java8 并行流使用
一.并行流
1.并行流运行时:内部使用了fork-join框架
其默认线程数为处理器数量,Runtime.getRuntime().availableProcessors()不过也可以修改这个值,但是是全局修改,对所有的并行流有效
System.setProperty("java.util.concurrent.ForkJoinPool.common.parallelism","12");
一般不建议修改
2.方法parallel()并没有改变对流本身,而是一个标记
然后再同一个流中,并行/窜行可以多次转换,以最后一次转换的标记为准
3关于使用并行流:
一般而言,想给出任何关于什么时候该用并行流的定量建议都是不可能也毫无意义的,因为
任何类似于“仅当至少有一千个(或一百万个或随便什么数字)元素的时候才用并行流)”的建
议对于某台特定机器上的某个特定操作可能是对的,但在略有差异的另一种情况下可能就是大错
特错。尽管如此,我们至少可以提出一些定性意见,帮你决定某个特定情况下是否有必要使用并
行流。
1.如果有疑问,测量。把顺序流转成并行流轻而易举,但却不一定是好事。我们在本节中
已经指出,并行流并不总是比顺序流快。此外,并行流有时候会和你的直觉不一致,所
以在考虑选择顺序流还是并行流时,第一个也是最重要的建议就是用适当的基准来检查
其性能。
2.留意装箱。自动装箱和拆箱操作会大大降低性能。 Java 8中有原始类型流(IntStream、
LongStream、 DoubleStream)来避免这种操作,但凡有可能都应该用这些流。
3.有些操作本身在并行流上的性能就比顺序流差。特别是limit和findFirst等依赖于元
素顺序的操作,它们在并行流上执行的代价非常大。例如, findAny会比findFirst性
能好,因为它不一定要按顺序来执行。你总是可以调用unordered方法来把有序流变成
无序流。那么,如果你需要流中的n个元素而不是专门要前n个的话,对无序并行流调用
limit可能会比单个有序流(比如数据源是一个List)更高效。
4.还要考虑流的操作流水线的总计算成本。设N是要处理的元素的总数, Q是一个元素通过
流水线的大致处理成本,则N*Q就是这个对成本的一个粗略的定性估计。 Q值较高就意味
着使用并行流时性能好的可能性比较大。
5.对于较小的数据量,选择并行流几乎从来都不是一个好的决定。并行处理少数几个元素
的好处还抵不上并行化造成的额外开销。
6.要考虑流背后的数据结构是否易于分解。例如, ArrayList的拆分效率比LinkedList
高得多,因为前者用不着遍历就可以平均拆分,而后者则必须遍历。
7.流自身的特点,以及流水线中的中间操作修改流的方式,都可能会改变分解过程的性能。
例如,一个SIZED流可以分成大小相等的两部分,这样每个部分都可以比较高效地并行处
理,但筛选操作可能丢弃的元素个数却无法预测,导致流本身的大小未知。
8.还要考虑终端操作中合并步骤的代价是大是小(例如Collector中的combiner方法)。
如果这一步代价很大,那么组合每个子流产生的部分结果所付出的代价就可能会超出通
过并行流得到的性能提升。
源 可分解性
ArrayList 极佳
LinkedList 差
IntStream.range 极佳
Stream.iterate 差
HashSet 好
TreeSet 好
接下来看下性能测试例子:
public class StreamDemo7 {
//并行方式1
public long Parsum1(long n) {
Long sum= Stream.iterate(1L, i->i+1)
.limit(n)
.parallel()
.reduce(0L,Long::sum);
return sum;
}
//并行方式2
public long Parsum2(long n) {
//在数量大的时候,有初始值比没初始值速度更快
Long sum= LongStream.rangeClosed(0, n)
.parallel()
.reduce(0L, Long::sum);
return sum;
//这里没有拆装箱
}
//并行方式3
public long Parsum3(long n) {
Long sum= LongStream.rangeClosed(0, n)
.parallel()
.reduce(0L,(a,b)->a+b);
return sum;
}
//窜行
public long cuanSum(long n) {
Long sum= LongStream.rangeClosed(0, n)
.reduce(0L, Long::sum);
return sum;
}
//for
public long sumFor(long n) {
long sum=0L;
for (long i = 1; i <= n; i++) {
sum+=i;
}
return sum;
}
//传统线程
public long callSum(long n) throws InterruptedException, ExecutionException {
ExecutorService es= Executors.newFixedThreadPool(8);
long avg=n/8;
long num2=avg*2;
long num3=avg*3;
long num4=avg*4;
long num5=avg*5;
long num6=avg*6;
long num7=avg*7;
//运行线程,返回结果
Future fu1=es.submit(new MyCallable(1, avg));
Future fu2=es.submit(new MyCallable(avg+1, num2));
Future fu3=es.submit(new MyCallable(num2+1, num3));
Future fu4=es.submit(new MyCallable(num3+1, num4));
Future fu5=es.submit(new MyCallable(num4+1, num5));
Future fu6=es.submit(new MyCallable(num5+1, num6));
Future fu7=es.submit(new MyCallable(num6+1, num7));
Future fu8=es.submit(new MyCallable(num7+1, n));
//这个不需要
// while(true){
// if (fu1.isDone()&&fu2.isDone()&&fu3.isDone()&&fu4.isDone()&&fu5.isDone()) {
// System.out.println(fu1.get()+fu2.get()+fu3.get()+fu4.get()+fu5.get());
// break;
// }
// }
//get()方法用来获取执行结果,这个方法会产生阻塞,会一直等到任务执行完毕才返回;
long sum=fu1.get()+fu2.get()+fu3.get()+fu4.get()+fu5.get()+fu6.get()+fu7.get()+fu8.get();
es.shutdown();
return sum;
}
@Test
public void testName() throws InterruptedException, ExecutionException {
long start=0L;
long duration=0L;
long sum=0L;
long temp=Long.MAX_VALUE;
//
// for (int i = 0; i < 2; i++) {
start=System.currentTimeMillis();
sum=sumFor(10_0000_0000);
duration=System.currentTimeMillis()-start;
if (duration{
private long sum1;
private long sum2;
public MyCallable(long sum1,long sum2) {
this.sum1=sum1;
this.sum2=sum2;
}
@Override
public Long call() throws Exception {
long sum=0;//定义在里面更好一些
for (long i = sum1; i < sum2+1; i++) {
sum+=i;
}
//返回计算结果
return sum;
}
} 既然并行流使用了frok-join,肯定有一种自动机制来为你拆分流。这种新的自动机制称为Spliterator
Spliterator是Java 8中加入的另一个新接口;这个名字代表“可分迭代器”(splitableiterator)。
boolean tryAdvance(Consumer action);
Spliterator
long estimateSize();
int characteristics();
}
Iterator ,因为它会按顺序一个一个使用 Spliterator 中的元素,并且如果还有其他元素要遍
历就返回 true 。但 trySplit 是专为 Spliterator 接口设计的,因为它可以把一些元素划出去分
给第二个 Spliterator (由该方法返回),让它们两个并行处理。 Spliterator 还可通过
estimateSize 方法估计还剩下多少元素要遍历,因为即使不那么确切,能快速算出来是一个值
也有助于让拆分均匀一点。
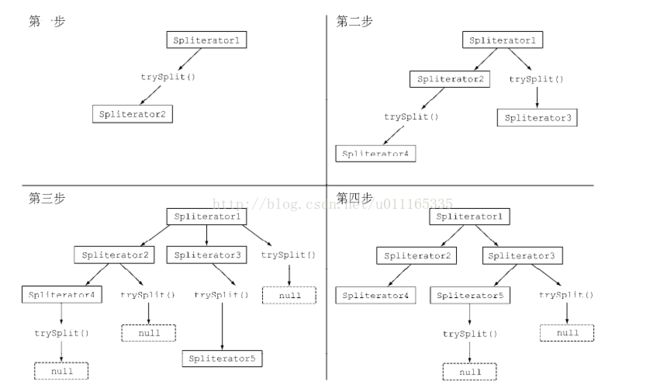
Spliterator 调用 trySplit ,生成第二个 Spliterator 。第二步对这两个 Spliterator 调用
trysplit ,这样总共就有了四个 Spliterator 。这个框架不断对 Spliterator 调用 trySplit
直到它返回 null ,表明它处理的数据结构不能再分割,如第三步所示。最后,这个递归拆分过
程到第四步就终止了,这时所有的 Spliterator 在调用 trySplit 时都返回了 null
Spliterator 接口声明的最后一个抽象方法是 characteristics ,它将返回一个 int ,代
表 Spliterator 本身特性集的编码。使用 Spliterator 的客户可以用这些特性来更好地控制和
优化它的使用
见图:

二.关于fork-join框架
1.流程图如下:
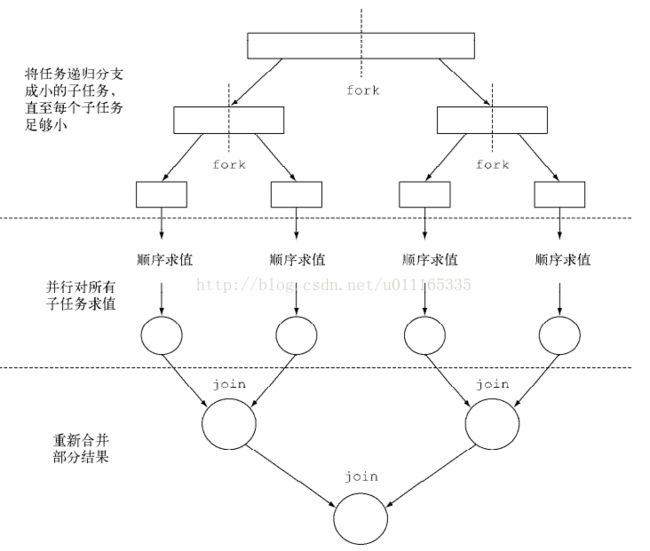
当把任务传给ForkJoinPool时,这个任务就由池中的一个线程
执行,这个线程会调用任务的compute方法。该方法会检查任务是否小到足以顺序执行,如果不
够小则会把要求和的数组分成两半,分给两个新的ForkJoinSumCalculator,而它们也由
ForkJoinPool安排执行。因此,这一过程可以递归重复,把原任务分为更小的任务,直到满足
不方便或不可能再进一步拆分的条件(本例中是求和的项目数小于等于10000)。这时会顺序计
算每个任务的结果,然后由分支过程创建的(隐含的)任务二叉树遍历回到它的根。接下来会合
并每个子任务的部分结果,从而得到总任务的结果。这一过程如图
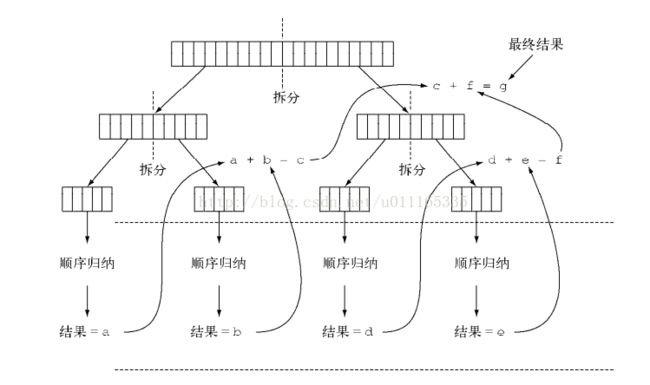
原理:
分支/合并框架工程用一种称为工作窃取(work stealing)的技术来解决这个问题。在实际应
用中,这意味着这些任务差不多被平均分配到ForkJoinPool中的所有线程上。每个线程都为分
配给它的任务保存一个双向链式队列,每完成一个任务,就会从队列头上取出下一个任务开始执
行。基于前面所述的原因,某个线程可能早早完成了分配给它的所有任务,也就是它的队列已经
空了,而其他的线程还很忙。这时,这个线程并没有闲下来,而是随机选了一个别的线程,从队
列的尾巴上“偷走”一个任务。这个过程一直继续下去,直到所有的任务都执行完毕,所有的队
列都清空。这就是为什么要划成许多小任务而不是少数几个大任务,这有助于更好地在工作线程
之间平衡负载。
一般来说,这种工作窃取算法用于在池中的工作线程之间重新分配和平衡任务。下图展示
了这个过程。当工作线程队列中有一个任务被分成两个子任务时,一个子任务就被闲置的工作线
程“偷走”了。如前所述,这个过程可以不断递归,直到规定子任务应顺序执行的条件为真 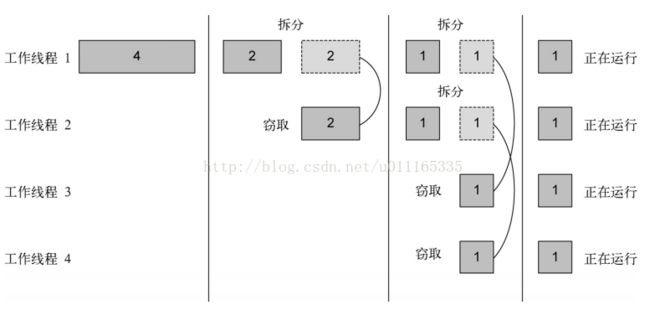
最佳做法。
对一个任务调用 join 方法会阻塞调用方,直到该任务做出结果。因此,有必要在两个子
任务的计算都开始之后再调用它。否则,你得到的版本会比原始的顺序算法更慢更复杂,
因为每个子任务都必须等待另一个子任务完成才能启动。
不应该在 RecursiveTask 内部使用 ForkJoinPool 的 invoke 方法。相反,你应该始终直
接调用 compute 或 fork 方法,只有顺序代码才应该用 invoke 来启动并行计算。
对子任务调用 fork 方法可以把它排进 ForkJoinPool 。同时对左边和右边的子任务调用
它似乎很自然,但这样做的效率要比直接对其中一个调用 compute 低。这样做你可以为
其中一个子任务重用同一线程,从而避免在线程池中多分配一个任务造成的开销。
调试使用分支 / 合并框架的并行计算可能有点棘手。特别是你平常都在你喜欢的 IDE 里面
看栈跟踪( stack trace )来找问题,但放在分支 合并计算上就不行了,因为调用 compute
的线程并不是概念上的调用方,后者是调用 fork 的那个。
和并行流一样,你不应理所当然地认为在多核处理器上使用分支 / 合并框架就比顺序计
算快。我们已经说过,一个任务可以分解成多个独立的子任务,才能让性能在并行化时
有所提升。所有这些子任务的运行时间都应该比分出新任务所花的时间长;一个惯用方
法是把输入 / 输出放在一个子任务里,计算放在另一个里,这样计算就可以和输入 / 输出
同时进行。此外,在比较同一算法的顺序和并行版本的性能时还有别的因素要考虑。就
像任何其他 Java 代码一样,分支 / 合并框架需要“预热”或者说要执行几遍才会被 JIT 编
译器优化。这就是为什么在测量性能之前跑几遍程序很重要,我们的测试框架就是这么
做的。同时还要知道,编译器内置的优化可能会为顺序版本带来一些优势(例如执行死
码分析 —— 删去从未被使用的计算)。
对于分支 / 合并拆分策略还有最后一点补充:你必须选择一个标准,来决定任务是要进一步
拆分还是已小到可以顺序求值
public class FrokJoinDemo extends RecursiveTask{
private static final long serialVersionUID = 1L;
//需求自已分组和合并
private long start=0;
private long end=0;
private static final long THRESHOLD=1_0000L;
public FrokJoinDemo(long start, long end) {
this.start = start;
this.end = end;
}
@Override
protected Long compute() {
long sum = 0;
if (end-start<=THRESHOLD) {
for (long i = start; i <= end; i++) {
sum+=i;
}
}else{
//进行细分
long middle=(start+end)/2;
FrokJoinDemo left = new FrokJoinDemo(start, middle);
FrokJoinDemo right = new FrokJoinDemo(middle+1, end);
left.fork();
right.fork();
sum=left.join()+right.join();
}
return sum;
} 测试代码:
public void test1() throws InterruptedException, ExecutionException {
Instant start=Instant.now();
//线程池
ForkJoinPool forkJoinPool=new ForkJoinPool();
FrokJoinDemo demo=new FrokJoinDemo(0, 100_0000_0000L);
//有返回值的
//方式1
Long invoke = forkJoinPool.invoke(demo);
System.out.println("结果"+invoke);
//方式2
// public abstract class ForkJoinTask implements Future, Serializable {}
// ForkJoinTask实现了Future接口
/*ForkJoinTask submit = forkJoinPool.submit(demo);
//这个需要抛异常
Long sum =submit.get();
System.out.println("结果"+sum);*/
Instant end=Instant.now();
System.out.println("毫秒"+Duration.between(start, end).toMillis());
}