双目测距原理
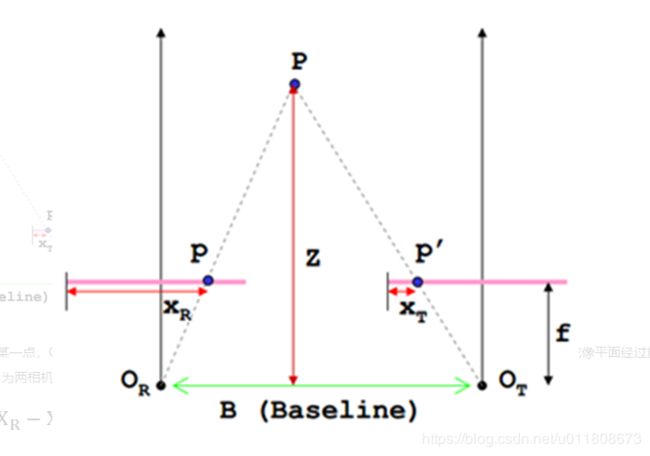
双目测距基本原理:

双目测距实际操作分4个步骤:相机标定——双目校正——双目匹配——计算深度信息。
相机标定:摄像头由于光学透镜的特性使得成像存在着径向畸变,可由三个参数k1,k2,k3确定;由于装配方面的误差,传感器与光学镜头之间并非完全平行,因此成像存在切向畸变,可由两个参数p1,p2确定。单个摄像头的定标主要是计算出摄像头的内参(焦距f和成像原点cx,cy、五个畸变参数(一般只需要计算出k1,k2,p1,p2,对于鱼眼镜头等径向畸变特别大的才需要计算k3))以及外参(标定物的世界坐标)。而双目摄像头定标不仅要得出每个摄像头的内部参数,还需要通过标定来测量两个摄像头之间的相对位置(即右摄像头相对于左摄像头的旋转矩阵R、平移向量t)。
双目校正:双目校正是根据摄像头定标后获得的单目内参数据(焦距、成像原点、畸变系数)和双目相对位置关系(旋转矩阵和平移向量),分别对左右视图进行消除畸变和行对准,使得左右视图的成像原点坐标一致(CV_CALIB_ZERO_DISPARITY标志位设置时发生作用)、两摄像头光轴平行、左右成像平面共面、对极线行对齐。这样一幅图像上任意一点与其在另一幅图像上的对应点就必然具有相同的行号,只需在该行进行一维搜索即可匹配到对应点。
双目匹配:双目匹配的作用是把同一场景在左右视图上对应的像点匹配起来,这样做的目的是为了得到视差图。双目匹配被普遍认为是立体视觉中最困难也是最关键的问题。得到视差数据,通过上述原理中的公式就可以很容易的计算出深度信息。
双目摄像机的物理机构
网上大部分人都写了这一点,也仿佛只有这一点有写的价值和物理意义。
这里本来想放个控件(可调节动画),一直弄不上来,就算了。需要的可以联系我要下,下面放两张图片。
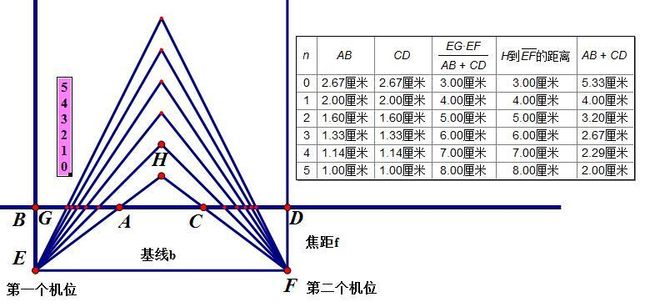
图中可以得出的结论
1.深度变化(EG*EF/(AB+CD)或者H到EF的距离),会导致AB,CD和AB+CD的变化,这里不过多强调AB,CD的变化,只讨论AB+CD,这个原因后边会提到。当深度变大时,AB+CD逐渐变小。
从公式(公式看不懂没关系,它只是我推导的,大家也可以自己推一下,推导是三角形的比例关系)
AC=EF-AB-DC
设Z为深度
那么AC/EF=(Z-EG)/Z
这样就可以推导出来了。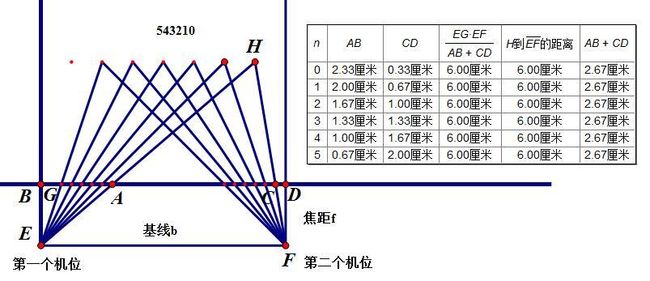
从这个图我们就可以明显看出只要我们的深度不变,那么我们的AB+CD也就不会改变,可以看出,深度和单独的AB与CD没有直接关系,而只与两者的和有关。
AB+CD 与同一距离的 视差 是想等的。
AB + DC = XR - XT
注意此处 AB DC 用向量相加 (AB + DC = = (Bx-Ax)+ (Cx - Dx) 【Bx 为左图像的中点x, Dx为右图像的中点x Ax,Cx为两幅图同一特征点的x坐标】
XR - XT = XRx - XTx (XRx 与 XTx 分别是两幅图同一特征点的x坐标)
备注:此处的公式都是假设摄像头是水平的,如果摄像头垂直,应该使用 y 坐标。
单目测距原理:
先通过图像匹配进行目标识别(各种车型、行人、物体等),再通过目标在图像中的大小去估算目标距离。这就要求在估算距离之前首先对目标进行准确识别,是汽车还是行人,是货车、SUV还是小轿车。准确识别是准确估算距离的第一步。要做到这一点,就需要建立并不断维护一个庞大的样本特征数据库,保证这个数据库包含待识别目标的全部特征数据。比如在一些特殊地区,为了专门检测大型动物,必须先行建立大型动物的数据库;而对于另外某些区域存在一些非常规车型,也要先将这些车型的特征数据加入到数据库中。如果缺乏待识别目标的特征数据,就会导致系统无法对这些车型、物体、障碍物进行识别,从而也就无法准确估算这些目标的距离。
单/双目方案的优点与难点
从上面的介绍,单目系统的优势在于成本较低,对计算资源的要求不高,系统结构相对简单;缺点是:(1)需要不断更新和维护一个庞大的样本数据库,才能保证系统达到较高的识别率;(2)无法对非标准障碍物进行判断;(3)距离并非真正意义上的测量,准确度较低。
双目检测原理:
通过对两幅图像视差的计算,直接对前方景物(图像所拍摄到的范围)进行距离测量,而无需判断前方出现的是什么类型的障碍物。所以对于任何类型的障碍物,都能根据距离信息的变化,进行必要的预警或制动。双目摄像头的原理与人眼相似。人眼能够感知物体的远近,是由于两只眼睛对同一个物体呈现的图像存在差异,也称“视差”。物体距离越远,视差越小;反之,视差越大。视差的大小对应着物体与眼睛之间距离的远近,这也是3D电影能够使人有立体层次感知的原因。

上图中的人和椰子树,人在前,椰子树在后,最下方是双目相机中的成像。其中,右侧相机成像中人在树的左侧,左侧相机成像中人在树的右侧,这是因为双目的角度不一样。再通过对比两幅图像就可以知道人眼观察树的时候视差小,而观察人时视差大。因为树的距离远,人的距离近。这就是双目三角测距的原理。双目系统对目标物体距离感知是一种绝对的测量,而非估算。
理想双目相机成像模型

根据上述推导,要求得空间点P离相机的距离(深度)z,必须知道:
1、相机焦距f,左右相机基线b(可以通过先验信息或者相机标定得到)。
2、视差 : ,即左相机像素点(xl, yl)和右相机中对应点(xr, yr)的关系,这是双目视觉的核心问题。
,即左相机像素点(xl, yl)和右相机中对应点(xr, yr)的关系,这是双目视觉的核心问题。
重点来看一下视差(disparity),视差是同一个空间点在两个相机成像中对应的x坐标的差值,它可以通过编码成灰度图来反映出距离的远近,离镜头越近的灰度越亮; (前提是两个摄像头是水平,如果两颗摄像头是垂直的,则使用y坐标的差值)

极线约束
对于左图中的一个像素点,如何确定该点在右图中的位置?需要在整个图像中地毯式搜索吗?当然不用,此时需要用到极线约束。
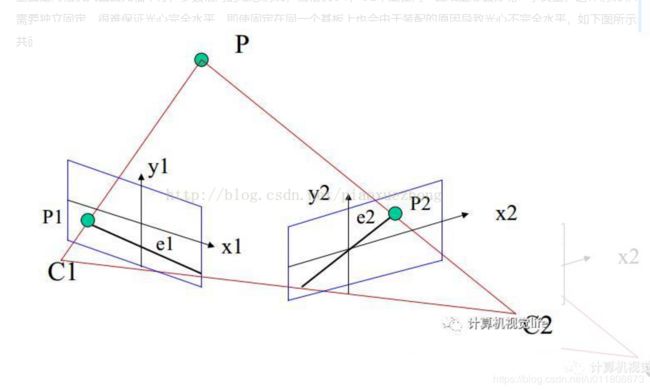
如上图所示。O1,O2是两个相机,P是空间中的一个点,P和两个相机中心点O1、O2形成了三维空间中的一个平面PO1O2,称为极平面(Epipolar plane)。极平面和两幅图像相交于两条直线,这两条直线称为极线(Epipolar line)。
P在相机O1中的成像点是P1,在相机O2中的成像点是P2,但是P的位置是未知的。我们的目标是:对于左图的P1点,寻找它在右图中的对应点P2,这样就能确定P点的空间位置。
极线约束(Epipolar Constraint)是指当空间点在两幅图像上分别成像时,已知左图投影点p1,那么对应右图投影点p2一定在相对于p1的极线上,这样可以极大的缩小匹配范围。即P2一定在对应极线上,所以只需要沿着极线搜索便可以找到P1的对应点P2。
非理性情况:
上面是两相机共面且光轴平行,参数相同的理想情况,当相机O1,O2不是在同一直线上怎么办呢?事实上,这种情况非常常见,因为有些场景下两个相机需要独立固定,很难保证光心完全水平,即使固定在同一个基板上也会由于装配的原因导致光心不完全水平,如下图所示:两个相机的极线不平行,并且不共面。
这种情况下拍摄的两张左右图片,如下图所示。
左图中三个十字标志的点,右图中对应的极线是右图中的三条白色直线,也就是对应的搜索区域。我们看到这三条直线并不是水平的,如果进行逐点搜索效率非常低。

图像矫正技术
图像矫正是通过分别对两张图片用单应性矩阵(homography matrix)变换得到,目的是把两个不同方向的图像平面(下图中灰色平面)重新投影到同一个平面且光轴互相平行(下图中黄色平面),这样转化为理想情况的模型。

经过图像矫正后,左图中的像素点只需要沿着水平的极线方向搜索对应点就可以了。从下图中我们可以看到三个点对应的视差(红色双箭头线段)是不同的,越远的物体视差越小,越近的物体视差越大。


上面的主要工作是在极线上寻找匹配点,但是由于要保证两个相机参数完全一致是不现实的,并且外界光照变化和视角不同的影响,使得单个像素点鲁棒性很差。所以匹配工作是一项很重要的事情,这也关系着双目视觉测距的准确性。
双目视觉的工作流程
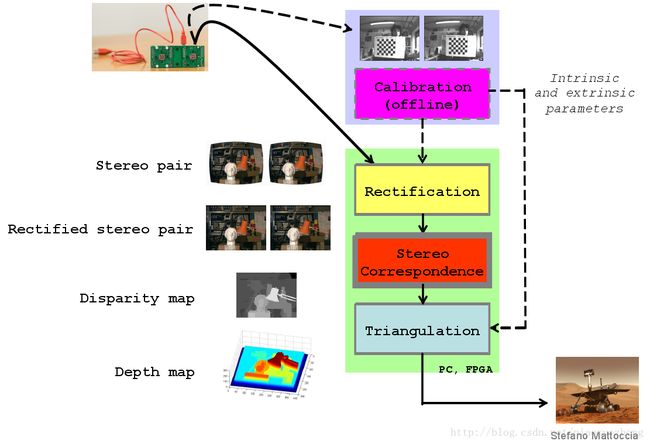
相机镜头畸变校正原理及方法,之前介绍过,这个基本是通用的,可以用张正友校准法。
双目测距的优点与难点
从上面的介绍看出,双目系统优势:(1)成本比单目系统要高,但尚处于可接受范围内,并且与激光雷达等方案相比成本较低;(2)没有识别率的限制,因为从原理上无需先进行识别再进行测算,而是对所有障碍物直接进行测量;(3)直接利用视差计算距离,精度比单目高;(4)无需维护样本数据库,因为对于双目没有样本的概念。
双目系统的难点:
(1)计算量非常大,对计算单元的性能要求非常高,这使得双目系统的产品化、小型化的难度较大。所以在芯片或FPGA上解决双目的计算问题难度比较大。国际上使用双目的研究机构或厂商,绝大多数是使用服务器进行图像处理与计算,也有部分将算法进行简化后,使用FPGA进行处理。
(2)双目的配准效果,直接影响到测距的准确性。
2.1、对环境光照非常敏感。双目立体视觉法依赖环境中的自然光线采集图像,而由于光照角度变化、光照强度变化等环境因素的影响,拍摄的两张图片亮度差别会比较大,这会对匹配算法提出很大的挑战。


2.2、不适用于单调缺乏纹理的场景。由于双目立体视觉法根据视觉特征进行图像匹配,所以对于缺乏视觉特征的场景(如天空、白墙、沙漠等)会出现匹配困难,导致匹配误差较大甚至匹配失败。

2.3、计算复杂度高。该方法需要逐像素匹配;又因为上述多种因素的影响,为保证匹配结果的鲁棒性,需要在算法中增加大量的错误剔除策略,因此对算法要求较高,想要实现可靠商用难度大,计算量较大。
2.4、相机基线限制了测量范围。测量范围和基线(两个摄像头间距)关系很大:基线越大,测量范围越远;基线越小,测量范围越近。所以基线在一定程度上限制了该深度相机的测量范围。
---------------项目开源:-----------
卡内基梅隆大学双目实验室
Oxford大牛:Andrew Zisserman,http://www.robots.ox.ac.uk/~vgg/hzbook/code/,主要研究多幅图像的几何学,该网站提供了部分工具,相当实用,还有例子
Cambridge:http://mi.eng.cam.ac.uk/milab.html,剑桥大学的机器智能实验室,里面有三个小组,Computer Vision & Robotics, Machine Intelligence, Speech
stanford:http://ai.stanford.edu/~asaxena/reconstruction3d/,主要对于单张照片的三维重建
caltech:http://www.vision.caltech.edu/bouguetj/calib_doc/,这是我们Computer Vision老师课件上的连接,主要是用于摄像机标定的工具集,当然也有涉及对标定图像三维重建的前期处理过程
JP Tarel:http://perso.lcpc.fr/tarel.jean-philippe/,个人主页
------------匹配与3D重建算法:-----------
https://www.cnblogs.com/polly333/p/5130375.html
http://blog.csdn.net/wangyaninglm/article/details/51533549
http://blog.csdn.net/wangyaninglm/article/details/51531333
https://www.zhihu.com/question/29885222?sort=created
http://blog.csdn.net/wangyaninglm/article/details/51558656
http://blog.csdn.net/wangyaninglm/article/details/51558310
https://www.cnblogs.com/mysunnyday/archive/2011/05/09/2041115.html
参考:
https://blog.csdn.net/piaoxuezhong/article/details/79016615
http://m.blog.csdn.net/article/details?id=52829190
https://blog.csdn.net/a6333230/article/details/82865439
https://blog.csdn.net/bit_cs2010/article/details/52829190