python3爬取百度搜索结果url,获得真实url,提取网页正文并分词,多进程的使用
本文是在学习了网上相关的一些博客和资料后的学习总结,属于入门级爬虫
相关工具与环境
python3及以上的版本
urllib
BeautifulSoup
jieba分词
url2io(提取网页正文http://www.url2io.com/)
整体过程简介
分析百度搜索的url,用urllib.request提取网页,用beausoup解析页面,分析搜索页面,找到搜索结果在页面里的结构位置,把搜索结果提取出来,再得到搜索结果真实url,提取网页正文,分词保存
详细过程
1.分析百度搜索的url,获取页面
我们在用百度的时候输入关键词点击搜索,可以看到页面url有一大串字符。但我们用爬虫获取页面的时候是用不到这么字符的,我们实际用的url是这个:http://www.baidu.com.cn/s?wd=' 关键词'&pn='分页'。wd是你要搜索的关键,pn是分页的页面,由于百度搜索每页的结果是十个(最上面的可能是广告推广,不是搜索结果),所以pn=0是第一页,第二页是pn=10,以此类推,可以试下https://www.baidu.com/s?wd=周杰伦&pn=20,得到的是关于周杰伦的第三页搜索结果。
word = '周杰伦'url = 'http://www.baidu.com.cn/s?wd=' + urllib.parse.quote(word) + '&pn=0' # word为关键词,pn是百度用来分页的..response = urllib.request.urlopen(url)
page = response.read()以上语句就是简单的爬虫,得到百度搜索结果的页面,word是传过来的关键词,如果含中文需要用urllib.parse.quote防止报错,因为超链接默认是用ascii编码的,所以不能直接出现中文。
2.分析页面的html结构,找到搜索链接在页面中的位置,得到真实的搜索链接
使用谷歌浏览器的开发者模式(F12或者Fn+F12),点击左上角的箭头后点击下其中一个搜索结果如下图可以看到搜索结果都在class="result c-container"的div里面,每个div里面都包含class="t"的h3标签,h3标签里包含a标签,而搜索结果就在其中的href便签里。
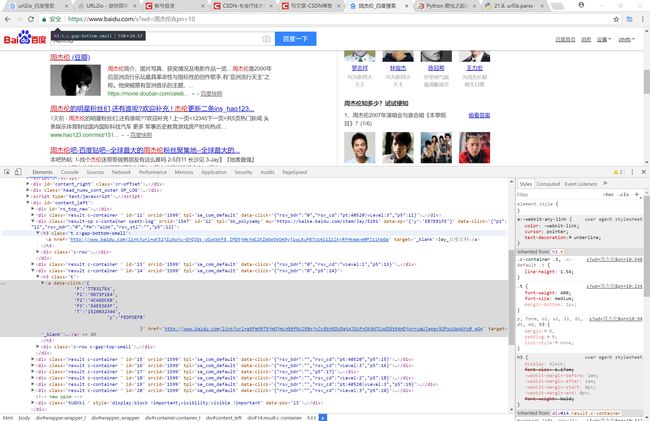
知道了url的位置接下来就很方便了,我们使用beautifulsoup使用lxml解析页面(pip install beautifulsoup4,pip install lxml,如果pip安装报错在网上搜索相关的安装教程)
headers = {
'Accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,*/*;q=0.8',
'Accept-Encoding': 'gzip, deflate, compress',
'Accept-Language': 'en-us;q=0.5,en;q=0.3',
'Cache-Control': 'max-age=0',
'Connection': 'keep-alive',
'User-Agent': 'Mozilla/5.0 (X11; Ubuntu; Linux x86_64; rv:22.0) Gecko/20100101 Firefox/22.0'
} #定义头文件,伪装成浏览器
all = open('D:\\111\\test.txt', 'a') soup = BeautifulSoup(page, 'lxml')
tagh3 = soup.find_all('h3')
for h3 in tagh3:
href = h3.find('a').get('href')
baidu_url = requests.get(url=href, headers=headers, allow_redirects=False)
real_url = baidu_url.headers['Location'] #得到网页原始地址
if real_url.startswith('http'):
all.write(real_url + '\n')因为页面中除了搜索结果外不包含其他h3标签,我们直接用beautifulsoup获取所有h3标签,然后用for循环得到每个搜索结果的url。
上面的requests也是一个爬虫的包,没有安装的化pip安装一下,我们用这个包的get的方法可以得到相关页面的头文件信息,里面的Location对应的就是网页真实url,我们在正则一下过滤掉一些没用的url,保存下来。
注意,有时候有时候伪装的头文件Accept-Encoding会引起乱码问题,可以删除。
3.提取网页正文,进行分词
api = url2io.API('bjb4w0WATrG7Lt6PVx_TrQ')
try:
ret = api.article(url=url,fields=['text', 'next'])
text = ret['text']
except:
return我们用网上的三方包url2io可以提取网页正文,网址http://www.url2io.com/。但注意,这个包是基于pyhton2.7写的,里面用到的urllib2在python3的版本已经被合并到urllib中去了,需要自己修改下,还有basestring在pyhton3中也被删除,改成str即可,这个包对于大部分包含正文的网页都能提取出来,用try语句处理不能提取的情况。
我们用jieba对提取的正文分词,jieba的使用:点击打开链接。
# -*- coding:utf-8 -*-
import jieba
import jieba.posseg as pseg
import url2io
from pymongo import MongoClient
conn = MongoClient('localhost', 27017)
db = conn.test
count = db.count
count.remove()
def test():
filename = 'C:\\xxx\\include.txt'
jieba.load_userdict(filename)
seg_list = jieba.cut("我家住在青山区博雅豪庭大华南湖公园世家五栋十三号") #默认是精确模式
print(", ".join(seg_list))
fff = "我家住在青山区博雅豪庭大.华南湖公园世家啊说,法撒撒打算武汉工商学院五栋十三号"
result = pseg.cut(fff)
for w in result:
print(w.word, '/', w.flag, ',')
def get_address(url):
api = url2io.API('bjb4w0WATrG7Lt6PVx_TrQ')
try:
ret = api.article(url=url,fields=['text', 'next'])
text = ret['text']
filename = 'C:\\xxx\\include.txt'
jieba.load_userdict(filename)
result = pseg.cut(text)
for w in result:
if(w.flag=='wh'):
print(w.word)
res = count.find_one({"name": w.word})
if res:
count.update_one({"name": w.word},{"$set": {"sum": res['sum']+1}})
else:
count.insert({"name": w.word,"sum": 1})
except:
return我这里是用的结合了自定义词库进行分词。
4.使用多进程(POOL进程池)提高爬虫速度
为什么不用多线程呢,因为python的多线程太过鸡肋,详细信息百度一下就知道了。下面我直接把全部代码放出来,里面有把地址存在txt文件和MongoDB数据库的方法。
Baidu.py
# -*- coding:utf-8 -*-
'''
从百度把前10页的搜索到的url爬取保存
'''
import multiprocessing #利用pool进程池实现多进程并行
# from threading import Thread 多线程
import time
from bs4 import BeautifulSoup #处理抓到的页面
import sys
import requests
import importlib
importlib.reload(sys)#编码转换,python3默认utf-8,一般不用加
from urllib import request
import urllib
from pymongo import MongoClient
conn = MongoClient('localhost', 27017)
db = conn.test#数据库名
urls = db.cache#表名
urls.remove()
'''
all = open('D:\\111\\test.txt', 'a')
all.seek(0) #文件标记到初始位置
all.truncate() #清空文件
'''
headers = {
'Accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,*/*;q=0.8',
'Accept-Encoding': 'gzip, deflate, compress',
'Accept-Language': 'en-us;q=0.5,en;q=0.3',
'Cache-Control': 'max-age=0',
'Connection': 'keep-alive',
'User-Agent': 'Mozilla/5.0 (X11; Ubuntu; Linux x86_64; rv:22.0) Gecko/20100101 Firefox/22.0'
} #定义头文件,伪装成浏览器
def getfromBaidu(word):
start = time.clock()
url = 'http://www.baidu.com.cn/s?wd=' + urllib.parse.quote(word) + '&pn=' # word为关键词,pn是百度用来分页的..
pool = multiprocessing.Pool(multiprocessing.cpu_count())
for k in range(1, 5):
result = pool.apply_async(geturl, (url, k))# 多进程
pool.close()
pool.join()
end = time.clock()
print(end-start)
def geturl(url, k):
path = url + str((k - 1) * 10)
response = request.urlopen(path)
page = response.read()
soup = BeautifulSoup(page, 'lxml')
tagh3 = soup.find_all('h3')
for h3 in tagh3:
href = h3.find('a').get('href')
# print(href)
baidu_url = requests.get(url=href, headers=headers, allow_redirects=False)
real_url = baidu_url.headers['Location'] #得到网页原始地址
if real_url.startswith('http'):
urls.insert({"url": real_url})
# all.write(real_url + '\n')
if __name__ == '__main__':
getfromBaidu('周杰伦') pool = multiprocessing.Pool(multiprocessing.cpu_count())根据cpu的核数确认进程池里的进程数,多进程和POOL的用法详见点击打开链接
修改过的url2io.py
#coding: utf-8
#
# This program is free software. It comes without any warranty, to
# the extent permitted by applicable law. You can redistribute it
# and/or modify it under the terms of the Do What The Fuck You Want
# To Public License, Version 2, as published by Sam Hocevar. See
# http://sam.zoy.org/wtfpl/COPYING (copied as below) for more details.
#
# DO WHAT THE FUCK YOU WANT TO PUBLIC LICENSE
# Version 2, December 2004
#
# Copyright (C) 2004 Sam Hocevar
#
# Everyone is permitted to copy and distribute verbatim or modified
# copies of this license document, and changing it is allowed as long
# as the name is changed.
#
# DO WHAT THE FUCK YOU WANT TO PUBLIC LICENSE
# TERMS AND CONDITIONS FOR COPYING, DISTRIBUTION AND MODIFICATION
#
# 0. You just DO WHAT THE FUCK YOU WANT TO.
"""a simple url2io sdk
example:
api = API(token)
api.article(url='http://www.url2io.com/products', fields=['next', 'text'])
"""
__all__ = ['APIError', 'API']
DEBUG_LEVEL = 1
import sys
import socket
import json
import urllib
from urllib import request
import time
from collections import Iterable
import importlib
importlib.reload(sys)
headers = {
'Accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,*/*;q=0.8',
'Cache-Control': 'max-age=0',
'Connection': 'keep-alive',
'User-Agent': 'Mozilla/5.0 (X11; Ubuntu; Linux x86_64; rv:22.0) Gecko/20100101 Firefox/22.0'
} #定义头文件,伪装成浏览器
class APIError(Exception):
code = None
"""HTTP status code"""
url = None
"""request URL"""
body = None
"""server response body; or detailed error information"""
def __init__(self, code, url, body):
self.code = code
self.url = url
self.body = body
def __str__(self):
return 'code={s.code}\nurl={s.url}\n{s.body}'.format(s = self)
__repr__ = __str__
class API(object):
token = None
server = 'http://api.url2io.com/'
decode_result = True
timeout = None
max_retries = None
retry_delay = None
def __init__(self, token, srv = None,
decode_result = True, timeout = 30, max_retries = 5,
retry_delay = 3):
""":param srv: The API server address
:param decode_result: whether to json_decode the result
:param timeout: HTTP request timeout in seconds
:param max_retries: maximal number of retries after catching URL error
or socket error
:param retry_delay: time to sleep before retrying"""
self.token = token
if srv:
self.server = srv
self.decode_result = decode_result
assert timeout >= 0 or timeout is None
assert max_retries >= 0
self.timeout = timeout
self.max_retries = max_retries
self.retry_delay = retry_delay
_setup_apiobj(self, self, [])
def update_request(self, request):
"""overwrite this function to update the request before sending it to
server"""
pass
def _setup_apiobj(self, apiobj, path):
if self is not apiobj:
self._api = apiobj
self._urlbase = apiobj.server + '/'.join(path)
lvl = len(path)
done = set()
for i in _APIS:
if len(i) <= lvl:
continue
cur = i[lvl]
if i[:lvl] == path and cur not in done:
done.add(cur)
setattr(self, cur, _APIProxy(apiobj, i[:lvl + 1]))
class _APIProxy(object):
_api = None
_urlbase = None
def __init__(self, apiobj, path):
_setup_apiobj(self, apiobj, path)
def __call__(self, post = False, *args, **kwargs):
# /article
# url = 'http://xxxx.xxx',
# fields = ['next',],
#
if len(args):
raise TypeError('only keyword arguments are allowed')
if type(post) is not bool:
raise TypeError('post argument can only be True or False')
url = self.geturl(**kwargs)
request = urllib.request.Request(url,headers=headers)
self._api.update_request(request)
retry = self._api.max_retries
while True:
retry -= 1
try:
ret = urllib.request.urlopen(request, timeout = self._api.timeout).read()
break
except urllib.error.HTTPError as e:
raise APIError(e.code, url, e.read())
except (socket.error, urllib.error.URLError) as e:
if retry < 0:
raise e
_print_debug('caught error: {}; retrying'.format(e))
time.sleep(self._api.retry_delay)
if self._api.decode_result:
try:
ret = json.loads(ret)
except:
raise APIError(-1, url, 'json decode error, value={0!r}'.format(ret))
return ret
def _mkarg(self, kargs):
"""change the argument list (encode value, add api key/secret)
:return: the new argument list"""
def enc(x):
#if isinstance(x, unicode):
# return x.encode('utf-8')
#return str(x)
return x.encode('utf-8') if isinstance(x, str) else str(x)
kargs = kargs.copy()
kargs['token'] = self._api.token
for (k, v) in kargs.items():
if isinstance(v, Iterable) and not isinstance(v, str):
kargs[k] = ','.join([str(i) for i in v])
else:
kargs[k] = enc(v)
return kargs
def geturl(self, **kargs):
"""return the request url"""
return self._urlbase + '?' + urllib.parse.urlencode(self._mkarg(kargs))
def _print_debug(msg):
if DEBUG_LEVEL:
sys.stderr.write(str(msg) + '\n')
_APIS = [
'/article',
#'/images',
]
_APIS = [i.split('/')[1:] for i in _APIS]