Envoy 源码分析(一) --------common
Envoy 源码分析(一) ——common
源码的目录结构在上一篇文章中已有说明:https://blog.csdn.net/u012778714/article/details/81041323
这里首先从公用目录common里的文件说起:
assert
主要提供了两个宏:
#define RELEASE_ASSERT(X, DETAILS)
#define PANIC(X) RELEASE_ASSERT 提供了release assert,弱断言失败则打印日志推出程序
PANIC 打印日志退出
JitteredBackOffStrategy
字面意思是颤抖退避算法的实现,主要提供了两个接口:
uint64_t nextBackOffMs() override;
void reset() override;nextBackOffMs 会从返回一个构造函数时传的区间内的随机数,且这个随机区间是不断向右扩大的,每次调用都会使随机数的右区间右移,直到等于构造时传的最大区间限制。
reset 会重置区间扩大的这一过程。
Base64
一个Base64的类提供了三个静态函数,实现Base64的编解码。
Base64Url类提供了对url编解码的函数。
两中编码方式的基础字符表有差异,而且非url得base64编码末尾会添加’=’字符。
block_memory_hash_set
定义了一个建立在连续内存上的HashMap,在构造函数时传递BlockMemoryHashSetOptions结构体定义了hash表桶的数量和总容量。
BlockMemoryHashSet(const BlockMemoryHashSetOptions& hash_set_options, bool init, uint8_t* memory,
const Stats::StatsOptions& stats_options)
: cells_(nullptr), control_(nullptr), slots_(nullptr), stats_options_(stats_options) {
mapMemorySegments(hash_set_options, memory);
if (init) {
initialize(hash_set_options);
} else if (!attach(hash_set_options)) {
throw EnvoyException("BlockMemoryHashSet: Incompatible memory block");
}
}构造函数中mapMemorySegments将成员变量格式在内存上,接着initialize初始化成员变量和hash表,或者将内存读出为一个hash表。
void mapMemorySegments(const BlockMemoryHashSetOptions& hash_set_options, uint8_t* memory) {
// Note that we are not examining or mutating memory here, just looking at the pointer,
// so we don't need to hold any locks.
cells_ = reinterpret_cast(memory); // First because Value may need to be aligned.
memory += cellOffset(hash_set_options.capacity, stats_options_);
control_ = reinterpret_cast(memory);
memory += sizeof(Control);
slots_ = reinterpret_cast(memory);
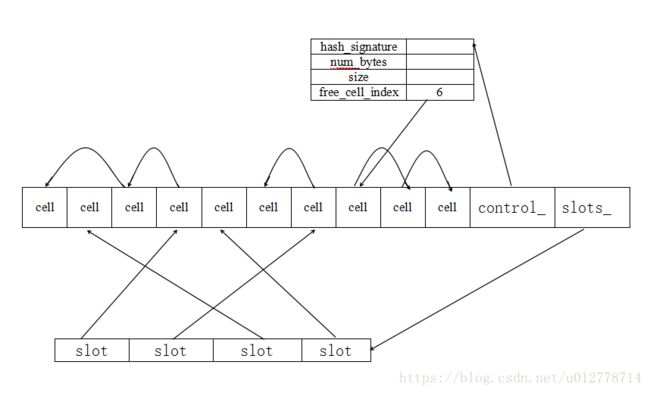
} 我们可以看下这个初始化函数,将hash表的成员变量格式化(格式化这个词可能有点不妥,实质是将内存的特定段强制转换为成员变量类型)到内存上。初始化完成之后类似于下图:

cells_的内存块长度是构造时总容量*字节对齐之后的sizeof(Cell),这里的三个指指针变量都指向所在内存段的起始位置。然后看下变量初始化过程:
void initialize(const BlockMemoryHashSetOptions& hash_set_options) {
//Control 初始化
//记录hash算法的字符序列
control_->hash_signature = Value::hash(signatureStringToHash());
control_->num_bytes = numBytes(hash_set_options, stats_options_);//占用总字节数
control_->hash_set_options = hash_set_options;//构造时的控制结构体
control_->size = 0;//已经存了的数量
control_->free_cell_index = 0;//空闲cell的索引
//将所有的桶(槽)都初始化为空的哨兵位
// Initialize all the slots;
for (uint32_t slot = 0; slot < hash_set_options.num_slots; ++slot) {
slots_[slot] = Sentinal;
}
//将cells_的内存初始化为一个单向链表,每个节点存储指向下个节点的索引。
// Initialize the free-cell list.
const uint32_t last_cell = hash_set_options.capacity - 1;
for (uint32_t cell_index = 0; cell_index < last_cell; ++cell_index) {
//getCell通过索引计算相对cells_指针偏移量取出内存段转化为cell
Cell& cell = getCell(cell_index);
cell.next_cell_index = cell_index + 1;
}
getCell(last_cell).next_cell_index = Sentinal;
}
//Control 结构体定义
struct Control {
BlockMemoryHashSetOptions hash_set_options; // Options established at map construction time.
uint64_t hash_signature; // Hash of a constant signature string.
uint64_t num_bytes; // Bytes allocated on behalf of the map.
uint32_t size; // Number of values currently stored.
uint32_t free_cell_index; // Offset of first free cell.
};接下来说下插入的过程,其他的删除和查找过程类似
ValueCreatedPair insert(absl::string_view key) {
Value* value = get(key);
if (value != nullptr) {
return ValueCreatedPair(value, false);
}
if (control_->size >= control_->hash_set_options.capacity) {
return ValueCreatedPair(nullptr, false);
}
//首先计算键的hash值并通过和solt数取余来获取solt的位置
const uint32_t slot = computeSlot(key);
//取出一个空闲的cell
const uint32_t cell_index = control_->free_cell_index;
Cell& cell = getCell(cell_index);
//将空闲索引后移一个位置
control_->free_cell_index = cell.next_cell_index;
//将新的cell插入到这个solt的首部
cell.next_cell_index = slots_[slot];
slots_[slot] = cell_index;
//insert函数并没有传value,将value的引用传回用来赋值
value = &cell.value;
value->truncateAndInit(key, stats_options_);
++control_->size;
return ValueCreatedPair(value, true);
}画一个可能的内存布局:
byte_order
定义了一些位区分的命令
c_smart_ptr
带析构时函数调用得std::unique_ptr,可用来包装C指针。
std::unique_ptr(*)(T*)> 在unique_ptr指针析构时调用传进来的函数指针
callback_impl
可变模板参数实现的回调函数管理,但是所有得函数调用的时候都传递的相同的参数
//存储可变参数返回void的函数对象
typedef std::function<void(CallbackArgs...)> Callback;
//调用时只传递了相同的参数
void runCallbacks(CallbackArgs... args) {
for (auto it = callbacks_.cbegin(); it != callbacks_.cend();) {
auto current = it++;
current->cb_(args...);
}
}cleanup
可以传递一个void()类型的函数对象, RAII析构时调用,可以保证离开作用域时调用。类似与Go的defer关键词。
compiler_requirements
监测编译器版本,是否支持C++14
empty_string
static const std::string EMPTY_STRING = "";只定义了一个静态的空字符串常量,可能是性能优化,所有的空字符串对象都指向这里。
enum_to_int
template <typename T> uint32_t enumToInt(T val) { return static_cast(val); } 将值转换为uint32_t类型
fmt
字符串格式化
hash
提供了hash算法的两个接口,基于xxHash算法。
hex
十六进制编解码
std::string Hex::encode(const uint8_t* data, size_t length) {
static const char* const digits = "0123456789abcdef";
std::string ret;
ret.reserve(length * 2);
for (size_t i = 0; i < length; i++) {
uint8_t d = data[i];
ret.push_back(digits[d >> 4]);
ret.push_back(digits[d & 0xf]);
}
return ret;
}这个算法实现的很巧妙。uint8_t 类型占8位, 每4位组成一个十六进制的数,这样每个uint8_t 类型都将对应两个十六进制数的字符。前四位右移,&1111获取后四位,正好对应字符数组中的位置。
linked_object
对插入链表对象的包装,记录对象在链表中的迭代器位置。从而快速操作节点。这个类只封装了链表操作,没有存储链表。相当与给每个插入链表的对象都额外带了一个迭代器信息。
lock_guard
封装了几种锁操作。
OptionalLockGuard 常规的RAII 锁,存储的锁指针
TryLockGuard 提供了tryLock操作,构造时并不锁定。保存的锁引用
LockGuard 常规的RAII 锁,存储的锁引用
ReleasableLockGuard 构造时获取锁,但是提供了release操作,使中途释放锁成为可能。
logger.h
logger_delegates.h
定义了日志相关的类和接口,包括不同模块的日志id和不同输出方向的代理类实现,没有涉及到线程相关。
matchers
检查值是否匹配匹配器? 留待以后
non_copyable
将复制构造函数和赋值操作符声明为private,防止对象的复制行为
perf_annotation
stl_helpers
辅助函数,容器中元素是否存在
thread
对pthread线程库的封装,没有使用C++11的线程对象。