深度学习经典网络回顾:GoogleNet系列
今天我们回顾下14年的经典模型GoogleNet以及其后续系列模型。
话不多说先上图
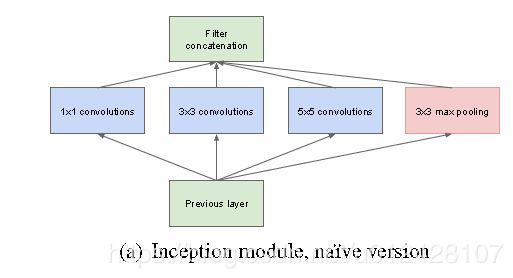
上图所示是GoogleNet的原始网络模块(Block),称作Inception(该名称来自于电影《盗梦空间》)而整个GoogleNet大部分由该模型不断串联而成(除了底层网络的几层以外),这样的网络串联网络的思想来源于NiN(Network in Network)网络,并且该思想对其后网络的设计包括ResNet都产生了较大的影响。
从图中可以直观地看出该网络与一般的卷积模块所最大的不同是该网络同一“层”中有不同尺度的多个卷积核,最后在channel这个维度上将输出并联起来,这样就可以得到同一层上的多尺度特征,有一个多尺度特征融合的效果。
details:为什么卷积核要设置成1x1,3x3,5x5,文章说是为了避免patch-alignment issues问题,即方便所有卷积后的输出的尺寸设置成相同的,能够并联到一起。
PS:当时腾讯一面被问到卷积核尺寸为什么都被设计成奇数?
1.保护位置信息:保证了 锚点 刚好在中间,方便以模块中心为标准进行滑动卷积,避免了位置信息发生 偏移,如 目标检测中多采用VGG或者ResNet作为Backbone网络时,原图到最后一个特征层的stride是16,特征图上一个点对应原图相应位置16x16的区域,只有卷积核为奇数才能对应过去。
2.padding时对称:保证了 padding 时,图像的两边依然相 对称 ,这样Inception才能够通过padding使得不同尺寸的卷积核的输出相同尺寸。
上图所示是Inception的原始结构,但实际结构却是下图这样:

为什么要加入1X1的卷积核,因为如果仅仅引入多个尺寸的卷积核,会带来大量的额外的参数,受到Network In Network中1×1卷积核的启发,为了解决这个问题,他们往Inception结构中加入了一些1×1的卷积核,我们把这个1x1的卷积叫做bottleneck。该结构对后续网络设计影响广泛,在ResNet、可分离卷积中也通过该结构来降低参数量。
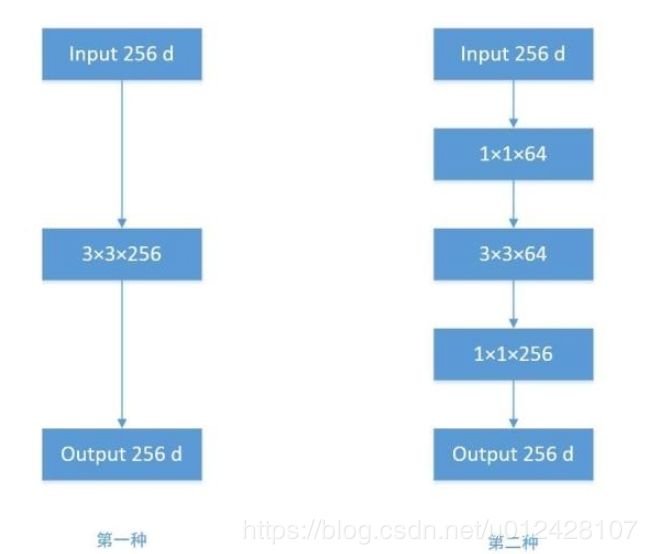
在这里1X1的卷积核的主要作用是降低参数量,右图加入bottleneck结构的参数量只有左边的9分之1。其次引入一些非线性,增加提取特征的能力。
以上是网络的主要结构和思想。
下面是Inception结构的pytorch实现代码:
def basic_conv2D(in_channels, out_channels, kernel, stride=1, padding=0):
layer = nn.Sequential(
nn.Conv2d(in_channels, out_channels, kernel, stride, padding),
nn.BatchNorm2d(out_channels, eps=1e-3),
nn.ReLU(True)
)
return layer
class Inception_v1(nn.Module):
def __init__(self, in_channel, out1_1, out2_1, out2_3, out3_1, out3_5, out4_1):
super(Inception_v1, self).__init__()
# 第一条线路
self.branch1x1 = basic_conv2D(in_channel, out1_1, 1)
# 第二条线路
self.branch3x3 = nn.Sequential(
basic_conv2D(in_channel, out2_1, 1),
basic_conv2D(out2_1, out2_3, 3, padding=1)
)
# 第三条线路
self.branch5x5 = nn.Sequential(
basic_conv2D(in_channel, out3_1, 1),
basic_conv2D(out3_1, out3_5, 5, padding=2)
)
# 第四条线路
self.branch_pool = nn.Sequential(
nn.MaxPool2d(3, stride=1, padding=1),
basic_conv2D(in_channel, out4_1, 1)
)
def forward(self, x):
f1 = self.branch1x1(x)
f2 = self.branch3x3(x)
f3 = self.branch5x5(x)
f4 = self.branch_pool(x)
output = torch.cat((f1, f2, f3, f4), dim=1)
return output
全图结构如下所示:
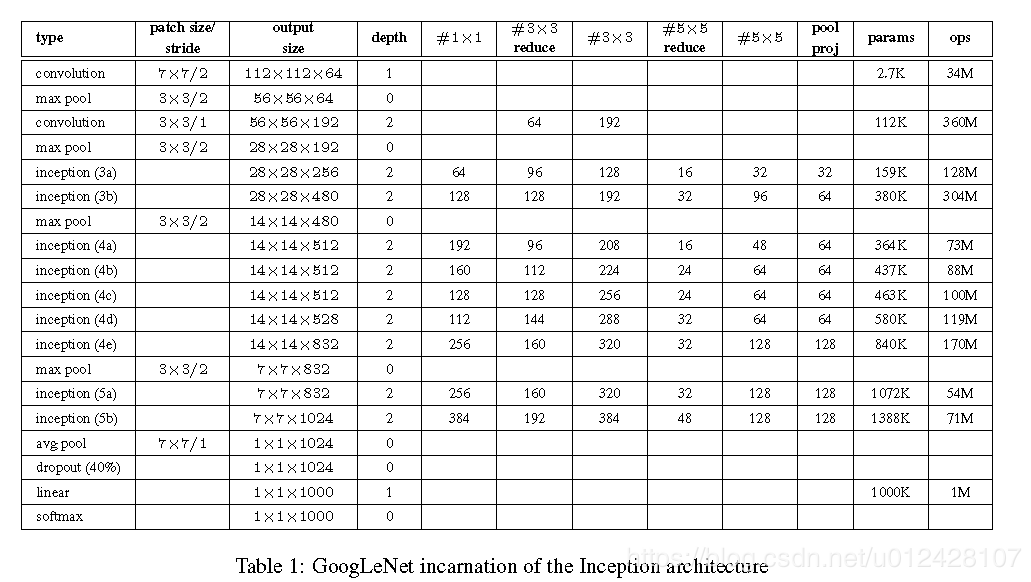
值得一提的是原网络中还在中间层的输出上增加了两个辅助的分类loss,作者认为中间层的特征should be discriminative。因此相对中间层的特征进行更好的利用,使其增强网络的梯度信息,提供额外的正则化。在训练时考虑到这两个loss,并一同计算,对他们赋予0.3的权重,在测试时,忽略。
在此之上后来google又推出了Inception的v2,v3, v4以及inception-resnet结构,总体来说,只是在原来的基础上的一些小修小补。
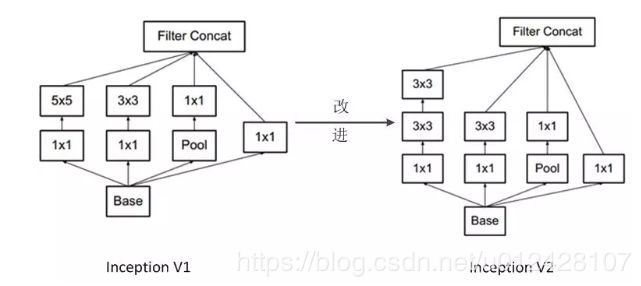
InceptionV2改进:增加了BN层(原始的Inception中是没有BN层的),用两个3x3的卷积核堆叠起来代替5x5卷积(从感受野上是等价的,同时减少参数量,增加了非线性)。
代码:
class BasicConv2d(nn.Module):
def __init__(self, in_channels, out_channels, **kwargs):
super(BasicConv2d, self).__init__()
self.conv = nn.Conv2d(in_channels, out_channels, bias=False, **kwargs)
self.bn = nn.BatchNorm2d(out_channels, eps=0.001)
def forward(self, x):
x = self.conv(x)
x = self.bn(x)
return F.relu(x, inplace=True)
class InceptionB(nn.Module):
def __init__(self, in_channels):
super(InceptionB, self).__init__()
self.branch3x3 = BasicConv2d(in_channels, 384, kernel_size=3, stride=2)
self.branch3x3dbl_1 = BasicConv2d(in_channels, 64, kernel_size=1)
self.branch3x3dbl_2 = BasicConv2d(64, 96, kernel_size=3, padding=1)
self.branch3x3dbl_3 = BasicConv2d(96, 96, kernel_size=3, stride=2)
def forward(self, x):
branch3x3 = self.branch3x3(x)
branch3x3dbl = self.branch3x3dbl_1(x)
branch3x3dbl = self.branch3x3dbl_2(branch3x3dbl)
branch3x3dbl = self.branch3x3dbl_3(branch3x3dbl)
branch_pool = F.max_pool2d(x, kernel_size=3, stride=2)
outputs = [branch3x3, branch3x3dbl, branch_pool]
return torch.cat(outputs, 1)InceptionV3也是同样的套路,用1x7和7x1代替7x7

代码:
class BasicConv2d(nn.Module):
def __init__(self, in_channels, out_channels, **kwargs):
super(BasicConv2d, self).__init__()
self.conv = nn.Conv2d(in_channels, out_channels, bias=False, **kwargs)
self.bn = nn.BatchNorm2d(out_channels, eps=0.001)
def forward(self, x):
x = self.conv(x)
x = self.bn(x)
return F.relu(x, inplace=True)
class InceptionC(nn.Module):
def __init__(self, in_channels, channels_7x7):
super(InceptionC, self).__init__()
self.branch1x1 = BasicConv2d(in_channels, 192, kernel_size=1)
c7 = channels_7x7
self.branch7x7_1 = BasicConv2d(in_channels, c7, kernel_size=1)
self.branch7x7_2 = BasicConv2d(c7, c7, kernel_size=(1, 7), padding=(0, 3))
self.branch7x7_3 = BasicConv2d(c7, 192, kernel_size=(7, 1), padding=(3, 0))
self.branch7x7dbl_1 = BasicConv2d(in_channels, c7, kernel_size=1)
self.branch7x7dbl_2 = BasicConv2d(c7, c7, kernel_size=(7, 1), padding=(3, 0))
self.branch7x7dbl_3 = BasicConv2d(c7, c7, kernel_size=(1, 7), padding=(0, 3))
self.branch7x7dbl_4 = BasicConv2d(c7, c7, kernel_size=(7, 1), padding=(3, 0))
self.branch7x7dbl_5 = BasicConv2d(c7, 192, kernel_size=(1, 7), padding=(0, 3))
self.branch_pool = BasicConv2d(in_channels, 192, kernel_size=1)
def forward(self, x):
branch1x1 = self.branch1x1(x)
branch7x7 = self.branch7x7_1(x)
branch7x7 = self.branch7x7_2(branch7x7)
branch7x7 = self.branch7x7_3(branch7x7)
branch7x7dbl = self.branch7x7dbl_1(x)
branch7x7dbl = self.branch7x7dbl_2(branch7x7dbl)
branch7x7dbl = self.branch7x7dbl_3(branch7x7dbl)
branch7x7dbl = self.branch7x7dbl_4(branch7x7dbl)
branch7x7dbl = self.branch7x7dbl_5(branch7x7dbl)
branch_pool = F.avg_pool2d(x, kernel_size=3, stride=1, padding=1)
branch_pool = self.branch_pool(branch_pool)
outputs = [branch1x1, branch7x7, branch7x7dbl, branch_pool]
return torch.cat(outputs, 1)InceptionV4结构比上述结构更复杂,且原理相同,就不一一列举了(而且电脑跑不动,滑稽脸),现在主流网络还是ResNet系列以及VGG,Inceptionv4及inception-ResNet设计过于精巧,应用并不广泛,电脑还跑不动,了解思想即可。
下面是Inception-ResNet的一般形式,即残差+Inception。个人理解:ResNet中的残差是一种思想不是一种固定的结构,本质是f(x)+x,它中间可以套用任意一种结构,如Inception和SENet等。

举例:

代码:
class InceptionResNetC(nn.Module):
def __init__(self, input_channels):
# Figure 19. The schema for 8×8 grid (Inception-ResNet-C)
# module of the Inception-ResNet-v2 network."""
super().__init__()
self.branch3x3 = nn.Sequential(
BasicConv2d(input_channels, 192, kernel_size=1),
BasicConv2d(192, 224, kernel_size=(1, 3), padding=(0, 1)),
BasicConv2d(224, 256, kernel_size=(3, 1), padding=(1, 0))
)
self.branch1x1 = BasicConv2d(input_channels, 192, kernel_size=1)
self.reduction1x1 = nn.Conv2d(448, 2048, kernel_size=1)
self.shorcut = nn.Conv2d(input_channels, 2048, kernel_size=1)
self.bn = nn.BatchNorm2d(2048)
self.relu = nn.ReLU(inplace=True)
def forward(self, x):
residual = [
self.branch1x1(x),
self.branch3x3(x)
]
residual = torch.cat(residual, 1)
residual = self.reduction1x1(residual) * 0.1
shorcut = self.shorcut(x)
output = self.bn(shorcut + residual)
output = self.relu(output)
return output整体网络:

代码:
class InceptionResNetV2(nn.Module):
def __init__(self, A, B, C, k=256, l=256, m=384, n=384, class_nums=10):
super().__init__()
self.stem = Inception_Stem(3)
self.inception_resnet_a = self._generate_inception_module(384, 384, A, InceptionResNetA)
self.reduction_a = InceptionResNetReductionA(384, k, l, m, n)
output_channels = self.reduction_a.output_channels
self.inception_resnet_b = self._generate_inception_module(output_channels, 1154, B, InceptionResNetB)
self.reduction_b = InceptionResNetReductionB(1154)
self.inception_resnet_c = self._generate_inception_module(2146, 2048, C, InceptionResNetC)
self.avgpool = nn.AvgPool2d(6)
# """Dropout (keep 0.8)"""
self.dropout = nn.Dropout2d(1 - 0.8)
self.linear = nn.Linear(2048, class_nums)
def forward(self, x):
x = self.stem(x)
x = self.inception_resnet_a(x)
x = self.reduction_a(x)
x = self.inception_resnet_b(x)
x = self.reduction_b(x)
x = self.inception_resnet_c(x)
x = self.avgpool(x)
x = self.dropout(x)
x = x.view(-1, 2048)
x = self.linear(x)
return x
@staticmethod
def _generate_inception_module(input_channels, output_channels, block_num, block):
layers = nn.Sequential()
for l in range(block_num):
layers.add_module("{}_{}".format(block.__name__, l), block(input_channels))
input_channels = output_channels
return layers