Selenium+Python爬取房天下二手房数据
注意!注意!注意!本文中大图较多,建议使用PC查看,手机端效果较差!
在上篇“Selenuim+Python网络爬虫基础讲解”博文中讲了一些Selenium的基础知识,接下来就要开始实战了。
其实使用Selenium爬取网页的思路很简单,首先梳理一下爬取流程。
打开二手房珠海地区首页http://zh.esf.fang.com/,首先会出现一个屏蔽页,我们需要点击“我知道了”,才能继续点击其他内容。


在上面的页面中,我们可以看到在区域页签下,有香洲、金湾、斗门等大区,点击香洲大区页签后出现翠微、凤凰北等子区。继续点击翠微后会出现翠微的二手房相关信息。
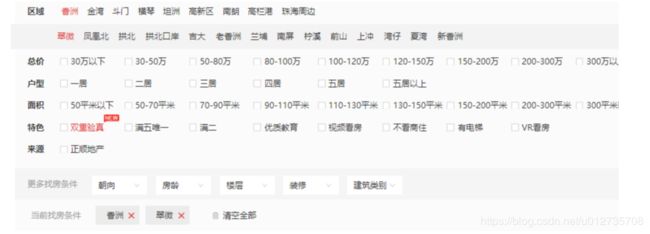

所以我们的思路就是先获取大区列表,然后点击大区,获取该大区下的子区 列表,逐一按子区爬取就行了。但是我们可以看到当前显示的房屋信息不全,需要我们点进去查看详细信息。详细信息中需要爬取的有以下被框信息。




爬取完以上信息后,需要关闭当前房屋详细信息页签,继续按房屋信息列表爬取。
遍历完当前页的房屋信息后,就需要跳转到下一页。

我们可以看到,这里最方便的页面切换方式就是通过点击“下一页”按钮,到最后一页的时候就没有“下一页”按钮,我们切换子区页签,进入下一个子区继续按上述方式爬取就成。
Go~就按上面的分析开始实现!
每一步基本上都有注释。
from selenium import webdriver
from selenium.webdriver.support.wait import WebDriverWait
from selenium.webdriver.common.by import By
from selenium.webdriver.support import expected_conditions as EC
import os
import time
import pandas as pd
browser=webdriver.Chrome() #设置浏览器
browser.maximize_window() #浏览器窗口最大化
wait=WebDriverWait(browser,20) #设置显示等待
list_dq=[] #已爬取大区列表,为了防止中断后重新爬取,需手动添加
list_zq=[] #已爬取子区列表,为了防止中断后重新爬取,需手动添加
#需要获取的信息列表
columns1=['价格','户型','建筑面积','单价','朝向','楼层','总楼层','装修'] #8
columns2=['小区','区域','子区域','小学'] #4
columns3=['建筑年代','有无电梯','产权性质','建筑类别','住宅类别','建筑结构','挂牌时间'] #7
columns4=['参考价格'] #1
columns5=['物业类型','物业费用','建筑类型','产权年限','绿 化 率','容 积 率','人车分流','总楼栋数','总 户 数'] #9
columns_all=columns1+columns2+columns3+columns4+columns5
#保存爬取数据
def save_file(title,data_div):
path='E:/fcwdata1'
if os.path.exists(path):
pass
else:
os.mkdir(path)
path_file_name =str(path +'/'+ title + '.csv')
file=pd.DataFrame(data_div,columns=columns_all)
file.to_csv(path_file_name,index=False)
#获取房屋信息
def get_houseInfo():
#详细信息列表
f_list=list()
#判断元素是否存在
def isElementExist(xpath):
flag=True
try:
browser.find_element_by_xpath(xpath)
return flag
except:
flag=False
return flag
#获取xpath中信息
def get_info(xpath):
if isElementExist(xpath):
f_list.append(wait.until(EC.presence_of_element_located((By.XPATH,xpath))).text)
else:
f_list.append(-1)
#columns1和columns2中的信息的xpath路径
f1=pd.Series()
f1['price']='/html/body/div[5]/div[1]/div[4]/div[1]/div[1]/div[1]'
f1['house_type']='/html/body/div[5]/div[1]/div[4]/div[2]/div[1]/div[1]'
f1['area']='/html/body/div[5]/div[1]/div[4]/div[2]/div[2]/div[1]'
f1['per_price']='/html/body/div[5]/div[1]/div[4]/div[2]/div[3]/div[1]'
f1['direction']='/html/body/div[5]/div[1]/div[4]/div[3]/div[1]/div[1]'
f1['floor']='/html/body/div[5]/div[1]/div[4]/div[3]/div[2]/div[1]'
f1['floor_sum']='/html/body/div[5]/div[1]/div[4]/div[3]/div[2]/div[2]'
f1['decoration']='/html/body/div[5]/div[1]/div[4]/div[3]/div[3]/div[1]'
f1['plot']='//*[@id="kesfsfbxq_A01_01_05"]'
f1['region1']='//*[@id="kesfsfbxq_C03_07"]'
f1['region2']='//*[@id="kesfsfbxq_C03_08"]'
f1['school']='//*[@id="kesfsfbxq_C03_09"]'
#获取columns1和columns2中信息
for i in range(len(f1)):
get_info(f1[i])
#获取coulumns3中信息
fyInfo=browser.find_element_by_class_name('fydes-item').find_elements_by_class_name('text-item')
dict_fyInfo=dict() #创建字典
for info_i in range(len(fyInfo)):
dict_fyInfo[fyInfo[info_i].text.split('\n')[0]]=fyInfo[info_i].text.split('\n')[1] #以字典形式保存
for name in columns3:
if name in dict_fyInfo.keys():
f_list.append(dict_fyInfo[name])
else:
f_list.append(-1) #缺失信息用-1填充
#获取columns4中信息
try:
ave_price=browser.find_element_by_class_name('topt').find_element_by_class_name('rcont').text
f_list.append(ave_price)
except:
f_list.append(-1)
#获取columns5中信息
xqInfo=browser.xqInfo=browser.find_element_by_class_name('pt30').find_elements_by_class_name('clearfix')[4].find_elements_by_class_name('text-item')
dict_xqInfo=dict()
for info_i in range(len(xqInfo)):
dict_xqInfo[xqInfo[info_i].text.split('\n')[0]]=xqInfo[info_i].text.split('\n')[1]
for name in columns5:
if name in dict_xqInfo.keys():
f_list.append(dict_xqInfo[name])
else:
f_list.append(-1)
return f_list
print('开始测试')
page_allinfo=[] #存储当前页所有信息
browser.get('http://zh.esf.fang.com/') #登入主页
wait.until(EC.presence_of_element_located((By.XPATH,'//*[@id="closemengceng"]'))).click() #点击屏蔽页上的我知道了
diqu = wait.until(EC.presence_of_element_located((By.XPATH, '//*[@id="kesfqbfylb_A01_03_01"]/ul'))) #找到大区
quyus=diqu.find_elements_by_xpath('.//li') #将大区内的所有地区赋值给quyus
quyus_num=len(quyus) #统计大区数量
for i in range(quyus_num): #逐一遍历每个大区
diqu = wait.until(EC.presence_of_all_elements_located((By.XPATH, '//*[@id="kesfqbfylb_A01_03_01"]/ul/li'))) #将大区内的所有地区赋值给quyus
daqu_node=diqu[i].find_element_by_xpath('.//a') #定位到要爬取的大区
daqu_node_name=daqu_node.text
print('大区',daqu_node_name) #输出当前大区名
if daqu_node_name in list_dq: #如果当前大区的所有子区已经爬完,则手动添加至list_dq列表,直接略过该大区
continue
daqu_node.click() #点击大区名称,显示子区列表
ziquyu=wait.until(EC.presence_of_all_elements_located((By.XPATH, '//*[@id="ri010"]/div[1]/ul/li[2]/ul/li'))) #将大区内的所有子区赋值给ziquyu
ziquyu_num=len(ziquyu) #统计当前大区下子区的数量
for j in range(ziquyu_num): #逐一遍历当前大区下的每个子区
ziquyu=wait.until(EC.presence_of_all_elements_located((By.XPATH, '//*[@id="ri010"]/div[1]/ul/li[2]/ul/li'))) #获取子区地区,将子区内的所有地区名称赋值给ziquyu
ziquyu_node=ziquyu[j].find_element_by_xpath('.//a') #定位到要爬取的子区
ziquyu_node_name=ziquyu_node.text
print('子区域',ziquyu_node_name) #输出当前子区名
ziquyu_node.click() #点击当前子区
if ziquyu_node_name in list_zq: #如果当前子区已经爬完,则手动添加至list_zq列表,直接略过该子区
continue
try: #试图搜寻页码块
page_list_end=wait.until(EC.presence_of_all_elements_located((By.XPATH, '//*[@id="list_D10_15"]/p')))
except: #有时网速不好造成搜寻不到,此时尝试刷新页面重新爬取
browser.refresh() #刷新页面
page_list_end=wait.until(EC.presence_of_all_elements_located((By.XPATH, '//*[@id="list_D10_15"]/p')))
for page_but in page_list_end: #查看子区信息共多少页
if page_but.text[0] in '共':
endStr=page_but.text
totalNum=int(endStr[1:len(endStr)-1]) #截取总页数,eg:共100页,totalNum则为100
for k in range(totalNum): #逐一遍历每页
if ziquyu_node_name=='': #如果当前子区前面n页被爬取,则跳过 eg:if ziquyu_node_name=='新香洲' and k in range(15):表示新香洲的前15页已经爬取,直接跳过
pass
else:
page_allinfo=[]
handle = browser.current_window_handle #记录当前页的句柄
data_div=browser.find_element_by_css_selector("[class='shop_list shop_list_4']").find_elements_by_css_selector('[dataflag="bg"]') #搜寻当前页下,所有房屋元素
for house_info_i in range(len(data_div)): #遍历当前页房屋元素
try: #尝试爬取房屋详细信息
data_div[house_info_i].find_element_by_class_name('clearfix').click() #点击房屋标题,进入房屋详细信息页
handles = browser.window_handles #记录当前页的句柄
for newhandle in handles:
if newhandle!=handle:
browser.switch_to_window(newhandle) #找到打开的新页签,并跳转至新页签
page_allinfo.append(get_houseInfo()) #爬取详细信息
browser.close() #关闭页签
browser.switch_to_window(handle) #跳转至房屋列表页签
break
except: #当网速不好的时候可能爬取不到,所有再重新爬取一遍
try:
browser.close()
browser.switch_to_window(handle)
time.sleep(5)
data_div[house_info_i].find_element_by_class_name('clearfix').click()
handles = browser.window_handles
for newhandle in handles:
if newhandle!=handle:
browser.switch_to_window(newhandle)
page_allinfo.append(get_houseInfo())
browser.close()
browser.switch_to_window(handle)
break
except: #有时候有些意外情况导致房屋详细信息页签没有关闭,所以关闭房屋详细信息页签并跳转至房屋列表页签
if len(handles)>1:
browser.close()
browser.switch_to_window(handle)
else: #实在爬取不到该房屋详细信息就跳过,因为网速确实不稳定,也不差那一两个房屋信息
pass
title=daqu_node_name+"-"+ziquyu_node_name+"-"+str(k+1) #以大区名+子区名+页码作为文件标题,eg:香洲-翠微-1
save_file(title,page_allinfo) #存储当前页信息
print(title)
try: #有时候当前页没有显示页码列表,所以无法点击下一页,所以没有显示的时候重新刷新一下
page_nodes=wait.until(EC.presence_of_element_located((By.XPATH,'//*[@id="list_D10_15"]'))).find_elements_by_tag_name('p')
except:
browser.refresh()
page_nodes=wait.until(EC.presence_of_element_located((By.XPATH,'//*[@id="list_D10_15"]'))).find_elements_by_tag_name('p')
for node in page_nodes:
if '下一页' in node.text:
next_node=node.find_element_by_xpath('.//a').click() #跳转至下一页
break
print('--------------------------')
嗯~大概就是这个样子!
这样我们会得到很多文件,如下图所示。

这么多文件不方便我们进行分析处理,所以我们需要将各文件进行合并,合并代码如下,
import pandas as pd
import glob
outputfile='f:/hebing.csv'
csv_list = glob.glob('F:/*.csv')
print(u'共发现%s个CSV文件'% len(csv_list))
print(u'正在处理............')
def hebing():
for inputfile in csv_list:
f=open(inputfile)
data=pd.read_csv(f)
data.to_csv(outputfile,mode='a',index=False,header=None)
print('完成合并')
def quchong(file):
df = pd.read_csv(file,header=0)
datalist = df.drop_duplicates()
datalist.to_csv(file)
print('完成去重')
if __name__ == '__main__':
hebing()
quchong(outputfile)合并好数据,我们看看爬到的数据是什么样子的,数据如下所示,

可以看到格式不是很标准,我们可以格式化处理一下数据,代码如下,
import pandas as pd
columns1=['价格','户型','建筑面积','单价','朝向','楼层','总楼层','装修'] #8
columns2=['小区','区域','子区域','小学'] #4
columns3=['建筑年代','有无电梯','产权性质','建筑类别','住宅类别','建筑结构','挂牌时间'] #7
columns4=['参考价格'] #1
columns5=['物业类型','物业费用','建筑类型','产权年限','绿 化 率','容 积 率','人车分流','总楼栋数','总 户 数'] #9
columns_all=columns1+columns2+columns3+columns4+columns5
data=pd.read_csv('e:/fcwdata/gen/hebing1.csv',names=columns_all)
data['户型'].replace('暂无','-1',inplace=True)
data['室']=''
data['厅']=''
data['卫']=''
for i in range(len(data)):
data.loc[i,'价格']=data.loc[i,'价格'].split('\r')[0]
if data.loc[i,'户型']=='-1':
data.loc[i,'室']='-1'
data.loc[i,'厅']='-1'
data.loc[i,'卫']='-1'
else:
data.loc[i,'室']=data.loc[i,'户型'].split('室')[0]
data.loc[i,'厅']=data.loc[i,'户型'].split('室')[1].split('厅')[0]
data.loc[i,'卫']=data.loc[i,'户型'].split('室')[1].split('厅')[1].split('卫')[0]
if data.loc[i,'建筑面积']!='-1':
data.loc[i,'建筑面积']= data.loc[i,'建筑面积'][:-2]
if data.loc[i,'单价']!='-1':
data.loc[i,'单价']= data.loc[i,'单价'][:-4]
data.loc[i,'总楼层']=data.loc[i,'总楼层'].split('共')[1].split('层')[0]
if data.loc[i,'建筑年代']!='-1':
data.loc[i,'建筑年代']=data.loc[i,'建筑年代'][:-1]
if data.loc[i,'有无电梯']=='有':
data.loc[i,'有无电梯']=1
if data.loc[i,'有无电梯']=='无':
data.loc[i,'有无电梯']=0
if data.loc[i,'参考价格']!='-1':
data.loc[i,'参考价格']= data.loc[i,'参考价格'][:-4]
if data.loc[i,'物业费用']=='暂无资料':
data.loc[i,'物业费用']='-1'
if data.loc[i,'物业费用']!='暂无资料':
data.loc[i,'物业费用']=data.loc[i,'物业费用'].split('元')[0]
data.loc[i,'产权年限']=data.loc[i,'产权年限'].split('年')[0]
data.loc[i,'绿 化 率']=data.loc[i,'绿 化 率'].split('%')[0]
data['产权性质'].replace('普通商品房','商品房',inplace=True)
data.fillna('-1',inplace=True)
data.to_csv('e:/fcwdata/gen/hebing1.csv')处理后的数据如下所示,

大功告成,可以用这些数据可以进行分析预测 ~