12_信息熵,信息熵公式,信息增益,决策树、常见决策树使用的算法、决策树的流程、决策树API、决策树案例、随机森林、随机森林的构建过程、随机森林API、随机森林的优缺点、随机森林案例
1 信息熵
以下来自:https://www.zhihu.com/question/22178202/answer/161732605
1.2 信息熵的公式
先抛出信息熵公式如下:

1.2 信息熵
信息量是对信息的度量,就跟时间的度量是秒一样,当我们考虑一个离散的随机变量x的时候,当我们观察到的这个变量的一个具体值的时候,我们接收到了多少信息呢?
多少信息用信息量来衡量,我们接受到的信息量跟具体发生的事件有关。
信息的大小跟随机事件的概率有关。越小概率的事情发生了产生的信息量越大,如湖南产生的地震了;越大概率的事情发生了产生的信息量越小,如太阳从东边升起来了(肯定发生嘛,没什么信息量)。这很好理解!
例子

如果我们有俩个不相关的事件x和y,那么我们观察到的俩个事件同时发生时获得的信息应该等于观察到的事件各自发生时获得的信息之和,即:
h(x,y) = h(x) + h(y)
由于x,y是两个不相关的事件,那么满足p(x,y) = p(x) * p(y)。
根据上面推导,我们很容易看出h(x)一定与p(x)的对数有关(因为只有对数形式的真数相乘之后,能够对应对数的相加形式,可以试试)。因此我们有信息量公式如下:
![]()
下面解决两个疑问:
1、为什么有一个负号
其中,负号是为了确保信息一定是正数或者是0,总不能为负数吧!
2、为什么底数为2
这是因为,我们只需要信息量满足低概率事件x对应于高的信息量。那么对数的选择是任意的。我们只是遵循信息论的普遍传统,使用2作为对数的底!
信息熵
下面我们正式引出信息熵
信息量度量的是一个具体事件发生了所带来的信息,而熵则是在结果出来之前对可能产生的信息量的期望——考虑该随机变量的所有可能取值,即所有可能发生事件所带来的信息量的期望。即:
![]()
转换一下为:
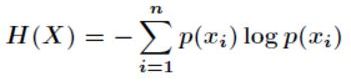
最终我们的公式来源推导完成了。
这里我再说一个对信息熵的理解。信息熵还可以作为一个系统复杂程度的度量,如果系统越复杂,出现不同情况的种类越多,那么他的信息熵是比较大的。
如果一个系统越简单,出现情况种类很少(极端情况为1种情况,那么对应概率为1,那么对应的信息熵为0),此时的信息熵较小。
2 信息增益
信息增益就是熵(这里是信息熵)和特征条件熵的差。
g(D,A)=H(D)-H(D|A) 【信息增益 = 信息熵 - 条件熵】
什么意思呢,就是说对于一个确定的数据集来说,HD(D)是确定的,那么H(D|A)在A特征一定的情况下,随机变量的不确定性越小,信息增益越大,这个特征的表现就越好。
所以,信息增益就是在得知特征X一定的情况下,Y(逾期概率)不确定性的减少程度。
一个特征往往会使一个随机变量Y的信息量减少,减少的部分就是信息增益。

条件熵:表示在条件X下y的信息熵。
3 决策树
3.1 认识决策树
决策树思想的来源非常朴素,程序设计中的条件分支结构就是if-then结构,最早的决策树就是利用这类结构分割数据的一种分类学习方法

3.2 信息论基础–银行贷款分析

你如何去划分是否能得到贷款?

决策树的实际划分:

3.3 决策树的理解
决策树是监督学习算法之一,并且是一种基本的分类与回归方法;决策树也分为回归树和分类树。
决策树是表示基于特征对实例进行分类的树形结构。
从给定的训练数据集中,依据特征选择的准则,递归的选择最优划分特征,并根据此特征将训练数据进行分割,使得各子数据集有一个最好的分类的过程。
决策树算法3要素:
1、特征选择
2、决策树生成
3、决策树剪枝
关于决策树生成:
决策树的生成过程就是 使用满足划分准则的特征不断的将数据集划分为纯度更高,不确定性更小的子集的过程。对于当前数据集D的每一次的划分,都希望根据某特征划分之后的各个子集的纯度更高,不确定性更小。
而如何度量划分数据集前后的数据集的纯度以及不确定性呢?
答案:特征选择准则,比如:信息增益,信息增益率,基尼指数
特征选择准则:
目的:使用某特征对数据集划分之后,各数据子集的纯度要比划分前的数据集D的纯度高(不确定性要比划分前数据集D的不确定性低)
注意:
- 划分后的纯度为各数据子集的纯度的加和(子集占比*子集的经验熵)。
- 度量划分前后的纯度变化 用子集的纯度之和与划分前的数据集D的纯度 进行对比。
3.4 常见决策树使用的算法
- ID3 信息增益 最大的准则
- C4.5 信息增益比 最大的准则
- CART 回归树:平均误差 最小; 分类树:基尼系数 最小的准则,在sklearn中可以选择划分的原则。
3.5 决策树的流程
- 收集数据:公开数据源或爬虫等方式。
- 准备数据:树构造算法只适用于标称型数据,因此数值型数据必须离散化。
- 分析数据:可以使用任何方法,构造树完成之后,需检查图形是否符合预期。
- 训练算法:构造树的数据结构。
- 测试算法:计算树模型的正确率。
- 使用算法:此步骤可以适用于任何监督学习算法,决策树可视化能更好地理解数据的内在含义。
构造决策树的数据必须要充足,特征较少的数据集可能会导致决策树的正确率偏低。若数据特征过多,不会选择特征也会影响决策树的正确率。构建一个比较理想的决策树,大致可分为以下三步:特征选择、决策树的生成与决策树的修剪。
3.6 sklearn决策树API
class sklearn.tree.DecisionTreeClassifier(criterion=’gini’, max_depth=None,random_state=None)
决策树分类器
criterion:默认是'gini'系数,也可以选择信息增益的熵'entropy'
max_depth:树的深度大小
random_state:随机数种子
method:
decision_path:返回决策树的路径。
3.7 泰坦尼克号乘客生存分类
在泰坦尼克号和titanic2数据帧描述泰坦尼克号上的个别乘客的生存状态。在泰坦尼克号的数据帧不包含从剧组信息,但它确实包含了乘客的一半的实际年龄。关于泰坦尼克号旅客的数据的主要来源是百科全书Titanica。这里使用的数据集是由各种研究人员开始的。其中包括许多研究人员创建的旅客名单,由Michael A. Findlay编辑。
我们提取的数据集中的特征是票的类别,存活,乘坐班,年龄,登陆,home.dest,房间,票,船和性别。乘坐班是指乘客班(1,2,1),是社会经济阶层的代表。
其中age数据存在缺失。
数据地址:http://biostat.mc.vanderbilt.edu/wiki/pub/Main/DataSets/titanic.txt

泰坦尼克号乘客生存分类模型:
1、pd读取数据
2、选择有影响的特征,处理缺失值
3、进行特征工程,pd转换字典,特征抽取
x_train.to_dict(orient="records")
4、决策树估计器流程。
决策树的结构、本地保存
1、sklearn.tree.export_graphviz()函数能够导出DOT格式
tree.export_graphviz(estimator,out_file='tree.dot’,feature_names=[‘’,’’])
2、工具:(能够将dot文件转换为pdf、png)
安装graphviz
ubuntu:sudo apt-get install graphviz Mac:brew install graphviz
3、运行命令
然后我们运行这个命令
dot -Tpng tree.dot -o tree.png
windows下安装graphviz
如果是windows下,访问graphviz官网,下载graphviz-2.38.msi
案例:
from sklearn.model_selection import train_test_split
from sklearn.feature_extraction import DictVectorizer
from sklearn.tree import DecisionTreeClassifier,export_graphviz
import pandas as pd
def decision():
"""
决策树对泰坦尼克号进行预测生死
:return:
"""
# 获取数据
titan = pd.read_csv("http://biostat.mc.vanderbilt.edu/wiki/pub/Main/DataSets/titanic.txt")
# 处理数据,找出特征值和目标值
x = titan[['pclass', 'age', 'sex']]
y = titan['survived']
print(x)
# 缺失值处理
x['age'].fillna(x['age'].mean(), inplace=True)
# 分割数据集到训练集合测试集
x_train, x_test, y_train, y_test = train_test_split(x, y, test_size=0.25)
# 进行处理(特征工程)特征-》类别-》one_hot编码
dict = DictVectorizer(sparse=False)
x_train = dict.fit_transform(x_train.to_dict(orient="records"))
print(dict.get_feature_names())
x_test = dict.transform(x_test.to_dict(orient="records"))
print(x_train)
# 用决策树进行预测
dec = DecisionTreeClassifier()
#
dec.fit(x_train, y_train)
#
# 预测准确率
print("预测的准确率:", dec.score(x_test, y_test))
#
# 导出决策树的结构
export_graphviz(dec, out_file="./tree.dot", feature_names=['年龄', 'pclass=1st', 'pclass=2nd', 'pclass=3rd', '女性', '男性'])
return None
if __name__ == "__main__":
decision()
输出结果:
pclass age sex
0 1st 29.0000 female
1 1st 2.0000 female
2 1st 30.0000 male
3 1st 25.0000 female
4 1st 0.9167 male
... ... ...
1308 3rd NaN male
1309 3rd NaN male
1310 3rd NaN male
1311 3rd NaN female
1312 3rd NaN male
[1313 rows x 3 columns]
D:\installed\Anaconda3\lib\site-packages\pandas\core\generic.py:6287: SettingWithCopyWarning:
A value is trying to be set on a copy of a slice from a DataFrame
See the caveats in the documentation: http://pandas.pydata.org/pandas-docs/stable/user_guide/indexing.html#returning-a-view-versus-a-copy
self._update_inplace(new_data)
['age', 'pclass=1st', 'pclass=2nd', 'pclass=3rd', 'sex=female', 'sex=male']
[[24. 0. 0. 1. 0. 1. ]
[20. 0. 1. 0. 1. 0. ]
[51. 1. 0. 0. 0. 1. ]
...
[31.19418104 0. 1. 0. 1. 0. ]
[18. 0. 0. 1. 0. 1. ]
[31.19418104 0. 1. 0. 1. 0. ]]
预测的准确率: 0.7781155015197568
3.8 决策树的优缺点以及改进
优点:
1、简单的理解和解释,树木可视化
2、需要很少的数据准备,其他技术通常需要数据归一化。
缺点:
1、决策树学习者可以创建不能很好地推广数据的过于复杂的树,这被称为过拟合。
2、决策树可能不稳定,因为数据的小变化可能会导致完全不同的树被生成
改进:
1、减枝cart算法。
2、随机森林
4 集成学习方法-随机森林
集成学习通过建立几个模型组合的来解决单一预测问题。它的工作原理是生成多个分类器/模型,各自独立地学习和作出预测。这些预测最后结合成单预测,因此优于任何一个单分类的做出预测。
4.1 什么是随机森林
定义:在机器学习中,随机森林是一个包含多个决策树的分类器,并且其输出的类别是由个别树输出的类别的众数(绝大多数)而定。
例如:如果你训练了5个树,其中有4个树的结果是True,1个树的结果是False,那么最终结果会是True。
随机森林是一种有监督学习算法,是以决策树为基学习器的集成学习算法。随机森林非常简单,易于实现,计算开销也很小,但是它在分类和回归上表现出非常惊人的性能,因此,随机森林被誉为“代表集成学习技术水平的方法”。
学习算法
根据下列算法而建造每棵树:
1、用N来表示训练用例(样本)的个数,M表示特征数目。
2、输入特征数目m,用于确定决策树上一个节点的决策结果;其中m应远小于M。
3、从N个训练用例(样本)中以有放回抽样的方式,取样N次,形成一个训练集(即bootstrap取样),并用未抽到的用例(样本)做预测,评估其误差。
随机森林的随机性体现在哪几个方面?
1、数据集的随机选取
从原始的数据集中采取有放回的抽样(bagging),构造子数据集,子数据集的数据量是和原始数据集相同的。不同子数据集的元素可以重复,同一个子数据集中的元素也可以重复。
2、待选特征的随机选取
与数据集的随机选取类似,随机森林中的子树的每一个分裂过程并未用到所有的待选特征,而是从所有的待选特征中随机选取一定的特征,之后再在随机选取的特征中选取最优的特征
为什么要随机抽样训练集?
如果不进行随机抽样,每棵树的训练集都一样,那么最终训练出的树分类结果也是完全一样的。
为什么要有放回地抽样?
如果不是有放回的抽样,那么每棵树的训练样本都是不同的,都是没有交集的,这样每棵树都是“有偏的”,都是绝对“片面的”(当然这样说可能不对),也就是说每棵树训练出来都是有很大的差异的;而随机森林最后分类取决于多棵树(弱分类器)的投票表决。
为什么使用随机森林
1、随机森林既可以用于分类问题,也可以用于回归问题
2、过拟合是个关键的问题,可能会让模型的结果变得糟糕,但是对于随机森林来说,如果随机森林的树足够多,那么分类器就不会过拟合模型
3、随机森林分类器可以处理缺失值。
4、随机森林分类器可以用分类值建模。
4.2 随机森林的构建过程

1、从原始训练集中使用Bootstraping方法随机有放回采样取出m个样本,共进行n_tree次采样。生成n_tree个训练集。
2、对n_tree个训练集,我们分别训练n_tree个决策树模型。
3、对于单个决策树模型,假设训练样本特征的个数为n,那么每次分裂时根据信息增益/信息增益比/基尼指数 选择最好的特征进行分裂。
4、每棵树都已知这样分裂下去,知道该节点的所有训练样例都属于同一类。在决策树的分裂过程中不需要剪枝
5、将生成的多颗决策树组成随机森林。对于分类问题,按照多棵树分类器投票决定最终分类结果;对于回归问题,由多颗树预测值的均值决定最终预测结果。
注意:OOB(out-of-bag ):每棵决策树的生成都需要自助采样,这时就有1/3的数据未被选中,这部分数据就称为袋外数据。
再如:
随机森林分解开来就是“随机”和“森林”。“随机”的含义我们之后讲,我们先说“森林”,森林是由很多棵树组成的,因此随机森林的结果是依赖于多棵决策树的结果,这是一种集成学习的思想。森林里新来了一只动物,森林举办森林大会,判断这到底是什么动物,每棵树都必须发表意见,票数最多的结果将是最终的结果。随机森林最终的模型见下图示:
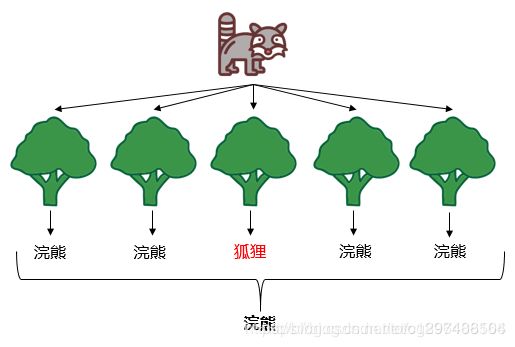
这里推荐一篇博文:用通俗易懂的方式剖析随机森林
4.3 随机森林API
class sklearn.ensemble.RandomForestClassifier(n_estimators=10, criterion=’gini’,max_depth=None, bootstrap=True, random_state=None)
n_estimators:integer,optional(default = 10) 森林里的树木数量
criteria:string,可选(default =“gini”)分割特征的测量方法。
max_depth: integer或None,可选(默认=无)树的最大深度
bootstrap:boolean,optional(default=True) 是否在构建树时使用放回抽样
4.4 随机森林的优点、缺点
- 在当前所有算法中,具有极好的准确率
- 能够有效地运行在大数据集上
- 能够处理具有高维特征的输入样本,而且不需要降维
- 能够评估各个特征在分类问题上的重要性
- 对于缺省值问题也能够获得很好得结果
- 由于采用了集成算法,本身精度比大多数单个算法要好,所以准确性高。
- 在测试集上表现良好,由于两个随机性的引入,使得随机森林不容易陷入过拟合(样本随机,特征随机)
- 在工业上,由于两个随机性的引入,使得随机森林具有一定的抗噪声能力,对比其他算法具有一定优势
- 由于树的组合,使得随机森林可以处理非线性数据,本身属于非线性分类(拟合)模型。
- 它能够处理很高维度(feature很多)的数据,并且不用做特征选择,对数据集的适应能力强:既能处理离散型数据,也能处理连续型数据,数据集无需规范化
- 训练速度快,可以运用在大规模数据集上。
- 可以处理缺省值(单独作为一类),不用额外处理。
- 由于有袋外数据(OOB),可以在模型生成过程中取得真实误差的无偏估计,且不损失训练数据量。
- 在训练过程中,能够检测到feature间的互相影响,且可以得出feature的重要性,具有一定参考意义。
- 由于每棵树可以独立、同时生成,容易做成并行化方法。
- 由于实现简单、精度高、抗过拟合能力强,当面对非线性数据时,适于作为基准模型。
缺点:
- 当随机森林中的决策树个数很多时,训练时需要的空间和时间会比较大
- 随机森林中还有许多不好解释的地方,有点算是黑盒模型
- 在某些噪音比较大的样本集上,RF的模型容易陷入过拟合
4.5 泰坦尼克号乘客生存分类分析
from sklearn.model_selection import train_test_split,GridSearchCV
from sklearn.feature_extraction import DictVectorizer
from sklearn.ensemble import RandomForestClassifier
import pandas as pd
def decision():
"""
决策树对泰坦尼克号进行预测生死
:return:
"""
# 获取数据
titan = pd.read_csv("http://biostat.mc.vanderbilt.edu/wiki/pub/Main/DataSets/titanic.txt")
# 处理数据,找出特征值和目标值
x = titan[['pclass', 'age', 'sex']]
y = titan['survived']
print(x)
# 缺失值处理
x['age'].fillna(x['age'].mean(), inplace=True)
# 分割数据集到训练集合测试集
x_train, x_test, y_train, y_test = train_test_split(x, y, test_size=0.25)
# 进行处理(特征工程)特征-》类别-》one_hot编码
dict = DictVectorizer(sparse=False)
x_train = dict.fit_transform(x_train.to_dict(orient="records"))
print(dict.get_feature_names())
x_test = dict.transform(x_test.to_dict(orient="records"))
# 随机森林进行预测(超参数调优)
rf = RandomForestClassifier()
param = {"n_estimators": [120, 200, 300, 500, 800, 1200], "max_depth": [5, 8, 15, 25, 30]}
# 网络搜索与交叉验证
gc = GridSearchCV(rf,param_grid=param,cv=2)
gc.fit(x_train,y_train)
print("准确率:",gc.score(x_test,y_test))
print("查看选择的参数模型:", gc.best_params_)
return None
if __name__ == "__main__":
decision()
输出结果:
pclass age sex
0 1st 29.0000 female
1 1st 2.0000 female
2 1st 30.0000 male
3 1st 25.0000 female
4 1st 0.9167 male
... ... ...
1308 3rd NaN male
1309 3rd NaN male
1310 3rd NaN male
1311 3rd NaN female
1312 3rd NaN male
[1313 rows x 3 columns]
D:\installed\Anaconda3\lib\site-packages\pandas\core\generic.py:6287: SettingWithCopyWarning:
A value is trying to be set on a copy of a slice from a DataFrame
See the caveats in the documentation: http://pandas.pydata.org/pandas-docs/stable/user_guide/indexing.html#returning-a-view-versus-a-copy
self._update_inplace(new_data)
['age', 'pclass=1st', 'pclass=2nd', 'pclass=3rd', 'sex=female', 'sex=male']
准确率: 0.7750759878419453
查看选择的参数模型: {'max_depth': 5, 'n_estimators': 120}
打个赏呗,您的支持是我坚持写好博文的动力。
