数据库基础知识--数据库知识的一些小总结
数据库是长期存储在计算机内有组织的大量的共享的数据集合。它可以提供各种用户分享,具有最小冗余度和较高的数据独立性。
一、数据模型
根据模型应用目的的不同,数据模型分为两类,第一类是概念模型,第二类是逻辑模型和物理模型。
概念模型,也称信息模型,它是按用户的观点来对数据和信息建模,主要用于数据库设计。
逻辑模型主要包括层次模型,网状模型,关系模型,面向对象模型和对象关系模型等。
物理模型是对数据最底层的抽象,它描述数据在系统内部的表示方法和存取方法,在磁盘或磁带上的存储方式和存取方法,是面向计算机系统的。
关系模型中数据的逻辑结构是一张二维表,或者说关系的数据结构就是一张表。关系数据模型的数据操作主要包括查询、插入、删除和更新数据。
二、主键和外键
若关系(二维表)中的某一属性组的值能唯一标识一个元组,则该属性组称为候选码,若一个表中有多个候选码,则可选定其中一个为主键。
如果关系模式R的某属性集不是R的主键,而是另一个关系R1的主键,则该属性集是关系模式R的外键。
关系模型的实体完整性规则:若属性A是基本关系R的主属性,则A不能取空值。即:主键不能为空。
关系模型的参照完整性规则:若属性F是某基本关系R的外键,且它与基本关系R1的主键相对应,则对于R中,每个F上的值或为空值或者等于R1中的主键值。
关系模型有三类完整性约束:实体完整性、参照完整性和用户定义的完整性。
三、事务
事务指的是用户定义的一个数据库操作序列,这些操作要么全做要么全不做,是一个不可分割的工作单位。
事务有四个特性:原子性(Atomicity)、一致性(Consistency)、隔离性(Isolation)和持续性(Durability)。这四个特性简称为ACID特性。
四、索引
索引是对数据库表中一列或多列的值进行排序的一种结构,使用索引可快速访问数据表中的特定信息。
为表设置索引是需要付出代价的,比如:一、增加了数据库的存储空间;二、在插入和修改数据时要花费较多的时间。
语句格式:
CREATE [UNIQUE] [CLUSTERED] INDEX <索引名> ON <表名>(<列名>[<次序>][,<列名>[<次序>] ]…);例子:
1)在表Student(学生信息表)上岸Sno(学号)降序建立唯一索引
CREATE UNIQUE INDEX Stusno ON Student(Sno desc);
ALTER TABLE Student DROP INDEX Stusno;创建索引可以大大提高系统的性能。
1.通过创建唯一性索引,可以保证数据库表中每一行数据的唯一性。
2.可以大大加快数据的检索速度,这也是创建索引的最主要原因。
3.可以加速表和表之间的连接,特别是在实现数据的参照完整性方面有很大的意义。
4.在使用分组和排序子句进行数据检索时,同样可以显著减少查询中分组和排序的时间。
5.通过使用索引,可以在查询的过程中,使用优化隐藏器,提高系统的性能。
4)建立索引的缺点
1.创建索引和维护索引要耗费时间,这种时间随着数据量的增加而增加。
2.索引需要占物理空间,除了数据表占数据空间之外,每一个索引还要占一定的物理空间,如果要建立聚簇索引,那么需要的空间就会更大。
3.当对表中的数据进行增加、删除和修改的时候,索引也要动态的维护,这样就降低了数据的维护速度。
5)在哪些列上建立索引?
1.在经常需要搜索的列上创建索引,可以加快搜索的速度。
2.在作为主键的列上创建索引,强制该列的唯一性和组织表中数据的排列顺序。
3.在经常用在连接的列上创建索引,这些列主要是一些外键,可以加快连接的速度。
4.把经常需要根据范围进行索引的列上创建索引,因为索引已经排序,其指定的范围是连续的。
5.在经常使用在where的子句汇总的列上创建索引,加快条件的判断速度。
6)在哪些列上不应该建立索引?
1.对于那些在查询中很少使用的列不应该创建索引。
2.对于那些只有很少数据值的列也不应该创建索引。
3.对于那些定义为text和bit等数据类型的列不应该创建索引。
4.当修改操作远远大于检索操作时,不应该创建索引。
五、视图
视图是从一个或几个基本表导出的表。它与基本表不同,是一个虚表。数据库中只存放视图的定义,而不存放视图对应的数据,这些数据仍存放在原来的基本表中。所以基本表中的数据发生变化,从视图查询出的数据也就随之改变了。从这个意义上说,视图就像一个窗口,透过它可以看到数据库中自己感兴趣的数据以及变化。
六、锁
1)共享锁(S锁):
如果事务T对数据A加上共享锁后,则其他事务只能对A再加共享锁,不能加排他锁。获准共享锁的事务只能读数据,不能修改数据。
2)排他锁(X锁):
如果事务T对数据A加上排他锁后,则其他事务不能再对A加任任何类型的封锁。获准排他锁的事务既能读数据,又能修改数据。
七、SQL语句
1、数据定义
1)定义基本表
create table <表名> (<列名><数据类型>[<列级完整性约束>]
[{,<列名><数据类型>[<列级完整性约束>]}]
……
[{, [<表级完整性约束>]}]--建立学生表Student
CREATE TABLE Student
(
Sno char(5) primary key, /*设置主键*/
Sname char(20), /*sname取唯一值*/
Ssex char(2),
Sage smallint, /*smallint:4字节整数/2字节整数,8字节/4字节,存放货币类型,值为-2^63~2^63-1*/
Sdept char(15)
)
--建立课程表Course
CREATE TABLE Course
(
Cno char(5) primary key, /*设置主键*/
Cname char(20),
Cpno char(4),
Ccredit smallint, /*smallint:4字节整数/2字节整数,8字节/4字节,存放货币类型,值为-2^63~2^63-1*/
) 其他完整性约束
not null:该属性不允许空值。
nuique:可以为空值,但不允许有重复值。
check(P):关系中所有元组必须满足P 。
2)修改基本表
一般格式如下:
ALTER TABLE <表名>
[ADD <新列名> <数据类型>[完整性约束]]
[DROP <完整性约束>]
[MODIFY COLUMN <列名><数据类型>]
--在student表中增加入学时间
alter table Student
add s_entrance datetime /*datetime为日期类型*/
--修改student表中的sage数据类型
alter table Student
alter column sage int当某个基本表不再需要时,可以使用DROP TABLE语句删除它。一般格式如下:
DROP TABLE <表名> [RESTRICT| CASCADE];若选择CASCADE,则该表的删除没有限制条件。在删除该表的同时,相关的依赖条件,如视图,都将一起被删除。
2、数据查询
数据库查询是数据库的核心操作。其一般格式如下:
SELECT [ALL|DISTINCE] <目标表达式> [,<目标表达式>]…
FROM <表名或者视图名> [,<表名或视图名>]…
[WHERE <条件表达式>]
[GROUP BY <列名1> [HAVING <条件表达式>]]
[ORDER BY <列名2> [ASC|DESC]];语法:
SELECT 列名1,列名2 FROM 表名 WHERE 列名1 运算符 值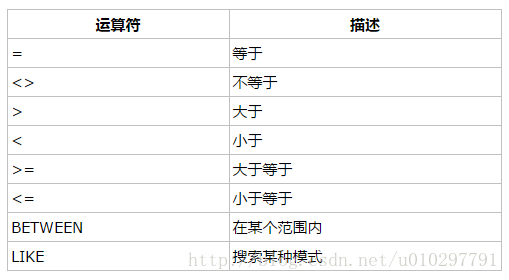
(1)查询全体学生的姓名、学号、所在系
SELECT Sname, Sno, Sdept FROM Student; 结果表中的列的顺序与基表中不同,是按查询要求,先列出姓名属性,然后再列学号属性和所在系属性。
(2)查询计算机系全体学生的名单
SELECT Sname FROM Student WHERE Sdept = '计算机系'; SELECT Sname, Sdept, Sage FROM Student WHERE Sage BETWEEN 20 AND 23; SELECT Sname, Sdept, Sage FROM Student WHERE Sage NOT BETWEEN 20 AND 23; SELECT Sname, Ssex FROM Student
WHERE Sdept NOT IN ('信息系', '数学系', '计算机系'); 谓词LIKE可以用来进行字符串的匹配。其一般语法格式如下:
[NOT] LIKE '<匹配串>'
其含义是查找指定的属性列值与<匹配串>相匹配的元组。<匹配串>可以是一个完整的字符串,也可以含有以下通配符。
- %(百分号) 代表任意长度(长度可以为0)的字符串。
- _(下横线) 代表任意单个字符。
- [ ]:匹配[ ]中的任意一个字符。
- [^]:不匹配[ ]中的任意一个字符。
(1)查所有姓林的学生的姓名、学号和性别
SELECT Sname, Sno, Ssex FROM Student WHERE Sname LIKE '林%'; SELECT Sname, Sno FROM Student WHERE Sname LIKE '__[大小]%'; SELECT Sname, Sno, Ssex FROM Student WHERE Sname NOT LIKE '刘%'; SELECT * FROM Student WHERE Sno LIKE ‘%[^235]’;对查询的结果按照一个或多个属性的升序或降序排列,默认值为升序。

例如:
(1)查询学生信息表的学号、姓名、年龄,并按Age升序排列
SELECT ID,Name,Age FROM Students ORDER BY Age ASCSELECT ID,Name,Age FROM Students ORDER BY Age DESC
COUNT([DISTINCT|ALL] *) 统计元组个数
COUNT([DISTINCT|ALL] <列名>) 统计一列中值的个数
SUM([DISTINCT|ALL] <列名>) 计算一列值的总和(此列必须是数值型)
AVG([DISTINCT|ALL] <列名>) 计算一列值的平均值(此列必须是数值型)
MAX([DISTINCT|ALL] <列名>) 求一列值中的最大值
MIN([DISTINCT|ALL] <列名>) 求一列值中的最小值 (1)查询学生总人数
SELECT COUNT(*) FROM Student; SELECT COUNT(DISTINCT Sno) FROM SC; (3)计算1号课程的学生平均成绩
SELECT AVG(Grade) FROM SC WHERE Cno='1'; SELECT MAX(Grade) FROM SC WHERE Cno='1'; GROUP BY子句根据一个或多个属性的值来对元组进行分组,值相等的为一组。
对查询结果分组的目的是为了细化聚集函数的作用对象。如果未对查询结果分组,集函数将作用于整个查询结果,即整个查询结果只有一个函数值。否则,集函数将作用于每一个组,即每一组都有一个函数值。
例如:
(1)查询各个课程号与相应的选课人数
SELECT Cno, COUNT(Sno) FROM SC GROUP BY Cno; (2)查询信息系选修了3门以上课程的学生的学号
SELECT Sno FROM SC WHERE Sdept=‘信息系’ GROUP BY Sno HAVING COUNT(*)>3;