LeetCode 刷题笔记(Go)
1、动态定义二维数组
n:=10
var e[][]bool
e=make([][]bool,n)
for i:=0;i单词搜索
回溯算法
定义
回溯算法实际上一个类似枚举的搜索尝试过程,主要是在搜索尝试过程中寻找问题的解,当发现已不满足求解条件时,就“回溯”返回,尝试别的路径。
回溯法是一种选优搜索法,按选优条件向前搜索,以达到目标。但当探索到某一步时,发现原先选择并不优或达不到目标,就退回一步重新选择,这种走不通就退回再走的技术为回溯法,而满足回溯条件的某个状态的点称为“回溯点”。
许多复杂的,规模较大的问题都可以使用回溯法,有“通用解题方法”的美称。
1
基本思想
在包含问题的所有解的解空间树中,按照深度优先搜索的策略,从根结点出发深度探索解空间树。当探索到某一结点时,要先判断该结点是否包含问题的解,如果包含,就从该结点出发继续探索下去,如果该结点不包含问题的解,则逐层向其祖先结点回溯。(其实回溯法就是对隐式图的深度优先搜索算法)。
若用回溯法求问题的所有解时,要回溯到根,且根结点的所有可行的子树都要已被搜索遍才结束。
而若使用回溯法求任一个解时,只要搜索到问题的一个解就可以结束。
用回溯法解题的一般步骤:
针对所给问题,确定问题的解空间:问题的解空间应该至少包含问题的一个(最优)解
确定节点的扩展搜索规则
以深度优先方式搜索解空间,并在搜索过程中利用剪枝函数避免无效搜索。
递归解法框架
递归函数的开头写好跳出条件,满足条件才将当前结果加入总结果中(如果只是求是否有解,则直接返回结果即可。)
已经拿过的数不再拿 if(s.contains(num)){continue;}
遍历过当前节点后,为了回溯到上一步,要去掉已经加入到结果list中的当前节点。

func exist(board [][]byte, word string) bool {
row:=len(board)
col:=len(board[0])
var visited [][]bool
visited=make([][]bool,row)
for i:=0;i=len(board)||col>=len(board[0]) {
return false
}
if visited[row][col]!=true&&word[index]==board[row][col] {
visited[row][col]=true
is:=dfs(board,word,index+1,visited,row+1,col)||dfs(board,word,index+1,visited,row-1,col)||dfs(board,word,index+1,visited,row,col+1)||dfs(board,word,index+1,visited,row,col-1)
visited[row][col]=false
return is
}
return false
}
单词拆分
通用的查找Slice是否包含某个元素的函数
func isExistItem(value interface{},array interface{})bool{
switch reflect.TypeOf(array).Kind() {
case reflect.Slice:
s:=reflect.ValueOf(array)
for i:=0;istring 转 []byte
var data []byte=[]byte(str)
byte[]转string
var str string=string(data[i:j]) //左闭右开
这个题的题意是 字典中的单词是否可以拼成s字符串,字典中单词可重复使用。这也就是说我们s字符串分割之后,所有的单词都必须在字典里可以找得到,但字典里的单词不一定全部都用得上。
用一个boolean类型的数组flags来记录 字符串某个位置前,是否可以由字典里的某些单词拼成。
初始flags[0]=true,再从下标1开始,判断下标1之前也就是 0-0 之间是否是由字典组成的, 判断下标2之前 也就是0-1是否是由字典组成的, 然后3 , 判断下标3,4,5,6,7……
这里的true,如果某个位置x的flags[x]为true,那么代表可以从这个位置的字母开始分割,否则即使是这个字母开始的一个子字符串在字典中,也是不可以的。
func wordBreak(s string, wordDict []string) bool {
var flag []bool
flag=make([]bool,len(s)+1)
flag[0]=true
for i:=1;i<=len(s);i++{
for j:=0;j34. 在排序数组中查找元素的第一个和最后一个位置
用折半的思想不难,就是注意一些细节的坑
package main
import "math"
var min,max int
func searchRange(nums []int, target int) []int{
min=math.MaxInt32
max=-1
halfFind(nums,target,0,len(nums)-1)
if max==-1{
return []int{-1,-1}
}
return []int{min,max}
}
func halfFind(nums []int,target int,begin int,len int) {
if begin>len{
return
}
half:=(begin+len)/2
if nums[half]==target {
smallOrBig(begin,half,len,nums,target)
return
}else if nums[half]>target{
halfFind(nums,target,begin,half-1)
}else{
halfFind(nums,target,half+1,len)
}
}
func smallOrBig(begin,n,len int,nums []int,target int){
for i:=begin;i<=n;i++{
if nums[i]==target{
if imax{
max=j
}
}
}
}
15. 三数之和

Slice实现简单排序
import “sort”
//sort.slice排序实现比较方法即可
- Len方法
- Less方法
- Swap方法
sort 包中提供了 sort.Slice() 函数进行更为简便的排序方法。sort.Slice() 函数只要求传入需要排序的数据,以及一个排序时对元素的回调函数,类型为 func(i,j int)bool
package main
import (
"fmt"
"sort"
)
/*slice 简单排序示例*/
func main() {
//定义一个slice
ageList := []int{1, 3, 7, 7, 8, 2, 5}
//排序,实现比较方法即可
sort.Slice(ageList, func(i, j int) bool {
return ageList[i] < ageList[j]
})
fmt.Printf("after sort:%v", ageList)
}
二维切片赋值
先用append填充一维的,然后将一维append到二维
var a [][]int
for i := 0; i < 10; i++ {
var tmp []int
for j:= 0; j < 10; j++ {
tmp = append(tmp, j)
}
a = append(a, tmp)
}
解题思路
首先对nums进行从小到大的排序
因为a+b+c=0
所以至少有一个是负数,又因为排序后,所以a一定是负数
若len(nums)长度小于3或者a>0直接返回空[][]int,这样我们就可以看出,只需要考虑nums[a]<0的a的情况就行,一旦nums[a]>0就直接结束for循环停止寻找就行,另外需要排除重复结果,因为排序过,所以排除很方便,只要连续判断重复nums就行
if i>0&&nums[i-1]==nums[i]{
continue
}
for left代码
func threeSum(nums []int) [][]int {
var result [][]int
nums=sortThis(nums)
if len(nums)<3 {
return result
}
length:=len(nums)
left,right,dif:=0,0,0
for i:=0;i0{
break
}
if i>0&&nums[i-1]==nums[i]{
continue
}
left=i+1
right=length-1
dif=-nums[i]
for left 287. 寻找重复数
一种是利用折半查找的思想,寻找小于half的个数与half的大小关系判断重复数的范围是(left,half)还是(half+1,right),逐渐缩小范围直至找到重复数
另一种是利用循环队列查找起始点的思想,设置快慢指针寻找重复数
func findDuplicate(nums []int) int {
length:=len(nums)
var slow,fast int
if(length>1){
slow=nums[0]
fast=nums[slow]
for slow!=fast{
slow=nums[slow]
fast=nums[nums[fast]]
}
result:=0
for result!=slow{
result=nums[result]
slow=nums[slow]
}
return result
}
return -1
}
347. 前 K 个高频元素
解题思路
题目最终需要返回的是前k个频率最大的元素,可以想到借助堆这种数据结构,对于k频率之后的元素不用再去处理
- 借助哈希表来建立数字和其出现次数的映射,遍历一遍数组统计元素的频率
- 维护一个元素数目为k的最小堆
- 每次都将新的元素与堆顶元素(堆中频率 最小的元素)进行比较
- 如果新的元素的频率比堆顶端的元素大,则弹出堆顶端的元素,将新的元素添加进堆中
- 最终,堆中的k个元素即为前k个高频元素
import "container/heap"
type Item struct{
fre int
num string
}
type freHeap []*Item
func (h freHeap)Len()int{
return len(h)
}
func (h freHeap)Less(i,j int)bool{
return h[i].freh[0].fre{
heap.Pop(&h)
heap.Push(&h,&Item{
fre: fre,
num: strconv.Itoa(num),
})
}
}
var result []int
for i:=0;i 19. 删除链表的倒数第N个节点

用双指针,两指针相距n,先让后面指针先走n,然后一起向后移动直至后面那个指针NULL
/**
* Definition for singly-linked list.
* type ListNode struct {
* Val int
* Next *ListNode
* }
*/
func removeNthFromEnd(head *ListNode, n int) *ListNode {
begin:=&ListNode{Next:head}
temp1,temp2:=begin,begin
flag:=1
for flag<=n{
temp2=temp2.Next
flag++
}
for temp2.Next!=nil{
temp2=temp2.Next
temp1=temp1.Next
}
temp1.Next=temp1.Next.Next
return begin.Next
}
警告:删除的是temp1后面的那个值
141. 环形链表
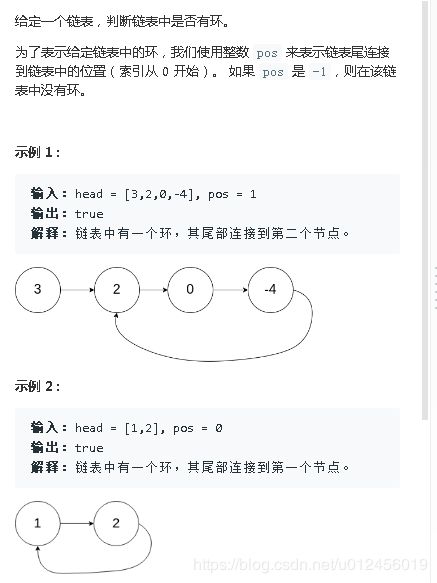
解题思想:快慢指针
/**
* Definition for singly-linked list.
* type ListNode struct {
* Val int
* Next *ListNode
* }
*/
func hasCycle(head *ListNode) bool {
//var Node *ListNode=&ListNode{Next:head}
slow,fast:=head,head
for fast!=nil&&fast.Next!=nil{
slow=slow.Next
fast=fast.Next.Next
if slow==fast{
return true
}
}
return false
}
560. 和为K的子数组

解题思路:
利用mapNum数组记录 nums[0]-nums[i]的和,再用mapNum[j]-mapNum[i]来计算nums[i]-nums[j]的子数组和
- 第一遍计算mapNum时候有可能==k
- 计算nums[i]-nums[j]的子数组和==k
func subarraySum(nums []int, k int) int {
length:=len(nums)
mapNum:=make([]int,length+10)
sum:=0
knum:=0
for i:=0;i时间复杂度较高,n平方
142. 环形链表 II

解题思路:
判环后得到的相遇点P和环链表的头结点q,p++和q++,他们相遇的点就是出入环的结点
/**
* Definition for singly-linked list.
* type ListNode struct {
* Val int
* Next *ListNode
* }
*/
func detectCycle(head *ListNode) *ListNode {
first:=hasCycle(head)
if first==nil{
return nil
}
for head!=first{
head=head.Next
first=first.Next
}
return first
}
func hasCycle(head *ListNode) *ListNode {
//var Node *ListNode=&ListNode{Next:head}
slow,fast:=head,head
for fast!=nil&&fast.Next!=nil{
slow=slow.Next
fast=fast.Next.Next
if slow==fast{
return slow
}
}
return nil
}
215. 数组中的第K个最大元素

直接用go 自带的sort.Slice 排序后取第K个最大,试了用快排的思想去求解,时间反而慢了5倍

用sort.Slice
func findKthLargest(nums []int, k int) int {
sort.Slice(nums,func(i,j int)bool{
return nums[i]>nums[j]
})
return nums[k-1]
}
用快排思想
func findKthLargest(nums []int, k int) int {
left:=0
right:=len(nums)-1
for{
index:=quickFind(nums,left,right)
if index==(k-1){
return nums[k-1]
}else if index>(k-1){
right=index
}else{
left=index+1
}
}
}
func quickFind(nums []int,left,right int) int{
flag:=nums[left]
l:=left+1
r:=right
for l<=r{
if nums[l]flag{
nums[l],nums[r]=nums[r],nums[l]
l++
r--
}
if nums[l]>=flag{
l++
}
if nums[r]<=flag{
r--
}
}
nums[left],nums[r]=nums[r],nums[left]
return r
}
238. 除自身以外数组的乘积

第一种解法:
用两个数组,一个为顺序相乘的积[1,2,6,24] 另一个为逆序相乘的积[24,24,12,4]。然后逆序那个作为最后的结果数组(不再申请额外的)result[i]=nums[i-1]*result[i+1]。
func productExceptSelf(nums []int) []int {
var result []int
result=make([]int,len(nums))
tmp:=1
for j:=(len(nums)-1);j>=0;j--{
tmp*=nums[j]
result[j]=tmp
}
tmp=1
for i:=0;i但是时间超时了,应该省去计算一部分计算顺序和逆序的时间,直接在其中计算得到结果数组
第二种解法
遍历nums,在遍历的过程中将对应元素累乘,得到i位置的左边的所有元素的累乘
1 2 3 4
1 1 2 6
反向遍历nums,得到i位置的所有元素的右乘
1 2 3 4
24 12 8 6
再将两个结果相乘即可
func productExceptSelf(nums []int) []int {
left := 1
right := 1
result := make([]int, len(nums))
// 左积
for i := 0; i < len(nums); i++ {
result[i] = left
left *= nums[i]
}
// 右积
for i := len(nums) - 1; i >= 0; i-- {
result[i] *= right
right *= nums[i]
}
return result
}
146. LRU缓存机制
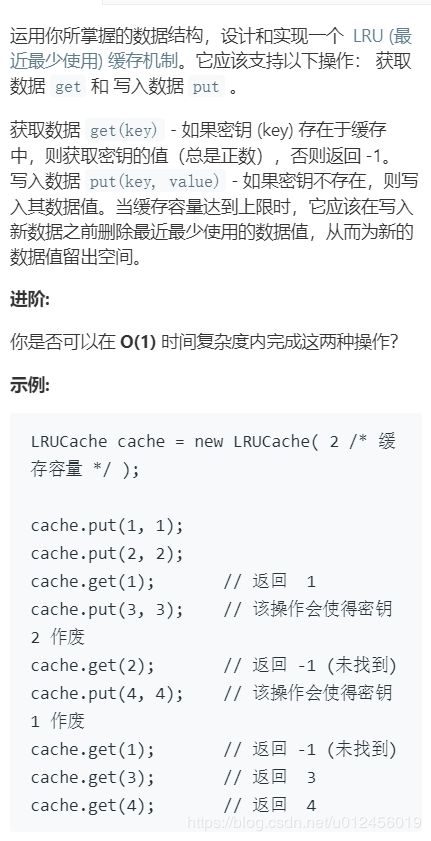
考Go的数据结构知识
主要用到双链表+map的组合
双链表存储key,value
用map来快速找到某个节点(空间换时间)
也可以不用map,节省空间牺牲时间
type Node struct{
val int
key int
pre *Node
next *Node
}
type LRUCache struct {
head *Node
tail *Node
length int
hash map[int]*Node
}
func Constructor(capacity int) LRUCache {
head:=&Node{val:-1,key:-1,pre:nil,next:nil}
tail:=&Node{val:-1,key:-1,pre:nil,next:nil}
head.next=tail
tail.pre=head
hash:=make(map[int]*Node,capacity)
cache:=LRUCache{head,tail,capacity,hash}
return cache
}
func (this *LRUCache)remove(node *Node){
node.pre.next=node.next
node.next.pre=node.pre
}
func (this *LRUCache)insert(node *Node){
t :=this.tail
node .pre=t.pre
t .pre.next=node
node.next=t
t .pre=node
}
func (this *LRUCache) Get(key int) int {
if val,ok:=this.hash[key];ok{
this.remove(val)
this.insert(val)
return val.val
}else{
return -1
}
}
func (this *LRUCache) Put(key int, value int) {
if val,ok:=this.hash[key];ok{
this.remove(val)
this.insert(val)
val.val=value
}else{
if len(this.hash)>=this.length{
h:=this.head.next
this.remove(h)
delete(this.hash,h.key)
}
node:=&Node{key:key,val:value,pre:nil,next:nil}
this.hash[key]=node
this.insert(node)
}
}
/**
* Your LRUCache object will be instantiated and called as such:
* obj := Constructor(capacity);
* param_1 := obj.Get(key);
* obj.Put(key,value);
*/
2. 两数相加
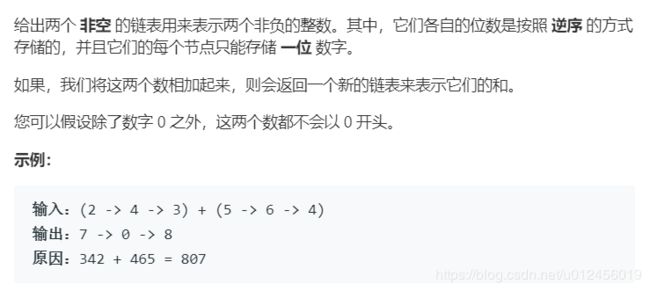
解题思路:
其实就是链表合并,先计算两个链表的长度,然后再根据长度进行错位的相加,要注意进位和进位后新增结点的情况
/**
* Definition for singly-linked list.
* type ListNode struct {
* Val int
* Next *ListNode
* }
*/
func addTwoNumbers(l1 *ListNode, l2 *ListNode) *ListNode {
head1:=l1
head2:=l2
length1:=0
length2:=0
for head1.Next!=nil{
length1++
head1=head1.Next
}
for head2.Next!=nil{
length2++
head2=head2.Next
}
head1=l1
head2=l2
if length10{
temp=head1.Val+head2.Val
if flag==1{
temp++
}
if temp>=10{
head1.Val=(temp%10)
flag=1
}else{
head1.Val=temp
flag=0
}
length2--
head1=head1.Next
head2=head2.Next
}
if head2!=nil{
temp=head1.Val+head2.Val
head2=head2.Next
}else{
temp=head1.Val
}
if flag==1{
temp++
}
if temp>=10{
head1.Val=(temp%10)
flag=1
if head1.Next==nil{
head1.Next=&ListNode{1,nil}
flag=0
}
head1=head1.Next
}else{
head1.Val=temp
flag=0
}
for flag==1{
if head1==nil{
head1=&ListNode{1,nil}
flag=0
}else{
temp=head1.Val+1
if temp>=10{
head1.Val=(temp%10)
flag=1
if head1.Next==nil{
head1.Next=&ListNode{1,nil}
flag=0
}
head1=head1.Next
}else{
head1.Val=temp
flag=0
}
}
}
return l1
}
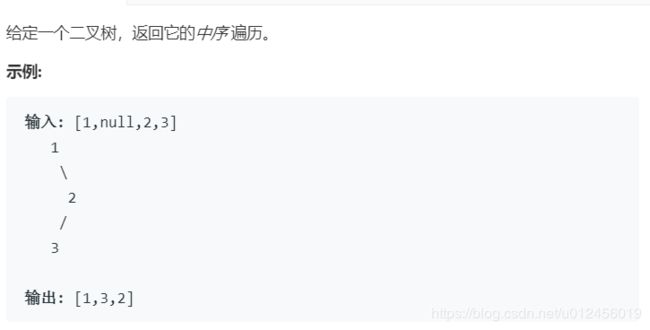
94. 二叉树的中序遍历
题目
/**
* Definition for a binary tree node.
* type TreeNode struct {
* Val int
* Left *TreeNode
* Right *TreeNode
* }
*/
var result []int;
func inorderTraversal(root *TreeNode) []int {
result=make([]int,0)
if root==nil{
return result
}
see(root)
return result
}
func see(root *TreeNode){
if root.Left!=nil{
see(root.Left)
}
result=append(result,root.Val)
if root.Right!=nil{
see(root.Right)
}
}
102. 二叉树的层次遍历

解题思路:
利用队列的先进先出特性,最开始将3入队,然后依次出队列,每次出队列后都将该节点的左右节点入队列,直到该层的所有节点都出队列并且将他们的左右子节点都入队后,循环。
/**
* Definition for a binary tree node.
* type TreeNode struct {
* Val int
* Left *TreeNode
* Right *TreeNode
* }
*/
func levelOrder(root *TreeNode) [][]int {
var result [][]int
result=make([][]int,0)
for i:=0;i<len(result);i++{
result[i]=make([]int,0)
}
if root==nil{
return result
}
list:=list.New()
list.PushFront(root)
for list.Len()>0{
var resultrow []int;
resultrow=make([]int,0)
length:=list.Len()
for i:=0;i<length;i++{
node:=list.Remove(list.Back()).(*TreeNode)
resultrow=append(resultrow,node.Val)
if node.Left!=nil{
list.PushFront(node.Left)
}
if node.Right!=nil{
list.PushFront(node.Right)
}
}
result=append(result,resultrow)
}
return result
}
105. 从前序与中序遍历序列构造二叉树
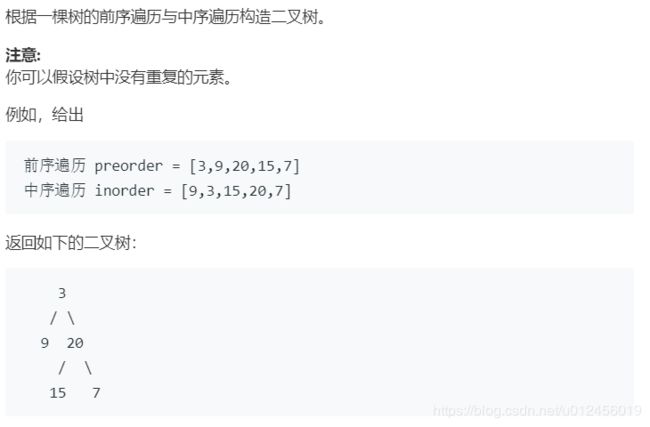
解题思路:
root[左子树][右子树]
[左子树]root[右子树]
根据上图的大概的分布,采用递归的方式,首先在先序遍历中第一个为root根节点然后通过这个根节点在中序遍历中区分左子树和右子树列表,然后递归两个遍历,将每个节点加入到二叉树结构中去
/**
* Definition for a binary tree node.
* type TreeNode struct {
* Val int
* Left *TreeNode
* Right *TreeNode
* }
*/
func buildTree(preorder []int, inorder []int) *TreeNode {
if preorder==nil||inorder==nil||len(preorder)<1||len(preorder)!=len(inorder){
return nil
}
var root *TreeNode=&TreeNode{}
root=build(preorder,inorder,0,len(preorder)-1,0,len(inorder)-1)
return root
}
func build(preorder []int,inorder []int,prestart int,preend int ,instart int,inend int) *TreeNode{
if (prestart>preend)||(instart>inend){
return nil
}
var root *TreeNode=&TreeNode{}
root.Val=preorder[prestart]
var i=0
for i=instart;i<=inend;i++{ //i从instart开始,所以滑动长度为i-instart
if preorder[prestart]==inorder[i]{
break
}
}
if i==(inend+1){
return nil
}
root.Left=build(preorder,inorder,prestart+1,prestart+i-instart,instart,i-1)
root.Right=build(preorder,inorder,prestart+i-instart+1,preend,i+1,inend)
return root
}
114. 二叉树展开为链表
给定一个二叉树,原地将它展开为链表。
例如,给定二叉树
1
/ \
2 5
/ \ \
3 4 6
将其展开为:
1
\
2
\
3
\
4
\
5
\
6
解题思路:
可以看出是按照先序遍历顺序进行展开的
采用递归的方式,可以先遍历到最左的子节点然后将此左子节点断开作为其父节点的右节点,再将原来的右节点拼接到现在的右节点后面。
注意两点:
1、将左节点作为右节点的时候备份右节点
2、将左节点拼接到父节点的右节点后将父节点原来的左节点置空(nil)
/**
* Definition for a binary tree node.
* type TreeNode struct {
* Val int
* Left *TreeNode
* Right *TreeNode
* }
*/
func flatten(root *TreeNode) {
if root==nil{
return
}
if root.Left!=nil{
flatten(root.Left)
}
if root.Right!=nil{
flatten(root.Right)
}
var tmp *TreeNode=root.Right
root.Right=root.Left
root.Left=nil
for root.Right!=nil{
root=root.Right
}
root.Right=tmp
}
输入带空格字符串
inputReader := bufio.NewReader(os.Stdin)
str, err := inputReader.ReadString('\n')
if err != nil {
return
}
