工作流调度器azkaban笔记(2) —— 案例测试
1 Command类型多job工作流flow
1.1 创建job
foo.job
# foo.job
type=command
command=echo foo
bar.job
# bar.job
type=command
dependencies=foo
将2个job打包成一个 zip 压缩包
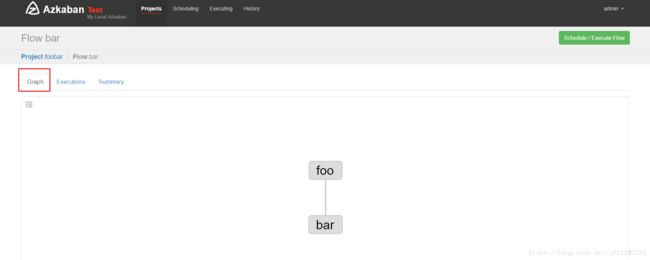
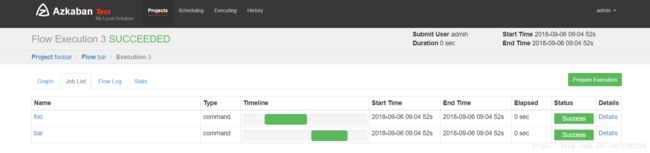
2.1 测试多job
访问 https://node1:8443
创建工程,上传 zip
2 HDFS操作任务
2.1 创建 job
# fs.job
type=command
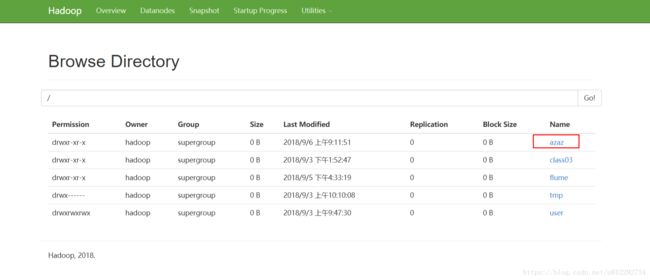
command=/home/hadoop/apps/hadoop-2.7.6/bin/hadoop fs -mkdir /azaz
打包成 zip
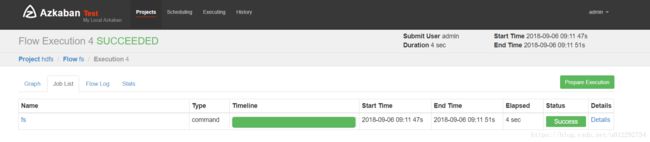
2.2 创建工程,上传zip
3 Mapreduce 任务
3.1 创建 job
# mrwc.job
type=command
command=/home/hadoop/apps/hadoop-2.7.6/bin/hadoop jar hadoop-mapreduce-examples-2.7.6.jar wordcount /wordcount/input /wordcount/azout
将 hadoop-mapreduce-examples-2.7.6.jar 和 job 打包成 zip 包
3.2 创建工程,上传zip
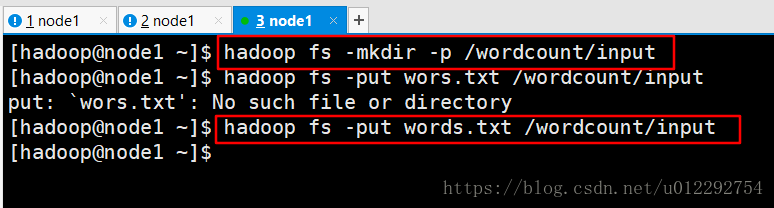
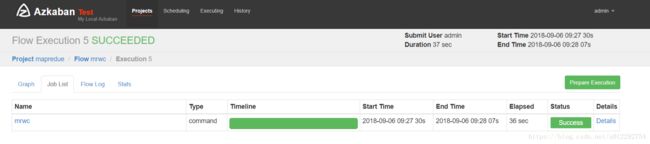
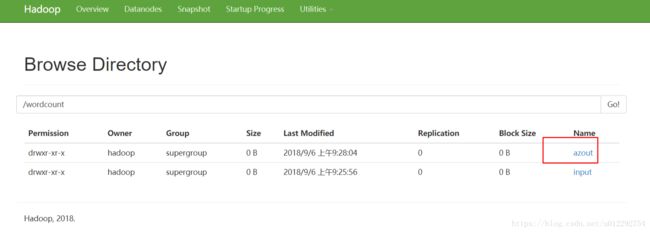
[hadoop@node1 ~]$ hadoop fs -cat /wordcount/azout/part-r-00000
$1 1
(APWG) 1
2,000 1
75 1
APWG 1
According 1
Anti-Phishing 1
Group 1
The 1
Working 1
a 1
also 2
are 1
as 1
attacks 1
billion 1
claim 1
claims 1
close 1
day 1
day. 1
each 2
email 2
emails 1
from 2
its 1
known 1
million 1
more 2
phishing 2
scams 2
sent 1
steal 1
than 2
that 2
the 1
these 1
to 2
victims 1
victims. 1
year 1
[hadoop@node1 ~]$ 4 HIVE脚本任务
4.1 创建 job
# hivef.job
type=command
command=/home/hadoop/apps/hive/bin/hive -f 'test.sql'
将 2个文件打包成 zip
test.sql
use school;
drop table aztest;
create table aztest(id int,name string) row format delimited fields terminated by ',';
load data inpath '/aztest/hiveinput' into table aztest;
create table azres as select * from aztest;
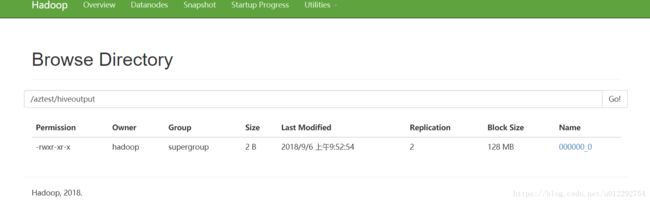
insert overwrite directory '/aztest/hiveoutput' select count(1) from aztest;
4. 2 准备数据
[hadoop@node1 ~]$ hadoop fs -mkdir -p /aztest/hiveinput
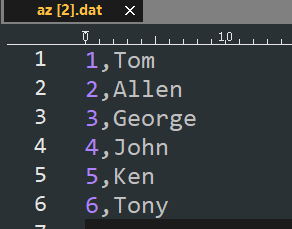
[hadoop@node1 ~]$ hadoop fs -put az.dat /aztest/hiveinput
4.3 新建工程,上传 zip
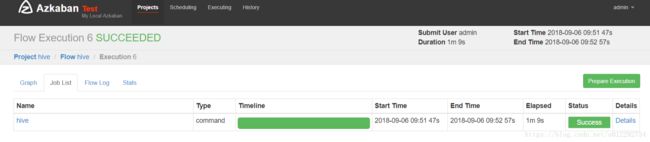
hive> show databases;
OK
default
school
Time taken: 0.015 seconds, Fetched: 2 row(s)
hive> use school;
OK
Time taken: 0.016 seconds
hive> show tables;
OK
a
azres
aztest
b
course
sc
student
t_buck
t_flow
t_temp
Time taken: 0.032 seconds, Fetched: 10 row(s)
hive> select * from aztest;
OK
1 Tom
2 Allen
3 George
4 John
5 Ken
6 Tony
Time taken: 2.343 seconds, Fetched: 6 row(s)
hive> select * from azres;
OK
1 Tom
2 Allen
3 George
4 John
5 Ken
6 Tony
Time taken: 0.239 seconds, Fetched: 6 row(s)
hive>
[hadoop@node1 ~]$ hadoop fs -cat /aztest/hiveoutput/000000_0
6
[hadoop@node1 ~]$