认识Hadoop
简单介绍
Hadoop的来历的,名字由来 Hadoop不是缩写,这个词是造出来的,Haddop之父Doug Cutting 孩子给毛绒象玩具取的名字Hadoop是一个分布式系统基础架构,在用户不了解底层细节的情况下,能利用集群的威力进行高速度运算和大文件存储。
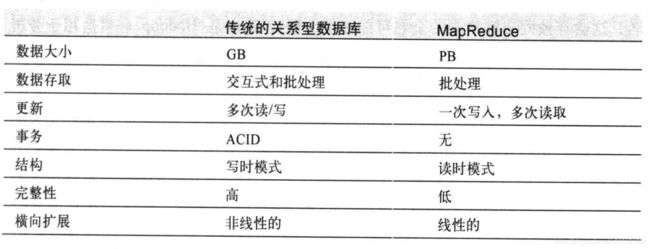
Hadoop主要组件有三个,这三个构成了狭义上的hadoop(因为正常使用上还会和其他组件配合使用),这三个基本的组件为:HDFS 分布式文件存储系统,MapReduce 分布式计算框架,YARN 另一种资源调度器,简单来说HDFS主要功能就是存储读取数据,MapReduce主要功能就是对数据进行计算,得出我们想要的新数据,YARN就是在前两个干活的时候,对资源(cpu,内存等)进行分配。那么Hadoop不止这三个组件还有ZooKeeper,Pig,Chukwa,Hive,Hbase,Mahout,flume等,这些所有的组件统称为Hadoop生态圈,也就是广义上的Hadoop。
Hadoop能做什么?形象生动的说下,如果有一个1000TB的大文件,文件里面全是数字,我们需要算出所有数的平均数,正常服务器无论从硬盘容量还有计算能力,内存等方面都是不能解决这个问题的,但是如果用Hadoop,首先HDFS可以存1000TB的文件,他会把文件切分成一个个的小文件块,然后存在多个服务器的硬盘上,这样就解决了存储这1000TB文件的问题,整个大文件分布在HDFS的存储集群上,MapReduce 会对算出所有数的平均数这个任务进行分割,也会有个集群,集群中每个计算机都拿一小块数据,进行对一小块数据的计算,然后每个小块的计算结果再汇总,最后得出最后的结果,例如把每个小块的数据全部累加,最后合并的时候除以总数,这样计算能力就能通过加机器的方法扩展,YARN 协调HDFS和MapReduce的资源调度。
Hadoop特点
1 文件大下可以存储TB PB 更高级的数据
2 不支持更新,一次写入多次读取
3 不支持事物ACID
4 普通数据库是写时模式(写入的时候确定数据格式)MapReduce是读时模式,读取的时候识别数据结构。
5横向扩展 是线性的,加机器就能提高计算能力和存储能力
三个主要组件
MapReduce
Map(映射) Reduce(化简)
MapReduce 如果要执行任务,是需要开发一个java程序的。
MapReduce 是一个计算框架,客户端发布一个任务叫Job ,会拆分成Map 和Reduce 两种任务,形成任务队列,叫集群去执行。
主要架构
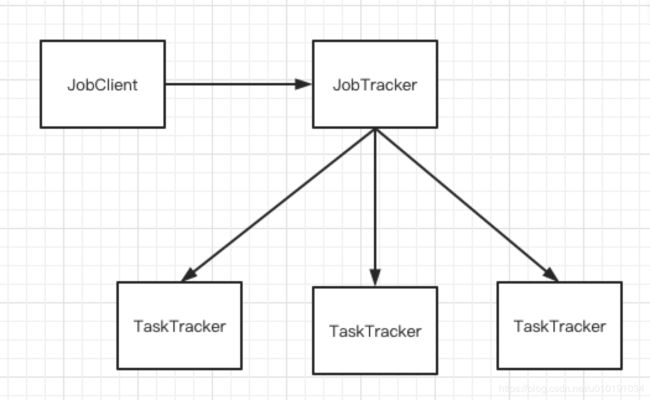
简单解释:JobClient 给JobTracker发一个任务,JobTracker会将任务拆分成两种任务map任务和reduce任务,这些任务会发给TaskTracker执行(map任务都执行完了才会跑reduce任务)。
JobTracker HA(High availability)JobTracker是单点的,会有高可用问题,但是暂时没找到具体JobTracker的高可用方案。
执行主要步骤
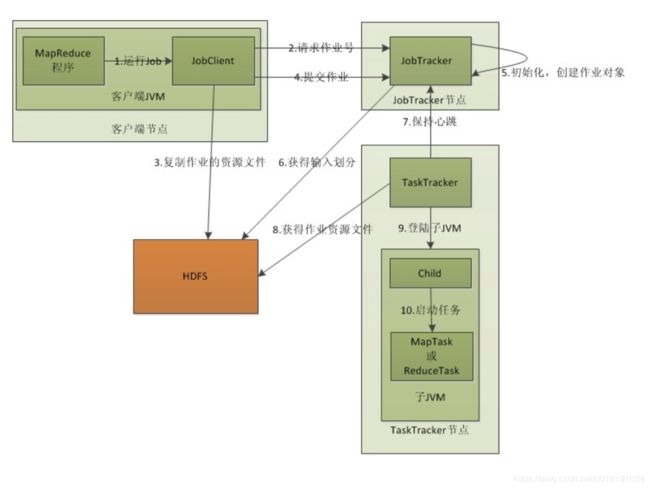
1 首先客户端会启动JobClient 用于控制调用JobTracker 和HDFS
2 请求作业号(产生一个作业任务)
3 叫HDFS复制一份Job任务需要的资源数据
4 像JobTracker提交作业(需要的资源数据信息,并非实际内容)
5 初始化,创建作业队形
6 获得输入划分(数据分块的划分)
7 保持心跳(如果执行任务的节点失败,会将任务分配给其他节点执行)
8 TaskTracker 获取HDFS的文件内容进行任务(一般情况下任务都会分配给储存着任务资源块的主机进行执行,这样就没有网络传输)
9 登录字JVM
10启动执行任务
map和reduce步骤
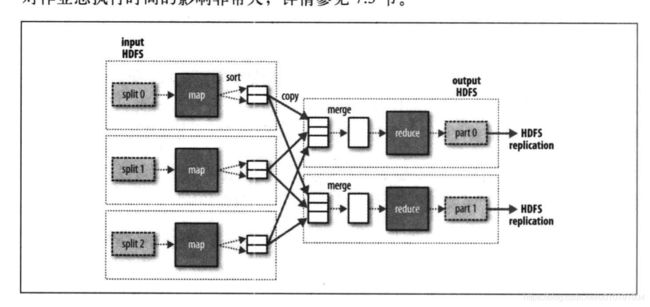
首先输入数据,执行map任务,输出数据,排序,这里的map主要是提取了数据的作用,然后进行排序和并,进行reduce任务计算,输出到HDFS,具体请参考https://www.jianshu.com/p/99a1d964434c 辣椒酱的故事。
HDFS
The Hadoop Distributed file System (HDFS) 分布式文件系统
以流式数据访问存超大文件(超大文件这里指,几百MB,几百GB,甚至几百TB,目前已经有PB级别的Hadoop集群了)
HDFS存储是将大文件分为一个个块进行存储,默认块大小128M,不足128,占文件本身的空间大小。
优点
1 流式数据访问 一次写入多次读取
2 构建在廉价的机器上 不需要昂贵可靠硬件,用普通硬件搭建集群
3 可靠性高 文件有备份机制
劣势
1 低延迟的数据访问,不适合几十毫秒范围的低延迟数据访问
2 大量小文件,namenode将文件的元数据存在内存中,所以文件的信息,目录,数据块等存储信息大概占150个字节,举例100万个文件,需要300M内存,如果上亿就超出了当前硬件能力(内存不够大)
3 多用户写入,任意修改文件,HDFS只支持文件单个写入,并以添加的方式(只在文件末尾添加数据),不支持文件任意位置的修改。
主要框架
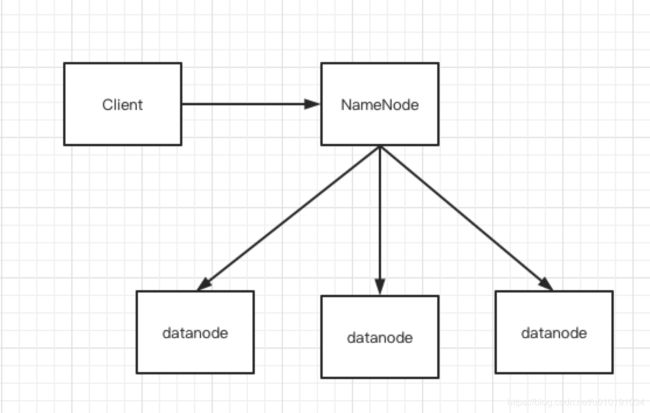
Namenode(管理节点)
管理文件系统命名空间,维护文件系统树,文件和目录信息永久保存再磁盘上,命名空间镜像文件和编辑日志文件,系统启动的时候重建这些信息。
Datanode(工作节点)
文件系统的工作节点,主要储存检索数据块,接受client和Datanode的调度,定期向namenode发送储存块的列表。
Client(客户端)
代表用户 与 Namenode和Datanode交互
图
namenode备份机制
1 生成持久化文件进行备份,当namenode出现问题用文件恢复
2 热备 ,运行另一个namenode
数据存储可靠

读取流程
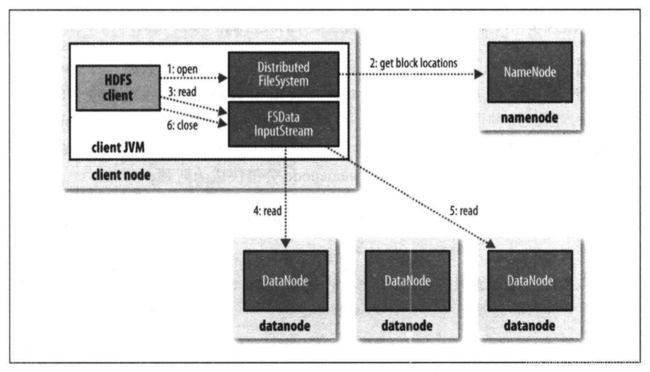
1 客户端调用DistributedFileSystem 的open方法
2 DistributedFileSystem 通过RPC调用namenode 确定文件块在哪些datanode上,然后DistributedFileSystem 返回一个DFSINputStream来管理datanode和namenode的IO
3 clinet调用read ,然后会根据clinet和datanode的距离,来选出距离最近的一个
4 -5连接读取数据,读取后关闭与这个datanode的连接然后读取下一个块,这些对客户端都是透明的,客户端看来是一直在读取一个连续的流。
6读取完成调用close
网络拓扑
上面说到会根据近的去找datanode,这个需要手动配置网络拓扑。
1 同一节点上的进程
2 同一机架上的不同节点
3 同一个数据中心,不同机架
4 不同数据中心
可用带宽一次递减,给出4中距离的描述/d1/r1/n1
写入流程

1 客户端调用DistributedFileSystem 的create() Rpc调用NameNode,在NameNode创建一个文件(此时文件还没有对应数据块)
2 创建成功后NameNode会返回一个FSDataOutputStream,他会封装一个DFSoutPutstream对象 来负责客户端与datanode和namenode的通信
3-5 在客户端写入数据时候,FSDataOutputStream 会将数据拆成一个一个数据包,并写入内部数据队列,DataStreamer处理队列,挑出适合存储的datanode(多个默认为3),DataStreamer会传到其中一个(假设第一个),然后1传2 ,2传3,以此类推,DataStreamer写入一个就算成功
6 写入完成后调用close,告知namenode写入完成。
7 写入后调用close,告namenode已经知道文件有哪些块组成,DataStreamer已经告知过,所以只需要等待副本复制完就能返回成功。
其他:
namenode如何选择在哪个datanode上储存副本?这里是根据可靠性,写入带宽,和读取带宽进行平衡的。(可靠性:副本不能放到一台机器上吧,写入和读取需要手工配置一个网络拓扑)
其他
缓存块:Datanode节点会对读取次数多的块进行缓存
联邦HDFS:Namenode存在单点,因为内存大小会有扩展瓶颈,联邦HDFS有多个Namenode,每个Namenode管理命名空间的一部分
Hadoop可以配置用户访问权限
基本操作
命令行输入 hadoop fs -help
YARN
Yet Another Resource Negotiator 集群资源管理系统
最早Hadoop 1 的时候是没有YARN的,资源管理是在MapReduce里的,为了让MapReduce能更好的干自己的工作,后来Hadoop2 将MapReduce中的这部分抽了出来,放到了YARN里
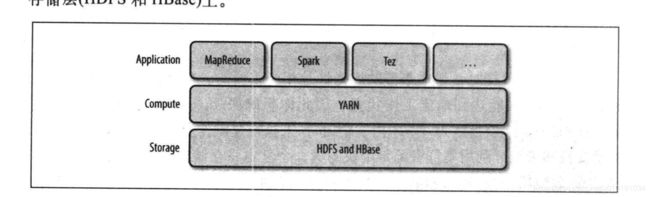
YARN是计算框架和HDFS之间做资源管理功能的
运行机制
资源管理器 resource manager 启动和监控 容器 container 的加点管理器 node manager
容器:一个容器可以是一个Unix 进程 也可以是一个linux cgroup
如何运行应用
1 客户端联系资源管理器,要求运行一个application master 进程
2 a 和 2b 找一个容器启动 application master
3 返回处理结果 或像resourceManager请求更多容器
4 a 4b 使用更多容器运行分布式计算
总结:
这几天了解hadoop其实还有很多问题都没有找到答案,还有很多问题,但是再深入之前我想先总结下,然后再继续深入学习,对于YARN还不是很了解,说是对资源进行控制管理,cpu内存等,但是具体怎么管理的还不是很明白,管理涉及到哪些资源也不是很清楚,比如HDFS的块数据在参与MapReduce运算的时候,块是被MapReduce调取的还是被YARN管理的,等具体细节。
————————————————————————chenchen——————————————————————————