【Linux内核层】深入netfilter编程
由于【智能路由器】系列系列博客中好几篇文章都用到了netfilter来实现路由器中的部分功能,所以写这篇博客来阐述一下我在使用netfilter框架编程时的看法。
我尽量以简洁的语言描述netfilter编程要点。
5个钩子点
分别为:PREROUTING、POSTOUTING、INPUT、FORWARD、OUTPUT,下面给了一个很简洁的框架图,想必大家很熟悉
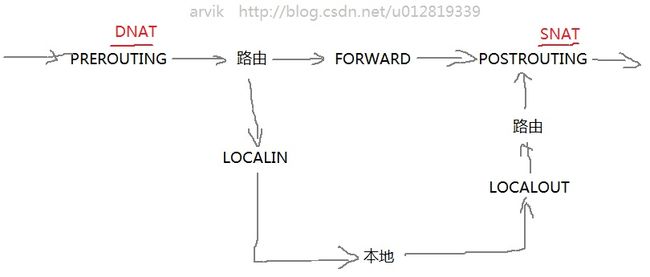
注意到:我在netfilter的5个钩子框架上用红色的字体标记了一下DNAT和SNAT的位置,为什么要标出?因为他们很重要,也很特别,它们影响我们在钩子点上截取的TCP/IP报文的内容。后面再说。
至于5个钩子点的作用我也不必再说(在此节省篇幅),因为一般介绍netfilter的的文章都会给出解释,搜搜好了。
源代码
注册/注销钩子
nerfilter的钩子注册/注销需先包含netfilter.h头文件
int nf_register_hook(strcut nf_hook_ops *reg);
void nf_unregister_hook(struct nf_hook_ops *reg);一般Linux内核模块的注册和注销代码都是这个形式
结构nf_hook_ops
上面的注册和注销函数里都有这个结构体,内容如下:
struct nf_hook_ops
{
struct list_head list; //钩子链表
nf_hookfn *hook; //钩子处理函数
struct module *owner; //模块所有者
int pf; //钩子协议族
int hooknum; //钩子的位置值
int priority; //钩子的的优先级
}仔细看一下这个nf_hookfn类型定义的形式:
typedef unsigned int nf_hookfn(unsigned int hooknum,
struct sk_buff *skb,
const struct net_device *in,
const struct net_device *out,
int (*okfn)(struct sk_buff *));处理结果
钩子函数是一定要返回的,处理结果代表了网络数据包的命运,有一下几种:
/* Responses from hook functions. */
#define NF_DROP 0 //丢弃该数据包,释放为他分配的资源
#define NF_ACCEPT 1 //保留该数据包,交由下一个hook函数处理
#define NF_STOLEN 2 //忘掉该数据包,hook函数处理该数据包,不再经过netfilter处理
#define NF_QUEUE 3 //将该数据包插入到用户空间
#define NF_REPEAT 4 //再次调用该hook函数
#define NF_STOP 5 //强于NF_ACCEPT,完全接受该数据包,并且后面的所有hook函数都不需处理该数据包
#define NF_MAX_VERDICT NF_STOP 钩子函数的优先级
在同一个钩子点下挂载的钩子函数用优先级来决定挂载函数的执行先后顺序了,钩子优先级在Linux内核中定义如下(源代码在netfilter_ipv4.h中):
enum nf_ip_hook_priorities {
NF_IP_PRI_FIRST = INT_MIN,
NF_IP_PRI_CONNTRACK_DEFRAG = -400,
NF_IP_PRI_RAW = -300,
NF_IP_PRI_SELINUX_FIRST = -225,
NF_IP_PRI_CONNTRACK = -200,
NF_IP_PRI_MANGLE = -150,
NF_IP_PRI_NAT_DST = -100,
NF_IP_PRI_FILTER = 0,
NF_IP_PRI_SECURITY = 50,
NF_IP_PRI_NAT_SRC = 100,
NF_IP_PRI_SELINUX_LAST = 225,
NF_IP_PRI_CONNTRACK_CONFIRM = INT_MAX,
NF_IP_PRI_LAST = INT_MAX,
};编写内核模块
有了以上基础代码就可以写内核模块了,最简单的例子如下:
#include 好了,全手打,一气呵成!
该程序的作用是将域名解析的请求数据丢掉!模块将流经netfilter的网络数据包中udp数据包目的端口为53的端口数据丢弃,而udp目的端口为53端口的数据就是即将送往DNS服务器的DNS解析请求数据包!
建议还没搞懂网络数据包层次的童鞋看看我的【以太网数据包】系列文章!
sk_buff结构体
sk_buff是网络数据包结构。恩,要详解这个估计好几篇文章都讲不完,在此只简单描述及解释
struct sk_buff {
/* These two members must be first. */
struct sk_buff *next;
struct sk_buff *prev;
ktime_t tstamp;
struct sock *sk;
struct net_device *dev;
char cb[48] __aligned(8);
unsigned long _skb_refdst;
#ifdef CONFIG_XFRM
struct sec_path *sp;
#endif
unsigned int len, data_len;
__u16 mac_len, hdr_len;
union {
__wsum csum;
struct {
__u16 csum_start;
__u16 csum_offset;
};
};
__u32 priority;
kmemcheck_bitfield_begin(flags1);
__u8 local_df:1,
cloned:1,
ip_summed:2,
nohdr:1,
nfctinfo:3;
__u8 pkt_type:3,
fclone:2,
ipvs_property:1,
peeked:1,
nf_trace:1;
kmemcheck_bitfield_end(flags1);
__be16 protocol;
void (*destructor)(struct sk_buff *skb);
#if defined(CONFIG_NF_CONNTRACK) || defined(CONFIG_NF_CONNTRACK_MODULE)
struct nf_conntrack *nfct;
#endif
#ifdef NET_SKBUFF_NF_DEFRAG_NEEDED
struct sk_buff *nfct_reasm;
#endif
#ifdef CONFIG_BRIDGE_NETFILTER
struct nf_bridge_info *nf_bridge;
#endif
int skb_iif;
#ifdef CONFIG_NET_SCHED
__u16 tc_index; /* traffic control index */
#ifdef CONFIG_NET_CLS_ACT
__u16 tc_verd; /* traffic control verdict */
#endif
#endif
__u32 rxhash;
kmemcheck_bitfield_begin(flags2);
__u16 queue_mapping:16;
#ifdef CONFIG_IPV6_NDISC_NODETYPE
__u8 ndisc_nodetype:2,
deliver_no_wcard:1;
#else
__u8 deliver_no_wcard:1;
#endif
__u8 ooo_okay:1;
kmemcheck_bitfield_end(flags2);
#ifdef CONFIG_NET_DMA
dma_cookie_t dma_cookie;
#endif
#ifdef CONFIG_NETWORK_SECMARK
__u32 secmark;
#endif
union {
__u32 mark;
__u32 dropcount;
};
__u16 vlan_tci;
sk_buff_data_t transport_header;
sk_buff_data_t network_header;
sk_buff_data_t mac_header;
/* These elements must be at the end, see alloc_skb() for details. */
sk_buff_data_t tail;
sk_buff_data_t end;
unsigned char *head,
*data;
unsigned int truesize;
atomic_t users;
};| sk_buff主要成员 | 含义 |
|---|---|
| next | sk_buff链表中的下一个缓冲区 |
| prev | sk_buff链表中的前一个缓冲区,很明显,sk_buff是在双向链表上的 |
| sk | 本报文所属的sock结构,此值仅在本机发出的报文中有效,从网络收到的报文此值为空 |
| tstamp | 报文收到的时间戳 |
| dev | 收到此报文的网络设备 |
| transport_header | 传输层头部 |
| network_header | 网络层头部 |
| mac_header | 链接层头部 |
| cb | 用于控制缓冲区。每个层都可以使用此指针,将私有数据放置于此。 |
| len | 有效数据长度 |
| data_len | 数据长度 |
| mac_len | 连接层头部长度,对于以太网,指MAC地址所用的长度,为6 |
| hdr_len | skb的可写头部长度 |
| csum | 校验和(包含开始和偏移) |
| csum_start | 当开始计算校验和时从skb->head的偏移 |
| csum_offset | 从csum_stat开始的偏移 |
| local_df | 允许本地分片 |
| pkt_type | 包的类别 |
| priority | 包队列的优先级 |
| truesize | 报文缓冲区的大小 |
| head | 报文缓冲区的头 |
| data | 数据的头指针 |
| tail | 数据的尾指针 |
| end | 报文缓冲区的尾部 |
鉴于时间和篇幅关系,sk_buff的数据结构图以及相关操作函数本文就不做介绍了,网上应该能找到。
struct net_device结构体
这是一个巨型结构体,不便在此罗列,网上有文章对此讲解,详细了解可前往地址http://blog.chinaunix.net/uid-21807675-id-1814837.html
NAT
网络数据包在通过netfilter的时候SNAT和DNAT对网络数据包做了更改,主要做了ip和端口映射,当然,输入设备net_device也变了,这些都要注意,在编写程序时,在适当的钩子点拦截数据包非常有必要,因为netfilter上除了你挂接的一些钩子函数外还有其他模块在上面挂接了钩子,这些钩子都会对数据包产生影响,往往挂错钩子点就拦截不到想要的数据。
好了,本篇文章到此结束。