图算法之节点分类Node Classification
前言
在图谱当中,有一项很重要的任务,节点分类。该任务通常是给定图中某些节点对应的类别,从而预测出生于没有标签的节点属于哪一个类别,该任务也被称为半监督节点分类。
本文主要介绍三种图算法来解决节点分类问题。
图中的相互关系
在图谱中,存在着两种重要的相互关系
- homophily亲和性(我自己的翻译成,不一定准确),具体意思就是指人以群分物以类聚,例如在社交网络中,喜欢蔡徐坤的人通常都会有同样的喜好。
- influence影响性,某节点的行为可能会影响到和他有关系的节点行为,例如有一天你吃起了螺蛳粉,结果你身边的人都跟着你吃了起来。
那么,如何利用这些关系来预测节点的标签呢?
通常,相似的节点都会紧密相连或者直接相连,而相连的节点大概率会有相同的标签。例如非法网站,通常都会有其它非法网站的链接。因此,我们预测节点类别时,通常会注意以下三个方面信息:
- 目标节点特征
- 目标节点的邻居节点的labels
- 目标节点的邻居节点的特征
有了以上的概念,我们就具体来看下有哪些节点分类的方法。注意,以下算法都遵循马尔科夫假设,即节点i的标签只是其邻居节点的标签有关系。
Probabilistic Relational Classifier概率关系分类器
基本思想:某节点的label是其邻居节点的对应的label概率的均值。
首先初始化已经存在label的节点标签概率,正例是1,负例是0,对于没有标签的全部设置为0.5,然后对所有没有标签的节点进行概率更新,直到收敛或者得到最大的迭代次数。(感觉是一个马尔科夫过程)
P ( Y i = c ) = 1 ∑ ( i , j ) ∈ E W ( i , j ) ∑ ( i , j ) ∈ E W ( i , j ) P ( Y j = c ) P(Y_i=c)=\frac{1}{\sum_{(i,j) \in E}W(i,j)}\sum_{(i,j)\in E}W(i,j)P(Y_j=c) P(Yi=c)=∑(i,j)∈EW(i,j)1(i,j)∈E∑W(i,j)P(Yj=c)
其中 W ( i , j ) W(i,j) W(i,j)表示的是节点 i i i与节点 j j j的边的权重。
接下来我们来看一个具体的例子:
初始化所有节点的概率值,没有标签的节点采用均匀分布设置为0.5
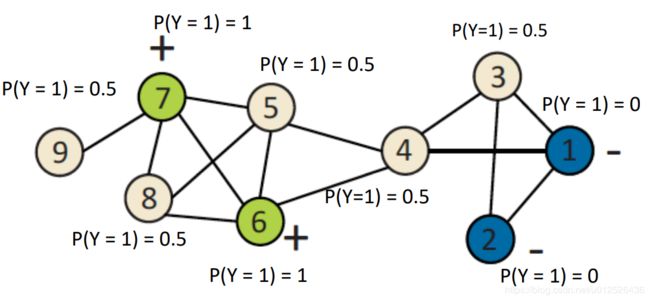
对节点3进行新的概率更新
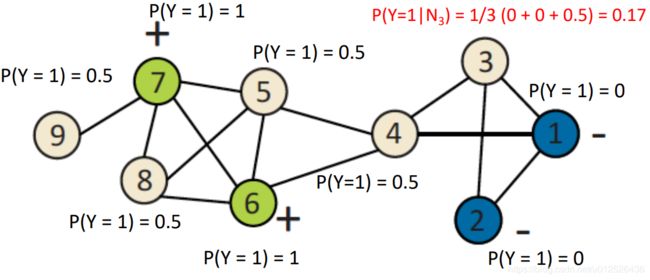
对节点4进行概率更新
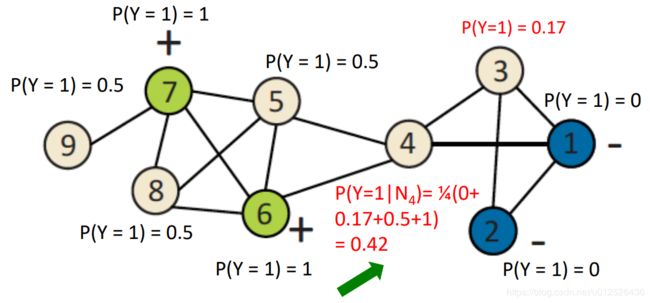
迭代一轮
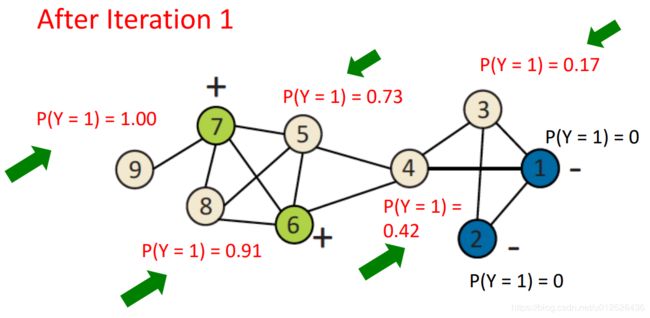
迭代五轮
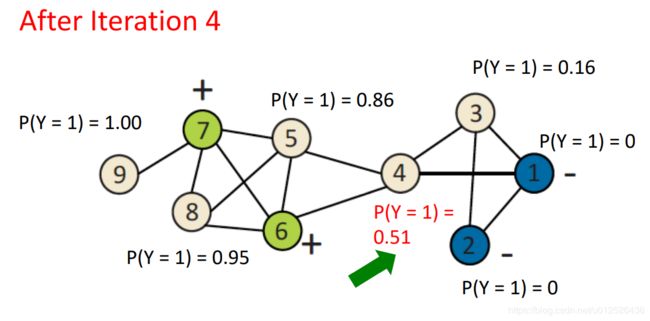
五轮迭代后,所有的概率值都趋于稳定,此时节点5、8、9对应的概率值大于0.5,设置为正例,节点3概率值小于0.5设置为负例,节点4概率值趋于0.5则正负都有可能。
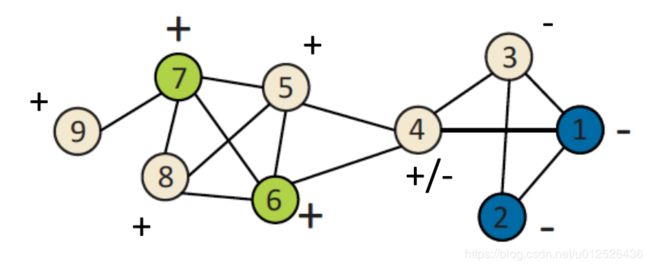
缺点:
- 收敛难以得到保障(节点4)
- 没有利用节点的特征信息
Iterative Classification迭代分类
Iterative classification实际上就是考虑关系的同时也考虑节点的的属性,主要包括三点
- 对于节点 i i i,创建一个向量 a i a_i ai
- 使用 a i a_i ai来训练分类器(例如LR、SVM等)
- 如果一个节点有多个邻居节点,做一个聚合操作,计算其数量,众数,比例,均值,是否存在邻居等。
训练过程和上一个算法类似,不停的迭代更新每一个节点的label,注意因为节点的改变,对应的节点的向量 a i a_i ai也需要更新。知道label稳定,或者达到最大的迭代次数,训练结束。
缺点:
该算法的收敛依旧没有得到保证。
Belief Propagation信念传播
Belief Propagation信念传播简称BP,是一种在图中通过计算条件概率的形式来表示消息传递的算法,可以理解为马尔科夫随机场,该算法采用了动态规划。
在开始之前,我们先了解几个概念:
- message:message表示的是从节点 i i i到节点 j j j传递的信息,通常表示为 m i → j ( X j ) m_{i\to j}(X_j) mi→j(Xj),message和概率很类型,非负但是其和不是1,如果 m i → j ( X j ) m_{i\to j}(X_j) mi→j(Xj)越高,说明边缘概率 P ( X j ) P(X_j) P(Xj)的值越高,通常message的初始值会设置为1
- belief:边缘概率即被称为belief
BP算法实际上就是不停的迭代更新message直到收敛再计算belief。看个具体的例子,如下图,我们想知道 k k k到底传递给了 j j j什么信息。
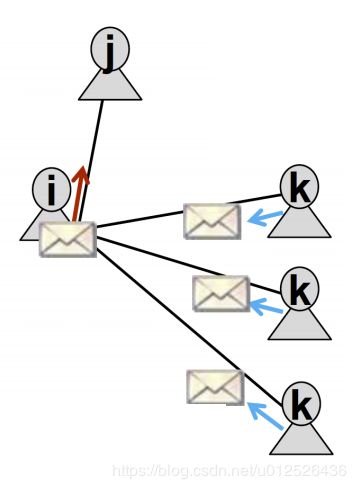
m i → j ( Y j ) m_{i \to j}(Y_j) mi→j(Yj)即上文提到的message,可以理解为是在计算整个图的联合概率,所以有如下公式:
m i → j ( Y j ) = α ∑ Y i ∈ L ψ ( Y i , Y j ) ϕ i ( Y i ) ∏ k ∈ N i ∖ j m k → i ( Y i ) m_{i \to j}(Y_j)=\alpha \sum_{Y_i \in \mathcal L} \psi(Y_i,Y_j) \phi_i(Y_i) \prod_{k \in N_i \setminus j}m_{k \to i(Y_i)} mi→j(Yj)=αYi∈L∑ψ(Yi,Yj)ϕi(Yi)k∈Ni∖j∏mk→i(Yi)
解释一下这个公式,
-
∑ Y i ∈ L \sum_{Y_i \in \mathcal L} ∑Yi∈L表示的是对所有状态求和,
-
ψ ( Y i , Y j ) \psi(Y_i,Y_j) ψ(Yi,Yj)是状态转移概率,表示的是已知节点 j j j的邻居节点 i i i的状态 Y i Y_i Yi, j j j节点状态为 Y j Y_j Yj的概率,可以理解为条件概率
-
ϕ i ( Y i ) \phi_i(Y_i) ϕi(Yi)表示的是节点 i i i状态为 Y i Y_i Yi的概率,可以理解为先验概率
-
L \mathcal L L表示的是所有状态的集合
上图只是一个比较简单的图,如果图比较复杂,那么就随机在图中选择一个节点作为根节点,然后从叶节点开始传递消息,重复这个过程n次,直到模型收敛。注意,每次消息传递的过程message的值都会保存下来,这就是算法中的动态规划。
因为每个结点都会收到来⾃所有相邻结点的信息,因此就可以计算每个节点的边缘概率即belief
b i ( Y i ) = α ϕ i ( Y i ) ∏ j ∈ N i m i → j ( Y i ) , ∀ Y i ∈ L b_i(Y_i)=\alpha \phi_i(Y_i) \prod_{j \in N_i }m_{i \to j(Y_i)},\forall Y_i \in \mathcal L bi(Yi)=αϕi(Yi)j∈Ni∏mi→j(Yi),∀Yi∈L
边缘概率最高的对应的类别就是当前节点的所属类别。
BP可以并行的进行计算,所以效率很高,但是该算法依旧没办法完全保证模型收敛,特别是有环的时候。
总结
本文介绍的节点分类方法都是基于传统的图算法,目前也有很多基于Node Vector、GNN的方法来做node classification,相关的博文我会尽快分享给大家,敬请期待。
References
cs224w 6. Message Passing and Node Classification