使用Jdom解析XML
最近,准备学习一下Spring的相关知识,虽然知道,javaweb使用properties文件和xml文件作为配置文件,其中properties文件是由java本身提供的相关类和方法进行解析的,而xml也需要解析。至于具体使用什么解析方法,不是很清楚,学习java基础的时候,好像知道xml常用的解析方式为dom4j和SAX解析,对于这两种解析方式不再赘述,本文简单探讨一下使用jdom解析XML的相关知识。
1.概述
JDOM是两位著名的 Java 开发人员兼作者,Brett Mclaughlin 和 Jason Hunter 的创作成果, 2000 年初在类似于Apache协议的许可下,JDOM作为一个开放源代码项目正式开始研发了。它已成长为包含来自广泛的 Java 开发人员的投稿、集中反馈及错误修复的系统,并致力于建立一个完整的基于 Java 平台的解决方案,通过 Java 代码来访问、操作并输出 XML 数据。
虽然许多Java 开发人员每天都在使用 XML,Sun 却在将 XML 整合进 Java 平台方面落后了。因为在 XML 成为从商家对商家集成到 Web 站点内容流水化等方面的关键技术之前,Java 2 平台就已经非常流行了。Sun已经使用JSR过程使之成为现存 XMLAPI的鼻祖,这一点已被广泛接受。目前最显著的是加入了JAXP(用于 XML语法分析的 Java API),其中包含了三个软件包:
·org.w3c.dom ,W3C 推荐的用于 XML 标准规划文档对象模型的 Java 工具
·org.xml.sax,用于对 XML 进行语法分析的事件驱动的简单 API
·javax.xml.parsers ,工厂化工具,允许应用程序开发人员获得并配置特殊的语法分析器工具 JDOM 能够替换org.w3c.dom软件包来有计划地操作 XML 文档
JDOM是一个开源项目,它基于树型结构,利用纯JAVA的技术对XML文档实现解析、生成、序列化以及多种操作。
JDOM 直接为JAVA编程服务。它利用更为强有力的JAVA语言的诸多特性(方法重载、集合概念以及映射),把SAX和DOM的功能有效地结合起来。
Jdom是用Java语言读、写、操作XML的新API函数。Jason Hunter 和 Brett McLaughlin公开发布了它的1.0版本。在直觉、简单和高效的前提下,这些API函数被最大限度的优化。在接下来的篇幅里将介绍怎么用Jdom去读写一个已经存在的XML文档。
在使用设计上尽可能地隐藏原来使用XML过程中的复杂性。利用JDOM处理XML文档将是一件轻松、简单的事。
JDOM在2000年的春天被Brett McLaughlin和Jason Hunter开发出来,以弥补DOM及SAX在实际应用当中的不足之处。
这些不足之处主要在于SAX没有文档修改、随机访问以及输出的功能,而对于DOM来说,JAVA程序员在使用时来用起来总觉得不太方便。
DOM的缺点主要是来自于由于Dom是一个接口定义语言(IDL),它的任务是在不同语言实现中的一个最低的通用标准,并不是为JAVA特别设计的。JDOM的最新版本为JDOM Beta 9。最近JDOM被收录到JSR-102内,这标志着JDOM成为了JAVA平台组成的一部分。
在 JDOM 中,XML 元素就是 Element 的实例,XML 属性就是 Attribute 的实例,XML 文档本身就是 Document 的实例。
因为 JDOM 对象就是像Document、Element 和 Attribute 这些类的直接实例,因此创建一个新 JDOM 对象就如在 Java 语言中使用 new 操作符一样容易。JDOM 的使用是直截了当的。
JDOM 使用标准的 Java 编码模式。只要有可能,它使用 Java new 操作符而不故弄玄虚使用复杂的工厂化模式,使对象操作即便对于初学用户也很方便。
2.简介
JDOM是由以下几个包组成的
org.jdom包含了所有的xml文档要素的java类
org.jdom.adapters包含了与dom适配的java类
org.jdom.filter包含了xml文档的过滤器类
org.jdom.input包含了读取xml文档的类
org.jdom.output包含了写入xml文档的类
org.jdom.transform包含了将jdomxml文档接口转换为其他xml文档接口
org.jdom.xpath包含了对xml文档xpath操作的类
3.API
1.Document
(1)Document的操作方法:
Element root=new Element("GREETING");Document doc=new Document(root);
root.setText("HelloJDOM!");
或者简单的使用Document doc=new Document(new Element("GREETING").setText("HelloJDOM!t"));
这点和DOM不同。Dom则需要更为复杂的代码,如下:
DocumentBuilderFactory factory=DocumentBuilderFactory.newInstance();
DocumentBuilder builder=factory.newDocumentBuilder();
Documentdoc=builder.newDocument();
Element root=doc.createElement("root");
Text text=doc.createText("Thisistheroot");
root.appendChild(text);
doc.appendChild(root);
注意事项:JDOM不允许同一个节点同时被2个或多个文档相关联,要在第2个文档中使用原来老文档中的节点的话。首先需要使用detach()把这个节点分开来。
(2)从文件、流、系统ID、URL得到Document对象:
DOMBuilder builder=new DOMBuilder();Document doc=builder.build(newFile("jdom_test.xml"));
SAXBuilder builder=new SAXBuilder();
Document doc=builder.build(url);
在新版本中DOMBuilder已经Deprecated掉DOMBuilder.builder(url),用SAX效率会比较快。
这里举一个小例子,为了简单起见,使用String对象直接作为xml数据源:
PublicjdomTest(){
String textXml=null;
textXml="";
textXml=textXml+ "aaabbbcccddd";
textXml=textXml+"";
SAXBuilder builder=new SAXBuilder();
Document doc=null;
Reader in=new StringReader(textXml);
try {
doc=builder.build(in);
Element root=doc.getRootElement();
List ls=root.getChildren();//注意此处取出的是root节点下面的一层的Element集合
for ( Iterator iter=ls.iterator(); iter.hasNext(); ){
Element el=(Element)iter.next();
if (el.getName().equals("to")){
System.out.println(el.getText());
}
}
} catch(IOException ex) {
ex.printStackTrace();
} catch(JDOMException ex) {
ex.printStackTrace();
}
}
(3)DOM的document和JDOM的Document之间的相互转换
DOMBuilder builder=new DOMBuilder();org.jdom.Document jdomDocument=builder.build(domDocument);
DOMOutputter converter=newDOMOutputter();//workwiththeJDOMdocument…
org.w3c.dom.Document domDocument=converter.output(jdomDocument);
//workwiththeDOMdocument…
2.XML输出
XMLOutPutter类:JDOM的输出非常灵活,支持很多种io格式以及风格的输出
Document doc=newDocument(...);
XMLOutputter outp=newXMLOutputter();
outp.output(doc,fileOutputStream);//Rawoutput
outp.setTextTrim(true);//Compressedoutput
outp.output(doc,socket.getOutputStream());
outp.setIndent("");//Prettyoutput
outp.setNewlines(true);
outp.output(doc,System.out);
详细请参阅最新的JDOMAPI手册
3.Element
(1)浏览Element树
Element root=doc.getRootElement();//获得根元素elementList allChildren=root.getChildren();//获得所有子元素的一个list
List namedChildren=root.getChildren("name");//获得指定名称子元素的list
Element child=root.getChild("name");//获得指定名称的第一个子元素
JDOM给了我们很多很灵活的使用方法来管理子元素(这里的List是java.util.List)
List allChildren=root.getChildren();
allChildren.remove(3);//删除第四个子元素
allChildren.removeAll(root.getChildren("jack"));//删除叫“jack”的子元素
root.removeChildren("jack");//便捷写法
allChildren.add(new Element("jane"));//加入
root.addContent(new Element("jane"));//便捷写法
allChildren.add(0,new Element("first"));
(2)移动Elements:
在JDOM里很简单Element movable=new Element("movable");
parent1.addContent(movable);//place
parent1.removeContent(movable);//remove
parent2.addContent(movable);//add
在Dom里
Element movable=doc1.createElement("movable");
parent1.appendChild(movable);//place
parent1.removeChild(movable);//remove
parent2.appendChild(movable);//出错!
纠错性
JDOM的Element构造函数(以及它的其他函数)会检查element是否合法。
而它的add/remove方法会检查树结构,检查内容如下:1.在任何树中是否有回环节点
2.是否只有一个根节点
3.是否有一致的命名空间(Namespaces)
(3)Element的text内容读取
Acooldemo//Thetextisdirectlyavailable
//Returns"\nAcooldemo\n"
String desc=element.getText();
//There'saconvenientshortcut
//Returns"Acooldemo"
String desc=element.getTextTrim();
(4)Elment内容修改
element.setText("Anewdescription");4.补充说明
1.org.JDOM这个包里的类是你解析xml文件后所要用到的所有数据类型。
AttributeCDATA
Coment
DocType
Document
Element
EntityRef
Namespace
ProscessingInstruction
Text
2.org.JDOM.transform在涉及xslt格式转换时应使用下面的2个类
JDOMSourceJDOMResult
org.JDOM.input
3.输入类,一般用于文档的创建工作
SAXBuilderDOMBuilder
ResultSetBuilder
4.org.JDOM.output输出类,用于文档转换输出
XMLOutputterSAXOutputter
DomOutputter
JTreeOutputter
使用前注意事项:
1.JDOM对于JAXP以及TRax的支持
JDOM支持JAXP1.1:你可以在程序中使用任何的parser工具类,默认情况下是JAXP的parser。
制定特别的parser可用如下形式
SAXBuilderparser
=newSAXBuilder("org.apache.crimson.parser.XMLReaderImpl");
Documentdoc=parser.build("str");
//workwiththedocument...
JDOM也支持TRaX:XSLT可通过JDOMSource以及JDOMResult类来转换(参见以后章节)
2.注意在JDOM里文档(Document)类由org.JDOM.Document来表示。这要与w3c中的Document区别开,这2种格式如何转换在后面会说明。
以下如无特指均指JDOM里的Document。
5.文档解析
JDOM 不光可以很方便的建立XML文档,它的另一个用处是它能够读取并操作现有的 XML 数据。
JDOM的解析器在org.jdom.input.*这个包里,其中的DOMBuilder的功能是将DOM模型的Document解析成JDOM模型的Document;SAXBuilder的功能是从文件或流中解析出符合JDOM模型的XML树。由于我们经常要从一个文件里读取数据,因此我们应该采用后者作为解析工具。
解析一个xml文档,基本可以看成以下几个步骤:
1.实例化一个合适的解析器对象
本例中我们使用SAXBuilder:SAXBuilder sb = new SAXBuilder();
2.以包含XML数据的文件为参数,构建一个文档对象myDocument
Document myDocument = sb.build(/some/directory/myFile.xml);3.获到根元素
Element rootElement = myDocument.getRootElement();一旦你获取了根元素,你就可以很方便地对它下面的子元素进行操作了,下面对Element对象的一些常用方法作一下简单说明:
getChild("childname") 返回指定名字的子节点,如果同一级有多个同名子节点,则只返回第一个;如果没有返回null值。
getChildren("childname") 返回指定名字的子节点List集合。这样你就可以遍历所有的同一级同名子节点。
getAttributeValue("name") 返回指定属性名字的值。如果没有该属性则返回null,有该属性但是值为空,则返回空字符串。
getChildText("childname") 返回指定子节点的内容文本值。
getText() 返回该元素的内容文本值。
6.应用
6.1创建文档
Element rootElement = new Element("MyInfo");//所有的XML元素都是 Element 的实例。根元素也不例外:)Document myDocument = new Document(rootElement);//以根元素作为参数创建Document对象。一个Document只有一个根,即root元素。
6.2元素
6.2.1给根元素添加属性
Attribute rootAttri = new Attribute("comment","introduce myself");//创建名为 commnet,值为 introduce myself 的属性。rootElement.setAttribute(rootAttri);//将刚创建的属性添加到根元素。
这两行代码你也可以合成一行来写,象这样:
rootElement.setAttribute(new Attribute("comment","introduce myself"));
或者
rootElement.setAttribute("comment","introduce myself");
6.2.2添加元素和子元素
JDOM里子元素是作为 content(内容)添加到父元素里面去的,所谓content就是类似上面样本文档中之间的东东,即kingwong。啰嗦了点是吧:)Element nameElement = new Element("name");//创建 name 元素
nameElement.addContent("kingwong");//将kingwong作为content添加到name元素
rootElement.addContent(nameElement);//将name元素作为content添加到根元素
这三行你也可以合为一句,象这样:
r ootElement.addContent((Content)(new Element("name").addContent("kingwong")));//因为addContent(Content child)方法返回的是一个Parent接口,而Element类同时继承了Content类和实现了Parent接口,所以我们把它造型成Content。
我们用同样的方法添加带属性的子元素
rootElement.addContent(new Element("sex").setAttribute("value","male"));//注意这里不需要转型,因为addAttribute(String name,String value)返回值就是一个 Element。
同样的,我们添加元素到根元素下,用法上一样,只是稍微复杂了一些:
rootElement.addContent((Content)(new Element("contact").addContent((Content)(new Element("telephone").addContent("87654321")))));
如果你对这种简写形式还不太习惯,你完全可以分步来做,就象本节刚开始的时候一样。事实上如果层次比较多,写成分步的形式更清晰些,也不容易出错。
6.2.3删除子元素
这个操作比较简单:rootElement.removeChild("sex");//该方法返回一个布尔值
到目前为止,我们学习了一下JDOM文档生成操作。上面建立了一个样本文档,可是我们怎么知道对不对呢?因此需要输出来看一下。我们将JDOM生成的文档输出到控制台,使用 JDOM 的 XMLOutputter 类。
6.3文本转换
JDOM 转为 XML 文本XMLOutputter xmlOut = new XMLOutputter(" ",true);
try {
xmlOut.output(myDocument,System.out);
} catch (IOException e) {
e.printStackTrace();
}
XMLOutputter 有几个格式选项。这里我们已指定希望子元素从父元素缩进两个空格,并且希望元素间有空行。
new XMLOutputter(java.lang.String indent, boolean newlines)这个方法在最新版本中已经不建议使用。JDOM有一个专门的用来定义格式化输出的类: org.jdom.output.Format,如果你没有特殊的要求,有时候使用里面的几个静态方法(应该可以说是预定义格式)如 getPrettyFormat()就可以了。我们把上面的输出格式稍微改一下,就象这样:
XMLOutputter xmlOut = new XMLOutputter(Format.getPrettyFormat());
6.将JDOM文档转化为其他形式
XMLOutputter 还可输出到 Writer 或 OutputStream。为了输出JDOM文档到一个文本文件,我们可以这样做:
FileWriter writer = new FileWriter("/some/directory/myFile.xml");
outputter.output(myDocument, writer);
writer.close();
XMLOutputter 还可输出到字符串,以便程序后面进行再处理:
Strng outString = xmlOut.outputString(myDocument);
当然,在输出的时候你不一定要输出所有的整个文档,你可以选择元素进行输出:
xmlOut.output(rootElement.getChild("name"),System.out);
7.实例代码
7.1准备工作,需要引入jdom的jar,本实例使用的是jdom-2.0.6.jar
7.2需要解析的xml文件test.xml
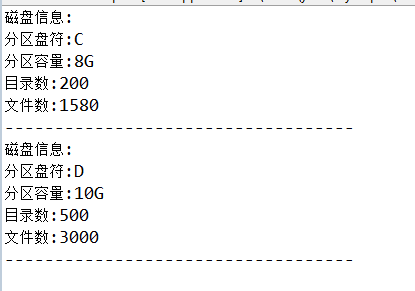
8G
200
1580
10G
500
3000
7.3xml解析使用的类Sample1.java
import java.util.*;
import org.jdom2.*;
import org.jdom2.input.SAXBuilder;
public class Sample1 {
public static void main(String[] args) throws Exception{
SAXBuilder sb=new SAXBuilder();
Document doc=sb.build(Sample1.class.getClassLoader().getResourceAsStream("test.xml")); //构造文档对象
Element root=doc.getRootElement(); //获取根元素HD
List list=root.getChildren("disk");//取名字为disk的所有元素
for(int i=0;i7.4运行结果:
本文简单讲述了使用jdom解析XML的相关知识,至于使用jdom操作xml的相关使用(比如创建、修改)等留待以后具体使用到的时候再来探讨了。