人脸关键点检测PFLD论文解读
最近做了一个人脸关键点相关的项目,选择了PFLD方案,在这里顺便写一下论文的学习笔记。
1. Introduction
论文地址:https://arxiv.org/pdf/1902.10859.pdf
人脸关键点检测论文《 PFLD: A Practical Facial Landmark Detector》 在2019年2月提出的,是由天津大学、武汉大学、腾讯AI Lab等共同提出。该算法在精度、效率、模型压缩方面都有较大的优势,部署在手机端是很适合的。
首先作者介绍人脸关键点检测在实用性上存在多方面的挑战,比如在大姿态、夸张表情、极端光照及遮挡的条件下的关键点检测。对这些情况总结为四个方面的挑战:
Challenge #1 - Local Variation.
在夸张表情及极端光照的下,人脸的部分区域特征就会发生较大偏差甚至消失的情况。
Challenge #2 - Global Variation.
考虑到拍照时不同的人脸姿态及使用不同的拍摄设备得到图像的质量方面,存在成像不清晰、颜色偏差等,这对关键点检测也有较大的影响。
Challenge #3 - Data Imbalance.
数据不平衡方面,训练的样本存在数据类别不平衡,这也是比较重要的问题。
Challenge #4 - Model Efficiency.
模型效率,比如使用我们的手机端进行跑模型,也要考虑模型的大小和计算速度的问题。
针对以上的这些挑战,作者就提出了解决方案,即PFLD算法。
2. Methodology
2.1. loss 函数
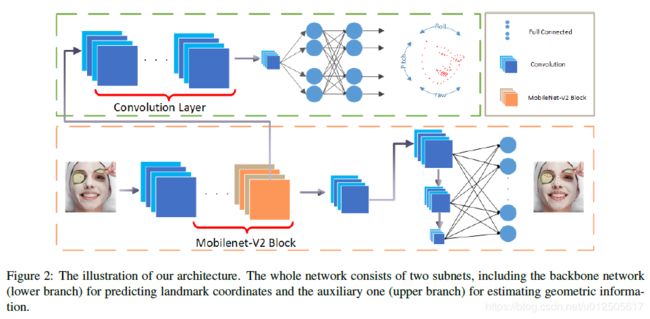
整个网络的结构如下图所示,分为主网络(橙色框)和辅助网络(绿色框),主干网络backbone是用来预测关键点,而辅助网络用来预测人脸姿态,使关键点位置更加稳定和鲁棒性更好。
loss函数的设计:
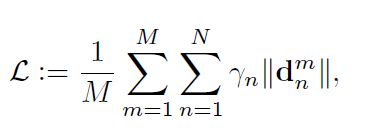
最原始的loss函数如上面的定义,其中M代表样本数,N代表关键点数,![]() 担任权重的角色,
担任权重的角色,![]() 关键点的距离(L1距离或者L2距离)。
关键点的距离(L1距离或者L2距离)。
作者考虑到数据集的各个类别不均衡,所以对loss函数进行重新设计如下:
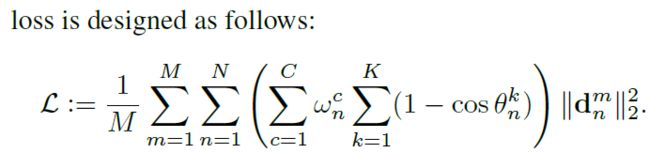
式中的 ![]() 表示最终的权重,相当于公式1中的
表示最终的权重,相当于公式1中的![]() 。
。
![]() (K=3)表示真实的人脸姿态和估算姿态之间的差值,用欧拉角来表示,即 yaw, pitch, roll。可以看到随着误差角度
(K=3)表示真实的人脸姿态和估算姿态之间的差值,用欧拉角来表示,即 yaw, pitch, roll。可以看到随着误差角度 的增大,惩罚也会相应增大。
的增大,惩罚也会相应增大。
C为人脸的属性分类,共分为6类:profile-face, frontal-face, head-up, head-down, expression, and occlusion。
2.2. Backbone Network(主网络)
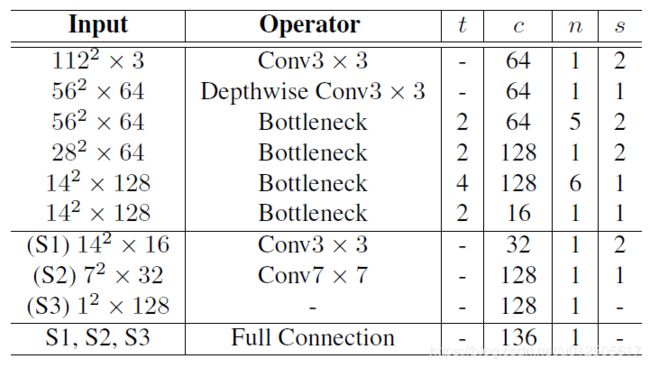
主干网络主要用于提取特征和预测关键点。结构如上图所示,先采用了mobilenet v2 的多个bottleneck 层, 然后再采用multi-scale,再通过FC层把多个尺度的特征连接起来。(更多有关于bottleneck的知识,请读者去阅读mobilenet v2论文)
2.3. Auxiliary Network(辅助网络)
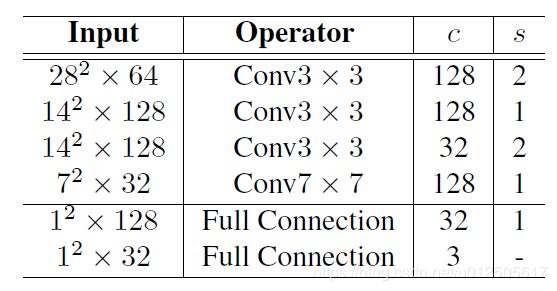
辅助网络用于预测人脸的姿态的欧拉角,让预测的关键点位置更加稳定和鲁棒。在估算人脸姿态时,ground-truth的姿态角度通过已知的关键点来估算。
2.4. Implementation Details
超参数:
input shape: 112x112
batch size :256
optimizer:Adam
weight decay:
learning rate:
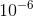

数据增强策略:
论文中使用300W挑战赛数据集,其中3148张图片用来训练,689张用来测试。在制作300W数据集时,对每张人脸图片进行翻转,在-30°~30°之前每隔5°进行一次旋转,在每张图片上随机遮挡人脸区域的20%
3. Experimental Evaluation
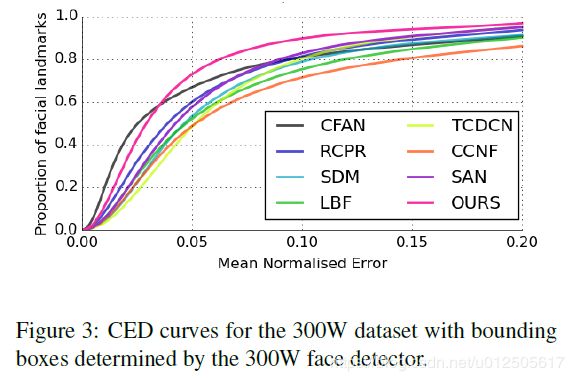
CED(cumulative error distribution)曲线如图所示:

上图是模型的大小与速度方面,可以看到PFLD模型很小,但运行速度非常快,在ARM 845处理器上达到140 fps。表中C代表 CPU i7-6700K,G表示GPU GTX 1080Ti ,A表示 Qualcomm ARM 845 处理器。PFLD 0.25X 和 1X 分别表示mobilenet 网络中深度可分离卷积的宽度乘法因子(width Multiplier)。
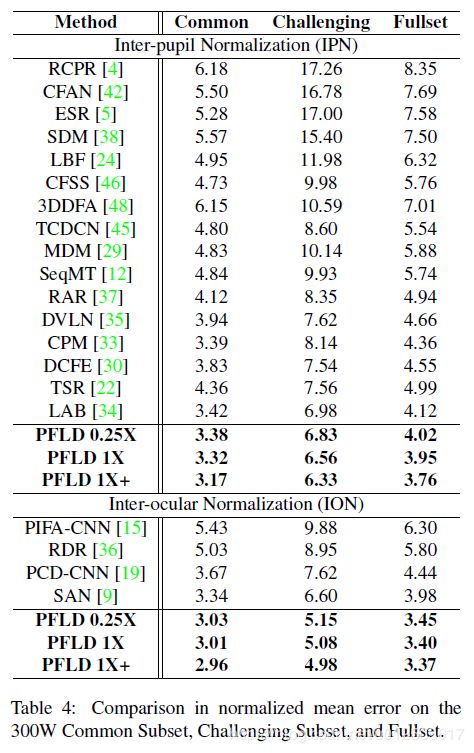
如上图,PFLD模型精度,在300W数据集上采用IPN/ IOP两种评价标准的精度对比结果,可以看到在精度方面依然是最棒的。
部分效果图如下:

看效果还是非常好的,自己也对该论文进行了复现,目前在精度方面也取得不错的结果,速度方面离论文还有一定差距,后面有空了再改善。
References:
[1] PFLD: A Practical Facial Landmark Detector
[2] PFLD:简单、快速、超高精度人脸特征点检测算法