特定敌手样本Adversarial Malware论文阅读小结
思考:这些论文都是针对特定的模型来做的敌手样本
那么我们的模型是怎么做的,cnn+rnn?怎么处理字节?
从而再决定怎么生成特定敌手样本
- Adversarial Malware Binaries: Evading Deep Learning for Malware Detection in Executables
- 深度网络检测方法:抽取k个bytes,补0到d个bytes,embedding成向量z,输入到神经网络中。
- 攻击方法:注入q个字节,k+q
q = min(k+q,d)−k
- Adversarial Examples for Malware Detection
前提认为:攻击者对自己的模型和数据非常了解
- 深度网络检测方法:给定特征1,2...,M表示使用二进制向量X∈{0,1} M的应用程序,其中Xi表示应用程序是否展现出特征i,该特征序列是一个稀疏向量
- 攻击方法:通过不断添加=0的特征使得其变为1
通过不断学习,得到良性结果或者修改次数最大后,截止。
为了维护对抗样本的功能
first, we will only change features that result in a single line of code that needs to be added to the real application
只改变添加到实际应用程序中的一行代码的特征
Second, we only modify manifest features which relate to the Android Manifest.xml file contained in any Android application.
(本文提到针对安卓的软件)只修改与Android应用程序中包含的Manifest.xm文件相关的清单特征
- Adversarial Deep Learning for Robust Detection of Binary Encoded Malware
x:input;
Θ:模型参数
y:标签
L(θ, x, y):网络产生的相关损失loss函数
分类Model:找到最优模型参数 θ∗使得risk最小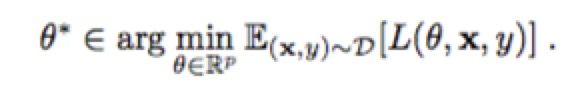 (1)
(1)
盲点是决策空间中的边界,没有训练样本,决策边界是不准确的
通过扰乱,使得Loss函数 L最大化,得到的xadv就是一个敌对样本
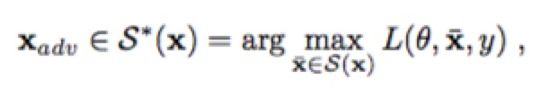 (2)‘
(2)‘
其中
S(x) ⊆ X是保持了恶意功能的样本
S ∗ (x) ⊆ S (x)是最大化loss的样本
对抗性学习将(1)和(2)归纳为
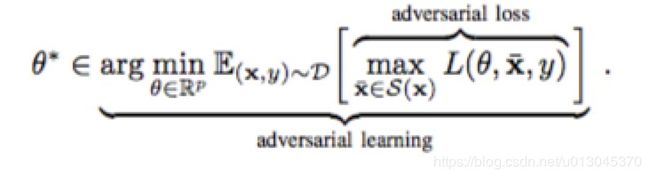
攻击方法:同上篇论文,翻转bit的0->1通过翻转恶意软件的二进制特征向量x的位
要求:在某一个方向上使得Loss函数最大化,这个样本是我们要找寻的敌对样本
而对于分类器模型来说,它只能在我们提出的最大化的损失函数中,找寻损失最小的那个对应参数,作为分类器的参数。
保持恶意功能的扰动对应于在恶意软件的二进制特征向量x中设置未置位的位
只能添加二进制可执行文件中不存在的特征,不能删除这些特征
- Adversary Resistant Deep Neural Networks with an Application to Malware Detection
提出一个新的对抗敌手技术:通过随机取消数据向量中的特征,来阻止构建有影响力的敌对样本。
在训练集和测试集中提出随机特征无效,使得DNN模型架构非确定(non-deterministic)。
这样即使敌手样本根据推断的关键特征,构建对抗样本,我们的模型在输入处理也会降低它的有效性。
a cost function L(θ,X,Y), where θ , X and Y denotes the parameters of the DNN, the input dataset,and the corresponding labels respectively.
用fast gradient sign method
生成敌手x:

表示成本函数L(·)相对于X 的导数。φ控制要添加的梯度的比例。
φ控制要添加的渐变的比例。
扰乱向量驱动数据点X朝向成本函数L(·)最敏感的方向。 但是,应该指出的是,δX必须保持在小范围内。 否则,添加δX将导致实际样本的显着失真,使操作很容易被检测到。
本文主要对分类模型引入了一个Nullification层,这个层对输入的特征向量进行处理,通过乘上一个稀疏一维矩阵,随机去除一些特征,从而降低特征对分类模型的影响力。
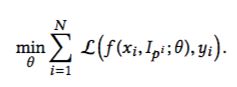
上面这个公式就是将x乘上一个稀疏矩阵Ip,再去计算其Loss函数。稀疏矩阵中的0的个数随机分布取样,从高斯分布中随机采样决定0的数量。
但是敌手样本操作中,也是只能增加特征。本分类模型的主要思想是降低特征对分类模型的影响力,实验结果均在90%多。但是,随着Nullification rate的增加,也就是去除特征比例增加,分类模型准确性会下降,抵抗恶意敌对样本能力增强。所以,需要在准确率和抵抗率之间选择一个最佳平衡。