Scrapy-splash 渲染网页(windows10)
Scrapy-splash 渲染网页
scrapy爬虫框架没有提供页面js渲染服务,所以我们获取不到部分HTML网页的数据信息,我们可以通过一个渲染引擎来为我们提供渲染服务将网页所有信息均呈现出来-----Splash渲染引擎:
1、Splash渲染引擎工作简介:
Splash是为Scrapy爬虫框架提供渲染Javascript代码的引擎,它具备如下功能:
(1)为用户返回渲染好的html页面;
(2)并发渲染多个页面;
(3)关闭图片加载,加速渲染;
(4)执行用户自定义的js代码;
(5)执行用户自定义的lua脚步,类似于无界面浏览器phantomjs;
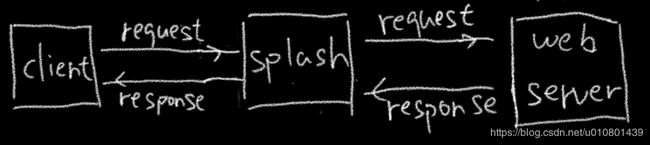
Splash流程:
(1)用户通过中间件splash向webserver发起请求;
(2)当webserver返回数据给splash;
(3)splash对返回数据进行渲染后输出给用户。
2、安装与使用splash:
安装步骤:
(1)安装scrapy-splash模块:
pip install scrapy-splash(2)安装docker:
scrapy-splash使用的是Splash HTTP API, 所以需要一个splash instance,一般采用docker运行splash,所以需要安装docker.
本博客暂时只针对window系统安装,docker下载链接地址:http://mirrors.aliyun.com/docker-toolbox/windows/docker-toolbox/
1、docker安装前期准备
- 打开任务管理器,检查自身电脑是否开启了虚拟化功能
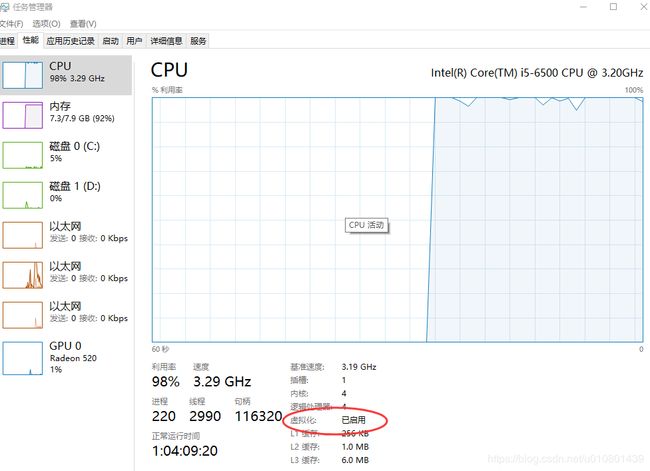
- Docker 有专门的 Win10 专业版系统的安装包,需要开启Hyper-V。
a.右键windows->应用和功能
b. 选中程序和功能

c.选中启动或关闭Windows功能
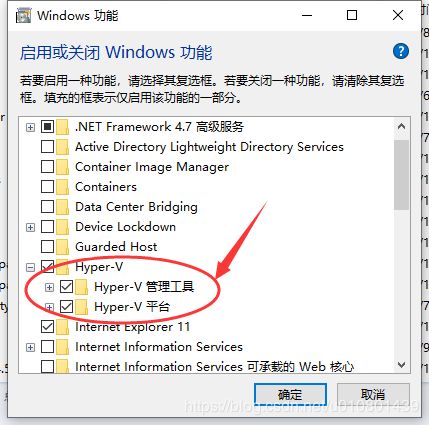
d.勾选Hyper-V所有内容
2、Docker安装
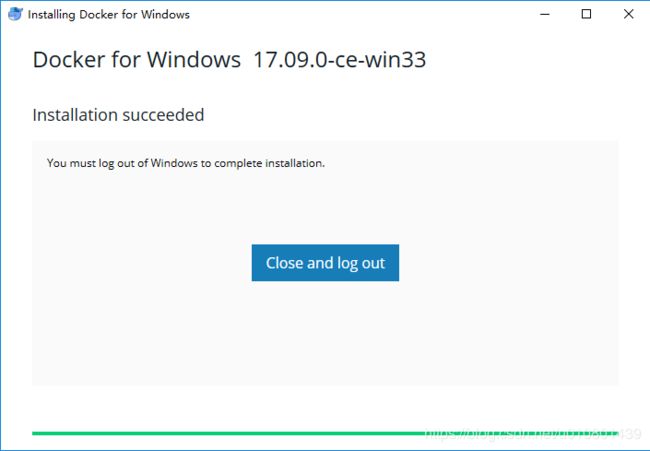
双击下载的 Docker for Windows Installer 安装文件,一路 Next,点击 Finish 完成安装。

a.双击.exe安装
b. 安装完成docker,利用cmd进行检验

利用管理员模式输入:docker –version
docker --version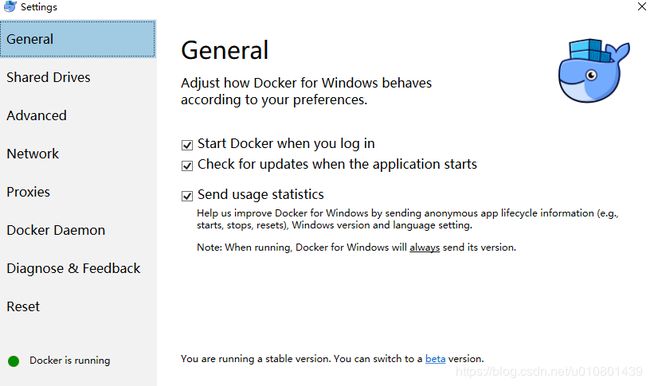
c.左下角显示Docker is running 便可以开始使用
d.启动docker for splash
在管理员命令行中输入:
>docker pull scrapinghub/splash
>docker run -p 8050:8050 scrapinghub/splash
3、配置scrapy工程文件:
a.配置setting文件
SPLASH_URL = 'http://localhost:8050'
DOWNLOADER_MIDDLEWARES = {
'scrapy_splash.SplashCookiesMiddleware': 723,
'scrapy_splash.SplashMiddleware': 725,
'scrapy.downloadermiddlewares.httpcompression.HttpCompressionMiddleware': 810,
}
SPIDER_MIDDLEWARES = {
'scrapy_splash.SplashDeduplicateArgsMiddleware': 100,
}
DUPEFILTER_CLASS = 'scrapy_splash.SplashAwareDupeFilter'
HTTPCACHE_STORAGE = 'scrapy_splash.SplashAwareFSCacheStorage'
b.在创建的spider文件中调用SplashRequest():
def query_list(self, response):
jxsp_url = response.xpath('//div[@class="rdzx w780"]//div[@class="pic"]//h4//a/@href').extract()
jxsp_name = response.xpath('//div[@class="rdzx w780"]//div[@class="pic"]//h4//a/text()').extract()
new_dict = Info.name_to_crawl(self.session, jxsp_name)
if new_dict:
for key in new_dict:
yield SplashRequest(
url=jxsp_url[key],
callback=self.get_base_info,
meta={
'jxsp_name': jxsp_name[key],
},
args={'wait': 1.0}
)
else:
print('没有需要补充的内容') 注意直接修改yield scrapy.Request() 方法为 yield SplashRequest()