1.初识Stream-API
一、什么是Java Stream API?
Java Stream函数式编程接口最初是在Java 8中引入的,并且与lambda一起成为Java开发的里程碑式的功能特性,它极大的方便了开放人员处理集合类数据的效率。从笔者之前看过的调查文章显示,绝大部分的开发者使用的JDK版本是java 8,其中Java Stream和lambda功不可没。
Java Stream就是一个数据流经的管道,并且在管道中对数据进行操作,然后流入下一个管道。有学过linux 管道的同学应该会很容易就理解。在没有Java Stram之前,对于集合类的操作,更多的是通过for循环。大家从后文中就能看出Java Stream相对于for 循环更加简洁、易用、快捷。
管道的功能包括:Filter(过滤)、Map(映射)、sort(排序)等,集合数据通过Java Stream管道处理之后,转化为另一组集合或数据输出。

二、Stream API代替for循环
我们先来看一个例子:
List nameStrs = Arrays.asList("Monkey", "Lion", "Giraffe","Lemur");
List list = nameStrs.stream()
.filter(s -> s.startsWith("L"))
.map(String::toUpperCase)
.sorted()
.collect(toList());
System.out.println(list);
- 首先,我们使用Stream()函数,将一个List转换为管道流
- 调用filter函数过滤数组元素,过滤方法使用lambda表达式,以L开头的元素返回true被保留,其他的List元素被过滤掉
- 然后调用Map函数对管道流中每个元素进行处理,字母全部转换为大写
- 然后调用sort函数,对管道流中数据进行排序
- 最后调用collect函数toList,将管道流转换为List返回
最终的输出结果是:[LEMUR, LION]。大家可以想一想,上面的这些对数组进行遍历的代码,如果你用for循环来写,需要写多少行代码?来,我们来继续学习Java Stream吧!
三、将数组转换为管道流
使用Stream.of()方法,将数组转换为管道流。
String[] array = {"Monkey", "Lion", "Giraffe", "Lemur"};
Stream nameStrs2 = Stream.of(array);
Stream nameStrs3 = Stream.of("Monkey", "Lion", "Giraffe", "Lemur");
四、将集合类对象转换为管道流
通过调用集合类的stream()方法,将集合类对象转换为管道流。
List list = Arrays.asList("Monkey", "Lion", "Giraffe", "Lemur");
Stream streamFromList = list.stream();
Set set = new HashSet<>(list);
Stream streamFromSet = set.stream();
五、将文本文件转换为管道流
通过Files.lines方法将文本文件转换为管道流,下图中的Paths.get()方法作用就是获取文件,是Java NIO的API!
也就是说:我们可以很方便的使用Java Stream加载文本文件,然后逐行的对文件内容进行处理。
Stream lines = Files.lines(Paths.get("file.txt"));
2.Stream的filter与谓语逻辑
一、基础代码准备
建立一个实体类,该实体类有五个属性。下面的代码使用了lombok的注解Data、AllArgsConstructor,这样我们就不用写get、set方法和全参构造函数了。lombok会帮助我们在编译期生成这些模式化的代码。
@Data
@AllArgsConstructor
public class Employee {
private Integer id;
private Integer age; //年龄
private String gender; //性别
private String firstName;
private String lastName;
}
写一个测试类,这个测试类的内容也很简单,新建十个Employee 对象
public class StreamFilterPredicate {
public static void main(String[] args){
Employee e1 = new Employee(1,23,"M","Rick","Beethovan");
Employee e2 = new Employee(2,13,"F","Martina","Hengis");
Employee e3 = new Employee(3,43,"M","Ricky","Martin");
Employee e4 = new Employee(4,26,"M","Jon","Lowman");
Employee e5 = new Employee(5,19,"F","Cristine","Maria");
Employee e6 = new Employee(6,15,"M","David","Feezor");
Employee e7 = new Employee(7,68,"F","Melissa","Roy");
Employee e8 = new Employee(8,79,"M","Alex","Gussin");
Employee e9 = new Employee(9,15,"F","Neetu","Singh");
Employee e10 = new Employee(10,45,"M","Naveen","Jain");
List employees = Arrays.asList(e1, e2, e3, e4, e5, e6, e7, e8, e9, e10);
List filtered = employees.stream()
.filter(e -> e.getAge() > 70 && e.getGender().equals("M"))
.collect(Collectors.toList());
System.out.println(filtered);
}
}
需要注意的是上面的filter传入了lambda表达式(之前的章节我们已经讲过了),表达过滤年龄大于70并且男性的Employee员工。输出如下:
[Employee(id=8, age=79, gender=M, firstName=Alex, lastName=Gussin)]
二、什么是谓词逻辑?
下面要说我们的重点了,通过之前的章节的讲解,我们已经知道lambda表达式表达的是一个匿名接口函数的实现。那具体到Stream.filter()中,它表达的是什么呢?看下图:可以看出它表达的是一个Predicate接口,在英语中这个单词的意思是:谓词。

什么是谓词?(百度百科)

什么是谓词逻辑?
WHERE 和 AND 限定了主语employee是什么,那么WHERE和AND语句所代表的逻辑就是谓词逻辑
SELECT *
FROM employee
WHERE age > 70
AND gender = 'M'
三、谓词逻辑的复用
通常情况下,filter函数中lambda表达式为一次性使用的谓词逻辑。如果我们的谓词逻辑需要被多处、多场景、多代码中使用,通常将它抽取出来单独定义到它所限定的主语实体中。
比如:将下面的谓词逻辑定义在Employee实体class中。
public static Predicate ageGreaterThan70 = x -> x.getAge() >70;
public static Predicate genderM = x -> x.getGender().equals("M");
3.1.and语法(并集)
List filtered = employees.stream()
.filter(Employee.ageGreaterThan70.and(Employee.genderM))
.collect(Collectors.toList());
输出如下:
[Employee(id=8, age=79, gender=M, firstName=Alex, lastName=Gussin)]
3.2.or语法(交集)
List filtered = employees.stream()
.filter(Employee.ageGreaterThan70.or(Employee.genderM))
.collect(Collectors.toList());
输出如下:实际上就是年龄大于70的和所有的男性(由于79的那位也是男性,所以就是所有的男性)
[Employee(id=1, age=23, gender=M, firstName=Rick, lastName=Beethovan), Employee(id=3, age=43, gender=M, firstName=Ricky, lastName=Martin), Employee(id=4, age=26, gender=M, firstName=Jon, lastName=Lowman), Employee(id=6, age=15, gender=M, firstName=David, lastName=Feezor), Employee(id=8, age=79, gender=M, firstName=Alex, lastName=Gussin), Employee(id=10, age=45, gender=M, firstName=Naveen, lastName=Jain)]
3.3.negate语法(取反)
List filtered = employees.stream()
.filter(Employee.ageGreaterThan70.or(Employee.genderM).negate())
.collect(Collectors.toList());
输出如下:把上一小节代码的结果取反,实际上就是所有的女性
[Employee(id=2, age=13, gender=F, firstName=Martina, lastName=Hengis), Employee(id=5, age=19, gender=F, firstName=Cristine, lastName=Mar
3.Stream管道流的map操作
一、回顾Stream管道流map的基础用法
最简单的需求:将集合中的每一个字符串,全部转换成大写!
List alpha = Arrays.asList("Monkey", "Lion", "Giraffe", "Lemur");
//不使用Stream管道流
List alphaUpper = new ArrayList<>();
for (String s : alpha) {
alphaUpper.add(s.toUpperCase());
}
System.out.println(alphaUpper); //[MONKEY, LION, GIRAFFE, LEMUR]
// 使用Stream管道流
List collect = alpha.stream().map(String::toUpperCase).collect(Collectors.toList());
//上面使用了方法引用,和下面的lambda表达式语法效果是一样的
//List collect = alpha.stream().map(s -> s.toUpperCase()).collect(Collectors.toList());
System.out.println(collect); //[MONKEY, LION, GIRAFFE, LEMUR]
所以map函数的作用就是针对管道流中的每一个数据元素进行转换操作。
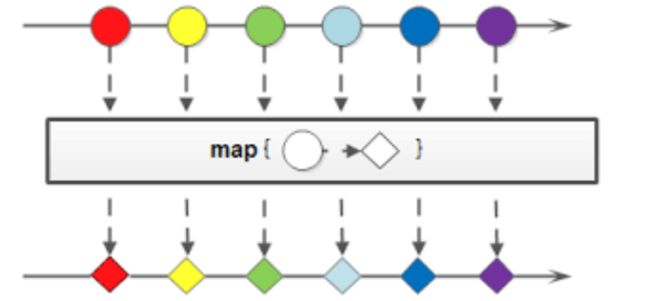
二、处理非字符串类型集合元素
map()函数不仅可以处理数据,还可以转换数据的类型。如下:
List lengths = alpha.stream()
.map(String::length)
.collect(Collectors.toList());
System.out.println(lengths); //[6, 4, 7, 5]
Stream.of("Monkey", "Lion", "Giraffe", "Lemur")
.mapToInt(String::length)
.forEach(System.out::println);
输出如下:
6
4
7
5
除了mapToInt。还有maoToLong,mapToDouble等等用法
三、再复杂一点:处理对象数据格式转换
还是使用上一节中的Employee类,创建10个对象。需求如下:
- 将每一个Employee的年龄增加一岁
- 将性别中的“M”换成“male”,F换成Female。
public static void main(String[] args){
Employee e1 = new Employee(1,23,"M","Rick","Beethovan");
Employee e2 = new Employee(2,13,"F","Martina","Hengis");
Employee e3 = new Employee(3,43,"M","Ricky","Martin");
Employee e4 = new Employee(4,26,"M","Jon","Lowman");
Employee e5 = new Employee(5,19,"F","Cristine","Maria");
Employee e6 = new Employee(6,15,"M","David","Feezor");
Employee e7 = new Employee(7,68,"F","Melissa","Roy");
Employee e8 = new Employee(8,79,"M","Alex","Gussin");
Employee e9 = new Employee(9,15,"F","Neetu","Singh");
Employee e10 = new Employee(10,45,"M","Naveen","Jain");
List employees = Arrays.asList(e1, e2, e3, e4, e5, e6, e7, e8, e9, e10);
/*List maped = employees.stream()
.map(e -> {
e.setAge(e.getAge() + 1);
e.setGender(e.getGender().equals("M")?"male":"female");
return e;
}).collect(Collectors.toList());*/
List maped = employees.stream()
.peek(e -> {
e.setAge(e.getAge() + 1);
e.setGender(e.getGender().equals("M")?"male":"female");
}).collect(Collectors.toList());
System.out.println(maped);
}
由于map的参数e就是返回值,所以可以用peek函数。peek函数是一种特殊的map函数,当函数没有返回值或者参数就是返回值的时候可以使用peek函数。
四、flatMap
map可以对管道流中的数据进行转换操作,但是如果管道中还有管道该如何处理?即:如何处理二维数组及二维集合类。实现一个简单的需求:将“hello”,“world”两个字符串组成的集合,元素的每一个字母打印出来。如果不用Stream我们怎么写?写2层for循环,第一层遍历字符串,并且将字符串拆分成char数组,第二层for循环遍历char数组。
List words = Arrays.asList("hello", "word");
words.stream()
.map(w -> Arrays.stream(w.split(""))) //[[h,e,l,l,o],[w,o,r,l,d]]
.forEach(System.out::println);
输出打印结果:
java.util.stream.ReferencePipeline$Head@3551a94
java.util.stream.ReferencePipeline$Head@531be3c5
- 用map方法是做不到的,这个需求用map方法无法实现。map只能针对一维数组进行操作,数组里面还有数组,管道里面还有管道,它是处理不了每一个元素的。

- flatMap可以理解为将若干个子管道中的数据全都,平面展开到父管道中进行处理。

words.stream()
.flatMap(w -> Arrays.stream(w.split(""))) // [h,e,l,l,o,w,o,r,l,d]
.forEach(System.out::println);
输出打印结果:
h
e
l
l
o
w
o
r
d
4.Stream的状态与并行操作
一、回顾Stream管道流操作

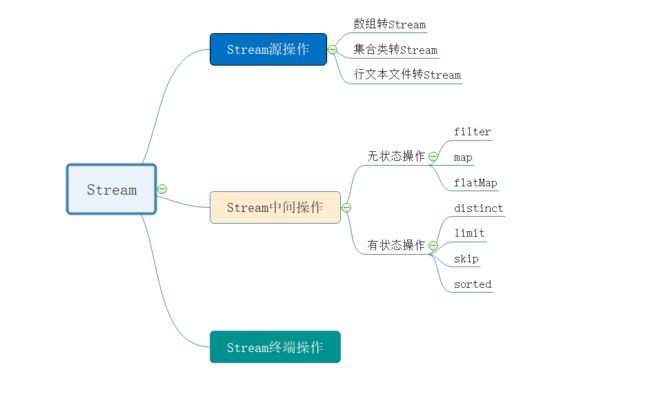
通过前面章节的学习,我们应该明白了Stream管道流的基本操作。我们来回顾一下:
- 源操作:可以将数组、集合类、行文本文件转换成管道流Stream进行数据处理
- 中间操作:对Stream流中的数据进行处理,比如:过滤、数据转换等等
- 终端操作:作用就是将Stream管道流转换为其他的数据类型。这部分我们还没有讲,我们后面章节再介绍。
看下面的脑图,可以有更清晰的理解:
二、中间操作:有状态与无状态
其实在程序员编程中,经常会接触到“有状态”,“无状态”,绝大部分的人都比较蒙。而且在不同的场景下,“状态”这个词的含义似乎有所不同。但是“万变不离其宗”,理解“状态”这个词在编程领域的含义,笔者教给大家几个关键点:
- 状态通常代表公用数据,有状态就是有“公用数据”
- 因为有公用的数据,状态通常需要额外的存储。
- 状态通常被多人、多用户、多线程、多次操作,这就涉及到状态的管理及变更操作。
是不是更蒙了?举个例子,你就明白了
- web开发session就是一种状态,访问者的多次请求关联同一个session,这个session需要存储到内存或者redis。多次请求使用同一个公用的session,这个session就是状态数据。
- vue的vuex的store就是一种状态,首先它是多组件公用的,其次是不同的组件都可以修改它,最后它需要独立于组件单独存储。所以store就是一种状态。
回到我们的Stream管道流
- filter与map操作,不需要管道流的前面后面元素相关,所以不需要额外的记录元素之间的关系。输入一个元素,获得一个结果。
- sorted是排序操作、distinct是去重操作。像这种操作都是和别的元素相关的操作,我自己无法完成整体操作。就像班级点名就是无状态的,喊到你你就答到就可以了。如果是班级同学按大小个排序,那就不是你自己的事了,你得和周围的同学比一下身高并记住,你记住的这个身高比较结果就是一种“状态”。所以这种操作就是有状态操作。
三、Limit与Skip管道数据截取
List limitN = Stream.of("Monkey", "Lion", "Giraffe", "Lemur")
.limit(2)
.collect(Collectors.toList());
List skipN = Stream.of("Monkey", "Lion", "Giraffe", "Lemur")
.skip(2)
.collect(Collectors.toList());
- limt方法传入一个整数n,用于截取管道中的前n个元素。经过管道处理之后的数据是:[Monkey, Lion]。
- skip方法与limit方法的使用相反,用于跳过前n个元素,截取从n到末尾的元素。经过管道处理之后的数据是: [Giraffe, Lemur]
四、Distinct元素去重
我们还可以使用distinct方法对管道中的元素去重,涉及到去重就一定涉及到元素之间的比较,distinct方法时调用Object的equals方法进行对象的比较的,如果你有自己的比较规则,可以重写equals方法。
List uniqueAnimals = Stream.of("Monkey", "Lion", "Giraffe", "Lemur", "Lion")
.distinct()
.collect(Collectors.toList());
上面代码去重之后的结果是: ["Monkey", "Lion", "Giraffe", "Lemur"]
五、Sorted排序
默认的情况下,sorted是按照字母的自然顺序进行排序。如下代码的排序结果是:[Giraffe, Lemur, Lion, Monkey],字数按顺序G在L前面,L在M前面。第一位无法区分顺序,就比较第二位字母。
List alphabeticOrder = Stream.of("Monkey", "Lion", "Giraffe", "Lemur")
.sorted()
.collect(Collectors.toList());
排序我们后面还会给大家详细的讲一讲,所以这里暂时只做一个了解。
六、串行、并行与顺序
通常情况下,有状态和无状态操作不需要我们去关心。除非?:你使用了并行操作。
还是用班级按身高排队为例:班级有一个人负责排序,这个排序结果最后就会是正确的。那如果有2个、3个人负责按大小个排队呢?最后可能就乱套了。一个人只能保证自己排序的人的顺序,他无法保证其他人的排队顺序。
- 串行的好处是可以保证顺序,但是通常情况下处理速度慢一些
- 并行的好处是对于元素的处理速度快一些(通常情况下),但是顺序无法保证。这可能会导致进行一些有状态操作的时候,最后得到的不是你想要的结果。

Stream.of("Monkey", "Lion", "Giraffe", "Lemur", "Lion")
.parallel()
.forEach(System.out::println);
- parallel()函数表示对管道中的元素进行并行处理,而不是串行处理。但是这样就有可能导致管道流中后面的元素先处理,前面的元素后处理,也就是元素的顺序无法保证。
如果数据量比较小的情况下,不太能观察到,数据量大的话,就能观察到数据顺序是无法保证的。
Monkey
Lion
Lemur
Giraffe
Lion
通常情况下,parallel()能够很好的利用CPU的多核处理器,达到更好的执行效率和性能,建议使用。但是有些特殊的情况下,parallel并不适合:深入了解请看这篇文章:
https://blog.oio.de/2016/01/22/parallel-stream-processing-in-java-8-performance-of-sequential-vs-parallel-stream-processing/
该文章中几个观点,说明并行操作的适用场景:
- 数据源易拆分:从处理性能的角度,parallel()更适合处理ArrayList,而不是LinkedList。因为ArrayList从数据结构上讲是基于数组的,可以根据索引很容易的拆分为多个。
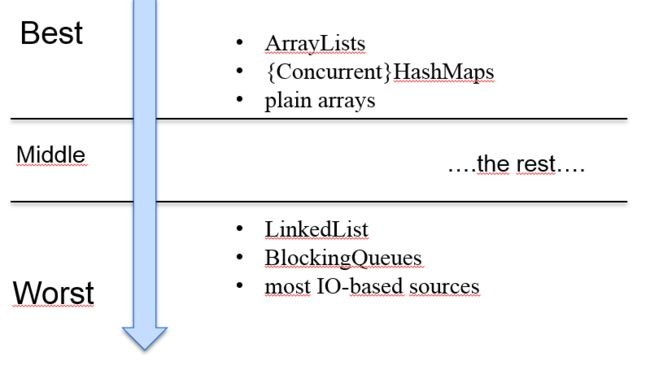
- 适用于无状态操作:每个元素的计算都不得依赖或影响任何其他元素的计算,的运算场景。
- 基础数据源无变化:从文本文件里面边读边处理的场景,不适合parallel()并行处理。parallel()一开始就容量固定的集合,这样能够平均的拆分、同步处理。
5.像使用SQL一样排序集合
在开始之前,我先卖个关子提一个问题:我们现在有一个Employee员工类。
@Data
@AllArgsConstructor
public class Employee {
private Integer id;
private Integer age; //年龄
private String gender; //性别
private String firstName;
private String lastName;
}
你知道怎么对一个Employee对象组成的List集合,先按照性别字段倒序排序,再按照年龄的倒序进行排序么?如果您不知道4行代码以内的解决方案(其实是1行代码就可以实现,但笔者格式化为4行),我觉得您有必要一步步的看下去。

一、字符串List排序
cities是一个字符串数组。注意london的首字母是小写的。
List cities = Arrays.asList(
"Milan",
"london",
"San Francisco",
"Tokyo",
"New Delhi"
);
System.out.println(cities);
//[Milan, london, San Francisco, Tokyo, New Delhi]
cities.sort(String.CASE_INSENSITIVE_ORDER);
System.out.println(cities);
//[london, Milan, New Delhi, San Francisco, Tokyo]
cities.sort(Comparator.naturalOrder());
System.out.println(cities);
//[Milan, New Delhi, San Francisco, Tokyo, london]
- 当使用sort方法,按照String.CASE_INSENSITIVE_ORDER(字母大小写不敏感)的规则排序,结果是:[london, Milan, New Delhi, San Francisco, Tokyo]
- 如果使用Comparator.naturalOrder()字母自然顺序排序,结果是:[Milan, New Delhi, San Francisco, Tokyo, london]
同样我们可以把排序器Comparator用在Stream管道流中。
cities.stream().sorted(Comparator.naturalOrder()).forEach(System.out::println);
//Milan
//New Delhi
//San Francisco
//Tokyo
//london
在java 7我们是使用Collections.sort()接受一个数组参数,对数组进行排序。在java 8之后可以直接调用集合类的sort()方法进行排序。sort()方法的参数是一个比较器Comparator接口的实现类,Comparator接口的我们下一节再给大家介绍一下。
二、整数类型List排序
List numbers = Arrays.asList(6, 2, 1, 4, 9);
System.out.println(numbers); //[6, 2, 1, 4, 9]
numbers.sort(Comparator.naturalOrder()); //自然排序
System.out.println(numbers); //[1, 2, 4, 6, 9]
numbers.sort(Comparator.reverseOrder()); //倒序排序
System.out.println(numbers); //[9, 6, 4, 2, 1]
三、按对象字段对List排序
这个功能就比较有意思了,举个例子大家理解一下。
Employee e1 = new Employee(1,23,"M","Rick","Beethovan");
Employee e2 = new Employee(2,13,"F","Martina","Hengis");
Employee e3 = new Employee(3,43,"M","Ricky","Martin");
Employee e4 = new Employee(4,26,"M","Jon","Lowman");
Employee e5 = new Employee(5,19,"F","Cristine","Maria");
Employee e6 = new Employee(6,15,"M","David","Feezor");
Employee e7 = new Employee(7,68,"F","Melissa","Roy");
Employee e8 = new Employee(8,79,"M","Alex","Gussin");
Employee e9 = new Employee(9,15,"F","Neetu","Singh");
Employee e10 = new Employee(10,45,"M","Naveen","Jain");
List employees = Arrays.asList(e1, e2, e3, e4, e5, e6, e7, e8, e9, e10);
employees.sort(Comparator.comparing(Employee::getAge));
employees.forEach(System.out::println);
- 首先,我们创建了10个Employee对象,然后将它们转换为List
- 然后重点的的代码:使用了函数应用Employee::getAge作为对象的排序字段,即使用员工的年龄作为排序字段
- 然后调用List的forEach方法将List排序结果打印出来,如下(当然我们重写了Employee的toString方法,不然打印结果没有意义):
Employee(id=2, age=13, gender=F, firstName=Martina, lastName=Hengis)
Employee(id=6, age=15, gender=M, firstName=David, lastName=Feezor)
Employee(id=9, age=15, gender=F, firstName=Neetu, lastName=Singh)
Employee(id=5, age=19, gender=F, firstName=Cristine, lastName=Maria)
Employee(id=1, age=23, gender=M, firstName=Rick, lastName=Beethovan)
Employee(id=4, age=26, gender=M, firstName=Jon, lastName=Lowman)
Employee(id=3, age=43, gender=M, firstName=Ricky, lastName=Martin)
Employee(id=10, age=45, gender=M, firstName=Naveen, lastName=Jain)
Employee(id=7, age=68, gender=F, firstName=Melissa, lastName=Roy)
Employee(id=8, age=79, gender=M, firstName=Alex, lastName=Gussin)
- 如果我们希望List按照年龄age的倒序排序,就使用reversed()方法。如:
employees.sort(Comparator.comparing(Employee::getAge).reversed());
四、Comparator链对List排序
下面这段代码先是按性别的倒序排序,再按照年龄的倒序排序。
employees.sort(
Comparator.comparing(Employee::getGender)
.thenComparing(Employee::getAge)
.reversed()
);
employees.forEach(System.out::println);
//都是正序 ,不加reversed
//都是倒序,最后面加一个reserved
//先是倒序(加reserved),然后正序
//先是正序(加reserved),然后倒序(加reserved)
细心的朋友可能注意到:我们只用了一个reversed()倒序方法,这个和SQL的表述方式不太一样。这个问题不太好用语言描述,建议大家去看一下视频!
排序结果如下:
Employee(id=8, age=79, gender=M, firstName=Alex, lastName=Gussin)
Employee(id=10, age=45, gender=M, firstName=Naveen, lastName=Jain)
Employee(id=3, age=43, gender=M, firstName=Ricky, lastName=Martin)
Employee(id=4, age=26, gender=M, firstName=Jon, lastName=Lowman)
Employee(id=1, age=23, gender=M, firstName=Rick, lastName=Beethovan)
Employee(id=6, age=15, gender=M, firstName=David, lastName=Feezor)
Employee(id=7, age=68, gender=F, firstName=Melissa, lastName=Roy)
Employee(id=5, age=19, gender=F, firstName=Cristine, lastName=Maria)
Employee(id=9, age=15, gender=F, firstName=Neetu, lastName=Singh)
Employee(id=2, age=13, gender=F, firstName=Martina, lastName=Hengis)
6.函数式接口Comparator
一、函数式接口是什么?
所谓的函数式接口,实际上就是接口里面只能有一个抽象方法的接口。我们上一节用到的Comparator接口就是一个典型的函数式接口,它只有一个抽象方法compare。
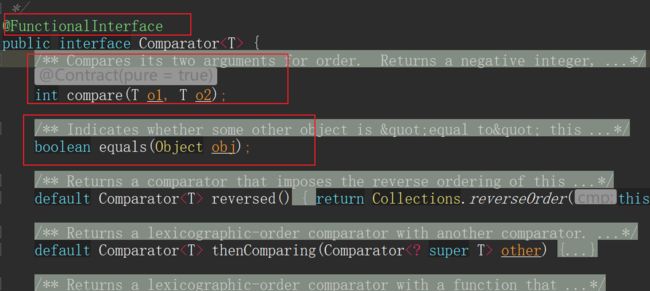
只有一个抽象方法?那上图中的equals方法不是也没有函数体么?不急,和我一起往下看!
二、函数式接口的特点
- 接口有且仅有一个抽象方法,如上图的抽象方法compare
- 允许定义静态非抽象方法
- 允许定义默认defalut非抽象方法(default方法也是java8才有的,见下文)
- 允许java.lang.Object中的public方法,如上图的方法equals。
- FunctionInterface注解不是必须的,如果一个接口符合"函数式接口"定义,那么加不加该注解都没有影响。加上该注解能够更好地让编译器进行检查。如果编写的不是函数式接口,但是加上了@FunctionInterface,那么编译器会报错
甚至可以说:函数式接口是专门为lambda表达式准备的,lambda表达式是只实现接口中唯一的抽象方法的匿名实现类。
三、default关键字
顺便讲一下default关键字,在java8之前
- 接口是不能有方法的实现,所有方法全都是抽象方法
- 实现接口就必须实现接口里面的所有方法
这就导致一个问题:当一个接口有很多的实现类的时候,修改这个接口就变成了一个非常麻烦的事,需要修改这个接口的所有实现类。
这个问题困扰了java工程师许久,不过在java8中这个问题得到了解决,没错就是default方法
- default方法可以有自己的默认实现,即有方法体。
- 接口实现类可以不去实现default方法,并且可以使用default方法。
四、JDK中的函数式接口举例
java.lang.Runnable,
java.util.Comparator,
java.util.concurrent.Callable
java.util.function包下的接口,如Consumer、Predicate、Supplier等
五、自定义Comparator排序
我们自定义一个排序器,实现compare函数(函数式接口Comparator唯一的抽象方法)。返回0表示元素相等,-1表示前一个元素小于后一个元素,1表示前一个元素大于后一个元素。这个规则和java 8之前没什么区别。
下面代码用自定义接口实现类的的方式实现:按照年龄的倒序排序!
employees.sort(new Comparator() {
@Override
public int compare(Employee em1, Employee em2) {
if(em1.getAge() == em2.getAge()){
return 0;
}
return em1.getAge() - em2.getAge() > 0 ? -1:1;
}
});
employees.forEach(System.out::println);
最终的打印结果如下,按照年龄的自定义规则进行排序。
Employee(id=8, age=79, gender=M, firstName=Alex, lastName=Gussin)
Employee(id=7, age=68, gender=F, firstName=Melissa, lastName=Roy)
Employee(id=10, age=45, gender=M, firstName=Naveen, lastName=Jain)
Employee(id=3, age=43, gender=M, firstName=Ricky, lastName=Martin)
Employee(id=4, age=26, gender=M, firstName=Jon, lastName=Lowman)
Employee(id=1, age=23, gender=M, firstName=Rick, lastName=Beethovan)
Employee(id=5, age=19, gender=F, firstName=Cristine, lastName=Maria)
Employee(id=9, age=15, gender=F, firstName=Neetu, lastName=Singh)
Employee(id=6, age=15, gender=M, firstName=David, lastName=Feezor)
Employee(id=2, age=13, gender=F, firstName=Martina, lastName=Hengis)
这段代码如果以lambda表达式简写。箭头左侧是参数,右侧是函数体,参数类型和返回值根据上下文自动判断。如下:
employees.sort((em1,em2) -> {
if(em1.getAge() == em2.getAge()){
return 0;
}
return em1.getAge() - em2.getAge() > 0 ? -1:1;
});
employees.forEach(System.out::println);
7.Stream查找与匹配元素
在我们对数组或者集合类进行操作的时候,经常会遇到这样的需求,比如:
- 是否包含某一个“匹配规则”的元素
- 是否所有的元素都符合某一个“匹配规则”
- 是否所有元素都不符合某一个“匹配规则”
- 查找第一个符合“匹配规则”的元素
- 查找任意一个符合“匹配规则”的元素
这些需求如果用for循环去写的话,还是比较麻烦的,需要使用到for循环和break!本节就介绍一个如何用Stream API来实现“查找与匹配”。
一、对比一下有多简单
employees是10个员工对象组成的List,在前面的章节中我们已经用过多次,这里不再列出代码。
如果我们不用Stream API实现,查找员工列表中是否包含年龄大于70的员工?代码如下:
boolean isExistAgeThan70 = false;
for(Employee employee:employees){
if(employee.getAge() > 70){
isExistAgeThan70 = true;
break;
}
}
如果我们使用Stream API就是下面的一行代码,其中使用到了我们之前学过的"谓词逻辑"。
boolean isExistAgeThan70 = employees.stream().anyMatch(Employee.ageGreaterThan70);
将谓词逻辑换成lambda表达式也可以,代码如下:
boolean isExistAgeThan72 = employees.stream().anyMatch(e -> e.getAge() > 72);
所以,我们介绍了第一个匹配规则函数:anyMatch,判断Stream流中是否包含某一个“匹配规则”的元素。这个匹配规则可以是lambda表达式或者谓词。
二、其他匹配规则函数介绍
- 是否所有员工的年龄都大于10岁?allMatch匹配规则函数:判断是够Stream流中的所有元素都符合某一个"匹配规则"。
boolean isExistAgeThan10 = employees.stream().allMatch(e -> e.getAge() > 10);
- 是否不存在小于18岁的员工?noneMatch匹配规则函数:判断是否Stream流中的所有元素都不符合某一个"匹配规则"。
boolean isExistAgeLess18 = employees.stream().noneMatch(e -> e.getAge() < 18);
三、元素查找与Optional
从列表中按照顺序查找第一个年龄大于40的员工。
Optional employeeOptional
= employees.stream().filter(e -> e.getAge() > 40).findFirst();
System.out.println(employeeOptional.get());
打印结果
Employee(id=3, age=43, gender=M, firstName=Ricky, lastName=Martin)
Optional类代表一个值存在或者不存在。在java8中引入,这样就不用返回null了。
- isPresent() 将在 Optional 包含值的时候返回 true , 否则返回 false 。
- ifPresent(Consumer block) 会在值存在的时候执行给定的代码块。我们在第3章
介绍了 Consumer 函数式接口;它让你传递一个接收 T 类型参数,并返回 void 的Lambda
表达式。 - T get() 会在值存在时返回值,否则?出一个 NoSuchElement 异常。
- T orElse(T other) 会在值存在时返回值,否则返回一个默认值。
关于Optinal的各种函数用法请观看视频!B站观看地址
- findFirst用于查找第一个符合“匹配规则”的元素,返回值为Optional
- findAny用于查找任意一个符合“匹配规则”的元素,返回值为Optional
8.Stream集合元素归约
Stream API为我们提供了Stream.reduce用来实现集合元素的归约。reduce函数有三个参数:
- Identity标识:一个元素,它是归约操作的初始值,如果流为空,则为默认结果。
- Accumulator累加器:具有两个参数的函数:归约运算的部分结果和流的下一个元素。
- Combiner合并器(可选):当归约并行化时,或当累加器参数的类型与累加器实现的类型不匹配时,用于合并归约操作的部分结果的函数。
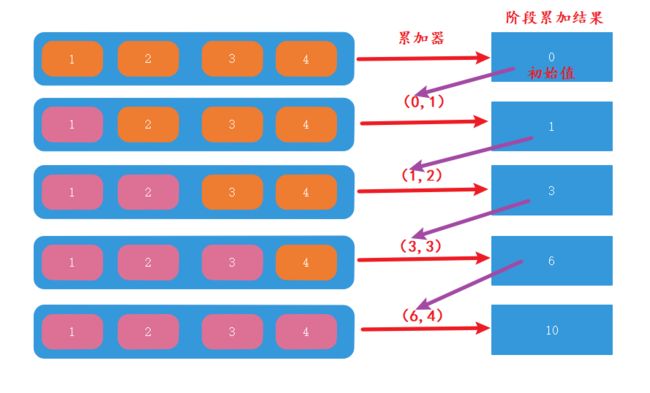
注意观察上面的图,我们先来理解累加器: - 阶段累加结果作为累加器的第一个参数
- 集合遍历元素作为累加器的第二个参数
Integer类型归约
reduce初始值为0,累加器可以是lambda表达式,也可以是方法引用。
List numbers = Arrays.asList(1, 2, 3, 4, 5, 6);
int result = numbers
.stream()
.reduce(0, (subtotal, element) -> subtotal + element);
System.out.println(result); //21
int result = numbers
.stream()
.reduce(0, Integer::sum);
System.out.println(result); //21
String类型归约
不仅可以归约Integer类型,只要累加器参数类型能够匹配,可以对任何类型的集合进行归约计算。
List letters = Arrays.asList("a", "b", "c", "d", "e");
String result = letters
.stream()
.reduce("", (partialString, element) -> partialString + element);
System.out.println(result); //abcde
String result = letters
.stream()
.reduce("", String::concat);
System.out.println(result); //ancde
复杂对象归约
计算所有的员工的年龄总和。
Employee e1 = new Employee(1,23,"M","Rick","Beethovan");
Employee e2 = new Employee(2,13,"F","Martina","Hengis");
Employee e3 = new Employee(3,43,"M","Ricky","Martin");
Employee e4 = new Employee(4,26,"M","Jon","Lowman");
Employee e5 = new Employee(5,19,"F","Cristine","Maria");
Employee e6 = new Employee(6,15,"M","David","Feezor");
Employee e7 = new Employee(7,68,"F","Melissa","Roy");
Employee e8 = new Employee(8,79,"M","Alex","Gussin");
Employee e9 = new Employee(9,15,"F","Neetu","Singh");
Employee e10 = new Employee(10,45,"M","Naveen","Jain");
List employees = Arrays.asList(e1, e2, e3, e4, e5, e6, e7, e8, e9, e10);
Integer total = employees.stream().map(Employee::getAge).reduce(0,Integer::sum);
System.out.println(total); //346
- 先用map将Stream流中的元素由Employee类型处理为Integer类型(age)。
- 然后对Stream流中的Integer类型进行归约
Combiner合并器的使用
除了使用map函数实现类型转换后的集合归约,我们还可以用Combiner合并器来实现,这里第一次使用到了Combiner合并器。
因为Stream流中的元素是Employee,累加器的返回值是Integer,所以二者的类型不匹配。这种情况下可以使用Combiner合并器对累加器的结果进行二次归约,相当于做了类型转换。
Integer total3 = employees.stream()
.reduce(0,(totalAge,emp) -> totalAge + emp.getAge(),Integer::sum); //注意这里reduce方法有三个参数
System.out.println(total); //346
计算结果和使用map进行数据类型转换的方式是一样的。
并行流数据归约(使用合并器)
对于大数据量的集合元素归约计算,更能体现出Stream并行流计算的威力。

在进行并行流计算的时候,可能会将集合元素分成多个组计算。为了更快的将分组计算结果累加,可以使用合并器。
Integer total2 = employees
.parallelStream()
.map(Employee::getAge)
.reduce(0,Integer::sum,Integer::sum); //注意这里reduce方法有三个参数
System.out.println(total); //346
9.StreamAPI终端操作
一、Java Stream管道数据处理操作
在本号之前写过的文章中,曾经给大家介绍过 Java Stream管道流是用于简化集合类元素处理的java API。在使用的过程中分为三个阶段。在开始本文之前,我觉得仍然需要给一些新朋友介绍一下这三个阶段,如图:
- 第一阶段(图中蓝色):将集合、数组、或行文本文件转换为java Stream管道流
- 第二阶段(图中虚线部分):管道流式数据处理操作,处理管道中的每一个元素。上一个管道中的输出元素作为下一个管道的输入元素。
- 第三阶段(图中绿色):管道流结果处理操作,也就是本文的将介绍的核心内容。
在开始学习之前,仍然有必要回顾一下我们之前给大家讲过的一个例子:
List nameStrs = Arrays.asList("Monkey", "Lion", "Giraffe","Lemur");
List list = nameStrs.stream()
.filter(s -> s.startsWith("L"))
.map(String::toUpperCase)
.sorted()
.collect(toList());
System.out.println(list);
- 首先使用stream()方法将字符串List转换为管道流Stream
- 然后进行管道数据处理操作,先用fliter函数过滤所有大写L开头的字符串,然后将管道中的字符串转换为大写字母toUpperCase,然后调用sorted方法排序。这些API的用法在本号之前的文章有介绍过。其中还使用到了lambda表达式和函数引用。
- 最后使用collect函数进行结果处理,将java Stream管道流转换为List。最终list的输出结果是:
[LEMUR, LION]
如果你不使用java Stream管道流的话,想一想你需要多少行代码完成上面的功能呢?回到正题,这篇文章就是要给大家介绍第三阶段:对管道流处理结果都可以做哪些操作呢?下面开始吧!
二、ForEach和ForEachOrdered
如果我们只是希望将Stream管道流的处理结果打印出来,而不是进行类型转换,我们就可以使用forEach()方法或forEachOrdered()方法。
Stream.of("Monkey", "Lion", "Giraffe", "Lemur", "Lion")
.parallel()
.forEach(System.out::println);
Stream.of("Monkey", "Lion", "Giraffe", "Lemur", "Lion")
.parallel()
.forEachOrdered(System.out::println);
- parallel()函数表示对管道中的元素进行并行处理,而不是串行处理,这样处理速度更快。但是这样就有可能导致管道流中后面的元素先处理,前面的元素后处理,也就是元素的顺序无法保证
- forEachOrdered从名字上看就可以理解,虽然在数据处理顺序上可能无法保障,但是forEachOrdered方法可以在元素输出的顺序上保证与元素进入管道流的顺序一致。也就是下面的样子(forEach方法则无法保证这个顺序):
Monkey
Lion
Giraffe
Lemur
Lion
三、元素的收集collect
java Stream 最常见的用法就是:一将集合类转换成管道流,二对管道流数据处理,三将管道流处理结果在转换成集合类。那么collect()方法就为我们提供了这样的功能:将管道流处理结果在转换成集合类。
3.1.收集为Set
通过Collectors.toSet()方法收集Stream的处理结果,将所有元素收集到Set集合中。
Set collectToSet = Stream.of(
"Monkey", "Lion", "Giraffe", "Lemur", "Lion"
)
.collect(Collectors.toSet());
//最终collectToSet 中的元素是:[Monkey, Lion, Giraffe, Lemur],注意Set会去重。
3.2.收集到List
同样,可以将元素收集到List使用toList()收集器中。
List collectToList = Stream.of(
"Monkey", "Lion", "Giraffe", "Lemur", "Lion"
).collect(Collectors.toList());
// 最终collectToList中的元素是: [Monkey, Lion, Giraffe, Lemur, Lion]
3.3.通用的收集方式
上面为大家介绍的元素收集方式,都是专用的。比如使用Collectors.toSet()收集为Set类型集合;使用Collectors.toList()收集为List类型集合。那么,有没有一种比较通用的数据元素收集方式,将数据收集为任意的Collection接口子类型。
所以,这里就像大家介绍一种通用的元素收集方式,你可以将数据元素收集到任意的Collection类型:即向所需Collection类型提供构造函数的方式。
LinkedList collectToCollection = Stream.of(
"Monkey", "Lion", "Giraffe", "Lemur", "Lion"
).collect(Collectors.toCollection(LinkedList::new));
//最终collectToCollection中的元素是: [Monkey, Lion, Giraffe, Lemur, Lion]
注意:代码中使用了LinkedList::new,实际是调用LinkedList的构造函数,将元素收集到Linked List。当然你还可以使用诸如LinkedHashSet::new和PriorityQueue::new将数据元素收集为其他的集合类型,这样就比较通用了。
3.4.收集到Array
通过toArray(String[]::new)方法收集Stream的处理结果,将所有元素收集到字符串数组中。
String[] toArray = Stream.of(
"Monkey", "Lion", "Giraffe", "Lemur", "Lion"
) .toArray(String[]::new);
//最终toArray字符串数组中的元素是: [Monkey, Lion, Giraffe, Lemur, Lion]
3.5.收集到Map
使用Collectors.toMap()方法将数据元素收集到Map里面,但是出现一个问题:那就是管道中的元素是作为key,还是作为value。我们用到了一个Function.identity()方法,该方法很简单就是返回一个“ t -> t ”(输入就是输出的lambda表达式)。另外使用管道流处理函数distinct()来确保Map键值的唯一性。
Map toMap = Stream.of(
"Monkey", "Lion", "Giraffe", "Lemur", "Lion"
)
.distinct()
.collect(Collectors.toMap(
Function.identity(), //元素输入就是输出,作为key
s -> (int) s.chars().distinct().count()// 输入元素的不同的字母个数,作为value
));
// 最终toMap的结果是: {Monkey=6, Lion=4, Lemur=5, Giraffe=6}
3.6.分组收集groupingBy
Collectors.groupingBy用来实现元素的分组收集,下面的代码演示如何根据首字母将不同的数据元素收集到不同的List,并封装为Map。
Map> groupingByList = Stream.of(
"Monkey", "Lion", "Giraffe", "Lemur", "Lion"
)
.collect(Collectors.groupingBy(
s -> s.charAt(0) , //根据元素首字母分组,相同的在一组
// counting() // 加上这一行代码可以实现分组统计
));
// 最终groupingByList内的元素: {G=[Giraffe], L=[Lion, Lemur, Lion], M=[Monkey]}
//如果加上counting() ,结果是: {G=1, L=3, M=1}
这是该过程的说明:groupingBy第一个参数作为分组条件,第二个参数是子收集器。
四、其他常用方法
boolean containsTwo = IntStream.of(1, 2, 3).anyMatch(i -> i == 2);
// 判断管道中是否包含2,结果是: true
long nrOfAnimals = Stream.of(
"Monkey", "Lion", "Giraffe", "Lemur"
).count();
// 管道中元素数据总计结果nrOfAnimals: 4
int sum = IntStream.of(1, 2, 3).sum();
// 管道中元素数据累加结果sum: 6
OptionalDouble average = IntStream.of(1, 2, 3).average();
//管道中元素数据平均值average: OptionalDouble[2.0]
int max = IntStream.of(1, 2, 3).max().orElse(0);
//管道中元素数据最大值max: 3
IntSummaryStatistics statistics = IntStream.of(1, 2, 3).summaryStatistics();
// 全面的统计结果statistics: IntSummaryStatistics{count=3, sum=6, min=1, average=2.000000, max=3}
10.java8如何排序Map
在这篇文章中,您将学习如何使用Java对Map进行排序。前几日有位朋友面试遇到了这个问题,看似很简单的问题,但是如果不仔细研究一下也是很容易让人懵圈的面试题。所以我决定写这样一篇文章。在Java中,有多种方法可以对Map进行排序,但是我们将重点介绍Java 8 Stream,这是实现目标的一种非常优雅的方法。
一、什么是Java 8 Stream
使用Java 8 Streams,我们可以按键和按值对映射进行排序。下面是它的工作原理:
- 将Map或List等集合类对象转换为Stream对象
- 使用Streams的
sorted()方法对其进行排序 - 最终将其返回为
LinkedHashMap(可以保留排序顺序)
sorted()方法以aComparator作为参数,从而可以按任何类型的值对Map进行排序。如果对Comparator不熟悉,可以看本号前几天的文章,有一篇文章专门介绍了使用Comparator对List进行排序。
二、学习一下HashMap的merge()函数
在学习Map排序之前,有必要讲一下HashMap的merge()函数,该函数应用场景就是当Key重复的时候,如何处理Map的元素值。这个函数有三个参数:
- 参数一:向map里面put的键
- 参数二:向map里面put的值
- 参数三:如果键发生重复,如何处理值。可以是一个函数,也可以写成lambda表达式。
String k = "key";
HashMap map = new HashMap() {{
put(k, 1);
}};
map.merge(k, 2, (oldVal, newVal) -> oldVal + newVal);
看上面一段代码,我们首先创建了一个HashMap,并往里面放入了一个键值为k:1的元素。当我们调用merge函数,往map里面放入k:2键值对的时候,k键发生重复,就执行后面的lambda表达式。表达式的含义是:返回旧值oldVal加上新值newVal(1+2),现在map里面只有一项元素那就是k:3。
其实lambda表达式很简单:表示匿名函数,箭头左侧是参数,箭头右侧是函数体。函数的参数类型和返回值,由代码上下文来确定。
三、按Map的键排序
下面一个例子使用Java 8 Stream按Map的键进行排序:
// 创建一个Map,并填入数据
Map codes = new HashMap<>();
codes.put("United States", 1);
codes.put("Germany", 49);
codes.put("France", 33);
codes.put("China", 86);
codes.put("Pakistan", 92);
// 按照Map的键进行排序
Map sortedMap = codes.entrySet().stream()
.sorted(Map.Entry.comparingByKey())
.collect(
Collectors.toMap(
Map.Entry::getKey,
Map.Entry::getValue,
(oldVal, newVal) -> oldVal,
LinkedHashMap::new
)
);
// 将排序后的Map打印
sortedMap.entrySet().forEach(System.out::println);
看上文中第二段代码:
- 首先使用entrySet().stream() 将Map类型转换为Stream流类型。
- 然后使用sorted方法排序,排序的依据是Map.Entry.comparingByKey(),也就是按照Map的键排序
- 最后用collect方法将Stream流转成LinkedHashMap。 其他参数都好说,重点看第三个参数,就是一个merge规则的lambda表达式,与merge方法的第三个参数的用法一致。由于本例中没有重复的key,所以新值旧值随便返回一个即可。
上面的程序将在控制台上打印以下内容,键(国家/地区名称)以自然字母顺序排序:
China=86
France=33
Germany=49
Pakistan=92
United States=1
请注意使用
LinkedHashMap来存储排序的结果以保持顺序。默认情况下,Collectors.toMap()返回HashMap。HashMap不能保证元素的顺序。
如果希望按照键进行逆向排序,加入下图中红色部分代码即可。
四、按Map的值排序
当然,您也可以使用Stream API按其值对Map进行排序:
Map sortedMap2 = codes.entrySet().stream()
.sorted(Map.Entry.comparingByValue())
.collect(Collectors.toMap(
Map.Entry::getKey,
Map.Entry::getValue,
(oldVal, newVal) -> oldVal,
LinkedHashMap::new));
sortedMap2.entrySet().forEach(System.out::println);
这是显示Map按值排序的输出:
United States=1
France=33
Germany=49
China=86
Pakistan=92
五、使用TreeMap按键排序
大家可能都知道TreeMap内的元素是有顺序的,所以利用TreeMap排序也是可取的一种方法。您需要做的就是创建一个TreeMap对象,并将数据从HashMapput到TreeMap中,非常简单:
// 将 `HashMap` 转为 `TreeMap`
Map sorted = new TreeMap<>(codes);
这是输出:
China=86
France=33
Germany=49
Pakistan=92
United States=1
如上所示,键(国家/地区名称)以自然字母顺序排序。
最后:上文代码
String k = "key";
HashMap map = new HashMap() {{
put(k, 1);
}};
map.merge(k, 2, (oldVal, newVal) -> oldVal + newVal);
// 创建一个Map,并填入数据
Map codes = new HashMap<>();
codes.put("United States", 1);
codes.put("Germany", 49);
codes.put("France", 33);
codes.put("China", 86);
codes.put("Pakistan", 92);
// 按照Map的键进行排序
Map sortedMap = codes.entrySet().stream()
.sorted(Map.Entry.comparingByKey())
.collect(
Collectors.toMap(
Map.Entry::getKey,
Map.Entry::getValue,
(oldVal, newVal) -> oldVal,
LinkedHashMap::new
)
);
// 将排序后的Map打印
sortedMap.entrySet().forEach(System.out::println);
// sort the map by values
Map sorted = codes.entrySet().stream()
.sorted(Map.Entry.comparingByValue())
.collect(Collectors.toMap(
Map.Entry::getKey,
Map.Entry::getValue,
(oldVal, newVal) -> oldVal,
LinkedHashMap::new));
sorted.entrySet().forEach(System.out::println);