之前介绍了CryptDB中元数据管理相关的类,以及这些类在MySQL中的存储格式。本文介绍这些元数据是什么时候创建的,在什么时候通过什么方式写入数据库,在什么时候被读取,以及元数据在什么地方被使用。
初始化与元数据读取
SchemaInfo 与 SchemaCache:
上一篇文章介绍了从DatabaseMeta往下的层次化结构,用来表示元数据。实际上,还有上面这两个结构也是元数据的存储有关。其中SchemaInfo在DatabaseMeta的上一层,其继承结构如下:
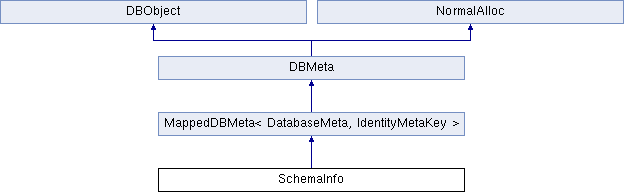
与上一篇文章介绍的类似,SchemaInfo继承了MappedDBMeta,通过Key-Value的形式保存了当前CryptDB中创建了的所有数据库信息。而SchemaCache则是对SchemaInfo进行简单的封装,其主要成员定义如下:
class SchemaCache {
public:
....
private:
mutable std::shared_ptr schema;
//设这stale状态
mutable bool no_loads;
//随机id
const unsigned int id;
};
我们知道,在CryptDB中,元数据是存储在本地的embedded MySQL中的。在初始化的过程中,如果这些元数据相关的MySQL表没有被建立,首先会有一个建表的过程,建表的操作位于在第一篇文章中介绍的connect函数中。也就是,第一个用户连接进入以后,如果还没有建立这些表,就会先初始化这些表。
有了这些表以后,我们需要先有内存的数据结构来保存层次化的元数据结构。首先就是获得一个id随机的SchemaCache结构,内部包含了一个空的SchemaInfo成员。如果之前已经建立了数据库,或者数据库下已经有一些表,则需要读取embedded MySQL中的元数据,反序列化,用内存的数据结构来表示。
首先看SchemaCache的成员id:初始化的时候,会给这个cache分配一个随机的id,并且设置no_loads为true。然后会进行no_loads的检查, 发现为true,则会进入initialStaleness函数执行以下sql语句:
INSERT INTO embedded_db.generic_prefix_staleness (cache_id, stale) VALUES (2313589110, TRUE);
同时将no_loads设置为false。之后会查询stale信息,通过如下的sql语句:
SELECT stale FROM embedded_db.generic_prefix_staleness WHERE cache_id = 2313589110;
由于刚才的no_loads设置,这里根据当前cache中的随机id查出来的肯定是stale为true。由于stale为ture,则会进入loadSchemaInfo的过程。相关的示例代码如下:
//代码位于main/schema.cc
std::shared_ptr
SchemaCache::getSchema(const std::unique_ptr &conn,
const std::unique_ptr &e_conn) const {
if (true == this->no_loads) {
initialStaleness(e_conn);
this->no_loads = false;
}
if (true == lowLevelGetCurrentStaleness(e_conn, this->id)) {
this->schema =
std::shared_ptr(loadSchemaInfo(conn, e_conn));
}
return this->schema;
}
经过了这个loadSchemaInfo的过程,SchemaCache中才开始有了自己的SchemaInfo,其内部包含了和磁盘数据等价的元数据。我们来看具体的实现:
//代码位于main/rewrite_main.cc
DBMeta* loadChildren(DBMeta *const parent,const std::unique_ptr &e_conn){
auto kids = parent->fetchChildren(e_conn);
for (auto it : kids) {
loadChildren(it,e_conn);
}
return parent;
}
std::unique_ptr
loadSchemaInfo(const std::unique_ptr &conn,
const std::unique_ptr &e_conn){
loadChildren(schema.get(),e_conn);
return std::move(schema);
}
可以看到,读取SchemaInfo是一个递归调用的过程,其中loadChildren函数的第一个参数是一个DBMeta*结构,表示当前需要读取的元数据管理类, 第二个参数用于访问底层的embedded数据库读取序列化以后的数据。其基本逻辑是,对于parent,首先通过fetchChildren函数读取所有的kids,并且将读取上来的kids加入到自己内部的map结构中,然后遍历kids,对每个kid递归调用loadChildren来完成所有的数据读取。
fetchChildren最早定义的MappedDBMeta中,其内部先定义了lambda表达式deserialize,该lambda表达式能用于完成反序列化以及添加类到map。 然后调用doFetchChildren函数, 内部首先读取数据库中的数据,然后调用之前定义的deserialize来完成反序列化和添加的功能,具体代码如下:
template
std::vector
MappedDBMeta::fetchChildren(const std::unique_ptr &e_conn){
std::function
deserialize =
[this] (const std::string &key, const std::string &serial,
const std::string &id) {
const std::unique_ptr
meta_key(AbstractMetaKey::factory(key));
auto dChild = ChildType::deserialize;
std::unique_ptr
new_old_meta(dChild(atoi(id.c_str()), serial));
this->addChild(*meta_key, std::move(new_old_meta));
return this->getChild(*meta_key);
};
return DBMeta::doFetchChildren(e_conn, deserialize);
}
我们继续看doFetchChildren函数的实现:
std::vector
DBMeta::doFetchChildren(const std::unique_ptr &e_conn,
std::function
deserialHandler) {
const std::string table_name = MetaData::Table::metaObject();
// Now that we know the table exists, SELECT the data we want.
std::vector out_vec;
std::unique_ptr db_res;
//this is the id of the current class.
const std::string parent_id = std::to_string(this->getDatabaseID());
const std::string serials_query =
" SELECT " + table_name + ".serial_object,"
" " + table_name + ".serial_key,"
" " + table_name + ".id"
" FROM " + table_name +
" WHERE " + table_name + ".parent_id"
" = " + parent_id + ";";
//all the metadata are fetched here.
TEST_TextMessageError(e_conn->execute(serials_query, &db_res),
"doFetchChildren query failed");
MYSQL_ROW row;
while ((row = mysql_fetch_row(db_res->n))) {
unsigned long * const l = mysql_fetch_lengths(db_res->n);
assert(l != NULL);
const std::string child_serial_object(row[0], l[0]);
const std::string child_key(row[1], l[1]);
const std::string child_id(row[2], l[2]);
DBMeta *const new_old_meta =
deserialHandler(child_key, child_serial_object, child_id);
out_vec.push_back(new_old_meta);
}
return out_vec;
}
可以看到,其首先获得parent_id,然后根据parent_id把当前parent对应的children行全部取出来,并且对每一行数据使用刚才定义的labmda函数进行反序列化处理,并且最后又以vector的形式把所有的children返回。这个时候便重新回到了loadChildren函数中,对于这个返回的vector类型children,里面的每一个元素会被遍历,对于每个元素,都采用刚才介绍的loadChildren函数来填充其内部的map。需要注意的是,和读取过程类似,对于onioneMeta,由于其内部通过vector来保存children,而不是用map,所以其fetchChindlren的定义也不同,如下:
std::vector
OnionMeta::fetchChildren(const std::unique_ptr &e_conn) {
std::function
deserialHelper =
[this] (const std::string &key, const std::string &serial,
const std::string &id) -> EncLayer * {
const std::unique_ptr
meta_key(AbstractMetaKey::factory(key));
const unsigned int index = meta_key->getValue();
if (index >= this->layers.size()) {
this->layers.resize(index + 1);
}
std::unique_ptr
layer(EncLayerFactory::deserializeLayer(atoi(id.c_str()),
serial));
this->layers[index] = std::move(layer);
return this->layers[index].get();
};
return DBMeta::doFetchChildren(e_conn, deserialHelper);
}
可以看到,其主要的区别在于,使用的反序列化处理函数deserialHelper不同,对于上层的deserialHelper,其内部逻辑是在map中添加新的元数据管理类,而对于OnionMeta,则是在vector中添加元数据管理类。
另外,由于EncLayer是最底层的类,作为递归终止条件,其fetchChildren的实现如下:
std::vector
fetchChildren(const std::unique_ptr &e_conn) {
return std::vector();
}
读取过程小结
通过上面的分析,我们就知道了元数据在内存中的存储方式。其示意图如下:
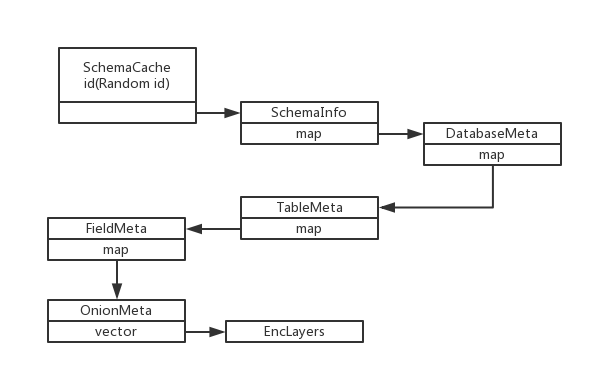
初始化的时候,最上层的schemaCache获得一个随机的id,并保存了一个空的SchemaInfo结构。之后,其通过上面的loadSchemaInfo机制来填充SchemaInfo里面的map。在SchemInfo这层,map中保存了所有的数据库名字以及对应的DatabaseMeta,SchemaInfo的id固定是0,所以在doFetchChildren函数中,以parent_id=0作为条件,可以获得所有序列化以后的DatabaseMeta,并且插入到SchemaInfo中。然后,所有的DatabaseMeta作为vector返回,依次再次用loadChildren函数递归处理。递归的终止条件是EncLayer,因为这个已经是最底层的类了。
为了理解这个递归处理的过程,我们给出以下例子:我们假设在CryptDB中有两个数据库db1和db2,每个数据库中分别有一个表student。则初始化的过程如下:
1) 初始化一个schemaCache,有一个随机的id,内部有空的schemaInfo,并且通过no_loads和stale的机制,出发loadSchemaInfo函数的调用
2) 调用loadSchemaInfo函数,内部使用loadChildren的递归调用,首先在schemaInfo中插入db1和db2对应的DatabaseMeta,并且返回一个DatabaseMeta的vector,里面有两个元素
3) 递归对vector中的第一个DatabaseMeta处理,在其内部插入student表对应的TableMeta,返回一个TableMeta的vector
4) 递归对vector中的第一个TableMeta进行处理,在其内部插入表对应的FieldMeta,返回一个FieldMeta的vector
5) 递归对vector中的第一个FieldMeta进行处理,内部插入Field对应的OnionMeta,返回一个OnionMeta的vector
6) 递归对vector中的第一个OnionMeta进行处理,内存插入对应的EncLayers,返回一个Enclayers的vector
7) 递归对vector中的第一个EncLayers进行出来,什么也不做,返回一个空的vector,这样递归开始重新进入上一层
8) .....
9) 经过一系列的处理,假设从上面步骤3)开始的第一次递归处理结束了,那么schemaInfo中的map里面已经有了两个DatabaseMeta,并且第一个DatabaseMeta内部已经有了TableMeta,TableMeta内部有了FieldMeta,以此类推。 而此时第二个DatabaseMeta还是空的,所以继续步骤3)中的循环处理,递归处理vector中的第二个DatabaseMeta继续3-8中的过程。
经过以上的过程,内存的元数据和磁盘中的数据就一致了。如果磁盘中的数据因为元数据的写入而发生变化,则会在当前的schemaCache对应的行中再次设置stale值为true。每次命令处理的时候,会去查这个stale的值,如果发现为true,则重复执行上面的loadSchema操作来更新内存的元数据。所以SchemaCache中的随机id,就是为了记录这个stale的情况,从而可以决定要不要使用上面的元数据导入函数来读取磁盘中的元数据。
接下来介绍什么时候会往磁盘中写入元数据,以及写入的机制是怎么样的。
元数据写入
从上面的分析可以看到,mysql-proxy端的元数据,主要存储了从database到EncLayer的一个层次化结构。所以,元数据写入对应了两个常见的语句:CREATE DATABASE 和CREATE TABLE。前者会导致写入一行DatabaseMeta数据,后者则会导致写入多行数据,包括一行TableMeta以及下层的多个FieldMeta,OnionMeta,和EncLayer。
我们首先来考虑CREATE DATABASE 语句造成的写入:
delta的创建
std::unique_ptr dm(new DatabaseMeta());
a.deltas.push_back(std::unique_ptr(
new CreateDelta(std::move(dm), a.getSchema(),
IdentityMetaKey(dbname))));
return new DDLQueryExecutor(*copyWithTHD(lex), std::move(a.deltas));
在执行CREATE DATABASE语句的时候,会新建一个空的DatabaseMeta用于代表这个新增加的数据库,然后以此为基础建立一个CreateDelta结构。Delta系列的类用于表示元数据的变化,其相关类的继承结构如下图所示:

Delta的相关定义如下:
class Delta {
public:
Delta(const DBMeta &parent_meta) : parent_meta(parent_meta) {}
virtual bool apply(const std::unique_ptr &e_conn,
TableType table_type) = 0;
protected:
const DBMeta &parent_meta;
};
其内部有一个parent_meta。当新添加或删除元数据的时候,这个元数据类有一个上层的类,就是parent_meta。比如对于要添加的DatabaseMeta来说,上层的类就是SchemaInfo。添加了DatabaseMeta以后,还需要同时保存一个信息:这个DatabaseMeta对应的数据库名字。所以,在下层的AbstractCreateDelta就对Delta进行了如下的扩展:
template
class AbstractCreateDelta : public Delta {
public:
AbstractCreateDelta(const DBMeta &parent_meta,
const KeyType &key)
: Delta(parent_meta), key(key) {}
protected:
const KeyType key;
};
最后来看CreateDelta的定义:
class CreateDelta : public AbstractCreateDelta {
public:
CreateDelta(std::unique_ptr &&meta,
const DBMeta &parent_meta,
IdentityMetaKey key)
: AbstractCreateDelta(parent_meta, key), meta(std::move(meta)) {}
bool apply(const std::unique_ptr &e_conn,
TableType table_type);
std::map & get_id_cache(){return id_cache;}
private:
const std::unique_ptr meta;
std::map id_cache;
};
可以看到,其添加了一个新的成员:meta。用来表示当前的元数据类。这样,我们就可以理解下面语句的含义了:
std::unique_ptr( new CreateDelta(std::move(dm), a.getSchema(),IdentityMetaKey(dbname)));
其表示新添加了Delta记录:增加了一个DatabaseMeta,其对应的数据库名是dbname,用IdentifyMetaKey来进行保存。其上层的类是SchemaInfo(a.getSchema调用就是返回SchemaInfo)。
已经有了内存的databaseMeta,这样就有了内存数据和磁盘数据的不一致,就需要一个写入磁盘来保持同步的过程。这个动作通过如下的函数来实现:
bool
writeDeltas(const std::unique_ptr &e_conn,
const std::vector > &deltas,
Delta::TableType table_type){
for (const auto &it : deltas) {
RFIF(it->apply(e_conn, table_type));
}
return true;
}
可以看到,其是通过对delta调用apply函数来实现写入数据库的,具体apply函数的实现如下:
bool CreateDelta::apply(const std::unique_ptr &e_conn,
Delta::TableType table_type){
//获取数据库表名
const std::string &table_name = tableNameFromType(table_type);
//写入
const bool b =
create_delta_helper(this,e_conn,table_type,table_name,
*meta.get(), parent_meta, key, parent_meta.getDatabaseID());
return b;
}
在create_delta_helper函数中,也是一个递归调用的过程。其主要代码如下:
//
static
bool create_delta_helper(CreateDelta* this_is, const std::unique_ptr &e_conn,
Delta::TableType table_type, std::string table_name,
const DBMeta &meta_me, const DBMeta &parent,
const AbstractMetaKey &meta_me_key, const unsigned int parent_id) {
const std::string &child_serial = meta_me.serialize(parent);
const std::string &serial_key = meta_me_key.getSerial();
//用于插入元数据的SQL语句
const std::string &query =
" INSERT INTO " + table_name +
" (serial_object, serial_key, parent_id, id) VALUES ("
" '" + esc_child_serial + "',"
" '" + esc_serial_key + "',"
" " + std::to_string(parent_id) + ","
" " + std::to_string(old_object_id.get()) + ");";
//执行SQL语句插入数据
e_conn->execute(query);
std::function localCreateHandler =
[&meta_me, object_id, this_is,&e_conn,table_type,table_name]
(const DBMeta &child){
return create_delta_helper(this_is,e_conn, table_type, table_name,
child, meta_me, meta_me.getKey(child), object_id);
};
//对于当前DBMeta的children,执行同样的操作
return meta_me.applyToChildren(localCreateHandler);
}
在一层调用中, meta_me和meta_me_key分别表示当前需要写入的DBMeta类,以及其对应的key。对于本例来说,就是DatabaseMeta以及对应的IdentifyMetaKey。这两个类需要被序列化,并且写入数据库。parent_id也需要被写入数据库。至于当前DBMeta本身的id,则是通过MySQL的auto increment结合last_insert_id()来得到的。
下面就是最后执行写入操作的SQL语句:
//由于auto increment,实际写入的id是1
INSERT INTO embedded_db.generic_prefix_BleedingMetaObject (serial_object, serial_key, parent_id, id) VALUES ( 'Serialize to associate database name with DatabaseMeta', 'db', 0, 0);
INSERT INTO embedded_db.generic_prefix_MetaObject (serial_object, serial_key, parent_id, id) VALUES ( 'Serialize to associate database name with DatabaseMeta', 'temp', 0, 1);
CryptDB建立了两个同样格式的元数据表,在不同的SQL执行阶段写两个不同的元数据表,最后保证这两个表中的数据是一致的。
然后来看CREATE TABLE语句造成的变化:
// ddl_handler.cc
AbstractQueryExecutor *
CreateTableHandler::rewriteAndUpdate(Analysis &a, LEX *lex, const Preamble &pre) const{
//创建Tablemeta,里面是空的
std::unique_ptr tm(new TableMeta(true, true));
//createAndRewriteField函数中遍历table的field并且为每个field创建FieldMeta,然后添加到TableMeta的map中
...
...
//创建CreateDelta进行记录
a.deltas.push_back(std::unique_ptr(
new CreateDelta(std::move(tm),
a.getDatabaseMeta(pre.dbname),
IdentityMetaKey(pre.table))));
...
...
}
FieldMeta::FieldMeta(){
//在上面介绍的FieldMeta的构造函数中,调用onion_layout,构造
//对应的OnionMeta并且添加到对应的FieldMeta的map中
init_onions_layout();
}
OnionMeta::OnionMeta{
//调用EncLayerFactory::encLayer函数来构造洋葱的加密层,添加到onionMeta的vector中
}
CREATE TABLE语句的处理流程如上所示,我们只截取和本文相关的部分示意代码,介绍调用了哪些函数,以及这些函数分别做什么用。 需要注意的有以下几点:
- 对于CREATE TABLE语句,首先会调用TableMeta的构造函数,构造一个空的TableMeta
- 对于table中的Field,则分别调用FieldMeta的构造函数,构造多个FieldMeta,并添加到TableMeta的map中
- FieldMeta的构造函数内,已经有OnionMeta的构造和添加的代码。而OnionMeta的构造函数内也包含了EncLayer的构造和添加
- 所以,在FieldMeta的层次来看,构造自身并且添加到TableMeta以后,整个层次化的元数据管理类就全部构造完成
- 最后添加的CreateDelta只要对table这层来做就可以,不需要对每层的类都添加delta
这样,通过上面的过程,我们就已经建立了内存中的从TableMeta到EncLayer的层次化结构。并且通过delta记录这个TableMeta,新的table的名字,以及其上层的DatabaseMeta。
在元数据写入的时候,依然是使用apply函数,递归做处理。我们以一个例子来进行说明:
假设我们执行这样的语句:CREATE TABLE student (id integer)并且为这个列id设置两个洋葱DET和OPE,其中DET包含了两个层det和rnd,OPE包含两个层ope和rnd。则其构造和写入的顺序如下:
首先是内存数据结构建立阶段:
1)为student构造TableMeta
2)为id构造FieldMeta
3)FieldMeta内部构造两个onionMeta,分别代表DET和OPE,而onionMeta构造的时候,也各自初始化了两个洋葱层
4)将FieldMeta添加到TableMeta的内部map中
5)构造delta来记录这个元数据的变化
然后是数据写入磁盘阶段:
1)写入TableMeta
2)写入id对应的FieldMeta
3)写入DET对应的OnionMeta
4)写入DET中的第一个Enclayer
5)写入DET中的第二个Enclayer
6)写入OPE中的第一个EncLayer
7)写入OPE中的第二个EncLayer
元数据使用
元数据的使用主要体现在层次化的加密和解密上。从DatabaseMeta开始的往下到OnionMeta的结构都是起辅助作用,是为了定位最后实际产生作用的EncLayer。得到了EncLayer以后,就可以调用其加解密相关的函数,来实现洋葱加密和解密功能,相关代码如下。
层次加密:
Item *
encrypt_item_layers(const Item &i, onion o, const OnionMeta &om,
const Analysis &a, uint64_t IV) {
const auto &enc_layers = a.getEncLayers(om);
const Item *enc = &i;
Item *new_enc = NULL;
for (const auto &it : enc_layers) {
new_enc = it->encrypt(*enc, IV);
enc = new_enc;
}
return new_enc;
}
层次解密:
Item *
decrypt_item_layers(const Item &i, const FieldMeta *const fm, onion o,
uint64_t IV) {
const Item *dec = &i;
const OnionMeta *const om = fm->getOnionMeta(o);
const auto &enc_layers = om->getLayers();
for (auto it = enc_layers.rbegin(); it != enc_layers.rend(); ++it) {
out_i = (*it)->decrypt(*dec, IV);
assert(out_i);
dec = out_i;
}
return out_i;
}
可以看到,加解密操作都是针对Item类型来完成,并且都是需要获得EncLayer,而为了获得正确的EncLayer,则需要上述的层次化数据结构。
总结
在CryptDB中,为了完成层次化的加密和解密的功能,需要构造加密层相关的类,以及从database开始的层次化结构来对加密层进行管理。本文介绍了这些元数据从磁盘中载入到内存以及从内存中写入磁盘的过程中涉及到的关键类和函数。本文涉及的代码细节比较多, 重点需要关注的是内存的数据结构表示,loadSchemInfo,stale查询机制以及delta的记录与写入。具体这些机制怎么和实际的SQL执行结合在一起,将在后续的文章中介绍,也可以看参考文献的链接,里面包含了我正在加注释的源码。
下篇文章将介绍加密算法,以及加密算法和元数据类的联系方式。
相关文献
https://github.com/yiwenshao/Practical-Cryptdb
原始链接:yiwenshao.github.io/2018/03/19/CryptDB代码分析4-加密元数据读写/
文章作者:Yiwen Shao
许可协议: Attribution-NonCommercial 4.0
转载请保留以上信息, 谢谢!