【机器学习sklearn】基于sklearn的股票预测
最近了解学习数据统计,了解到了python的sklearn这个库,集成了很多机器学习的模型,感觉很强大,官网
下面通过一个简单的预测的例子来上手sklearn这个库。
根据pythonprogramming上的例子改写。本次实验使用anaconda的集成环境,故不需要下载所需的包,但需要使用conda命令更新sklearn至官网教程所使用的版本(之前因为版本问题纠结了好久)。如果没有使用anaconda,需要先下载scipy,numpy等库作为支持,这里使用python自带的pip install命令即可方便下载。
导入相应的库
import pandas as pd
import numpy as np
import datetime
import pandas.io.data as web
import math
import matplotlib.pyplot as plt
from matplotlib import style
from sklearn.model_selection import cross_val_score
from sklearn import preprocessing, cross_validation, svm
from sklearn.linear_model import LinearRegression首先从互联网上获取我们所需要的yahoo的股票数据:
start = datetime.datetime(2015, 1, 1)
end = datetime.datetime(2016, 11, 20)
#从互联网获取数据
df = web.DataReader("XOM", "yahoo", start, end)
#print(df.head())构建我们的数据集
df = df[['Open', 'High', 'Low', 'Close', 'Volume']]
df['HL_PCT'] = (df['High'] - df['Low']) / df['Close'] * 100.0
df['PCT_change'] = (df['Close'] - df['Open']) / df['Open'] * 100.0
df = df[['Close', 'HL_PCT', 'PCT_change', 'Volume']]
#print(df.head())对空数据进行处理,同时对Close的股票value进行预测,forecast_out表示往后预测的天数
forecast_col = 'Close'
df.fillna(value=-99999, inplace=True)
forecast_out = int(math.ceil(0.01 * len(df)))
#预测forecast_out天后的重新构建X和y,X为[‘Close’, ‘HL_PCT’, ‘PCT_change’, ‘Volume’],y为[‘label’]表示forecast_out天后的股票值,使用preprocessing.scale对数据集进行scaling。
X_lately 表示后forecast_out天 的数据集,既对应的y值为NAN
df['label'] = df[forecast_col].shift(-forecast_out)
print(df.shape)
print(df.tail())
X = np.array(df.drop(['label'], 1))
X = preprocessing.scale(X)
X_lately = X[-forecast_out:]
X = X[:-forecast_out]
df.dropna(inplace=True)
print(X)
print(X_lately)
y = np.array(df['label'])
#print(y)
print(X.shape)
print(y.shape)选择数据集80%作为训练集,20%作为测试集
使用sklearn提供的Linear Regression函数进行建模,最后使用测试集进行测试,计算相应的精确度
X_train, X_test, y_train ,y_test = cross_validation.train_test_split(X,y,test_size=0.2)
clf = LinearRegression()
clf.fit(X_train,y_train)
accuracy = clf.score(X_test,y_test)
print(accuracy)forecast_set是我们通过训练集训练出的模型和我们的最近的数据进行的预测
把我们的预测集放入之前的DataFrame,最后绘图得到股票走势图
forecast_set = clf.predict(X_lately)
print(forecast_set,accuracy,forecast_out)
style.use('ggplot')
df['Forecast']=np.nan
last_date = df.iloc[-1].name
last_unix = last_date.timestamp()
print(last_date,last_unix)
one_day = 86400
next_unix = last_unix + one_day
for i in forecast_set:
next_date = datetime.datetime.fromtimestamp(next_unix)
next_unix += 86400
df.loc[next_date] = [np.nan for _ in range(len(df.columns)-1)]+[i]
print(df.tail())
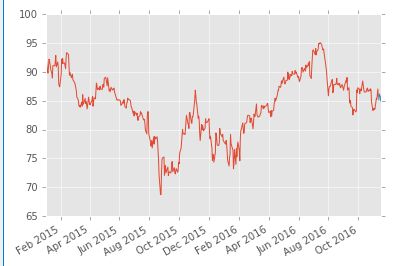
df['Close'].plot()
df['Forecast'].plot()
plt.show()
红线表示原始数据,蓝线表示预测的股票走势
具体代码,见Titanssword的github