flume 监控目录文件,将内容定时输入到hdfs上
3.3.1 编写脚本文件:tohdfs.conf
#定义agent名, source、channel、sink的名称
a4.sources = r1
a4.channels = c1
a4.sinks = k1
#具体定义source
a4.sources.r1.type = spooldir
a4.sources.r1.spoolDir = /opt/rh
#具体定义channel
a4.channels.c1.type = memory
a4.channels.c1.capacity = 10000
a4.channels.c1.transactionCapacity = 100
#定义拦截器,为消息添加时间戳
a4.sources.r1.interceptors = i1
a4.sources.r1.interceptors.i1.type = org.apache.flume.interceptor.TimestampInterceptor$Builder
#具体定义sink
a4.sinks.k1.type = hdfs
#flume这个目录会自动创建
a4.sinks.k1.hdfs.path = hdfs://meboth-master:9000/flume/%Y%m%d
a4.sinks.k1.hdfs.filePrefix = events-
a4.sinks.k1.hdfs.fileType = DataStream
#不按照条数生成文件
a4.sinks.k1.hdfs.rollCount = 0
#HDFS上的文件达到128M时生成一个文件
a4.sinks.k1.hdfs.rollSize = 134217728
#HDFS上的文件达到60秒生成一个文件
a4.sinks.k1.hdfs.rollInterval = 60
#组装source、channel、sink
a4.sources.r1.channels = c1
a4.sinks.k1.channel = c1
3.3.2 执行命令
[root@meboth-master flume-1.9.0]# bin/flume-ng agent -c ./execonfbyjurf -f ./execonfbyjurf/tohdfs.conf -n a4 -Dflume.root.logger=INFO,console
注意:代理的名称要和配置文件设置的代理名称配置一致。如本案例的代理为a4,前面几个为a1,一定配置一致。
3.3.3 将文件扔到指定的目录
[root@meboth-master rh]# cp /opt/tb_user.java .
[root@meboth-master rh]# ls
say.txt.COMPLETED tb_user.java.COMPLETED
[root@meboth-master rh]#
3.3.4 查看执行命令窗口的日志

3.3.5 查看hdfs上的结果
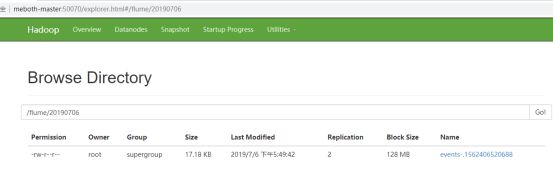
3.3.6 下载查看内容
打开文件的部分内容截图:
本次案例使用flume-1.9版本操作比较顺利,如果执行命令报错,参考传智介绍的解决方法:
Flume补充hadoop的jar包:
Hadoop-common-xxx.jar
Commons-configuration-xx.jar
Hadoop-auth-xx.jar
Hadoop-hdfs-xx.jar
当执行报错:不知道域名的时候,需要将hadooop下的core-site.xml,hdfs-site.xml拷贝到flume的conf目录下,然后再hosts文件配置:hadoop所在机器的ip与主机的映射。

详情文档见:百度网盘
