redis从单点、主从、哨兵、到集群的总结(阶段性总结)
我最近看项目:发现我们当前项目用的redis是主从,但是跟单点其实没有什么区别,因为我们在应用层面没有做读写分离,所以其实从服务器只是做了一个主从复制的工作,其他的什么都没有做。
那么如果我们的系统升级,用户量上升,那么一主一从可能扛不住那么大的压力,可能需要一主多从做备机,那么假如主服务器宕机了,选举哪台从服务器做主呢?这就是一个问题,需要一个第三个人来解决,所以我查了一下,哨兵模式可以解决这个问题。哨兵模式的细节下面会讲到。
然后我又想了,那如果单台服务器无法承受100%的存储压力,那就应该将存储压力分散开来,所以集群就可以解决这个问题 了,比如我们用6台服务器做集群,3主3从,那么每台服务器只需要存储1/3即可。好,那么我们就来详细看一下这些具体怎么做的。
一、redis单点(主从)
基本上就是一主一从,我们应用层主要使用的是主节点,从节点的主要工作是从主节点做主从复制。关键时刻,如果主服务器挂掉,可以手动启动从服务器,然后更改应用层的redis的ip即可。
二、redis读写分离
常见的应用场景下我觉得redis没必要进行读写分离。
先来讨论一下为什么要读写分离:
读写分离使用于大量读请求的情况,通过多个slave分摊了读的压力,从而增加了读的性能。
过多的select会阻塞住数据库,使你增删改不能执行,而且到并发量过大时,数据库会拒绝服务。
因而通过读写分离,从而增加性能,避免拒绝服务的发生。
我认为需要读写分离的应用场景是:写请求在可接受范围内,但读请求要远大于写请求的场景。
再来讨论一下redis常见的应用场景:
-
1.缓存
-
2. 排名型的应用,访问计数型应用
-
3. 实时消息系统
首先说一下缓存集群,这也是非常常见的应用场景:
-
缓存主要解决的是用户访问时,怎么以更快的速度得到数据。
-
2. 单机的内存资源是很有限的,所以缓存集群会通过某种算法将不同的数据放入到不同的机器中。
-
3. 不同持久化数据库,一般来说,内存数据库单机可以支持大量的增删查改。
-
4. 如果一台机器支持不住,可以用主从复制,进行缓存的方法解决。
-
综上,在这个场景下应用redis 进行读写分离,完全就失去了读写分离的意义。
当然,也有可能我考虑不到的地方需要读写分离,毕竟“存在即合理”嘛,那么我们就来介绍一下这个读写分离吧。
读写分离:
对于读占比较高的场景,可以通过把一部分流量分摊导出从节点(salve) 来减轻主节点(master)压力,同时需要主要只对主节点执行写操作,如下图:
当使用从节点响应读请求时,业务端可能会遇到以下问题:
复制数据延迟
读到过期数据
从节点故障
1.数据延迟
Redis 复制数的延迟由于异步复制特性是无法避免的,延迟取决于网络带宽和命令阻塞情况,对于无法容忍大量延迟场景,可以编写外部监控程序监听主从节点的复制偏移量,当延迟较大时触发报警或者通知客户端避免读取延迟过高的从节点,实现逻辑如下图:
说明如下:
1) 监控程序(monitor) 定期检查主从节点的偏移量,主节点偏移量在info replication 的master_repl_offset 指标记录,从节点 偏移量可以查询主节点的slave0 字段的offset指标,它们的差值就是主从节点延迟的字节 量。
2)当延迟字节量过高时,比如超过10M。监控程序触发报警并通知客户端从节点延迟过高。可以采用Zookeeper的监听回调机制实现客户端通知。
3) 客户端接到具体的从节点高延迟通知后,修改读命令路由到其他从节点或主节点上。当延迟回复后,再次通知客户端,回复从节点的读命令请求。
这种方案成本较高,需要单独修改适配Redis的客户端类库。
2.读到过期数据
当主节点存储大量设置超时的数据时,如缓存数据,Redis内部需要维护过期数据删除策略,删除策略主要有两种:惰性删除和定时删除。
惰性删除:主节点每次处理读取命令时,都会检查键是否超时,如果超时则执行del命令删除键对象那个,之后del命令也会异步 发送给 从节点
需要注意的是为了保证复制的一致性,从节点自身永远不会主动删除超时数据,如上图。
定时删除:
Redis主节点在内部定时任务会循环采样一定数量的键,当发现采样的键过期就执行del命令,之后再同步给从节点,如下图
如果此时 数据的大量超时,主节点采样速度跟不上过期速度且主节点没有读取过期键的操作,那么从节点将无法收到del命令,这时在从节点 上可以读取到已经超时的数据。Redis在3.2 版本解决了这个问题,从节点 读取数据之前会检查键的过期时间来决定是否返回数据,可以升级到3.2版本来规避这个问题。
3.从节点故障问题
对于从节点故障问题,需要在客户端维护可用从节点列表,当从节点故障时立刻切换到其他从节点或主节点上。
但是建议如果仅仅是为性能考虑的话最好使用集群。
运维操作:
准备三个redis服务,依次命名文件夹子master,slave1,slave2.这里为在测试机上,不干扰原来的redis服务,我们master使用6000端口。
配置文件(redis.conf)
master配置修改端口:
port 6000
requirepass 123456
slave1修改配置:
port 6001
slaveof 127.0.0.1 6000
masterauth 123456
requirepass 123456
slave2修改配置:
port 6002
slaveof 127.0.0.1 6000
masterauth 123456
requirepass 123456requirepass是认证密码,应该之后要作主从切换,所以建议所有的密码都一致, masterauth是从机对主机验证时,所需的密码。(即主机的requirepass)
启动主机
redis-server redis.conf 启动从机:
redis-server redis1.conf
redis-server redis2.conf输入:
ps -ef |grep redisroot 6617 1 0 18:34 ? 00:00:01 redis-server *:6000
root 6647 1 0 18:43 ? 00:00:00 redis-server *:6001
root 6653 1 0 18:43 ? 00:00:00 redis-server *:6002
root 6658 6570 0 18:43 pts/0 00:00:00 grep redis可以看到主从机的redis已经相应启动。
我们来验证下 主从复制。
master:
[root@localhost master]# redis-cli -p 6000
127.0.0.1:6000> auth 123456
OK
127.0.0.1:6000> set test chenqm
OKslave1:
[root@localhost slave2]# redis-cli -p 6001
127.0.0.1:6001> auth 123456
OK
127.0.0.1:6001> get test
"chenqm"slave2:
[root@localhost slave2]# redis-cli -p 6002
127.0.0.1:6002> auth 123456
OK
127.0.0.1:6002> get test
"chenqm"
可以看到主机执行写命令,从机能同步主机的值,主从复制,读写分离就实现了。
三、一主多从的哨兵模式
工作原理:
1.用户链接时先通过哨兵获取主机Master的信息
2.获取Master的链接后实现redis的操作(set/get)
3.当master出现宕机时,哨兵的心跳检测发现主机长时间没有响应.这时哨兵会进行推选.推选出新的主机完成任务.
4.当新的主机出现时,其余的全部机器都充当该主机的从机
这就有一个问题,就是添加哨兵以后,所有的请求都会经过哨兵询问当前的主服务器是谁,所以如果哨兵部在主服务器上面的话可能会增加服务器的压力,所以最好是将哨兵单独放在一个服务器上面。以分解压力。然后可能还有人担心哨兵服务器宕机了怎么办啊,首先哨兵服务器宕机的可能性很小,然后是如果哨兵服务器宕机了,使用人工干预重启即可,就会导致主从服务器监控的暂时不可用,不影响主从服务器的正常运行。
先配置服务器(本地)哨兵模式,直接从redis官网下载安装或者解压版,安装后的目录结构

然后配置哨兵模式
测试采用3个哨兵,1个主redis,2个从redis。
复制6份redis.windows.conf文件并重命名如下(开发者可根据自己的开发习惯进行重命名)
配置master.6378.conf
port:6379
#设置连接密码
requirepass:grs
#连接密码
masterauth:grsslave.6380.conf配置
port:6380
dbfilename dump6380.rdb
#配置master
slaveof 127.0.0.1 6379slave.6381.conf配置
port 6381
slaveof 127.0.0.1 6379
dbfilename "dump.rdb"配置哨兵sentinel.63791.conf(其他两个哨兵配置文件一致,只修改端口号码即可)
port 63791
#主master,2个sentinel选举成功后才有效,这里的master-1是名称,在整合的时候需要一致,这里可以随便更改
sentinel monitor master-1 127.0.0.1 6379 2
#判断主master的挂机时间(毫秒),超时未返回正确信息后标记为sdown状态
sentinel down-after-milliseconds master-1 5000
#若sentinel在该配置值内未能完成failover操作(即故障时master/slave自动切换),则认为本次failover失败。
sentinel failover-timeout master-1 18000
#选项指定了在执行故障转移时, 最多可以有多少个从服务器同时对新的主服务器进行同步,这个数字越小,完成故障转移所需的时间就越长
sentinel config-epoch master-1 2需要注意的地方
1、若通过redis-cli -h 127.0.0.1 -p 6379连接,无需改变配置文件,配置文件默认配置为bind 127.0.0.1(只允许127.0.0.1连接访问)若通过redis-cli -h 192.168.180.78 -p 6379连接,需改变配置文件,配置信息为bind 127.0.0.1 192.168.180.78(只允许127.0.0.1和192.168.180.78访问)或者将bind 127.0.0.1注释掉(允许所有远程访问)
2、masterauth为所要连接的master服务器的requirepass,如果一个redis集群中有一个master服务器,两个slave服务器,当master服务器挂掉时,sentinel哨兵会随机选择一个slave服务器充当master服务器,鉴于这种机制,解决办法是将所有的主从服务器的requirepass和masterauth都设置为一样。
3、sentinel monitor master-1 127.0.0.1 6379 2 行尾最后的一个2代表什么意思呢?我们知道,网络是不可靠的,有时候一个sentinel会因为网络堵塞而误以为一个master redis已经死掉了,当sentinel集群式,解决这个问题的方法就变得很简单,只需要多个sentinel互相沟通来确认某个master是否真的死了,这个2代表,当集群中有2个sentinel认为master死了时,才能真正认为该master已经不可用了。(sentinel集群中各个sentinel也有互相通信,通过gossip协议)。
依次启动redis
redis-server master.6379.conf
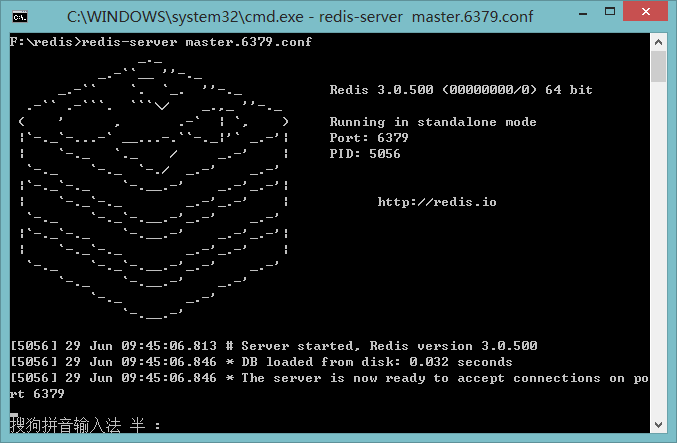
redis-server slave.6380.conf

redis-server slave.6381.conf
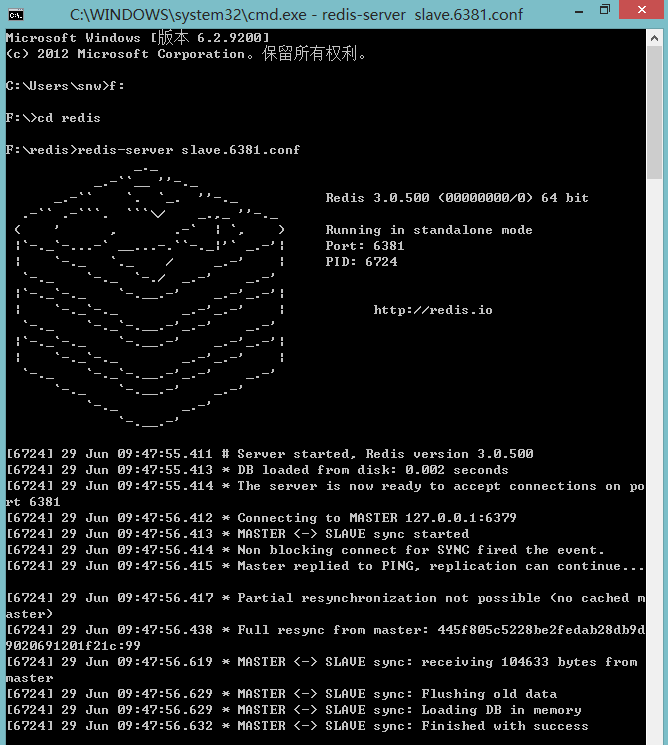
redis-server sentinel.63791.conf --sentinel(linux:redis-sentinel sentinel.63791.conf)其他两个哨兵也这样启动

使用客户端查看一下master状态
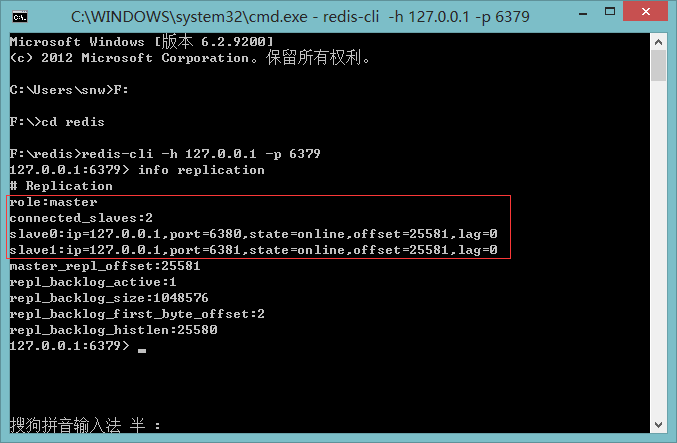
查看一下哨兵状态

现在就可以在master插入数据,所有的redis服务都可以获取到,slave只能读
整合spring,导入依赖
redis.clients
jedis
2.8.0
org.springframework.data
spring-data-redis
1.6.4.RELEASE
org.apache.commons
commons-pool2
2.4.2
redis.properties
#redis中心
redis.host=127.0.0.1
#redis.host=10.75.202.11
redis.port=6379
redis.password=
#redis.password=123456
redis.maxTotal=200
redis.maxIdle=100
redis.minIdle=8
redis.maxWaitMillis=100000
redis.maxActive=300
redis.testOnBorrow=true
redis.testOnReturn=true
#Idle时进行连接扫描
redis.testWhileIdle=true
#表示idle object evitor两次扫描之间要sleep的毫秒数
redis.timeBetweenEvictionRunsMillis=30000
#表示idle object evitor每次扫描的最多的对象数
redis.numTestsPerEvictionRun=10
#表示一个对象至少停留在idle状态的最短时间,然后才能被idle object evitor扫描并驱逐;这一项只有在timeBetweenEvictionRunsMillis大于0时才有意义
redis.minEvictableIdleTimeMillis=60000
redis.timeout=100000配置sentinel方式一
配置sentinel方式二
spring-redis-sentinel.properties内容:
#哨兵监控主redis节点名称,必选
spring.redis.sentinel.master=mymaster
#哨兵节点
spring.redis.sentinel.nodes=192.168.48.31:26379,192.168.48.32:26379,192.168.48.33:26379xml配置
com.service.impl...*ServiceImpl.*
RedisConfiguration类
import static org.springframework.util.Assert.notNull;
import java.util.Set;
import org.springframework.data.redis.connection.RedisNode;
import org.springframework.data.redis.connection.RedisSentinelConfiguration;
public class RedisConfiguration extends RedisSentinelConfiguration{
public RedisConfiguration(){}
public RedisConfiguration(Iterable sentinels){
notNull(sentinels, "Cannot set sentinels to 'null'.");
Set sentinels2 = getSentinels();
if(!sentinels2.isEmpty()){
sentinels2.clear();
}
for (RedisNode sentinel : sentinels) {
addSentinel(sentinel);
}
}
} MethodCacheInterceptor拦截器
import java.lang.reflect.Method;
import org.aopalliance.intercept.MethodInterceptor;
import org.aopalliance.intercept.MethodInvocation;
import com.uec.village.annotation.RedisCache;
import com.uec.village.util.RedisUtil;
/**
* 用户登录过滤器
* @author snw
*
*/
public class MethodCacheInterceptor implements MethodInterceptor {
private RedisUtil redisUtil;
/**
* 初始化读取不需要加入缓存的类名和方法名称
*/
public MethodCacheInterceptor() {
}
@Override
public Object invoke(MethodInvocation invocation) throws Throwable {
Object value = null;
String targetName = invocation.getThis().getClass().getName();
Method method = invocation.getMethod();
String methodName = method.getName();
RedisCache annotation = method.getAnnotation(RedisCache.class);
//说明当前方法不需要缓存的,
if(annotation == null){
return invocation.proceed();
}
Object[] arguments = invocation.getArguments();
String key = getCacheKey(targetName, methodName, arguments);
System.out.println(key);
try {
// 判断是否有缓存
if (redisUtil.exists(key)) {
System.out.println("方法名称为:"+methodName+",根据:"+key+",从缓存中获取");
return redisUtil.get(key);
}
// 写入缓存
value = invocation.proceed();
if (value != null) {
final String tkey = key;
final Object tvalue = value;
if(annotation.isTime()){
redisUtil.set(tkey, tvalue);
}
}
return value;
} catch (Exception e) {
e.printStackTrace();
if (value == null) {
return invocation.proceed();
}
}
return value;
}
/**
* 创建缓存key
*
* @param targetName
* @param methodName
* @param arguments
*/
private String getCacheKey(String targetName, String methodName,
Object[] arguments) {
StringBuffer sbu = new StringBuffer();
sbu.append(targetName).append("_").append(methodName);
if ((arguments != null) && (arguments.length != 0)) {
for (int i = 0; i < arguments.length; i++) {
sbu.append("_").append(arguments[i]);
}
}
return sbu.toString();
}
public void setRedisUtil(RedisUtil redisUtil) {
this.redisUtil = redisUtil;
}
}redis工具类
import java.io.Serializable;
import java.util.Set;
import java.util.concurrent.TimeUnit;
import org.springframework.data.redis.core.RedisTemplate;
import org.springframework.data.redis.core.ValueOperations;
/**
* redis工具
* @author snw
*
*/
public class RedisUtil {
private RedisTemplate redisTemplate;
/**
* 批量删除对应的value
*
* @param keys
*/
public void remove(final String... keys) {
for (String key : keys) {
remove(key);
}
}
/**
* 批量删除key
*
* @param pattern
*/
public void removePattern(final String pattern) {
Set keys = redisTemplate.keys(pattern);
if (keys.size() > 0)
redisTemplate.delete(keys);
}
/**
* 删除对应的value
*
* @param key
*/
public void remove(final String key) {
if (exists(key)) {
redisTemplate.delete(key);
}
}
/**
* 判断缓存中是否有对应的value
*
* @param key
* @return
*/
public boolean exists(final String key) {
return redisTemplate.hasKey(key);
}
/**
* 读取缓存
*
* @param key
* @return
*/
public Object get(final String key) {
Object result = null;
ValueOperations operations = redisTemplate
.opsForValue();
result = operations.get(key);
return result;
}
/**
* 写入缓存
*
* @param key
* @param value
* @return
*/
public boolean set(final String key, Object value) {
boolean result = false;
try {
ValueOperations operations = redisTemplate
.opsForValue();
operations.set(key, value);
result = true;
} catch (Exception e) {
e.printStackTrace();
}
return result;
}
/**
* 写入缓存
*
* @param key
* @param value
* @return
*/
public boolean set(final String key, Object value, Long expireTime) {
boolean result = false;
try {
ValueOperations operations = redisTemplate
.opsForValue();
operations.set(key, value);
redisTemplate.expire(key, expireTime, TimeUnit.SECONDS);
result = true;
} catch (Exception e) {
e.printStackTrace();
}
return result;
}
public void setRedisTemplate(
RedisTemplate redisTemplate) {
this.redisTemplate = redisTemplate;
}
} 自定义注解
import java.lang.annotation.ElementType;
import java.lang.annotation.Retention;
import java.lang.annotation.RetentionPolicy;
import java.lang.annotation.Target;
@Target(ElementType.METHOD)
@Retention(RetentionPolicy.RUNTIME)
public @interface RedisCache {
boolean isCache() default false;
}
四、集群模式
一、概述
Redis3.0版本之后支持Cluster.
1.1、redis cluster的现状
目前redis支持的cluster特性:
1):节点自动发现
2):slave->master 选举,集群容错
3):Hot resharding:在线分片
4):进群管理:cluster xxx
5):基于配置(nodes-port.conf)的集群管理
6):ASK 转向/MOVED 转向机制.
1.2、redis cluster 架构
1)redis-cluster架构图

架构细节:
(1)所有的redis节点彼此互联(PING-PONG机制),内部使用二进制协议优化传输速度和带宽.
(2)节点的fail是通过集群中超过半数的节点检测失效时才生效.
(3)客户端与redis节点直连,不需要中间proxy层.客户端不需要连接集群所有节点,连接集群中任何一个可用节点即可
(4)redis-cluster把所有的物理节点映射到[0-16383]slot上,cluster 负责维护node<->slot<->value
2) redis-cluster选举:容错
(1)领着选举过程是集群中所有master参与,如果半数以上master节点与master节点通信超过(cluster-node-timeout),认为当前master节点挂掉.
(2):什么时候整个集群不可用(cluster_state:fail),当集群不可用时,所有对集群的操作做都不可用,收到((error) CLUSTERDOWN The cluster is down)错误
a:如果集群任意master挂掉,且当前master没有slave.集群进入fail状态,也可以理解成进群的slot映射[0-16383]不完成时进入fail状态.
b:如果进群超过半数以上master挂掉,无论是否有slave集群进入fail状态.
二、redis cluster安装
1、下载和解包
| 1 2 3 |
|
2、 编译安装
cd redis-3.2.1 make && make install
3、创建redis节点
测试我们选择2台服务器,分别为:192.168.1.237,192.168.1.238.每分服务器有3个节点。
我先在192.168.1.237创建3个节点:
cd /usr/local/
mkdir redis_cluster //创建集群目录
mkdir 7000 7001 7002 //分别代表三个节点 其对应端口 7000 7001 7002
//创建7000节点为例,拷贝到7000目录
cp /usr/local/redis-3.2.1/redis.conf ./redis_cluster/7000/
//拷贝到7001目录
cp /usr/local/redis-3.2.1/redis.conf ./redis_cluster/7001/
//拷贝到7002目录
cp /usr/local/redis-3.2.1/redis.conf ./redis_cluster/7002/分别对7001,7002、7003文件夹中的3个文件修改对应的配置
daemonize yes //redis后台运行
pidfile /var/run/redis_7000.pid //pidfile文件对应7000,7002,7003
port 7000 //端口7000,7002,7003
cluster-enabled yes //开启集群 把注释#去掉
cluster-config-file nodes_7000.conf //集群的配置 配置文件首次启动自动生成 7000,7001,7002
cluster-node-timeout 5000 //请求超时 设置5秒够了
appendonly yes //aof日志开启 有需要就开启,它会每次写操作都记录一条日志在192.168.1.238创建3个节点:对应的端口改为7003,7004,7005.配置对应的改一下就可以了。
4、两台机启动各节点(两台服务器方式一样)
cd /usr/local
redis-server redis_cluster/7000/redis.conf
redis-server redis_cluster/7001/redis.conf
redis-server redis_cluster/7002/redis.conf
redis-server redis_cluster/7003/redis.conf
redis-server redis_cluster/7004/redis.conf
redis-server redis_cluster/7005/redis.conf5、查看服务
ps -ef | grep redis #查看是否启动成功
netstat -tnlp | grep redis #可以看到redis监听端口
三、创建集群
前面已经准备好了搭建集群的redis节点,接下来我们要把这些节点都串连起来搭建集群。官方提供了一个工具:redis-trib.rb(/usr/local/redis-3.2.1/src/redis-trib.rb) 看后缀就知道这鸟东西不能直接执行,它是用ruby写的一个程序,所以我们还得安装ruby.
yum -y install ruby ruby-devel rubygems rpm-build
再用 gem 这个命令来安装 redis接口 gem是ruby的一个工具包.
gem install redis //等一会儿就好了 当然,方便操作,两台Server都要安装。
上面的步骤完事了,接下来运行一下redis-trib.rb
/usr/local/redis-3.2.1/src/redis-trib.rb
Usage: redis-trib
reshard host:port
--to
--yes
--slots
--from
check host:port
call host:port command arg arg .. arg
set-timeout host:port milliseconds
add-node new_host:new_port existing_host:existing_port
--master-id
--slave
del-node host:port node_id
fix host:port
import host:port
--from
help (show this help)
create host1:port1 ... hostN:portN
--replicas
For check, fix, reshard, del-node, set-timeout you can specify the host and port of any working node in the cluster.
看到这,应该明白了吧, 就是靠上面这些操作 完成redis集群搭建的.
确认所有的节点都启动,接下来使用参数create 创建 (在192.168.1.237中来创建)
/usr/local/redis-3.2.1/src/redis-trib.rb create --replicas 1 192.168.1.237:7000 192.168.1.237:7001 192.168.1.237:7003 192.168.1.238:7003 192.168.1.238:7004 192.168.1.238:7005解释下, --replicas 1 表示 自动为每一个master节点分配一个slave节点 上面有6个节点,程序会按照一定规则生成 3个master(主)3个slave(从)
前面已经提醒过的 防火墙一定要开放监听的端口,否则会创建失败。
运行中,提示Can I set the above configuration? (type 'yes' to accept): yes //输入yes
接下来 提示 Waiting for the cluster to join.......... 安装的时候在这里就一直等等等,没反应,傻傻等半天,看这句提示上面一句,Sending Cluster Meet Message to join the Cluster.
这下明白了,我刚开始在一台Server上去配,也是不需要等的,这里还需要跑到Server2上做一些这样的操作。
在192.168.1.238, redis-cli -c -p 700* 分别进入redis各节点的客户端命令窗口, 依次输入 cluster meet 192.168.1.238 7000……
回到Server1,已经创建完毕了。
查看一下 /usr/local/redis/src/redis-trib.rb check 192.168.1.237:7000
到这里集群已经初步搭建好了。
四、测试
1)get 和 set数据
redis-cli -c -p 7000
进入命令窗口,直接 set hello howareyou
直接根据hash匹配切换到相应的slot的节点上。
还是要说明一下,redis集群有16383个slot组成,通过分片分布到多个节点上,读写都发生在master节点。
2)假设测试
果断先把192.168.1.238服务Down掉,(192.168.1.238有1个Master, 2个Slave) , 跑回192.168.1.238, 查看一下 发生了什么事,192.168.1.237的3个节点全部都是Master,其他几个Server2的不见了
测试一下,依然没有问题,集群依然能继续工作。
原因: redis集群 通过选举方式进行容错,保证一台Server挂了还能跑,这个选举是全部集群超过半数以上的Master发现其他Master挂了后,会将其他对应的Slave节点升级成Master.
疑问: 要是挂的是192.168.1.237怎么办? 哥试了,cluster is down!! 没办法,超过半数挂了那救不了了,整个集群就无法工作了。 要是有三台Server,每台两Master,切记对应的主从节点
不要放在一台Server,别问我为什么自己用脑子想想看,互相交叉配置主从,挂哪台也没事,你要说同时两台crash了,呵呵哒......
3)关于一致性
我还没有这么大胆拿redis来做数据库持久化哥网站数据,只是拿来做cache,官网说的很清楚,Redis Cluster is not able to guarantee strong consistency.
五、安装遇到的问题
1、
CC adlist.o
/bin/sh: cc: command not found
make[1]: *** [adlist.o] Error 127
make[1]: Leaving directory `/usr/local/redis-3.2.1/src
make: *** [all] Error 2
解决办法:GCC没有安装或版本不对,安装一下
yum install gcc2、
zmalloc.h:50:31:
error: jemalloc/jemalloc.h: No such file or directory
zmalloc.h:55:2: error:
#error "Newer version of jemalloc required"
make[1]: *** [adlist.o] Error
1
make[1]: Leaving directory `/data0/src/redis-2.6.2/src
make: *** [all]
Error 2
解决办法:原因是没有安装jemalloc内存分配器,可以安装jemalloc 或 直接
输入make MALLOC=libc && make install