接口可用,必须设置跨多个命名空间的“虚拟”网络接口。然后,便可能创建虚拟以太网桥,并且实现数据包在命名空间之间的转发。最终,一个“routing process”必须运行在全局命名空间中,负责从物理网卡中接收数据,并将数据通过对应的虚拟网口发送到正确的子命名空间中。由于完成了如此多的工作,Docker才变得那么受欢迎。
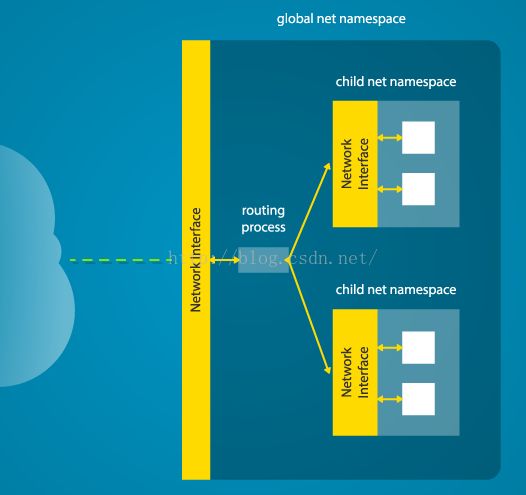
如果要手动完成上述功能,你可以在父命名空间中运行如下命令,该命令会在父子命名空间之间创建一对虚拟以太网链接。
ip link add name veth0 type veth peer name veth1 netns 这里,
挂载命名空间(Mount Namespace)
Linux也为系统的所有挂载点维护了一个数据结构。该结构包含的信息诸如:哪些磁盘分区被挂载,这些分区挂载在哪里,这些分区是否只读,等等。通过Linux命名空间,我们可以将该数据结构克隆,从而使得在不同命名空间下的进程可以独立修改挂载点信息而不影响其他进程。
创建单独的挂载空间与chroot()效果相似。但是chroot()并不能提供完全的隔离,并且其影响只能局限于root挂载点。通过生成新的挂载命名空间,隔绝的进程间会拥有对于整个系统完全不同的挂载点配置。这就可以实现隔绝的进程间拥有不同的root目录,以及不同的其他挂载点。我们甚至可以实现底层系统对于子命名空间的完全透明。
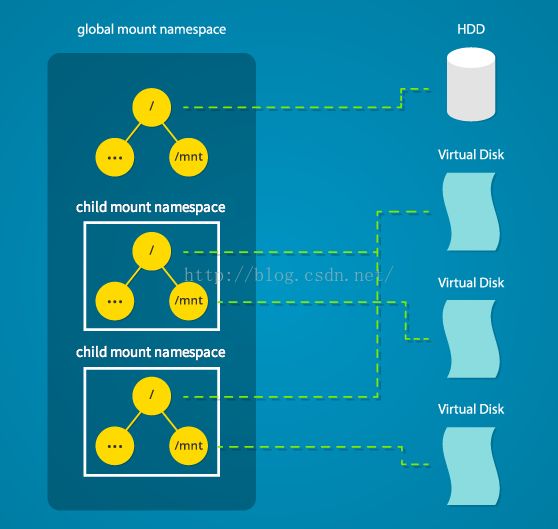
要实现上述功能,需要在clone()函数中传入CLONE_NEWNS参数:
clone(child_fn, child_stack+1048576, CLONE_NEWPID | CLONE_NEWNET | CLONE_NEWNS | SIGCHLD, NULL)但是,比起直接用CLONE_NEWNS生产目标子进程,更好的方法是先用CLONE_NEWNS生成一个“init”进程,让“init”进程改变挂载点配置,环境重新配置好后,再在“init”进程中生产目标子进程。在本文结束之前,我们还会进一步讨论此问题。
其他命名空间
还有其他可以隔绝进程的命名空间,包括user,IPC,和UTS。user命名空间允许在该空间中的进程拥有root权限。在IPC命名空间中的进程拥有进程间通信资源,比如System V IPC以及POSIX消息。在UTS命名空间隔绝了两个特殊的系统标识:nodename和domainname。
UTS空间如何隔绝的例子如下所示:
#define _GNU_SOURCE
#include
#include
#include
#include
#include
#include
static char child_stack[1048576];
static void print_nodename() {
struct utsname utsname;
uname(&utsname);
printf("%s\n", utsname.nodename);
}
static int child_fn() {
printf("New UTS namespace nodename: ");
print_nodename();
printf("Changing nodename inside new UTS namespace\n");
sethostname("GLaDOS", 6);
printf("New UTS namespace nodename: ");
print_nodename();
return 0;
}
int main() {
printf("Original UTS namespace nodename: ");
print_nodename();
pid_t child_pid = clone(child_fn, child_stack+1048576, CLONE_NEWUTS | SIGCHLD, NULL);
sleep(1);
printf("Original UTS namespace nodename: ");
print_nodename();
waitpid(child_pid, NULL, 0);
return 0;
} 输出如下:
Original UTS namespace nodename: XT
New UTS namespace nodename: XT
Changing nodename inside new UTS namespace
New UTS namespace nodename: GLaDOS
Original UTS namespace nodename: XT上面程序中,child_fn()打印nodename,然后改变nodename的设置,再打印。可以看到,父命名空间中的nodename并没有改变。
更多关于这些命名空间的信息可以参考这里。
跨命名空间通信
经常需要在父命名空间和子命名空间之间建立通信渠道,有可能是因为要在隔绝环境中进行配置工作,也有可能仅仅是想要从其他空间中参看该空间中的环境状态。一种方式是在隔绝空间中运行SSH服务。在每个网络命名空间中都可以启动单独的SSH服务。但是,同时启动多个SSH服务会耗费大量诸如内存等系统资源。这里就再次印证了使用“init”进程是一个好的方法。
“init”进程可以用来在父子命名空间之间建立通信管道。通信管道可以基于UNIX sockets或者甚至使用TCP。为了创建跨越两个不同命名空间的UNIX socket,需要首先创建子进程,然后创建UNIX socket,这之后才能将子进程隔绝到一个单独的挂载命名空间中。但是,怎样才能实现先创建进程,然后再来隔绝它呢?Linux提供了unshare()系统调用。该系统调用能够让进程自己从之前的命名空间中隔绝出来,而不是让父进程对其进行隔绝。比如,以下代码与前面章节中网络命名空间相关代码的作用相同:
#define _GNU_SOURCE
#include
#include
#include
#include
#include
static char child_stack[1048576];
static int child_fn() {
// calling unshare() from inside the init process lets you create a new namespace after a new process has been spawned
unshare(CLONE_NEWNET);
printf("New `net` Namespace:\n");
system("ip link");
printf("\n\n");
return 0;
}
int main() {
printf("Original `net` Namespace:\n");
system("ip link");
printf("\n\n");
pid_t child_pid = clone(child_fn, child_stack+1048576, CLONE_NEWPID | SIGCHLD, NULL);
waitpid(child_pid, NULL, 0);
return 0;
} 由于你已经想出了“init”进程,你可以让其先完成所有必要的工作,然后用unshare使其隔绝,之后创建目标子进程。
结论
本文是对Linux中如何使用namespace的概述。通过本文,你应该能够了解如何在Linux中实现系统隔离,这也是Docker或者LXC工具背后的原理。在大多数情况下,你只需直接使用这些现成的工具就好。但是,在某些情况下,你可能需要自己定制相关工具,这时,本文也许能为你提供帮助。
对于系统隔离来说,本文未尽之处颇多。但是,我希望本文能够为需要了解Linux命名空间隔离工作机制的朋友提供一点小小的帮助。
参见原文。