Spark MLlib中基于DataFrame的 pipeline介绍
一 基本重要概念解释
1.1 管道中的主要概念
MLlib对机器学习算法的API进行了标准化,使得将多种算法合并成一个pipeline或工作流变得更加容易。Pipeline的概念主要是受scikit-learn启发。
DataFrame:这个ML API使用Spark SQL 的DataFrame作为一个ML数据集,它可以容纳各种数据类型。例如,a DataFrame具有可以存储文本,特征向量,真实标签和预测值的不同列。
Transformer:ATransformer是可以将一个DataFrame变换成另一个DataFrame的算法(可以安装spark的transform理解)。例如,一个ML模型是一个Transformer,负责将特征DataFrame转化为一个包含预测值的DataFrame。
Estimator:An Estimator是一个算法,可以作用于一个DataFrame产生一个Transformer。例如,学习算法是一种Estimator,负责训练DataFrame和产生模型。
Pipeline: Pipeline将多个Transformers和Estimators连接起来以确定一个ML工作流程。
Parameter:所有Transformers和Estimators现在共享一个通用API,用于指定参数的。
1.2 DataFrame
机器学习可以应用于各种数据类型,如向量,文本,图像和结构化数据。采用Spark Sql的dataframe来支持多种数据类型。
Dataframe支持很多基础类型和结构化类型,具体可以参考Spark官网查看其支持的数据类型列表。另外,除了SparkSql官方支持的数据类型,dataframe还可以支持ML的向量类型。
Dataframe可以从一个规则的RDD隐式地或显式地创建。有关创建实例请参考Spark官网,或者等待浪尖后续更新。
DataFrame的列式有列名的。后面例子中会发现列明为text,feature,label等
1.3 pipeline组件
1.3.1 转换器(Transformers)
Transformer是包含特征转换器和学习模型的抽象。通常情况下,转换器实现了一个transform方法,该方法通过给Dataframe添加一个或者多个列来将一个DataFrame转化为另一个Dataframe。
例如:一个特征转换器可以获取一个dataframe,读取一列(例如,text),然后将其映射成一个新的列(例如,特征向量)并且会输出一个新的dataframe,该dataframe追加了那个转换生成的列。
一个学习模型可以获取一个dataframe,读取包含特征向量的列,为每一个特征向量预测一个标签,然后生成一个包含预测标签列的新dataframe。
1.3.2 评估器(Estimators)
Estimator抽象了一个学习算法或者任何能对数据进行fit或者trains操作的算法。从技术上讲,一个Estimator实现了一个fit()方法,该方法接受一个dataframe并生成一个模型(也即一个Transformer)。例如,一个学习算法,比如:LogisticRegression是一个Estimator,通过调用fit()训练一个LogisticRegressionModel,这就是一个模型,也是一个Transformer。
1.3.3 PipeLine组件属性
Transformer.transform()s和Estimator.fit()s都是无状态的。将来,有状态算法可以通过替代概念来支持。
每个Transformer或者Estimator都有一个唯一的ID,该ID在指定参数时有用,会在后面讨论。
1.4 管道(pipeline)
在机器学习中,通常运行一系列算法来处理和学习数据。例如,简单的文本文档处理工作流程可能包括几个阶段:
1. 将每个文档的文本分成单词;
2. 将每个文档的单词转换为数字特征向;
3. 使用特征向量和标签学习预测模型。
MLlib将这个样一个工作流程成为一个pipeline,其包括一些列的按顺序执行的PipelineStages (Transformers 和Estimators) 。后面会有一个详细的例子介绍该工作流程。
1.5 管道运行原理
每个pipeline被指定包含一系列的stages,并且每个stage要么是一个Transformer,要么是一个Estimator。这些stage是按照顺序执行的,输入的dataframe当被传入每个stage的时候会被转换。对于Transformer stages,transform()方法会被调用去操作Dataframe。对于Estimator stages,fit()方法会被调用,然后产生一个Transformer(其会成为PipelineModel的一部分,或者fitted pipeline-训练好的pipeline),并且那个Transformer的transform方法会被调用去操作那个Dataframe。
我们用简单的文本文档工作流来说明这一点。
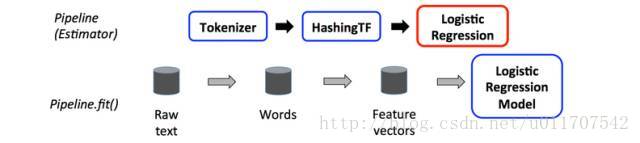
在上面,最上面一行代表一个Pipeline有三个阶段。前两个(Tokenizer和HashingTF)是Transformers(蓝色),第三个(LogisticRegression)是Estimator(红色)。最下面一行代表流经管道的数据,其中圆柱表示DataFrames。Pipeline.fit()方法被调用操作原始DataFrame,其包含原始文档和标签上。Tokenizer.transform()方法将原始文本分割成单词,增加一个带有单词的列到原始的dataframe上。HashingTF.transform()方法将单词列转化为特征向量,给dataframe增加一个带有特征向量的列。接着,由于LogisticRegression是一个Estimator,Pipeline先调用LogisticRegression.fit(),来产生一个LogisticRegressionModel。如果,Pipeline有更多的Estimators,他会调用LogisticRegressionModel’stransform()方法在Dataframe传入下个stage前去作用于Dataframe。
一个Pipeline是一个Estimator。因此,在pipeline的fit()方法运行后,它会产生一个PipelineModel,其也是一个Transformer。这PipelineModel是在测试时使用 ; 下图说明了这种用法。
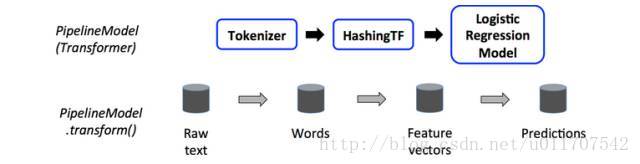
上图中,PipelineModel和原始的Pipeline有相同数量的stage,但是在原始pipeline中所有的Estimators已经变为了Transformers。当PipelineModel’s transform()方法被调用再测试集上,数据就会按顺序在fitted pipeline中传输。每个stage的transform方法更新dataset然后将更新后的传给下一个stage。
1.6 细节介绍
DAG Pipelines:一个Pipeline的stages被定义为一个顺序数组。目前这里给出的都是线性的Pipelines,即Pipeline每个stage使用前一stage产生的数据。Pipeline只要数据流图形成有向无环图(DAG),就可以创建非线性的Pipelines。该图目前是基于每个stage的输入和输出列名(通常指定为参数)隐含指定的。如果Pipeline形成为DAG,那么stage必须按拓扑顺序指定。
Runtime checking:由于pipelines能够操作带有不同数据类型的Dataframe,肯定不能使用编译时类型检查。Pipelines 和PipelineModels在正式运行pipeline之前执行运行时类型检查。该类型检查使用Dataframe的schema来实现,schema就是dataframe列的数据类型描述。
Unique Pipeline stages:一个Pipeline的stages应该是一个唯一的实例。相同的myHashingTF不应该在pipeline中出现两次,因为pipeline的stages都包含唯一的IDs。然而,不同的实例myHashingTF1 和myHashingTF2 (类型都是HashingTF)可以被放入同一个Pipeline,因为不同的实例会被打上不同的IDs。
1.7 参数
MLlib 的Estimators和Transformers使用统一的API来指定参数。Param是自包含文档的命名参数。ParamMap是一系列(parameter,value)对。
有两种主要的方式将参数传入算法:
(1)为实例设置参数。
例如,lr是LogisticRegression的一个实例,你可以调用lr.setMaxIter(10)来使得lr.fit()最多十次迭代使用。这个API类似于spark.mllib包中使用的API 。
(2)给fit()或者transform()传入一个ParamMap。
在ParamMap中的任何参数将覆盖以前通过setter方法指定的参数。参数属于Estimators和Transformers的特定实例。例如,如果我们有两个LogisticRegression实例lr1和lr2,然后我们可以建立一个ParamMap与两个maxIter指定的参数:ParamMap(lr1.maxIter -> 10, lr2.maxIter -> 20)。在一个pipeline中两个算法都使用了maxIter。
1.8 保存或者加载管道
通常情况下,将模型或管道保存到磁盘供以后使用是值得的。模型的导入导出功能在spark1.6的时候加入了pipeline API。大多数基础transformers和基本ML models都支持。
可以将训练好的pipeline输出到磁盘保存起来
model.write.overwrite().save("/opt/spark-logistic-regression-model")将已经保存的模型加载出来 便于使用
val sameModel =PipelineModel.load("/opt/spark-logistic-regression-model")二 代码实例
2.1 Estimator, Transformer, and Param
importorg.apache.spark.ml.classification.LogisticRegression
import org.apache.spark.ml.linalg.{Vector,Vectors}
import org.apache.spark.ml.param.ParamMap
import org.apache.spark.sql.Row
//准备数据的格式:(label,features)
//注意使用时候特征命名最好命名为features
//因为在一些算法中是取找特征列根据features列名
val training = spark.createDataFrame(
Seq((1.0, Vectors.dense(0.0, 1.1, 0.1)),
(0.0, Vectors.dense(2.0, 1.0, -1.0)),
(0.0, Vectors.dense(2.0, 1.3, 1.0)),
(1.0, Vectors.dense(0.0, 1.2, -0.5)))
).toDF("label","features")
//创建一个LogisticRegression实例,该实例是一个Estimator
val lr = new LogisticRegression()
//使用setter函数设置参数
lr.setMaxIter(10).setRegParam(0.01)
//学习一个回归模型,使用存储在lr中的参数
val model1 = lr.fit(training)
//由于model1是一个模型(即Estimator生成的Transformer),我们可以查看它//在fit()中使用的参数。
//打印参数(名称:值)对,其中名称是此
println("Model 1 was fit usingparameters: " + model1.parent.extractParamMap)
//我们也可以使用ParamMap指定参数,
//它支持几种指定参数的方法。
val paramMap = ParamMap(lr.maxIter ->20).put(lr.maxIter, 30).put(lr.regParam -> 0.1, lr.threshold -> 0.55)
// 修改输出列名称
val paramMap2 = ParamMap(lr.probabilityCol-> "myProbability")
//还可以结合ParamMaps。
val paramMapCombined = paramMap ++paramMap2
//现在使用paramMapCombined参数学习一个新的模型。
// paramMapCombined覆盖之前通过lr.set*方法设置的所有参数。
val model2 = lr.fit(training,paramMapCombined)
println("Model 2 was fit usingparameters: " + model2.parent.extractParamMap)
//准备测试数据
val test = spark.createDataFrame(Seq((1.0,Vectors.dense(-1.0, 1.5, 1.3)),(0.0, Vectors.dense(3.0, 2.0, -0.1)),(1.0,Vectors.dense(0.0, 2.2, -1.5)))).toDF("label", "features")
//使用Transformer.transform()方法对测试数据进行预测。
// LogisticRegression.transform将仅使用“特征”列。
//注意model2.transform()输出一个'myProbability'列,而不是通常的
//'probability'列,因为之前我们重命名了lr.probabilityCol参数。
model2.transform(test).select("features","label", "myProbability","prediction").collect().foreach { case Row(features: Vector, label:Double, prob: Vector, prediction: Double) =>println(s"($features,$label) -> prob=$prob, prediction=$prediction")} 2.2 Pipeline
import org.apache.spark.ml.{Pipeline,PipelineModel}
importorg.apache.spark.ml.classification.LogisticRegression
import org.apache.spark.ml.feature.{HashingTF,Tokenizer}
import org.apache.spark.ml.linalg.Vector
import org.apache.spark.sql.Row
// 准备数据数据类型:(id, text,label).
val training = spark.createDataFrame(
Seq((0L, "a b c d e spark", 1.0),
(1L, "b d", 0.0),(2L, "spark f g h", 1.0),
(3L, "hadoop mapreduce", 0.0))
).toDF("id", "text","label")
//设计一个包含三个stage的ML pipeline:tokenizer, hashingTF, and lr.
val tokenizer = newTokenizer().setInputCol("text").setOutputCol("words")
val hashingTF = newHashingTF().setNumFeatures(1000).setInputCol(tokenizer.getOutputCol).setOutputCol("features")
val lr = newLogisticRegression().setMaxIter(10).setRegParam(0.001)
val pipeline = newPipeline().setStages(Array(tokenizer, hashingTF, lr))
// 调用fit,训练数据
val model = pipeline.fit(training)
// 可以将训练好的pipeline输出到磁盘
model.write.overwrite().save("/opt/spark-logistic-regression-model")
// 也可以直接将为进行训练的pipeline写到文件
pipeline.write.overwrite().save("/opt/unfit-lr-model")
// 加载到出来
val sameModel = PipelineModel.load("/opt/spark-logistic-regression-model")
// (id, text) 这个格式未打标签的数据进行测试
val test = spark.createDataFrame(Seq((4L,"spark i j k"),(5L, "l m n"),(6L, "spark hadoopspark"),(7L, "apache hadoop"))).toDF("id","text")
// 在测试集上进行预测
model.transform(test).select("id","text", "probability","prediction").collect().foreach { case Row(id: Long, text: String,prob: Vector, prediction: Double) =>println(s"($id, $text) -->prob=$prob, prediction=$prediction")}