深度学习之五:使用GPU加速神经网络的训练
使用神经网络训练,一个最大的问题就是训练速度的问题,特别是对于深度学习而言,过多的参数会消耗很多的时间,在神经网络训练过程中,运算最多的是关于矩阵的运算,这个时候就正好用到了GPU,GPU本来是用来处理图形的,但是因为其处理矩阵计算的高效性就运用到了深度学习之中。Theano支持GPU编程,但是只是对英伟达的显卡支持,而且对于Python编程而言,修改一些代码就可以使用GPU来实现加速了。
一,首先需要安装GPU环境(说明:我开始按照官网步骤发生了错误,下面是我综合网上一些资料最后安装成功之后的环境配置,本人机器能用)
- 安装Cuda,Cuda是英伟达公司提供的GPU开发环境,可以直接在官网上下载,我安装的是windows64位版本 ,按照制定的步骤一步一步安装即可
- 安装visual studio2010(cuda支持visual studio 2010,2012,2013) ,我就是因为没有装这个导致一直报错:找不到nvcc编译器
- 安装Cuda过程中会自动在windows的环境变量里面加上了CUDA_PATH这个环境变量:C:\Program Files\NVIDIA GPU Computing Toolkit\CUDA\v7.5
- 在环境变量中的path配置如下:
C:\Program Files\NVIDIA GPU Computing Toolkit\CUDA\v7.5\bin;
C:\Program Files\NVIDIA GPU Computing Toolkit\CUDA\v7.5\libnvvp;[global]
device=gpu
floatX=float32
openmp=False
[blas]
ldflags=
[gcc]
cxxflags = -ID:\Anaconda2\MinGW
[cuda]
root=C:\Program Files\NVIDIA GPU Computing Toolkit\CUDA\v7.5\bin
[nvcc]
fastmath=True
flags= -LD:\Anaconda2\libs
compiler_bindir=C:\Program Files (x86)\Microsoft Visual Studio 10.0\VC\bin
如果需要验证是否成功开启了GPU ,可以使用下面的测试程序(见了解gputest.py),如果显示使用的是GPU则表示成功!
到这里,就可以使用Theano来编写GPU加速的程序了,在theano中编写Theano程序需要注意几个点:
1.Python中的浮点数默认是float64位的,但是如果需要用到cuda那么必须将浮点数转成float32,在上面的.theanorc.txt中就是使用了floatX=float32,就是为了这点,当然还是几种其他的方法,例如使用Tensor的T.fvector方法等
2.使用GPU编程,在Theano中得shared parameters需要全部转成float32位数据,array必须使用dtype=float32进行定义或者使用asType等方法转化成float32
3.从GPU中存取数据一定要小心,如果需要将全部数据存入GPU中,那么最好是讲参数全部变成32位的shared parameters,避免或者谨慎使用gpu_from_host方法
了解了上面的内容,我们就可以将前一篇文章的代码改成可以在GPU上运行的代码了,改动的地方如下:
二、将数据类型全部改成float32位的
np.random.seed(0)
train_X, train_y = datasets.make_moons(5000, noise=0.20)
train_y_onehot = np.eye(2)[train_y]
#设置参数
num_example=len(train_X)
nn_input_dim=2 #输入神经元个数
nn_output_dim=2 #输出神经元个数
nn_hdim=1000
#梯度下降参数
epsilon=np.float32(0.01) #learning rate
reg_lambda=np.float32(0.01) #正则化长度
#设置共享变量
# GPU NOTE: Conversion to float32 to store them on the GPU!
X = theano.shared(train_X.astype('float32')) # initialized on the GPU
y = theano.shared(train_y_onehot.astype('float32'))
# GPU NOTE: Conversion to float32 to store them on the GPU!
w1 = theano.shared(np.random.randn(nn_input_dim, nn_hdim).astype('float32'), name='W1')
b1 = theano.shared(np.zeros(nn_hdim).astype('float32'), name='b1')
w2 = theano.shared(np.random.randn(nn_hdim, nn_output_dim).astype('float32'), name='W2')
b2 = theano.shared(np.zeros(nn_output_dim).astype('float32'), name='b2')
w1.set_value((np.random.randn(nn_input_dim, nn_hdim) / np.sqrt(nn_input_dim)).astype('float32'))
b1.set_value(np.zeros(nn_hdim).astype('float32'))
w2.set_value((np.random.randn(nn_hdim, nn_output_dim) / np.sqrt(nn_hdim)).astype('float32'))
b2.set_value(np.zeros(nn_output_dim).astype('float32'))这里把输入数值traing_X和train_y也设置成theano的共享变量,也是为了将数据全部放入GPU中进行运算。其他的过程都不变,整个代码见下:
# -*- coding: utf-8 -*-
import theano
import theano.tensor as T
import numpy as np
from sklearn import datasets
import matplotlib.pyplot as plt
import time
#定义数据类型
np.random.seed(0)
train_X, train_y = datasets.make_moons(5000, noise=0.20)
train_y_onehot = np.eye(2)[train_y]
#设置参数
num_example=len(train_X)
nn_input_dim=2 #输入神经元个数
nn_output_dim=2 #输出神经元个数
nn_hdim=1000
#梯度下降参数
epsilon=np.float32(0.01) #learning rate
reg_lambda=np.float32(0.01) #正则化长度
#设置共享变量
# GPU NOTE: Conversion to float32 to store them on the GPU!
X = theano.shared(train_X.astype('float32')) # initialized on the GPU
y = theano.shared(train_y_onehot.astype('float32'))
# GPU NOTE: Conversion to float32 to store them on the GPU!
w1 = theano.shared(np.random.randn(nn_input_dim, nn_hdim).astype('float32'), name='W1')
b1 = theano.shared(np.zeros(nn_hdim).astype('float32'), name='b1')
w2 = theano.shared(np.random.randn(nn_hdim, nn_output_dim).astype('float32'), name='W2')
b2 = theano.shared(np.zeros(nn_output_dim).astype('float32'), name='b2')
#前馈算法
z1=X.dot(w1)+b1
a1=T.tanh(z1)
z2=a1.dot(w2)+b2
y_hat=T.nnet.softmax(z2)
#正则化项
loss_reg=1./num_example * reg_lambda/2 * (T.sum(T.square(w1))+T.sum(T.square(w2)))
loss=T.nnet.categorical_crossentropy(y_hat,y).mean()+loss_reg
#预测结果
prediction=T.argmax(y_hat,axis=1)
forword_prop=theano.function([],y_hat)
calculate_loss=theano.function([],loss)
predict=theano.function([],prediction)
#求导
dw2=T.grad(loss,w2)
db2=T.grad(loss,b2)
dw1=T.grad(loss,w1)
db1=T.grad(loss,b1)
#更新值
gradient_step=theano.function(
[],
updates=(
(w2,w2-epsilon*dw2),
(b2,b2-epsilon*db2),
(w1,w1-epsilon*dw1),
(b1,b1-epsilon*db1)
)
)
def build_model(num_passes=20000,print_loss=False):
w1.set_value((np.random.randn(nn_input_dim, nn_hdim) / np.sqrt(nn_input_dim)).astype('float32'))
b1.set_value(np.zeros(nn_hdim).astype('float32'))
w2.set_value((np.random.randn(nn_hdim, nn_output_dim) / np.sqrt(nn_hdim)).astype('float32'))
b2.set_value(np.zeros(nn_output_dim).astype('float32'))
for i in xrange(0,num_passes):
start=time.time()
gradient_step()
end=time.time()
# print "time require:"
# print(end-start)
if print_loss and i%1000==0:
print "Loss after iteration %i: %f" %(i,calculate_loss())
def accuracy_rate():
predict_result=predict()
count=0;
for i in range(len(predict_result)):
realResult=train_y[i]
if(realResult==predict_result[i]):
count+=1
print "count"
print count
print "the correct rate is :%f" %(float(count)/len(predict_result))
def plot_decision_boundary(pred_func):
# Set min and max values and give it some padding
x_min, x_max = train_X[:, 0].min() - .5, train_X[:, 0].max() + .5
y_min, y_max = train_X[:, 1].min() - .5, train_X[:, 1].max() + .5
h = 0.01
# Generate a grid of points with distance h between them
xx, yy = np.meshgrid(np.arange(x_min, x_max, h), np.arange(y_min, y_max, h))
# Predict the function value for the whole gid
Z = pred_func(np.c_[xx.ravel(), yy.ravel()])
Z = Z.reshape(xx.shape)
# Plot the contour and training examples
plt.contourf(xx, yy, Z, cmap=plt.cm.Spectral)
plt.scatter(train_X[:, 0], train_X[:, 1], c=train_y, cmap=plt.cm.Spectral)
plt.show()
build_model(print_loss=True)
accuracy_rate()
# plot_decision_boundary(lambda x: predict(x))
# plt.title("Decision Boundary for hidden layer size 3")
程序中为了使得加速效果更明显,将隐含层的个数调整为1000个然后将训练参数个数调整到5000个,首先来看一下执行结果:
然后我们对比一下在使用GPU加速之前和使用GPU加速之后一次迭代的时间代价,需要使用cpu只需要将上面配置文件的device的gpu改成cpu即可
在使用GPU之后,一次迭代gradient_step()的时间是:
使用CPU运行的结果是:
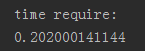
我的显卡是GT720,属于比较低端的显卡,我的CPU是Inter i5,算是还不多的CPU,但是就算配置相差大,但是加速效果也有5倍之多,在稍微好点的GPU中,这个实验可以跑到7.5ms,加速足足有40倍之多,所以GPU对训练过程的加速效果还是显而易见的