从零学SpringCloud系列(七):API网关Zuul
一、为什么需要API网关
通过前面对几个组件的 介绍,我们基本可以构建一个下图中的简单的微服务架构系统:

我们聚焦到Open Service 和 外部调用的地方,随着下方服务的增多,我们需要手动维护负载均衡器中的服务列表,并且如果我们需要服务的微服务接口都需要 权限校验,这样我们需要在每个对外服务中维护一套这样的逻辑,这样会加重开发和测试人员的负担。
为了解决上面问题,API 网关的概念应运而生。API网关是一个更为智能的服务器,它的定义类似于面向对象中的Facade模式,它的存在就像是整个微服务 架构系统的门面一样,所有的外部客户端访问都需要经过它来进行调度和过滤。它除了要实现请求路由、负载均衡、校验过滤等功能之外,还需要更多能力,比如与服务 治理框架的结合,请求转发时的熔断,服务的聚合等一系列高级功能。
二、Zuul的作用
- 统一入口:未全部为服务提供一个唯一的入口,网关起到外部和内部隔离的作用,保障了后台服务的安全性。
- 鉴权校验:识别每个请求的权限,拒绝不符合要求的请求。
- 动态路由:动态的将请求路由到不同的后端集群中。
- 减少客户端与服务端的耦合:服务可以独立发展,通过网关层来做映射。
三、Zuul工作原理
zuul的核心是一系列的filters,其作用类比servlet框架的filter,或者AOP。zuul把请求路由到用户处理逻辑的过程中,这些filter参与一些过滤处理,比如Authentication,Load Shedding等。

zuul使用 一系列不同类型的过滤器,使我们能够快速灵活的将功能应用于 我们的边缘服务。这些过滤器可帮助我们执行以下功能
身份验证和安全性:确定每个资源的身份验证要求并拒绝不满足要求的请求。
洞察和监控:在边缘跟中有意义的数据和统计数据,以便为我们提供准确的生产视图。
动态路由:根据需要动态的将请求路由到不同的后端集群。
压力测试: 逐渐增加集群的流量以衡量性能。
Load Shedding:为每种类型的请求分配容量并删除超过限制的请求。
静态响应处理:直接在边缘构建一些响应,而不是将他们转发到内部集群。
四、过滤器生命周期
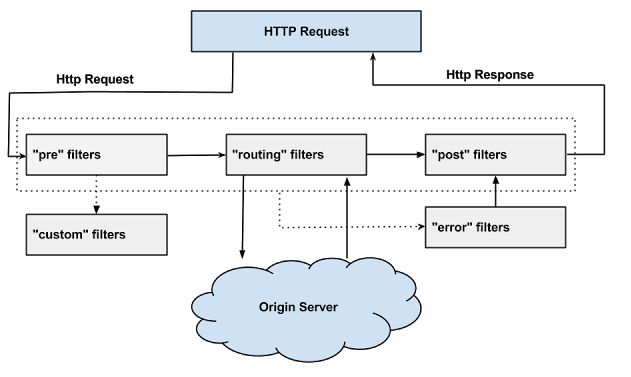
从上图中我们可以看到,当外部HTTP请求到达API网关服务的时候,首先他会进入第一个阶段pre, 在这里他会被pre类型的过滤器进行处理,该类型的过滤器的主要目的是在进行请求路由之前做一些前置加工,比如请求的校验等。然后进入第二个阶段routing,也就是之前我们说过的路由 请求转发阶段,请求 将会被routing 类型的过滤器进行处理。这里的具体处理内容就是将外部请求转发到具体服务实例上去的过程,当服务实例将请求结果返回之后,routing阶段完成,请求进入第三阶段post。此时,请求将会被post类型的处理器处理,这些过滤器处理的时候不仅能获取到请求信息,还能获取到服务实例返回信息,所以在post类型的过滤器中,我们可以对结果进行加工或转换等内容。另外,还有一个特殊阶段error,该阶段只有上述三个阶段中发生异常的时候才会触发,但是它最后流向还是post类型的过滤器,因为它需要通过post过滤器将最终结果返回给请求客户端(对于error过滤器处理,在Spring Cloud Zuul的过滤连中实际上有一些不同)
五、核心过滤器
在Spring Cloud zuul中,为了让API更为方便的被使用,它在HTTP请求生命周期各个阶段默认实现了一批过滤器,他们会在API网关启动的时候呗自动加载和启用。
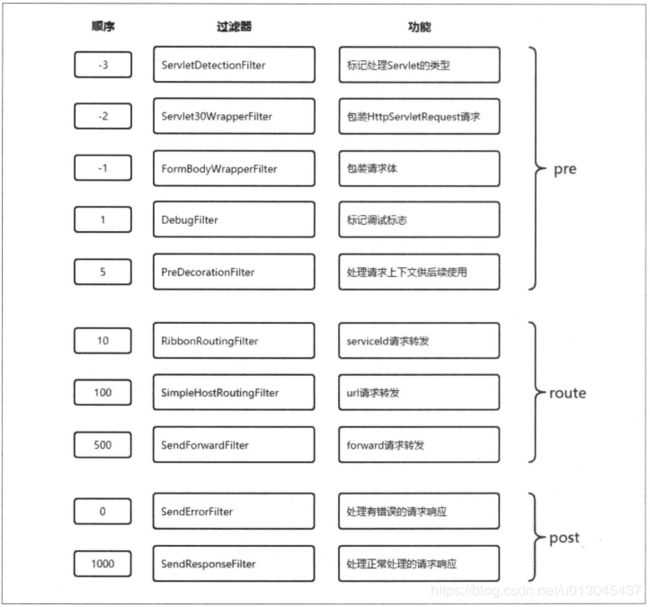
六、路由详解
6.1 传统路由配置
传统路由配置是指没有服务发现机制的情况下,通过在配置文件中具体指定每个路由表达式与服务实例的映射关系来实现API网关对外部请求的路由。
单实例配置
通过zuul.routes.<路由名>.path与zuul.routes.<路由名>.url
zuul:
routes:
service-provider:
path: /eureka-service/**
url: http://localhost:8080多实例配置
通过zuul.routes.<路由名>.path与zuul.routes.<路由名>.serviceId
zuul:
routes:
service-provider:
path: /eureka-service/**
serviceId: eureka-service
ribbon:
eureka:
enabled: false
eureka-service:
ribbon:
listOfServers: http://localhost:8080/,http://localhost:8081/它的配置和服务路由的配置方式一样,只是服务实例列表需要我们手动维护,由于多个实例的存在,所以就需要负载均衡策略,所以这里需要依赖ribbon配置。
6.2 服务路由配置
快速入门中已经讲了面向服务路由的配置,通过与Eureka的整合,实现了对服务实例的自动维护,所以在使用服务路由的时候,无须指定serviceId所指定具体服务实例地址,只需要通过zuul.routes.<路由名>.path与zuul.routes.<路由名>.serviceId成对配置即可。
zuul:
routes:
eureka-service:
path: /eureka-service/**
serviceId: eureka-service面向服务的路由配置除了上边的方法还有一种更简单的方式:zuul.routes.<服务名>=<映射地址>
zuul:
routes:
eureka-service: /eureka-service/**与传统路由相比,有外部请求到API网关的时候,面向服务路由发生了什么?
当有外部请求到达API网关的时候,根据请求的URL路径去匹配path的规则,通过path找到路由名,去找对应的serviceId的服务名,
- 传统路由就会去根据这个服务名去找listOfServers参数,从而进行负载均衡和请求转发
- 面向服务路由会从注册到服务治理框架中取出服务实例清单,通过清单直接找到对应的实例地址清单,从而通过Ribbon进行负载均衡选取实例进行路由(请求转发)
6.3 服务路由的默认配置
Eureka与Zuul整合为我们省去了大量的维护服务实例清单的配置工作,但是实际操作中我们会将path与serviceId都用服务名开头,如上边我所举的几个例子都是,这样的配置其实Zuul已经默认为我们实现了。
其实,Zuul在注册到Eureka服务中心之后,它会为Eureka中的每个服务都创建一个默认的路由规则,默认规则的path会使用serviceId配置的服务名作为请求前缀。这会使一些我们不希望的开放的服务有可能被外部访问到,此时,我们可以使用zuul.ignored-services参数来设置一个不自动创建该服务的默认路由。Zuul在自动创建服务路由的时候会根据这个表达式进行判断,如果服务名匹配表达式,那么Zuul将跳过此服务,不为其创建默认路由;
zuul:
ignored-services: feign-customer,eureka-service如果不想使用自动创建默认路由功能,可以使用如下方法跳过默认路由
zuul:
ignored-services: '*'6.4 自定义路由映射规则
可以使用regexmapper在serviceId和路由之间提供约定。它使用正则表达式命名组从serviceId提取变量并将它们注入路由模式。
@Bean
public PatternServiceRouteMapper serviceRouteMapper() {
return new PatternServiceRouteMapper(
"(?^.+)-(?v.+$)",
"${version}/${name}");
} PatternServiceRouteMapper 对象可以让开发者 通过正则表达式来 自定义服务与路由映射的生成关系。其中构造函数的第一个参数是用来匹配服务名称是否符合自定义规则的正在表达式,第二个参数则是定义根据服务名称中定义的内容转换出的路径表达式规则,当开发者在API网关中定义了PatternServiceRouteMapper的实现之后,只要符合 第一个参数定义的规则的服务名,都会优先使用该实现构建出的路径表达式,如果没有匹配成功服务规则,则还是走默认的路由映射规则,即采用完整服务名作为前缀的路径表达式。
6.5 路径匹配
不论是使用传统路由配置方式还是服务路由的配置方式,我们都需要为每个路由规则定义匹配表达式,也就是上面说的path参数。在zuul中,路由匹配的路径表达式采用了ant风格定义。
| 通配符 | 说明 |
| ? | 匹配任意单个字符 |
| * | 匹配任意数量的字符 |
| ** | 匹配任意数量的字符,支持多级目录 |

如果有一个可以同时满足多个path的匹配的情况,此时匹配结果取决于路由规则的定义顺序,
这里需要注意的是:properties无法保证路由规则的顺序,推荐使用yml格式配置文件
忽略表达式
Zuul提供了用于忽略路径表达式的参数zuul.ignored-patterns。使用该参数可以用来设置不希望被API网关进行路由的URL表达式。
zuul:
ignored-patterns: /**/hello/**路由前缀
为了方便全局为路由path增加前缀信息,Zuul提供了zuul.prefix参数来进行设置,但是代理前缀会从默认路径中移除掉,为避免这种情况,可以使用zuul.stripPrefix=false 来关闭移除代理前缀的动作,也可以通过zuul.routes.<路由名>.strip-prefix=false来指定服务关闭移除代理前缀的动作
zuul:
prefix: /api
routes:
feign-customer:
path: /feign/**
stripPrefix: false6.6 Cookie与头信息
默认情况下,Zuul在请求路由时会过滤掉HTTP请求头信息中的一些敏感信息,防止这些敏感的头信息传递到下游外部服务器。但是如果我们使用安全框架如Spring Security、Apache Shiro等,需要使用Cookie做登录和鉴权,这时可以通过zuul.sensitiveHeaders参数定义,包括Cookie、Set-Cookie、Authorization三个属性来使Cookie可以被传递。可以分为全局指定放行Cookie和Headers信息和指定路由放行
1.全局放行
zuul:
sensitiveHeaders: Cookie,Set-Cookie,Authorization2.指定路由名放行
zuul:
routes:
users:
path: /myusers/**
sensitiveHeaders: Cookie,Set-Cookie,Authorization
url: https://downstream如果全局配置和路由配置均有不同程度的放行,那么采取就近原则,路由配置的放行规则将生效
6.7 本地跳转
迁移现有应用程序或API时的一种常见模式是“关闭”旧的端点,并慢慢地用不同的实现替换它们。Zuul代理是一个有用的工具,因为可以使用它来处理来自旧端点客户端的所有流量,但会将某些请求重定向到新端点。
zuul.routes.<路由名>.url=forward:/<要跳转到的端点>
举例:
zuul:
routes:
first:
path: /first/**
url: http://first.example.com
second:
path: /second/**
url: forward:/first这样就会将请求到/second端点的请求转发到/first端点
七、Hystrix和Ribbon支持
上文有讲过,Zuul中包含了Hystrix和Ribbon的依赖,所以Zuul拥有线程隔离和断路器的自我保护功能,以及对服务调用的客户端负载均衡,需要注意的是传统路由也就是使用path与url映射关系来配置路由规则的时候,对于路由转发的请求不会使用HystrixCommand来包装,所以没有线程隔离和断路器的保护,并且也不会有负载均衡的能力。所以我们在使用Zuul的时候推荐使用path与serviceId的组合来进行配置。
7.1. 设置Hystrix超时时间
使用hystrix.command.default.execution.isolation.thread.timeoutInMilliseconds来设置API网关中路由转发请求的命令执行时间超过配置值后,Hystrix会将该执行命令标记为TIMEOUT并抛出异常,Zuul会对该异常进行处理并返回如下JSON信息给外部调用方
{
"timestamp":20180705141032,
"status":500,
"error":"Internal Server Error",
"exception":"com.netflix.zuul.exception.ZuulException",
"message":"TIMEOUT"
}7.2. 设置Ribbon连接超时时间
使用ribbon.ConnectTimeout参数创建请求连接的超时时间,当ribbon.ConnectTimeout的配置值小于hystrix.command.default.execution.isolation.thread.timeoutInMilliseconds的配置值时,若出现请求超时的时候,会自动进行重试路由请求,如果依然失败,Zuul会返回如下JSON信息给外部调用方
{
"timestamp":20180705141032,
"status":500,
"error":"Internal Server Error",
"exception":"com.netflix.zuul.exception.ZuulException",
"message":"NUMBEROF_RETRIES_NEXTSERVER_EXCEEDED"
}如果ribbon.ConnectTimeout的配置值大于hystrix.command.default.execution.isolation.thread.timeoutInMilliseconds的配置值时,当出现请求超时的时候不会进行重试,直接超时处理返回TIMEOUT的错误信息
7.3. 设置Ribbon的请求转发超时时间
使用ribbon.ReadTimeout来设置请求转发超时时间,处理与ribbon.ConnectTimeout类似,不同点在于这是连接建立之后的处理时间。该值小于hystrix.command.default.execution.isolation.thread.timeoutInMilliseconds的配置值时报TIMEOUT错误,反之报TIMEOUT的错误。小于的时候会先重试,不成才报错;大于的时候直接报错。
7.4. 关闭重试配置
- 全局配置
zuul.retryable=false - 针对路由配置
zuul.routes.<路由名>.retryable=false
8 小结
网关在微服务中还是非常重要的一个组件,我们还是需要好好掌握的。