大数据平台搭建(二):hadoop HA 集群搭建
前言
本章搭建zookeeper集群和hadoop集群
1.hadoop版本的选择
1.目前而言,不收费的Hadoop版本主要有三个(均是国外厂商),分别是:Apache(最原始的版本,所有发行版均基于这个版本进行改进)、Cloudera版本(Cloudera’s Distribution Including Apache Hadoop,简称CDH)、Hortonworks版本(Hortonworks Data Platform,简称“HDP”),对于国内而言,绝大多数选择CDH版本。
2.上一段摘自网络,由于CDH用的比较多,所以我决定用CDH来搭建集群,但是我不想通过CM来安装,而是使用CDH tar包安装方式来搭建。
3.不用Apache版本原因是:CDH 提供的jar包比较稳定且不用自己去搭配版本(更多原因请看区别)。
4.不用CM安装CDH的方式原因是:太方便太傻瓜,我自己不放心,所以最终决定使用CDH5 tar包安装。
2. CDH和Apache原始版的区别
1. CDH对Hadoop版本的划分非常清晰,比如,cdh3、cdh4和cdh5,相比而言,Apache版本则混乱得多;比Apache hadoop在兼容性,安全性,稳定性上有增强。
2.CDH总是并应用了最新Bug修复或者Feature的Patch,并比Apache hadoop同功能版本提早发布,更新速度比Apache官方快。
3.安全 CDH支持Kerberos安全认证,apache hadoop则使用简陋的用户名匹配认证
4.)CDH文档清晰,很多采用Apache版本的用户都会阅读CDH提供的文档,包括安装文档、升级文档等。
5.)CDH支持Yum/Apt包,Tar包(本次使用方式),RPM包,Cloudera Manager四种方式安装,Apache hadoop只支持Tar包安装。
3.CDH版本选择
| hadoop生态选用CDH5.9.3 |
|---|
| jdk-8u161-linux-x64.tar.gz |
| zookeeper-3.4.5-cdh5.9.3.tar.gz |
| hadoop-2.6.0-cdh5.9.3.tar.gz |
| hive-1.1.0-cdh5.9.3.tar.gz |
| sqoop2-1.99.5-cdh5.9.3.tar.gz |
| hbase-1.2.0-cdh5.9.3.tar.gz |
| 。。。请认准cdh5.9.3去官方下载:http://archive.cloudera.com/cdh5/cdh/5/ |
4.集群规划
| 主机名称 | IP | 安装软件 | 运行的进程 |
|---|---|---|---|
| hadoop201 | 192.168.8.201 | jdk,hadoop | NameNode、 JournalNode 、DFSZKFailoverController(zkfc)、 ResourceManager |
| hadoop202 | 192.168.8.202 | jdk,hadoop | NameNode、 JournalNode 、DFSZKFailoverController(zkfc)、 ResourceManager |
| hadoop203 | 192.168.8.203 | jdk,hadoop,zk | DataNode、NodeManager、QuorumPeerMain |
| hadoop204 | 192.168.8.204 | jdk,hadoop,zk | DataNode、NodeManager、QuorumPeerMain |
| hadoop205 | 192.168.8.205 | jdk,hadoop, zk | DataNode、NodeManager、QuorumPeerMain |
DFSZKFailoverController:监控管理NameNode,必须跟NameNode在一起
JournalNode: 存储NameNode的状态等信息,包括edits文件等
QuorumPeerMain: zk进程,为什么用zookeeper?主要是利用zookeeper的选举机制、故障自动转移、心跳监测等保障高可靠
5.HDFS HA示例图
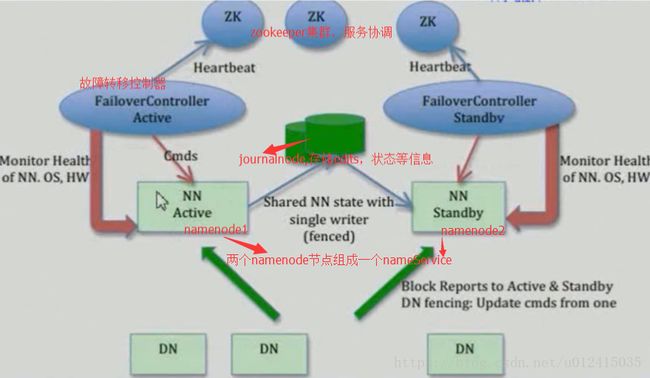
参考官方文档,使用QJM的HA方案来安装:

6.zookeeper集群搭建
1.203上安装,解压zk包,找到zoo.cfg,一般有个sample配置文件,改下名字即可。

2.vim zoo.cfg,主要修改数据目录和3个集群节点的通信选举端口
# The number of milliseconds of each tick
tickTime=2000
# The number of ticks that the initial
# synchronization phase can take
initLimit=10
# The number of ticks that can pass between
# sending a request and getting an acknowledgement
syncLimit=5
# the directory where the snapshot is stored.
# do not use /tmp for storage, /tmp here is just
# example sakes.
#数据文件目录
dataDir=/home/hadoop/zookeeper/data
#日志目录
#dataLogDir=/home/hadoop/zookeeper/zkdatalog
# the port at which the clients will connect
clientPort=2181
#
# Be sure to read the maintenance section of the
# administrator guide before turning on autopurge.
#
# http://zookeeper.apache.org/doc/current/zookeeperAdmin.html#sc_maintenance
#
# The number of snapshots to retain in dataDir
#autopurge.snapRetainCount=3
# Purge task interval in hours
# Set to "0" to disable auto purge feature
#autopurge.purgeInterval=1
#server.服务编号=主机名称:Zookeeper不同节点之间同步和通信的端口:选举端口
server.3=hadoop203:2888:3888
server.4=hadoop204:2888:3888
server.5=hadoop205:2888:3888
3.将配置好的zookeeper文件夹scp到204 205上
4.三个节点分别cd到数据目录/home/hadoop/zookeeper/data下,创建myid文件,输入各自编号3,4,5 ,要跟zoo.cfg中配置的编号一致。
5.启动zk,/home/hadoop/zookeeper/sbin/zkServer.sh start
6.验证,jps zk进程QuorumPeerMain已启动。zkServer.sh status,一个leader,两个follower,即搭建成功。如果不放心,可以杀掉一个zk,然后看角色变化。

7.hadoop集群搭建
1.下载安装notepad++插件NPPFTP,为了修改配置文件方便,文件可以直接在notepad中打开修改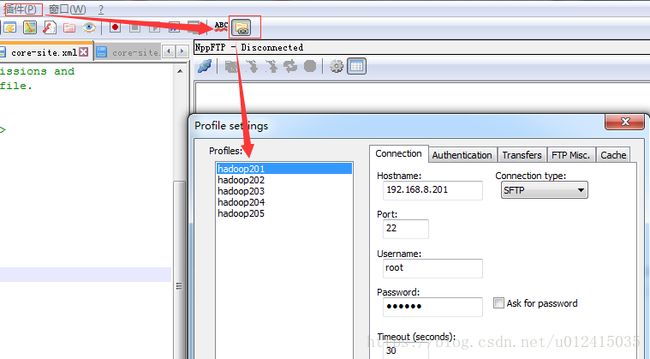
2.下载解压hadoop对应cdh版本5.9.3,在201上安装 ,并设置环境变量
3.配置hdfs,共4个,参考官方文档
hadoop-env.sh,主要是配置jdk
core-site.xml
"1.0" encoding="UTF-8"?>
"text/xsl" href="configuration.xsl"?>
fs.defaultFS
hdfs://mycluster
hadoop.tmp.dir
/home/hadoop/hadoop/tmp
dfs.journalnode.edits.dir
/home/hadoop/journalnodeTmp
ha.zookeeper.quorum
hadoop203:2181,hadoop204:2181,hadoop205:2181
hdfs-site.xml
"1.0" encoding="UTF-8"?>
"text/xsl" href="configuration.xsl"?>
dfs.nameservices
mycluster
dfs.ha.namenodes.mycluster
nn1,nn2
dfs.namenode.rpc-address.mycluster.nn1
hadoop201:9000
dfs.namenode.rpc-address.mycluster.nn2
hadoop202:9000
dfs.namenode.http-address.mycluster.nn1
hadoop201:50070
dfs.namenode.http-address.mycluster.nn2
hadoop202:50070
dfs.namenode.shared.edits.dir
qjournal://hadoop201:8485;hadoop202:8485/mycluster
dfs.journalnode.edits.dir
/home/hadoop/hadoop/journal
dfs.client.failover.proxy.provider.mycluster
org.apache.hadoop.hdfs.server.namenode.ha.ConfiguredFailoverProxyProvider
dfs.ha.fencing.methods
sshfence
shell(/bin/true)
dfs.ha.fencing.ssh.private-key-files
/home/hadoop/.ssh/id_rsa
dfs.ha.fencing.ssh.connect-timeout
30000
dfs.ha.automatic-failover.enabled
true
slaves
4.配置yarn,共2个,参考官方文档
mapred-site.xml
"1.0"?>
"text/xsl" href="configuration.xsl"?>
mapreduce.framework.name
yarn
yarn-site.xml
"1.0"?>
yarn.resourcemanager.ha.enabled
true
yarn.resourcemanager.ha.automatic-failover.enabled
true
yarn.resourcemanager.recovery.enabled
true
yarn.resourcemanager.cluster-id
cluster1
yarn.resourcemanager.ha.rm-ids
rm1,rm2
yarn.resourcemanager.hostname.rm1
hadoop201
yarn.resourcemanager.hostname.rm2
hadoop202
yarn.resourcemanager.address.rm1
hadoop201:8032
yarn.resourcemanager.scheduler.address.rm1
hadoop201:8034
yarn.resourcemanager.webapp.address.rm1
hadoop201:8088
yarn.resourcemanager.address.rm2
hadoop202:8032
yarn.resourcemanager.scheduler.address.rm2
hadoop202:8034
yarn.resourcemanager.webapp.address.rm2
hadoop202:8088
yarn.resourcemanager.zk-address
hadoop203:2181,hadoop204:2181,hadoop205:2181
yarn.resourcemanager.zk.state-store.address
hadoop203:2181,hadoop204:2181,hadoop205:2181
yarn.nodemanager.aux-services
mapreduce_shuffle
yarn.nodemanager.aux-services.mapreduce_shuffle.class
org.apache.hadoop.mapred.ShuffleHandler
更多配置属性,请参考*-default.xml默认配置文件。
至此,集群的配置工作基本完成,下面就要完成集群的初始化、启动和关闭了。
8.hadoop集群初始化
1.启动zk,在203 204 205上执行
2.启动journalNode,在201 202节点上执行hadoop-daemon.sh start journalnode
3.格式化hdfs,在201上执行命令: hdfs namenode -format
4.格式化高可用,在201上执行: hdfs zkfc -formatZK,查看zk根目录下,多了个ha的目录:
5.同步NameNode的元数据信息
201执行: hdfs namenode
202节点执行: hdfs namenode -bootstrapStandby,同步完成后,ctrl+c结束掉201的进程
6.启动hdfs,在201上执行,sbin/start-dfs.sh
7.启动yarn,
在201上执行,sbin/start-yarn.sh
在202上执行:sbin/yarn-daemon.sh start resourcemanager (单独启动rm进程)
8.各节点进程展示

9.测试hdfs HA,kill掉一个namenode进程,然后通过http://hadoop201:50070/,http://hadoop202:50070/查看201和202节点的状态转换,不再演示。
10.测试hdfs和yarn
本地创建:vim a.txt
上传到hdfs:
hdfs dfs -mkdir /test
hdfs dfs -put a.txt /test
hdfs dfs -ls /test/

测试yarn:查看rs状态:bin/yarn rmadmin -getServiceState rm1

运行mr,测试workcount示例:
hadoop jar share/hadoop/mapreduce/hadoop-mapreduce-examples-2.6.0-cdh5.9.3.jar wordcount /test/a.txt /test/out/

统计信息如下

9.集群启动顺序
1.启动zk,203 204 205bin目录下 ./zkServer.sh start
2.启动hdfs,201 sbin/start-dfs.sh
3.启动yarn,
201: sbin/start-yarn.sh
202: sbin/yarn-daemon.sh start resourcemanager
10.集群关闭顺序
1.关闭yarn
201执行 sbin/stop-yarn.sh
202执行 sbin/yarn-daemon.sh stop resourcemanager
2.关闭hdfs,201执行 sbin/stop-dfs.sh
3.关闭zookeeper,203 204 205执行./zkServer.sh stop
11.观察dfs启动和关闭顺序:
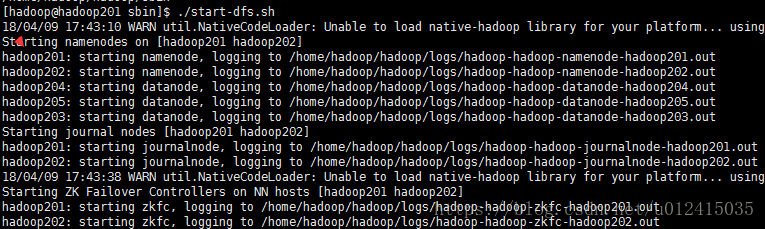

12.搭建过程中遇到的问题
1.Linux用户权限问题,用root用户搭建不存在这问题
chown -R hadoop zookeeper/ 递归更改文件夹的所属用户
chgrp -R hadoop zookeeper/ 递归更改文件夹的所属组
2.hdfs格式化会报connected refused
原因:namenode节点没有启动journalnode进程
解决:namenode节点 优先启动journalnode再进行格式化
3.201启动dfs,202节点的namenode没有启动起来,日志报connected refused
原因:202的core-site.xml 没有指定hadoop临时文件目录,这个需要跟201指定目录一致
解决:把所有节点的core-site.xml中指定同样的目录,删除tmp文件夹,重新格式化
总结:
本文主要讲了zookeeper集群和hadoop集群的搭建,其实看下来主要工作在配置文件,其他的都比较简单。下一章节将继续扩展。
大数据平台搭建(三):hive 介绍和安装配置