使用Spring Cloud Netflix技术栈实施微服务架构
本文假设读者已经熟悉分布式系统的常见模式,如服务发现、注册,统一配置管理等
前言
系统一旦走向分布式,其复杂程度成倍增长,传统单体应用只考虑业务逻辑的开发方式已经不再适用。正因其复杂性,目前只有业务需求大的大型互联网公司才会(被迫)采用,而且需要投入大量的技术力量来开发基础设施,也造成了小公司“用不起”分布式架构的情况。现在这一局面正在逐渐被打破,因为Netflix开源了其经过实战考验的一系列基础设施构件,加上Spring Cloud的大力支持,开发分布式系统已经不再像以前那样可怕了。
统一的配置管理
微服务意味着要将单体应用中的业务拆分成一个个子服务,每个服务的粒度相对较小,因此系统中会出现大量的服务。由于每个服务都需要必要的配置信息才能运行,所以一套集中式的、动态的配置管理设施是必不可少的。Spring Cloud提供了Config Server来解决这个问题。Config Server的主要功能如下:
集中化的配置文件管理
不再需要在每个服务部署的机器上编写配置文件,服务会向配置中心统一拉取配置自己的信息。动态化的配置更新
当配置发生变动时,服务不需要重启即可感知到配置的变化并应用新的配置。将配置信息以HTTP REST接口的形式暴露
这使得非Java语言的服务也能享受到上面两点功能。
Config Server的架构图如下:
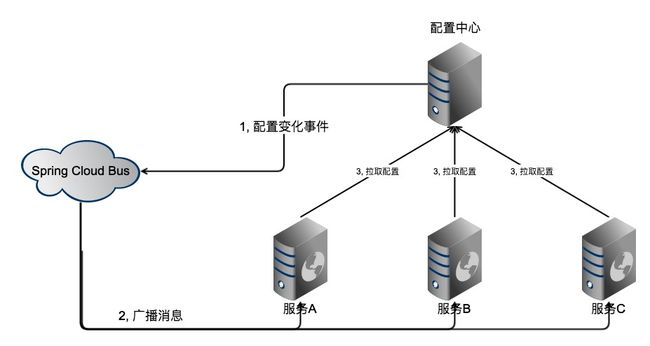
工作流程如下:
- 配置中心感知到配置变化(如,git仓库发生commit提交),向Bus投递消息
- Bus向服务广播消息
- 服务收到消息后,主动向配置中心拉取新配置并应用
其中配置中心可集群部署实现高可用。
服务的注册发现和LB
Spring Cloud Netflix通过Eureka Server实现服务注册中心,通过Ribbon实现软负载均衡:
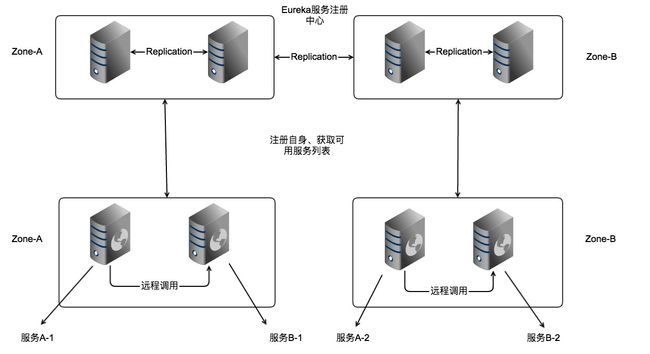
Zone
Eureka支持Region和Zone的概念。其中一个Region可以包含多个Zone。Eureka在启动时需要指定一个Zone名,即当前Eureka属于哪个zone, 如果不指定则属于defaultZone。Eureka Client也需要指定Zone, Client(当与Ribbon配置使用时)在向Server获取注册列表时会优先向自己Zone的Eureka发请求,如果自己Zone中的Eureka全挂了才会尝试向其它Zone。当获取到远程服务列表后,Client也会优先向同一个Zone的服务发起远程调用。Region和Zone可以对应于现实中的大区和机房,如在华北地区有10个机房,在华南地区有20个机房,那么分别为Eureka指定合理的Region和Zone能有效避免跨机房调用,同时一个地区的Eureka坏掉不会导致整个该地区的服务都不可用。
Ribbon软负载均衡
Ribbon工作在服务的调用方,分成两步,第一步先选择 Eureka Server, 它优先选择在同一个Zone且负载较少的server, 第二步从Eureka中获取到目标服务全部可用的地址,再根据用户指定的策略,从列表中选择一个地址作为最终要发请求的目标服务器。其中Ribbon提供了三种策略:轮询、断路器和根据响应时间加权。
声明式HTTP REST客户端Feign
Feign与Apache Http Client这类客户端最大的不同,是它允许你通过定义接口的形式构造HTTP请求,不需要手动拼参数,使用起来与正常的本地调用没有什么区别:
@FeignClient(name = "ea")
public interface AdvertGroupRemoteService {
@RequestMapping(value = "/group/{groupId}", method = RequestMethod.GET)
AdvertGroupVO findByGroupId(@PathVariable("groupId") Integer adGroupId);
}这里我们只需要调用AdvertGroupRemoteService.findByGroupId()方法就能完成向目标主机发HTTP请求并封装返回结果的效果。
断路器、资源隔离与自我修复
断路器(Cricuit Breaker)是一种能够在远程服务不可用时自动熔断(打开开关),并在远程服务恢复时自动恢复(闭合开关)的设施,Spring Cloud通过Netflix的Hystrix组件提供断路器、资源隔离与自我修复功能。下面介绍一下在分布式系统中为什么需要断路器。
在微服务架构中,对于客户端的一个请求,我们可能需要调用多个子(微)服务,如图所示:
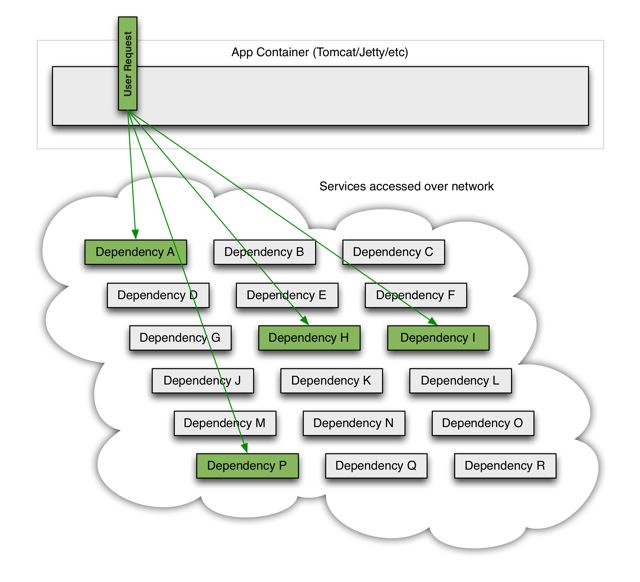
上图中的请求需要调用A, P, H, I 四个服务,如果一切顺利则没有什么问题,关键是如果I服务超时会出现什么情况呢?
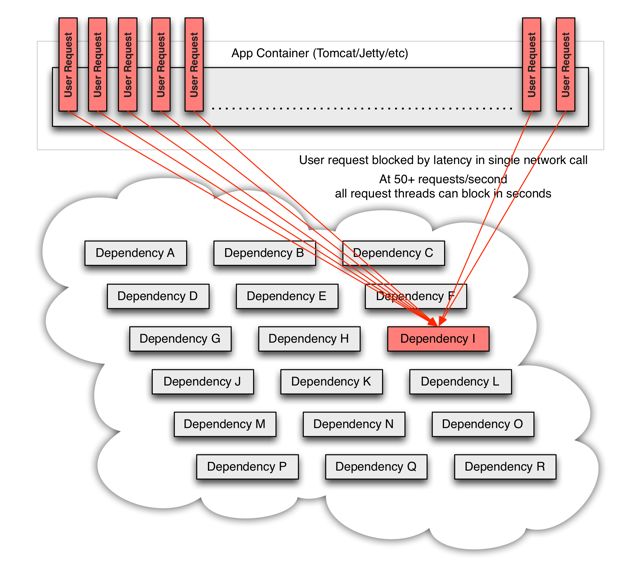
当服务I由于某种原因无法响应时,用户请求就会卡在服务 I 的远程调用上,假如超时失败时间设置为2秒,那么在这2秒内容器的当前线程就会一直被堵塞在该调用中。 我们假设容器最大线程数为100, 如果此时又有另外99个请求都需要调用服务 I, 那么这99个线程同样会被堵塞,这样就会因为容器线程耗尽而导致该应用无法响应其它任何请求。因为一个服务挂掉而导致整个应用不可用显然是无法接受的。那么 Hystrix 是如何解决这个问题的呢?
资源隔离
首选,Hystrix对每一个依赖服务都配置了一个线程池,对依赖服务的调用会在线程池中执行。例如,我们设计服务 I 的线程池大小为20, 那么 Hystrix会最多允许有20个容器线程调用服务 I, 如果超出20,Hystrix会拒绝并快速失败。这样即使服务 I 长时间未响应,容器最多也只能堵塞20个线程,剩余80个线程仍然可以处理用户请求。
快速失败
快速失败是防止资源耗尽的关键一点。当 Hystrix 发现在过去某段时间内对服务 I 的调用出错率达到某个阀值时,Hystrix 就会“熔断”该服务,后续任何向服务 I 的请求都会快速失败,而不是白白让调用线程去等待。
自我修复
处于熔断状态的服务,在经过一段时间后,Hystrix会让其进入“半关闭”状态,即允许少量请求通过,然后统计调用的成功率。如果这个请求都能成功,Hystrix 会恢复该服务,从而达到自我修复的效果。其中,在服务被熔断到进入半关闭状态之间的时间,就是留给开发人员排查错误并恢复故障的时间,开发人员可以通过监控措施得到提醒并线上排查。
监控方案
监控是保障分布式系统健康运行必不可少的方案。基于Spring Cloud,我们可以从两个纬度进行监控:Hystrix断路器的监控和每个服务监控状况的监控。
下图是 Hystrix 提供的 Dashboard 图形化监控:
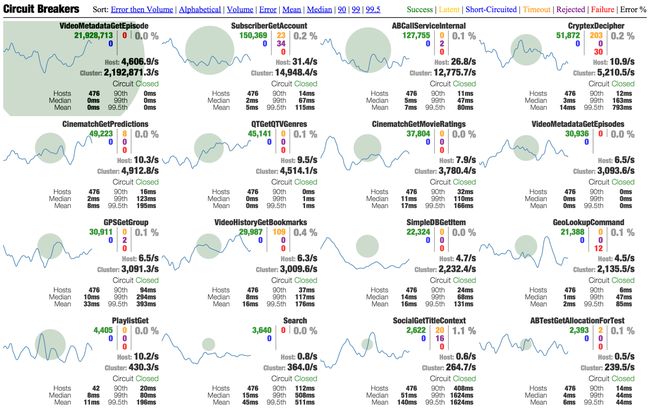
可见图中监控信息应有尽有(调用成功率、平时响应时间、调用频次、断路器状态等)。我们可以通过编程的方式定时获取该信息,并在断路器熔断时通过短信、邮件等方式通知开发者。
Hystrix的监控数据默认是保存在每个实例的内存中的,Spring Boot提供了多种方式,可以导入到Redis、TSDB以供日后分析使用。
除此之外,Spring Cloud还提供了对单个实例的监控:
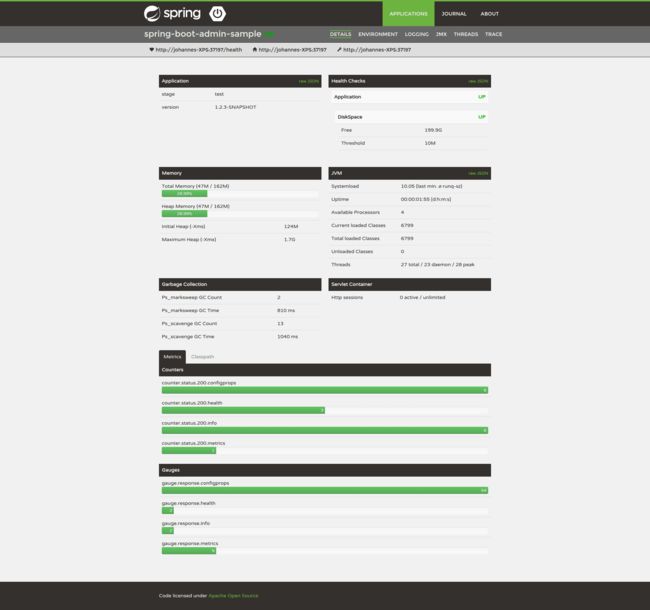
其中包含了接口调用频次,响应时间,JVM状态,动态日志等各种开发者关心的信息。
总结
以上是Spring Cloud Netflix为微服务架构提供的支持,Spring Cloud项目还有许多其它子项目有着更强大的功能,通过这些组件,我们能以 Spring Boot 简洁的风格快速搭建微服务架构,并让开发人员专注于业务,让分布式对开发者尽量透明。
欢迎访问Spring Cloud论坛交流经验:http://bbs.spring-cloud.io/