《SQL Server 2008从入门到精通》--20180704
XML查询技术
XML文档以一个纯文本的形式存在,主要用于数据存储。不但方便用户读取和使用,而且使修改和维护变得更容易。
XML数据类型
XML是SQL Server中内置的数据类型,可用于SQL语句或者作为存储过程的参数。用户可以直接在数据库中存储、查询和管理XML文件。XML数据类型还能保存整个XML文档。XML数据类型和其他数据类型不存在根本上的差别,可以把它用在任何普通SQL数据类型可以使用的地方。
示例1:创建一个XML变量并用XML填充
DECLARE @doc XML
SELECT @doc='示例2:创建XML数据类型列
CREATE TABLE t1(
column1 INT,
column2 XML,
CONSTRAINT pk_column1 PRIMARY KEY(column1));在上面的示例中,column2列是XML数据类型列。
示例3:不能将XML数据类型列设置为主键或外键
CREATE TABLE t1(
column1 INT,
column2 XML,
CONSTRAINT pk_column1 PRIMARY KEY(column2));执行上面的代码,报错如下:
消息1919,级别16,状态1,第1 行
表’t1’ 中的列’column2’ 的类型不能用作索引中的键列。
消息1750,级别16,状态0,第1 行
无法创建约束。请参阅前面的错误消息。
XML数据类型的使用限制
只有STRING数据类型才能转换成XML。
XML列不能应用于GROUP BY语句中
XML数据类型存储的数据不能超过2GB
XML数据类型字段不能被设置成主键或者外键或称为其一部分。
Sql_variant数据类型字段的使用不能把XML数据类型作为种子类型。
XML列不能指定为唯一的。
COLLATE子句不能被使用在XML列上。
存储在数据库中的XML仅支持128级的层次。
表中最对只能拥有32个XML列。
XML列不能加入到规则中。
唯一可应用于XML列的内置标量函数是ISNULL和COALESCE。
具有XML数据类型列的表不能有一个超过15列的主键。
类型化的XML和非类型化的XML
可以创建xml类型的变量,参数和列,或者将XML架构集合和xml类型的变量、参数或列关联,这种情况下,xml数据类型实例称之为类型化xml实例。否则XML实例称为非类型化的实例。
XML数据类型方法
XML数据类型共有5种方法
query():执行一个XML查询并返回查询结果(返回一个XML数据类型)。
示例4:
DECLARE @xmlDoc XML--声明XML类型的变量@xmlDoc
SET @xmlDoc='<students>
<class name="数学" NO="8501">
<student>
<name>李林name>
<sex>男sex>
<age>16age>
<address>江苏address>
student>
class>
students>'--将XML实例分配给变量@xmlDoc
SELECT @xmlDoc.query('/students/class/student') AS test
--用query()查询@xmlDoc变量实例中标签<student>的子元素查询结果如图所示
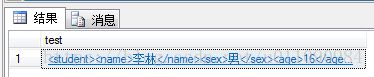
点击查询结果
如想查询标签的子元素,可以将上面SQL语句中query()方法中的参数换成’/students/class/student/name’即可,查询结果如图所示
![]()
Exist():执行一个XML查询,如果有结果的话返回1。
示例5:利用上述的XML示例对exsit()方法做一个应用
DECLARE @addr XML--声明一个XML类型变量@addr
SET @addr='/students/class/student'
SELECT @addr.exist('/students/class="江苏"') AS 返回值结果如图所示

注:exsit()方法的参数不必做精确定位
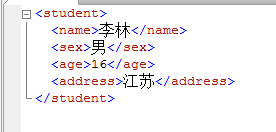
Value():计算一个查询并从XML中返回一个简单的值(只能返回单个值,且该值为非XML数据类型)。
Value()方法有2个参数XQuery和SQLType,XQuery参数表示命令要从XML实例内部查询数据的具体位置,SQLType参数表示value()方法返回的值的首选数据类型。
示例6
DECLARE @xmlDoc XML--声明XML类型的变量@xmlDoc
DECLARE @classID INT--声明INT类型的变量@classID
SET @xmlDoc='<students>
<class name="数学" NO="8501">
<student>
<name>李林name>
<sex>男sex>
<age>16age>
<address>江苏address>
student>
class>
students>'--将XML实例分配给变量@xmlDoc
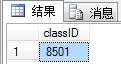
SET @[email protected]('(/students/class/@NO)[1]','INT')
--将value()方法返回值赋值给变量@classID
SELECT @classID AS classID查询结果如图所示
注:SQLType不能是XML数据类型,公共语言运行时(CLR)用户定义类型,image,text,ntext或sql_variant数据类型,但可以是用户自定义数据类型SQL。
Modify():在XML文档的适当位置执行一个修改操作。它的参数XML_DML代表一串字符串,根据此字符串表达式来更新XML文档的内容。
示例7:在@xmlDoc的实例中,元素后面插入元素
DECLARE @xmlDoc XML--声明XML类型的变量@xmlDoc
SET @xmlDoc='
李林
男
16
江苏
class>
'
SELECT @xmlDoc AS '插入节点前信息'
SET @xmlDoc.modify('insert <学历>本科 after (students/class/student/age)[1]')
SELECT @xmlDoc AS '插入节点后信息'查询结果插入节点后信息如图所示

注:modify()方法的参数中insert和其他关键字必须小写,否则会报错
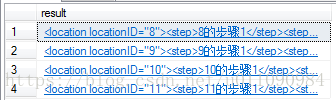
Nodes():允许把XML分解到一个表结构中。此方法将XML数据类型实例拆分为关系数据,并返回包含原始XML数据的行集。
示例8:依然用@locat参数的实例来示范
DECLARE @locat XML--声明XML变量@locat
SET @locat=
'<root>
<location locationID="8">
<step>8的步骤step>
<step>8的步骤step>
<step>8的步骤step>
location>
<location locationID="9">
<step>9的步骤step>
<step>9的步骤step>
<step>9的步骤step>
location>
<location locationID="10">
<step>10的步骤step>
<step>10的步骤step>
<step>10的步骤step>
location>
<location locationID="11">
<step>11的步骤step>
<step>11的步骤step>
<step>11的步骤step>
location>
root>'--@locat变量的实例
SELECT T.Loc.query('.') AS result
FROM @locat.nodes('/root/location') T(Loc)
GO查询结果如下图所示
XQuery简介
XQuery是一种查询语言,可以查询结构化或者半结构化的数据。SQL Server 2008中对XML数据类型提供了支持,可以存储XML文档,然后使用XQuery语言进行查询。
FOR XML子句
通过在SELECT语句中使用FOR XML子句可以把数据库表中的数据检索出来并生成XML格式。SQL Server 2008支持FOR XML的四种模式,分别是RAW模式,AUTO模式,EXPLICIT模式和PATH模式。
FOR XML RAW
将表转换成元素名称是row,属性名称为列名或者列的别名。
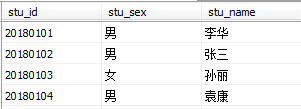
示例9:将Student表转换为XML格式(FOR XML RAW)
Student表的数据如图所示
执行语句:
SELECT * FROM Student FOR XML RAW;查询结果如图所示


FOR XML AUTO
使用表名称作为元素名称,使用列名称作为属性名称,SELECT关键字后面列的顺序用于XML文档的层次。
示例10:将Student表转换为XML格式(FOR XML AUTO)
执行语句:
SELECT * FROM Student FOR XML AUTO;查询结果如图所示
![]()

FOR XML EXPLICIT
允许用户显式地定义XML树的形状,不受AUTO模式中的种种限制。不能将FOR XML EXPLICIT直接用在SELECT子句中。
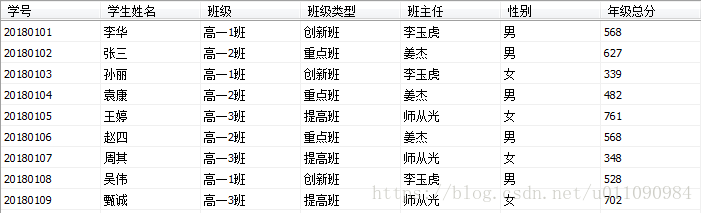
示例11:将xmlTest表转换为XML格式(FOR XML EXPLICIT)
XmlTest表的数据如图所示
SELECT DISTINCT 1 AS TAG,--指定顶级层级序号1
NULL AS PARENT,--该层级没有父级
NULL AS '班级信息!1!',
NULL AS '班级信息!2!班级',
NULL AS '班级信息!2!班级类型',
NULL AS '班级信息!2!班主任',
NULL AS '学生信息!3!学号!Element',
NULL AS '学生信息!3!学生姓名!Element',
NULL AS '学生信息!3!性别!Element',
NULL AS '学生信息!3!总分!Element'--设置所有层级元素和属性命名,暂时不对这些元素赋值
--例如在“学生信息!3!总分!Element”格式中,学生信息是元素名,3表示该元素所处层级,总分表示属性名
--Element指出生成以属性单独为一行的XML格式
UNION ALL--层级之间用UNION ALL相连
SELECT DISTINCT 2 AS TAG,--指定二级层级序号
1 AS PARENT,--父级序号是序号为1的层级
NULL,--在层级的代码中已列出了所有层级元素和属性命名,因此这里给元素和属性做赋值。这句语句对应层级代码中“NULL AS '班级信息!1!'”,说明我希望该元素作为独立成行的标签,没有赋值。
班级,--对层级中的“NULL AS '班级信息!2!班级'”赋值,将xmlTest表中的班级赋值给属性班级
班级类型,--对层级中的“NULL AS '班级信息!2!班级类型'”赋值,将xmlTest表中的班级赋值给属性班级类型
班主任,--同上
NULL,--这句语句开始对应的是层级3的属性,因此在层级的代码中不做赋值,在下面层级的代码中做赋值
NULL,
NULL,
NULL
FROM xmlTest--指出上面赋值的数据源来自于xmlTest表
UNION ALL--各个层级之间用UNION ALL连接
SELECT 3 AS TAG,--指定3级层级序号3
2 AS PARENT,--父级是序号为2的层级
NULL,--对应层级的”NULL AS '班级信息!1!'“语句,不希望它有值,所以不做赋值
NULL,--这三个NULL对应层级的各个属性,在层级的代码中已经做过赋值,因此在这里不做赋值
NULL,
NULL,
学号,--对应层级1代码中的层级3属性,在层级3代码中进行赋值
学生姓名,
性别,
年级总分
FROM xmlTest
FOR XML EXPLICIT;--将上述查询转换为XML,不能漏掉,否则结果会以表格形式显示查询结果如图所示


在结果图中我们发现,红框中3个班级信息列在一起,而所有学生都列在高一3班下,这不是我们想要的结果,我们希望每个班级对应自己的学生。那么如何解决此类问题呢,这涉及到排序。
注:如果层级中有多个数据完全重复,可以在该层级对应的代码前加DISTINCT关键字去除重复元素。
首先删除代码行末的FOR XML EXPLICIT语句,仅仅执行剩下的部分,使结果以表格形式呈现,那么结果如下

这个表格每行的顺序也代表了该表格转化为XML文档后内容显示顺序。图中层级2(TAG=2)的几行,位置都在一起,这也就是为什么层级3的所有数据都在高一3班下面了。我们需要对表格每行的顺序进行调整,使学生所在行按照xmlTest表中的数据逻辑分散在班级行之下。但是根据上面的表格发现,不管按照什么字段排序,都不可能达到效果。
正确代码如下
SELECT DISTINCT 1 AS TAG,
NULL AS PARENT,
NULL AS '班级信息!1!',
NULL AS '班级信息!2!班级',
NULL AS '班级信息!2!班级类型',
NULL AS '班级信息!2!班主任',
NULL AS '学生信息!3!学号!Element',
NULL AS '学生信息!3!学生姓名!Element',
NULL AS '学生信息!3!性别!Element',
NULL AS '学生信息!3!总分!Element'
UNION ALL
SELECT DISTINCT 2 AS TAG,
1 AS PARENT,
NULL,
班级,
班级类型,
班主任,
NULL,
NULL,
NULL,
NULL
FROM xmlTest
UNION ALL
SELECT 3 AS TAG,
2 AS PARENT,
NULL,
班级,
班级类型,
班主任,
学号,
学生姓名,
性别,
年级总分
FROM xmlTest
ORDER BY [班级信息!2!班级],[学生信息!3!学号!Element]
FOR XML EXPLICIT;对比第一次代码,我们发现上面的代码不止在行末对数据按元素属性进行了排序,还在赋值的代码中有所改动。在层级1代码中完全没有改动,因为层级1的代码作用是设置XML格式的,对数据排序没有影响。在下面几个层级的赋值部分,每个层级的代码中都对上面几个层级的元素重复赋值,这样做使结果的表格中不再有那么多属性值是NULL,可以方便排序。最后再按照元素[班级信息!2!班级]和[学生信息!3!学号!Element]排序。让我们看看结果如何。
运行上面的代码,但不运行FOR XML EXPLICIT语句,看看表格中数据内容和行顺序是否改变
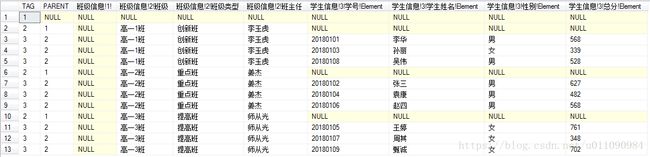
如图所示,发现行数据和学生数据的顺序显示正确。运行所有代码得到XML文档,结果如图所示
![]()
由于XML文档内容过长,不贴图了,直接复制所有XML内容展示一下。
<班级信息>
<班级信息 班级="高一1班" 班级类型="创新班" 班主任="李玉虎">
<学生信息>
<学号>20180101学号>
<学生姓名>李华学生姓名>
<性别>男性别>
<总分>5.680000000000000e+002总分>
学生信息>
<学生信息>
<学号>20180103学号>
<学生姓名>孙丽学生姓名>
<性别>女性别>
<总分>3.390000000000000e+002总分>
学生信息>
<学生信息>
<学号>20180108学号>
<学生姓名>吴伟学生姓名>
<性别>男性别>
<总分>5.280000000000000e+002总分>
学生信息>
班级信息>
<班级信息 班级="高一2班" 班级类型="重点班" 班主任="姜杰">
<学生信息>
<学号>20180102学号>
<学生姓名>张三学生姓名>
<性别>男性别>
<总分>6.270000000000000e+002总分>
学生信息>
<学生信息>
<学号>20180104学号>
<学生姓名>袁康学生姓名>
<性别>男性别>
<总分>4.820000000000000e+002总分>
学生信息>
<学生信息>
<学号>20180106学号>
<学生姓名>赵四学生姓名>
<性别>男性别>
<总分>5.680000000000000e+002总分>
学生信息>
班级信息>
<班级信息 班级="高一3班" 班级类型="提高班" 班主任="师从光">
<学生信息>
<学号>20180105学号>
<学生姓名>王婷学生姓名>
<性别>女性别>
<总分>7.610000000000000e+002总分>
学生信息>
<学生信息>
<学号>20180107学号>
<学生姓名>周其学生姓名>
<性别>女性别>
<总分>3.480000000000000e+002总分>
学生信息>
<学生信息>
<学号>20180109学号>
<学生姓名>甄诚学生姓名>
<性别>女性别>
<总分>7.020000000000000e+002总分>
学生信息>
班级信息>
班级信息>将上面的结果对比一下原始xmlTest表,看看每个班级和它下属学生的层级关系是否有误。
注:写FOR XML EXPLICIT代码要注意,层级1的代码中先设置层级结构,不要先急着赋值。在下属层级的代码中对层级1中的代码进行赋值,最好重复赋值,不然就会出现文中的排序问题。如果某个层级出现重复数据,在该层级的代码前加DISTINCT关键字。解决排序问题最好的办法是对各个层级的属性重复赋值并在末尾用ORDER BY按层级属性排序。
仔细观察上面的XML文档,发现总分属性的值是个float类型,要把它转换成int,只需要把层级3中对总分的赋值代码改成CAST(年级总分 AS int)

FOR XML PATH
PATH模式提供了一种较简单的方法来混合元素及属性。在PATH模式中,列名或列别名被作为XPATH表达式来处理,这些表达式指定了如何将值映射到XML中。默认情况下,PATH模式为每一样自动生成元素,用户也可以自定义元素名称。
没有名称的列
下面介绍一种简单的FOR XML PATH应用方式
SELECT 2+3 FOR XML PATH;--将2+3的值转换成xml格式查询结果如图所示
![]()
注:如果提供了空字符串FOR XML PATH(‘’)则不会生成任何元素。
SELECT 2+3 FOR XML PATH('');--将2+3的值转换成xml格式并去掉|
查询结果如图所示
![]()
示例12:利用xmlTest表和mainTeacher表查询出xmlTest表中成绩>=700分的学生的班主任信息和学生信息,并转化成XML格式
XmlTest表数据如下图所示

MainTeacher表数据如下图所示

执行下面的语句
SELECT xmlTest.学号 AS '学生信息/@学号',--@符号表示该名称为属性名,斜杠表示子层级
xmlTest.学生姓名 AS '学生信息/@姓名',
xmlTest.班级 AS '学生信息/@班级',
mainTeacher.姓名 AS '学生信息/班主任信息/姓名',
mainTeacher.教师编号 AS '学生信息/班主任信息/教师编号',
mainTeacher.性别 AS '学生信息/班主任信息/性别',
mainTeacher.年龄 AS '学生信息/班主任信息/年龄',
mainTeacher.联系电话 AS '学生信息/班主任信息/联系电话'
FROM xmlTest,mainTeacher
WHERE xmlTest.年级总分>=700
AND xmlTest.班主任=mainTeacher.姓名
FOR XML PATH('result');--将根目录名改为result查询结果如下所示
<result>
<学生信息 学号="20180105" 姓名="王婷" 班级="高一3班">
<班主任信息>
<姓名>师从光姓名>
<教师编号>83928182教师编号>
<性别>男性别>
<年龄>28年龄>
<联系电话>15963002120联系电话>
班主任信息>
学生信息>
result>
<result>
<学生信息 学号="20180109" 姓名="甄诚" 班级="高一3班">
<班主任信息>
<姓名>师从光姓名>
<教师编号>83928182教师编号>
<性别>男性别>
<年龄>28年龄>
<联系电话>15963002120联系电话>
班主任信息>
学生信息>
result>TYPE命令
SQL Server支持TYPE命令将FOR XML的查询结果作为XML数据类型返回。
示例13:依然是上面的例子,将查询结果作为XML数据类型返回。
CREATE TABLE xmlType(xml_col XML);
--首先创建一个表xmlType,只有一列xml数据类型的xml_col
INSERT INTO xmlType
SELECT(--将上面的查询语句全部复制到括号中,末尾加上TYPE,表示将XML文档作为xml数据类型,并插入到表xmlType中
SELECT xmlTest.学号 AS '学生信息/@学号',
xmlTest.学生姓名 AS '学生信息/@姓名',
xmlTest.班级 AS '学生信息/@班级',
mainTeacher.姓名 AS '学生信息/班主任信息/姓名',
mainTeacher.教师编号 AS '学生信息/班主任信息/教师编号',
mainTeacher.性别 AS '学生信息/班主任信息/性别',
mainTeacher.年龄 AS '学生信息/班主任信息/年龄',
mainTeacher.联系电话 AS '学生信息/班主任信息/联系电话'
FROM xmlTest,mainTeacher
WHERE xmlTest.年级总分>=700
AND xmlTest.班主任=mainTeacher.姓名
FOR XML PATH('result'),TYPE
);
SELECT * FROM xmlType;--查询xmlType表查询结果如图所示
![]()
双击打开查看XML
<result>
<学生信息 学号="20180105" 姓名="王婷" 班级="高一3班">
<班主任信息>
<姓名>师从光姓名>
<教师编号>83928182教师编号>
<性别>男性别>
<年龄>28年龄>
<联系电话>15963002120联系电话>
班主任信息>
学生信息>
result>
<result>
<学生信息 学号="20180109" 姓名="甄诚" 班级="高一3班">
<班主任信息>
<姓名>师从光姓名>
<教师编号>83928182教师编号>
<性别>男性别>
<年龄>28年龄>
<联系电话>15963002120联系电话>
班主任信息>
学生信息>
result>FOR XML的嵌套查询
示例14:在示例12的查询结果中查询班主任联系电话
SELECT (
SELECT xmlTest.学号 AS '学生信息/@学号',
xmlTest.学生姓名 AS '学生信息/@姓名',
xmlTest.班级 AS '学生信息/@班级',
mainTeacher.姓名 AS '学生信息/班主任信息/姓名',
mainTeacher.教师编号 AS '学生信息/班主任信息/教师编号',
mainTeacher.性别 AS '学生信息/班主任信息/性别',
mainTeacher.年龄 AS '学生信息/班主任信息/年龄',
mainTeacher.联系电话 AS '学生信息/班主任信息/联系电话'
FROM xmlTest,mainTeacher
WHERE xmlTest.年级总分>=700
AND xmlTest.班主任=mainTeacher.姓名
FOR XML PATH('result'),TYPE).query('result/学生信息/班主任信息/联系电话') AS '优秀教师联系方式';SELECT里面依然套用了示例13中被套用的代码,外面用了query方法,查询结果如下图所示
![]()
<联系电话>15963002120联系电话>
<联系电话>15963002120联系电话>XML索引
由于XML数据类型最大可存储2GB的数据,因此需要创建XML索引来优化查询性能。
主XML索引
主XML索引对XML列中XML实例内的所有标记,值和路径进行索引。创建主XML索引时,相应XML列所在的表必须对该表的主键创建了聚集索引。
辅助XML索引
为了增强主XML索引的性能,可以创建辅助XML索引。只有创建了主XML索引后才能创建辅助XML索引。辅助XML索引分3种:PATH,VALUES和PROPERTY辅助XML索引。
创建索引
为表中某个列创建索引,要求该列是XML数据类型。
ALTER TABLE Student
ADD xml_test XML;--对Student表添加一个XML数据类型字段xml_test
--对Student表的xml_test字段创建主XML索引,命名为学生信息表
CREATE PRIMARY XML INDEX 学生信息表
ON Student(xml_test)
GO
--对Student表的xml_test字段创建PATH辅助XML索引,记得写上主索引名
CREATE XML INDEX 辅助学生信息表
ON Student(xml_test)
USING XML INDEX 学生信息表 FOR PATH
GO注:辅助索引的命名不能与主索引相同。
修改和删除索引(ALTER INDEX 和 DROP INDEX)
ALTER INDEX ALL ON Student--重建所有索引
REBUILD WITH(FILLFACTOR=80,SORT_IN_TEMPDB=ON,STATISTICS_NORECOMPUTE=ON);
--删除索引
DROP INDEX 学生信息表 ON Student
GO注:删除主索引,与其相关的所有辅助索引也会被删除。因此上面语句中删除学生信息表索引后,辅助学生信息表索引也被删除了。
OPENXML函数
OPENXML是一个行集函数,用于检索XML文档。在试用OPENXML函数之前,一定要先用系统存储过程sp_xml_preparedocument分析文档,该存储过程在分析完XML文档后会返回一个句柄,使用OPENXML检索文档时要将该句柄作为参数传给OPENXML。
示例15
--定义两个变量@Student和@StudentInfo
DECLARE @Student int
DECLARE @StudentInfo xml
--使用SET为@StudentInfo赋值
SET @StudentInfo='
<姓名>祝红涛
<班级编号>2019382910
<成绩>89
<籍贯>沈阳
'
--使用系统存储过程sp_xml_preparedocument分析由@Student变量表示的XML文档,将分析得到的句柄赋值给@Student变量
EXEC sp_xml_preparedocument @Student OUTPUT,@StudentInfo
--在SELECT语句中使用OPENXML函数返回行集中的指定数据
SELECT * FROM OPENXML(@Student,'/row',2)
WITH(
姓名 varchar(8),
班级编号 varchar(10),
成绩 int,
籍贯 varchar(20)
);结果如图所示
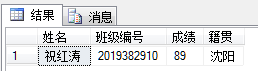
在上述语句中,sp_xml_preparedocument存储过程语句用了2个参数,其中@Student是一个int型变量,该存储过程会将句柄存储在@Student变量中作为结果数据,@StudentInfo是一个XML类型的变量,存储了将要进行分析的XML文档。
OPENXML函数的语句中,使用了3个参数,其中@Student代表已经经过sp_xml_preparedocument存储过程分析的文档的句柄,’/row’使用XPath模式提供了一个路径,代表要返回XML文档中该路径下的数据行,2是一个可选数据参数,表示将这些数据行以元素为中心映射。