C4.5(weka又称为J48)算法原理详解
1. 信息增益率
ID3算法有以下几个缺点:
1个属性取值越多,则此属性的信息增益率越大,越有可能被ID3选为当前分类属性。然而取值较多的属性并不一定最优。(例如一个属性的每个子节点都只有1个样本,此时信息增益率达到最大,但是用这样的属性却没有任何意义)
ID3只能处理离散型属性
可以处理缺失数据
可以对树进行剪枝
针对ID3算法的不足,Quinlan又提出了C4.5,C4.5算法采用信息增益率来取代信息增益作为当前最优决策属性的度量标准。
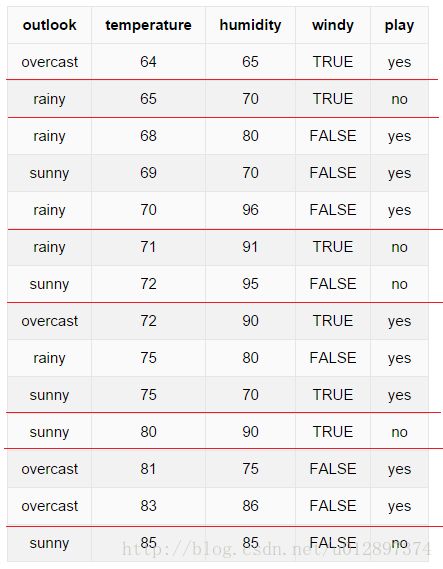
仍然选择weka中天气的数据集为例子:
| outlook | temperature | humidity | windy | play |
|---|---|---|---|---|
| sunny | hot | high | FALSE | no |
| sunny | hot | high | TRUE | no |
| overcast | hot | high | FALSE | yes |
| rainy | mild | high | FALSE | yes |
| rainy | cool | normal | FALSE | yes |
| rainy | cool | normal | TRUE | no |
| overcast | cool | normal | TRUE | yes |
| sunny | mild | high | FALSE | no |
| sunny | cool | normal | FALSE | yes |
| rainy | mild | normal | FALSE | yes |
| sunny | mild | normal | TRUE | yes |
| overcast | mild | high | TRUE | yes |
| overcast | hot | normal | FALSE | yes |
| rainy | mild | high | TRUE | no |
1.1 计算属性outlook的信息增益:
1.2 计算分裂信息(SplitInfo)来将信息增益规范化
一个属性取值情况越多, SplitInfo 越大,实际我们需要属性的 SplitInfo 越小越好
通过Outlook将样本分为以下几个部分:
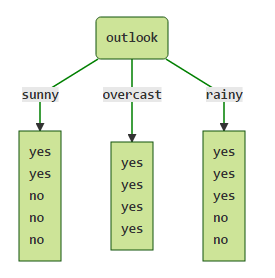
故 SplitInfooutlook 为:
同理计算其他属性的 SplitInfo
1.3 计算属性的信息增益率
IGR: Information Gain Ratio,即信息增益率
由此可见,属性 outlook 信息增益率越大,故第一步选择该属性为分类属性。在分裂之后的子节点中,如果该子节点只有一种 label ,则停止继续分类。否则重复上述步骤,继续分裂下去。
1.4 C4.5算法总结
选择 IGR (信息增益率)作为 ID3 算法中 IG (信息增益)的代替来选择更好的分类属性:
然后用此公式遍历每个属性,选择 IGR 最大的属性作为当前的分类属性来产生树。对于分类不纯的节点,继续重复上述方法选择其他属性继续分类。
2. C4.5处理连续型属性
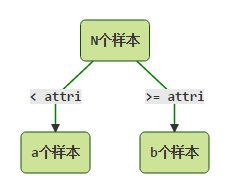
对于连续型属性,C4.5先把它当转换成离散型属性再进行处理。本质上属性取值连续,但对于有限的采样数据它是离散的。例如某连续型属性有N个不同取值,则有N-1种离散化的方法: <= vj 的分到左子树, > vj 的分到右子树,然后计算N-1种情况下最大的信息增益率。
对于离散型属性只需计算1次信息增益率,但连续型属性却需要计算N-1次。为了减少计算量,可对连续属性先进行排序,在只有label发生变化的地方才需要切开。比如:
原本需要计算13种情况,现在仅需计算7种。
+ 利用信息增益率来选择连续值属性的分界点存在的问题
由于C4.5对于连续值属性,每次选取一个分裂点进行分裂,即二分裂。此时
假设分裂结果为
而
当 a=b=2N 的时候 SplitInfo(attr) 达到最大值 1 (具体计算过程省略)。 SplitInfo 越大, IGR 就越小。故而等分分界点被抑制。此时子集样本个数能够影响分界点,显然不合理。因此在决定分界点时,还是采用了信息增益这个指标,而在选择具体属性的时候才选择信息增益率这个指标。(注意选择分裂点和选择具体属性的区别)
对于离散型属性,C4.5一次进行分裂后,后续不再使用该属性。但是对于连续型属性,由于进行的是二分裂,故下一次分裂可能还会继续用到该属性。例如:
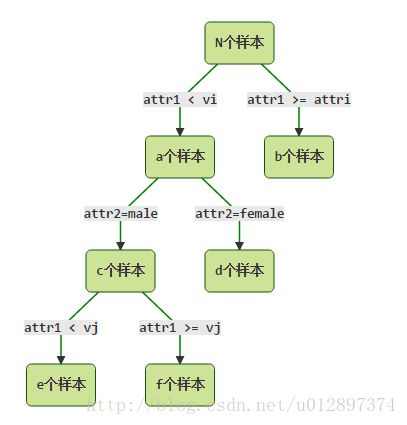
连续属性attr1会被用到多次。
3. C4.5处理缺失数据
3.1 缺失属性的增益值和增益率求解
3.1.1 离散型属性
仍然以下表为例说明:
| Day | Outlook | Temperature | Humidity | Wind | play |
|---|---|---|---|---|---|
| D1 | Sunny | Hot | High | Weak | No |
| D2 | ? | Hot | High | Strong | No |
| D3 | ? | ? | High | ? | Yes |
| D4 | Rain | Mild | High | Weak | Yes |
| D5 | Rain | Cool | ? | Weak | Yes |
| D6 | Rain | Cool | Normal | Strong | No |
| D7 | Overcast | Cool | Normal | Strong | Yes |
| D8 | ? | Mild | High | ? | No |
| D9 | ? | Cool | Normal | Weak | Yes |
| D10 | ? | ? | Normal | ? | Yes |
| D11 | ? | Mild | Normal | ? | Yes |
| D12 | Overcast | Mild | ? | Strong | Yes |
| D13 | Overcast | Hot | ? | Weak | Yes |
| D14 | Rain | Mild | High | Strong | No |
以属性 outlook 为例,共有14个样本,其中6个样本 outlook 值缺失,8个样本()不缺失。首先计算信息增益
- 原始信息熵为:(8个无缺失值样本, 5个yes, 3个no)
Entropy(S)=−(58×log258+38×log238)=0.954 - 属性outlook的信息熵为(只计算属性不为空的样本):
∑v=vi−Plog2P=[−18×(−1)]sunny+[−38×(−1)]overcast+[−24×log224−24×log224]rain=0.5 属性outlook的信息增益为:
IG(outlook)=814×(0.954−0.5)=0.259计算属性outlook的 SplitInfo ,此时将缺失值当作一种单独的属性:
SplitInfo(outlook)=−114log2114−314log2314−414log2414−614log2614=1.659属性outlook的信息增益率为
IGR(outlook)=0.2591.659=0.156
3.1.1 连续型属性
以下表为例进行说明:
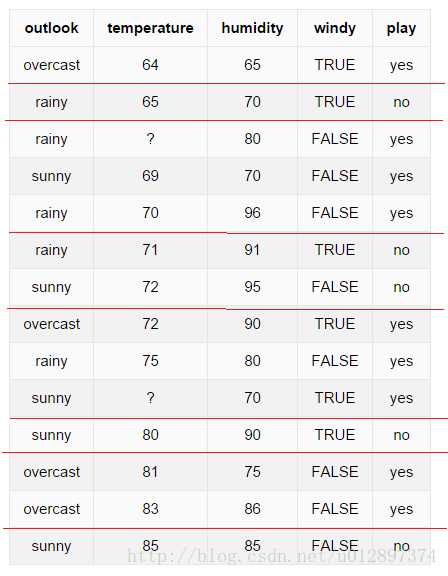
后面的计算步骤与上面完全相同,此处省略
3.2 将含有缺失值的样本分配给子节点
在C4.5算法中,带有缺失属性的样本会被分配到所有的子节点中,但是带有一个权值。即普通样本的权值为1,但缺失属性的样本权值为小数。如下图:
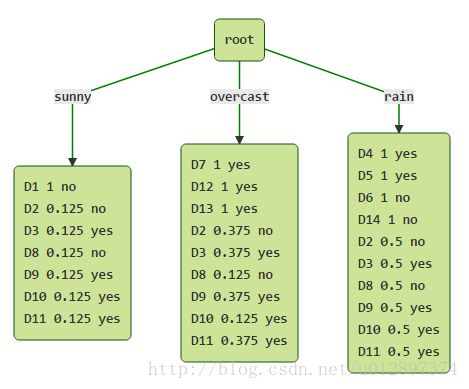
后面再继续分裂时,计算信息增益和增益率与上面的方法相同,只有样本个数中含有小数,计算过程此处省略。
3.3 预测含有缺失属性的样本的label
遇到一个未知label样本需要预测,但属性值中含有缺失数据时,按照3.2中的方法将该属性分别归类到所有子节点中,最后计算为各个标签的概率,取概率最大的标签作为最终的标签。如下图:
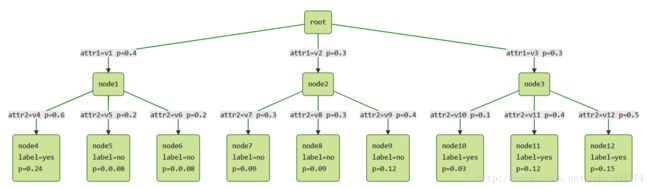
先假设碰到了一个需要预测的样本,但是attr1和attr2都不知,因此该样本为标签为yes的概率为:
该样本标签为no的概率为:
由于 P(yes)>P(no) ,故最终该样本(attr1和attr2均缺失)的标签为yes
参考文献: C4.5缺失值处理方法
4. C4.5的剪枝处理
为了防止C4.5分裂过度,造成过拟合现象,ross quinlan提出了两种剪枝方法:
pessimistic pruning
far more pessimistic estimate
4.1 早期的pessimistic pruning方法
把一颗子树(有多个叶子节点)用一个叶子节点代替,在训练集上的误判率肯定是上升的,但在新的数据集上不一定。于是需要将叶子节点的错误率加上一个惩罚因子,此处取为0.5[Quinlan, 1987e]。如果一个叶子节点有N个样本,其中E个被误判,则该叶子节点的误判率为 E+0.5N 。对于一颗子树,如果有L个叶子节点,则剪枝前该子树的误判率为:
由于加上了惩罚因子,因此一颗子树虽有多个叶子,但也未能占到便宜。剪枝后子树变成内部节点,因此也需要加上惩罚因子,因此剪枝后的误判率为:
树的误判次数服从二项分布,因此剪枝前的均值为
剪枝前的方差为:
因此剪枝前误判的上限数量为:
剪枝后的误判数量为:
因此由于采用悲观剪枝法,剪枝的条件是:
这也是为何称之为悲观剪枝的原因。
以下面的例子来计算一遍:
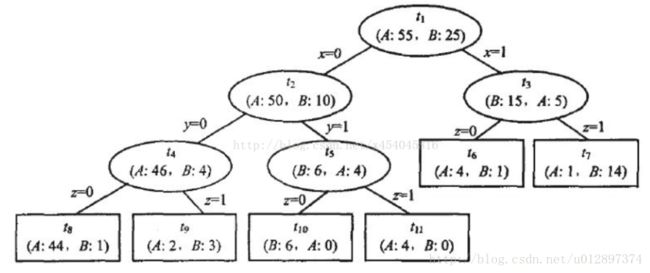
t1 、 t2 、 t3 、 t4 、 t5 5个节点可能会被剪枝。
此处仅计算 t4 节点的情况,其余省略。
因此 Eerror_before=E+std=5.92 。剪枝后:
由于 Eerror_after<Eerror_before ,因此应该对 t4 节点进行剪枝,所有样本全部标为A。
4.2 后来的far more pessimistic estimate
EBP(Error-Based Pruning)剪枝法
首先取置信度为0.25(根据统计经验)。对于N个样本,错分E个,则置信区间上限为:
错分样本率可以看出是 n(t) 次试验中某事件发生 e(t) 次,服从二项分布,因此置信区间上限
故:
只需据此求出错误率 p 即可。令
例如6个样本中0个被错分,要求错误率置信区间上限 U25%(0,6) ,则令 f(p)=0 。则 (1−p)6=0.25=>p=0.206 。即 U25%(0,6)=0.206 。同理要求 U25%(1,16) ,令 f(p)=0 ,则:
可用二分法求得 p=0.157
求导,得: f′(p) 。求得函数单调性之后,再用牛顿二分法求得p的近似值即可。下面以著名的国会投票数据(1984 United States Congressional Voting Records Database)为例进行说明。
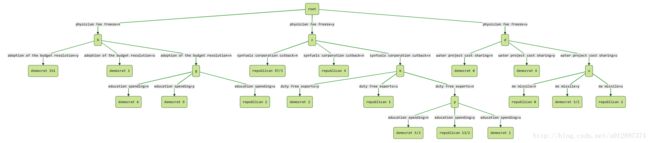
考虑下面这个局部:
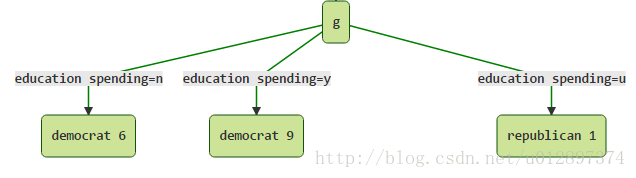
由于 U25%(0,6)=0.206 , U25%(0,9)=0.143 , U25%(0,1)=0.75 ,故剪枝前的错分的样本数目上限为:
而剪枝后应该16个样本全部变为democrat,但此时其实错分了1个republican。因此错分上限为:
因为 2.512<3.273 ,此处应该剪枝。然后继续进行下一步剪枝判断,剪枝前:
剪枝后
因为 Error′<Error ,因此此处应该继续剪枝。后面的计算仿照前面的步骤,此处省略。至此,C4.5的关键步骤全部完成。
参看文献: Quinlan J R. C4. 5: Programs for Machine Learning[M]:35-43. 1993.