dubbo源码分析26 -- 网络编解码
在网络传输中只将数据看作是原始的字节序列。然则,我们的应用程序需要把这些字节序列组成有意义的信息。将应用程序的数据转换为网络格式,以及将网络格式转换为应用程序的数据的组件分别叫作编码器和解码器,同时具有这两种功能的单一组件叫作编解码器。
1、粘包 & 拆包
基于前面的分析我们知道 dubbo 的远程调用是基于 Netty 这个 Nio 框架进行基于 TCP/IP 的 Socket 通信。
TCP 是一个“流”协议,所谓流就是没有界限的一串数据。可以想像一个河里的流水是连成一片的,其间没有分界线。TCP 底层并不了解上层业务数据的具体含义,它会根据 TCP 缓冲区的实际情况进行包的划分,所以在业务上认为,一个完整的包可能会被 TCP 拆分成多个包进行发送。也有可能把多个小的包封装成一个大的数据包发送,这就是所谓的 TCP 粘包和拆包问题。
1.1 TCP 粘包 & 拆包问题说明
下面就通过以下的图来说明 TCP 粘包与拆包问题:

假设客户端分别发送了两个数据包 D1 和 D2 给服务端,由于服务端一次读取到的字节数据是不确定的,所以可能存在以下 4 种情况。
- 服务端两次读取到了两个独立的数据包,分别是 D1 和 D2,没有粘包和拆包
- 服务端一次接收到了两个数据包, D1 和 D2 粘合在一起,被称为 TCP 粘包
- 服务端分两次读取到了两个数据包,第一次读取到了完整的 D1 包和 D2 包的部分内部,第二次读取到了 D2 包的剩余内部,这被称为 TCP 拆包
- 服务端两次读取到了两个数据包,第一次读取到了 D1 包的部分内部 D1_1,第二次读取到了 D1 包的剩余内部 D1_2 和 D2 包的整包。
如果此时服务端 TCP 接收滑窗非常小,而数据包 D1 和 D2 比较大 ,很有可能会发生第五种可能,即服务端分多次才能将 D1 和 D2 包接收完全,期间发生多次拆包。
1.2 解决粘包 & 拆包
由于底层的 TCP 无法理解上层的业务数据,所以在底层是无法保证数据包不被拆分和重组的。这个问题只能通过上层的应用协议栈设计来解决,主流的解决方案如下:
- 消息定长,例如每个报文的大小为固定长度 200 字节,如果不够,空位被空格。
- 在包尾增加回车换行符进行分割,例如 TFP 协议
- 将消息分为消息头和消息体,消息头中包含表示消息总长度(或者消息体长度)的字段。
netty 对于前 2 种都有自己的实现,而 dubbo 采用的是第 3 种来解决粘包与拆包问题的。
2、dubbo 自定义协议
Netty 对于开发者而言,其实就是操作 ChannelHandler 这个组件。之前我们分析了 dubbo 网络请求的发送与接收是实现了 ChannelHandler 的 NettyServerHandler。针对于编解码同样也是实现 ChannelHandler 来进行的。
NettyServer#doOpen
protected void doOpen() throws Throwable {
bootstrap = new ServerBootstrap();
bossGroup = new NioEventLoopGroup(1, new DefaultThreadFactory("NettyServerBoss", true));
workerGroup = new NioEventLoopGroup(getUrl().getPositiveParameter(Constants.IO_THREADS_KEY, Constants.DEFAULT_IO_THREADS),
new DefaultThreadFactory("NettyServerWorker", true));
final NettyServerHandler nettyServerHandler = new NettyServerHandler(getUrl(), this);
channels = nettyServerHandler.getChannels();
bootstrap.group(bossGroup, workerGroup)
.channel(NioServerSocketChannel.class)
.childOption(ChannelOption.TCP_NODELAY, Boolean.TRUE)
.childOption(ChannelOption.SO_REUSEADDR, Boolean.TRUE)
.childOption(ChannelOption.ALLOCATOR, PooledByteBufAllocator.DEFAULT)
.childHandler(new ChannelInitializer() {
@Override
protected void initChannel(NioSocketChannel ch) throws Exception {
NettyCodecAdapter adapter = new NettyCodecAdapter(getCodec(), getUrl(), NettyServer.this);
ch.pipeline()//.addLast("logging",new LoggingHandler(LogLevel.INFO))//for debug
.addLast("decoder", adapter.getDecoder())
.addLast("encoder", adapter.getEncoder())
.addLast("handler", nettyServerHandler);
}
});
// bind
ChannelFuture channelFuture = bootstrap.bind(getBindAddress());
channelFuture.syncUninterruptibly();
channel = channelFuture.channel();
}
在进行服务暴露的时候,在初始化的时候通过 ChannelPipeline 添加编码、解码与处理请求响应的具体 ChannelHandler 实现类。dubbo 编解码的具体都是通过 NettyCodecAdapter 来处理的。
下面我们来看一下 dubbo 的协议头约定:

dubbo 使用长度为 16 的 byte 数组作为协议头。1 个 byte 对应 8 位。所以 dubbo 的协议头有 128 位 (也就是上图的从 0 到 127)。我们来看一下这 128 位协议头分别代表什么意思。
- 0 ~ 7 : dubbo 魔数(
(short) 0xdabb) 高位,也就是 (short) 0xda。 - 8 ~ 15: dubbo 魔数(
(short) 0xdabb) 低位,也就是 (short) 0xbb。 - 16 ~ 20:序列化 id(Serialization id),也就是 dubbo 支持的序列化中的
contentTypeId,比如 Hessian2Serialization#ID 为 2 - 21 :是否事件(event )
- 22 : 是否 Two way 模式(Two way)。默认是 Two-way 模式,
- 23 :标记是请求对象还是响应对象(Req/res)
- 24 ~ 31:response 的结果响应码 ,例如 OK=20
- 32 ~ 95:id(long),异步变同步的全局唯一ID,用来做consumer和provider的来回通信标记。
- 96 ~ 127: data length,请求或响应数据体的数据长度也就是消息头+请求数据的长度。用于处理 dubbo 通信的粘包与拆包问题。
我们就根据源码来分析一下 dubbo 是如何进行编解码的。
3、协议源码分析
dubbo 的编解码可以分为以下 4 个部分来分析:
- consumer 请求编码
- consumer响应结果解码
- provider 请求解码
- provider 响应结果编码
在 dubbo 进行服务暴露的时候是通过 NettyCodecAdapter 来获取到需要添加的编码器与解码器。在 NettyCodecAdapter 里面定义内部类 InternalEncoder (继承 netty 中的 MessageToByteEncoder)实现 dubbo 的自定义编码器,定义内部类 ByteToMessageDecoder (继承 netty 中的 ByteToMessageDecoder) 实现 dubbo 自定义解码器。不管是自定义的编码器还是解码器最终都会调用到 dubbo 的 SPI 接口 Codec2 默认使用 DubboCodec。下面就具体的分析一下 dubbo 这 4 个编解码过程。
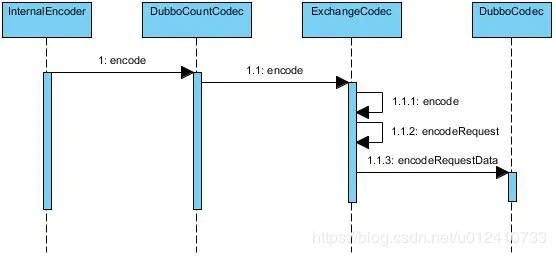
3.1 consumer 请求编码
consumer 在请求 provider 的时候需要把 Request 对象转化成 byte 数组,所以它是一个需要编码的过程。
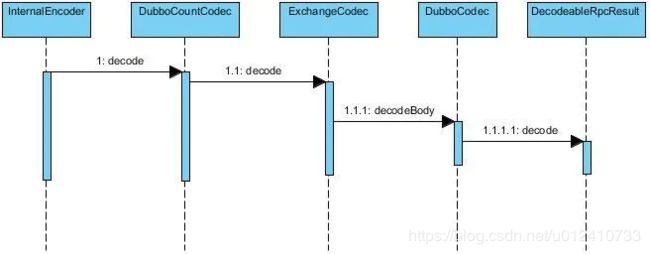
3.2 consumer响应结果解码
consumer 在接收 provider 响应的时候需要把 byte 数组转化成 Response 对象,所以它是一个需要解码的过程。
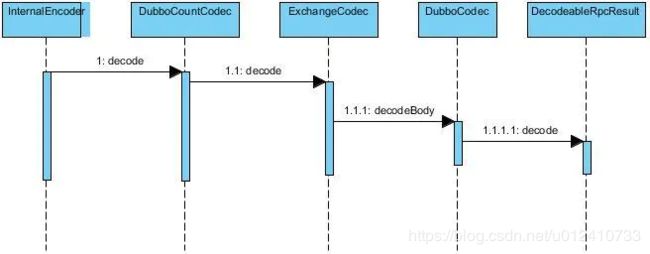
3.3 provider 请求解码
provider 在接收 consumer 请求的时候需要把 byte 数组转化成 Request 对象,所以它是一个需要解码的过程。
3.4 响应结果编码
provider 在处理完成 consumer 请求需要响应结果的时候需要把 Response 对象转化成 byte 数组,所以它是一个需要编码的过程。
