Linux服务篇--高可用集群Keepalived
本章概要
- 高可用集群
- Keepalived
- Keepalived配置
- Keepalived支持IPVS
1、高可用集群
集群Cluster
- 集群类型:
LB集群:负载均衡集群
四层 lvs,nginx(stream),haproxy(mode tcp)
七层 nginx,haproxy(mode http),varnish(diectors modules)
HA集群:高可用性集群
SPoF: Single Point of Failure
核心特性:通过冗余方式,为活动设备提供备用设备,在活动设备出现故障时,备用设备能够上线并取代活动设备成为新的活动设备,即组合多台主机完成一个核心目标所构建出来的集群
HP集群:高性能计算集群
综合多台计算机的能力,解决复杂问题 - 系统可用性的公式:A=MTBF/(MTBF+MTTR)
MTBF(Mean Time Between Failure):平均无故障时间
MTTR(Mean Time To Restoration):平均修复(故障)时间
(0,1), 95%
几个9(指标): 99%, …, 99.999%,99.9999%;
系统故障:
硬件故障:设计缺陷、wear out(损耗)、自然灾害……
软件故障:设计缺陷 - 提升系统高用性的解决方案:
提升MTBF 平均无故障时间增大,即硬件设备故障率降低
与设备厂商有关,x86服务器故障率较高
降低MTTR 平均修复(故障)时间降低
提供备用服务器,其配置和主服务器相同,使用应用程序监控设备是否出现故障,一旦出现故障,就自动使用备用服务器替换主服务器
手段:设备冗余redundant
active/passive 主备
active/active 双主
active --> HEARTBEAT --> passive
active <–> HEARTBEAT <–> active
注意:活动主机为active,备用主机为passive
活动主机通过单播,多播或组播方式向其他主机发送心跳信息,如果其他主机在一定周期内没有收到活动主机的心跳信息,就认为活动主机出现故障,备用主机就取代活动主机成为活动主机 - 高可用的是“服务”:
HA nginx service:
vip/nginx process[/shared storage]
资源:组成一个高可用服务的“组件”
(1) passive node的数量
(2) 资源切换
提供(构建高可用)服务的关键因素:
ip地址:进入服务器的接口。
如果使用固定ip地址提供服务,那么备用主机则必须能够拿到该固定ip才能够在活动主机故障后成为活动主机
process:用户空间的进程对客户端提供服务
相对于ipvs来说,没有进程的说法,仅是内核空间的规则
storage:数据同步问题
对于mysql数据库来说,主备只能解决设备问题,备用服务器无法获取数据库中的数据,因此需要解决数据同步的问题
数据同步:
主从复制:使用软件或某个服务脱离于系统本身,对数据进行数据主从复制完成数据同步
rsync_inotify 文件级同步
drbd kernel2.6.33 分布式复制块设备
在不安装第三方软件,基于内核模块的情况下,把两个主机之上的两个磁盘或磁盘分区做成跨主机的镜像设备,
当在其中一块磁盘写入数据时,会同步到另外一块镜像磁盘上,实现数据同步的功能,系统可用性最高达到99.5%
- shared storage:
NAS:文件共享服务器;
SAN:存储区域网络,块级别的共享
注意:NAS和SAN二者要求不同,NAS属于文件级别的存储设备,SAN属于块级别存储设备,二者的区别在于后端主机之上是否有操作系统,是否能够对多个节点同时对同一个文件施加读写操作时,自动维持文件锁。
另外,块设备后端服务器无法维持文件锁,需要前端调用者来维持,如果两个节点写同一个文件,会导致文件系统崩溃 - Network partition:网络分区
网络分区:由于硬件设备故障而导致节点之间无法连接,出现网络不同的区域。
一旦出现网络分区,能够代表集群继续工作的网络分区小群体中的节点成员数量必须大于原集群成员节点的一半,在大于半数的网络分区中选举主节点和备用节点
quorum:法定人数
with quorum: > total/2
without quorum: <= total/2
隔离设备: fence
node:STONITH = Shooting The Other Node In The Head,断电重启
资源:断开存储的连接 - TWO nodes Cluster
辅助设备:ping node, quorum disk - Failover:故障切换,即某资源的主节点故障时,将资源转移至其它节点的操作
- Failback:故障移回,即某资源的主节点故障后重新修改上线后,将之前已转移至其它节点的资源重新切回的过程
- HA Cluster实现方案:
ais:应用接口规范 完备复杂的HA集群
RHCS:Red Hat Cluster Suite红帽集群套件
heartbeat
corosync
vrrp协议实现:虚拟路由冗余协议
keepalived
2、KeepAlived
KeepAlived介绍
- keepalived:
vrrp协议:Virtual Router Redundancy Protocol - 术语:
虚拟路由器:Virtual Router
虚拟路由器标识:VRID(0-255),唯一标识虚拟路由器
物理路由器:
master:主设备
backup:备用设备
priority:优先级
VIP:Virtual IP
VMAC:Virutal MAC (00-00-5e-00-01-VRID) - 通告:心跳,优先级等;周期性
- 工作方式:抢占式,非抢占式
- 安全工作:
认证:
无认证
简单字符认证:预共享密钥
MD5 - 工作模式:
主/备:单虚拟路径器
主/主:主/备(虚拟路径器1),备/主(虚拟路径器2)
keepalived 协议
即vrrp的软件实现,能够安装在linux主机上,让linux主机像路由器一样能漂移ip地址,完成地址转移
第一个功能模块
keepalived基于VRRP(虚拟路由冗余协议)协议,仅用于ip地址转移
对于构建高可用服务来说,keepalived仅能够实现ip地址的功能,对于进程和存储,则无能为力
keepalived设计之初就是为ipvs提供高可用集群
第二个模块
IPVS wrapper
可以通过自身配置文件生成ipvs规则
第三个模块
Checkers
能对ipvs的后端服务器real server做健康状态检测,这就补充了ipvs不能做健康状态检测的缺点,为ipvs添加了在多个节点之上实现高可用的功能
扩展功能:
调用外置脚本,完成必要的管理操作,如通过脚本管理nginx或haproxy实现高可用
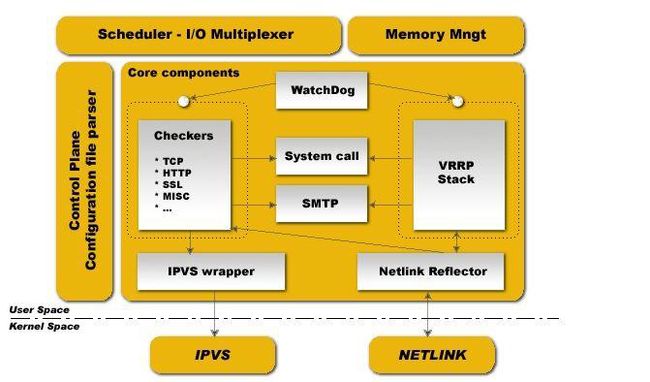
KeepAlived组成
- keepalived:
vrrp协议的软件实现,原生设计目的为了高可用ipvs服务 - 功能:
vrrp协议完成地址流动
为vip地址所在的节点生成ipvs规则(在配置文件中预先定义)
为ipvs集群的各RS做健康状态检测
基于脚本调用接口通过执行脚本完成脚本中定义的功能,进而影响集群事务,以此支持nginx、haproxy等服务 - 组件:
核心组件:
vrrp stack
vrrp组件的实现
监控本地节点状态,判定服务器主从节点,确保主节点向备用节点发送心跳信息、优先级信息等,实现ip地址转移
ipvs wrapper
可以通过自身配置文件自动生成ipvs规则
checkers
健康状态检测,通过邮件发送报警信息
WatchDog
内核级功能,调用硬件实现
监控vrrp进程,如果进程出现故障,负责通知相关进程,重启vrrp进程
控制组件:配置文件分析器
IO复用器
内存管理组件
知识扩展:
VRRP协议介绍
虚拟路由冗余协议
VRID 虚拟路由标识
由两个或两个以上的路由器组成,在虚拟路由器中存在一个master路由器,多个backup路由器
接收客户端请求的VIP地址配置在master路由器上,有master路由器承载报文的转发,当master出现故障,由backup路由器代替master路由器进行工作
虚拟ip地址,即VIP,一个虚拟路由器可以配置一个或多个虚拟ip地址
虚拟mac地址
master选举方式:
优先级
根据优先级确定虚拟路由器中每台物理路由器的地位
抢占式
根据优先级进行选举主节点和从节点
该模式导致网络格局出现不稳定
非抢占式
只要选举出主节点,并且主节点无故障,即使增加优先级更高的节点,也不会触发新的选举操作
KeepAlived实现
- HA Cluster 配置准备:
(1) 各节点时间必须同步
ntp, chrony
(2) 确保iptables及selinux不会成为阻碍
(3) 各节点之间可通过主机名互相通信(对KA并非必须)
建议使用/etc/hosts文件实现
(4) 各节点之间的root用户可以基于密钥认证的ssh服务完成互相通信(对KA并非必须) - keepalived安装配置:
CentOS 6.4+ Base源 - 程序环境:
主配置文件:/etc/keepalived/keepalived.conf
主程序文件:/usr/sbin/keepalived
Unit File:/usr/lib/systemd/system/keepalived.service
Unit File的环境配置文件:/etc/sysconfig/keepalived
知识扩展:
如何完成ip地址转移
vrrp通过将多个物理设备组建为一个虚拟设备组并通过优先级和选举机制来确保始终有一个当下优先级最高的节点能持有并配置虚拟ip地址并接收并服务于用户请求,
一旦节点出现故障,会重新触发选举操作,选举出一个新的节点,并将ip地址配置在新的主节点上,进而保证有节点转发客户端的访问请求,实现高可用服务的效果
本地通信通过mac地址实现,当主节点设备出现故障后,从节点代替主节点进行报文的转发,拿到vip地址(虚拟ip地址),
但由于客户端记录mac地址为原主节点设备的mac地址,因此二者仍然无法通信
如何使二者能够通信呢?
gracious arp
当主节点出现故障后,从节点代替主节点,当从节点成为主节点之后,拿到vip地址,会通过免费arp发送广播报文宣告自己的mac地址,
当其他设备接收到该广播报文后发现mac地址与vip的对应关系不一致,就更新自己的arp表,从而实现与新的主节点通信
3、KeepAlived配置
KeepAlived配置
- 配置文件组件部分:
- TOP HIERACHY
GLOBAL CONFIGURATION 全局配置
Global definitions 全局定义
Static routes/addresses 静态路由规则
VRRPD CONFIGURATION VRRP配置
VRRP svripts vrrp脚本
VRRP synchronization group(s):vrrp同步组
VRRP gratuitous ARP 免费arp
VRRP instance(s):即一个vrrp虚拟路由器
LVS CONFIGURATION
生成real server和ipvs规则的配置和对后端RS服务健康状态检测的配置,该配置段只有在对ipvs做高可用配置才有用
Virtual server group(s)
Virtual server(s):ipvs集群的vs和rs
查看配置文件man帮助信息:
查看配置文件具体信息:man keepalived.conf
GLOBAL和VRRP配置段:
Global definitions
global_defs # Block id
{
notification_email # To: #用于接收告警邮件的邮件地址,用于定义目标收件人
{
[email protected]
...
}
notification_email_from [email protected]
smtp_server 127.0.0.1 []
模拟发件人,由keepalived自动生成,调用mstp server向目标收件人发邮件
发送邮件场景:当主从节点发生转移,lvs中某个real server的上限或下限
vrrp_mcast_group4 224.0.0.18 定义组播域的ip地址,默认为224.0.0.18
主节点发送心跳信息,通过组播发送给组播域中的所有主机
如果生产环境中只有一个keepalived集群,使用默认即可
在ip地址分类中,组播地址段为:224.0.0.0-239.0.0.0
只有所有主机同用一个组播地址,才在一个组播域,组播地址可配置在多个主机之上
VRRP instance配置段
配置虚拟路由器:
vrrp_instance {
....
}
专用参数:
state MASTER|BACKUP:当前节点在此虚拟路由器上的初始状态;只能有一个是MASTER,余下的都应该为BACKUP
interface IFACE_NAME:绑定为当前虚拟路由器使用的物理接口
virtual_router_id VRID:当前虚拟路由器惟一标识,范围是0-255
priority 100:当前物理节点在此虚拟路由器中的优先级;范围1-254
advert_int 1:vrrp通告的时间间隔,默认1s
authentication { #认证机制
auth_type AH|PASS PASS指明文认证,AH认证方式尚未研发完成
auth_pass 仅前8字节有效,默认为1234
}
virtual_ipaddress { #虚拟IP
/ brd dev scope label - 配置语法:
- 配置虚拟路由器:
vrrp_instance{
…
} - 专用参数:
state MASTER|BACKUP:当前节点在此虚拟路由器上的初始状态;只能有一个是MASTER,余下的都应该为BACKUP
interface IFACE_NAME:绑定为当前虚拟路由器使用的物理接口
virtual_router_id VRID:当前虚拟路由器惟一标识,范围是0-255
priority 100:当前物理节点在此虚拟路由器中的优先级;范围1-254
advert_int 1:vrrp通告的时间间隔,默认1s
示例:
authentication { #认证机制
auth_type AH|PASS
auth_pass 仅前8位有效
}
virtual_ipaddress { #虚拟IP
/ brd dev scope label - nopreempt:定义工作模式为非抢占模式
- preempt_delay 300:抢占式模式,节点上线后触发新选举操作的延迟时长,默认模式
- 定义通知脚本:
notify_master| :
当前节点成为主节点时触发的脚本
notify_backup| :
当前节点转为备节点时触发的脚本
notify_fault| :
当前节点转为“失败”状态时触发的脚本
notify| :
通用格式的通知触发机制,一个脚本可完成以上三种状态的转换时的通知
示例:KeepAlived单主配置
VIP地址:192.168.32.200
主节点配置:
! Configuration File for keepalived
global_defs {
notification_email {
root@localhost #接收邮件通知的地址
}
notification_email_from keepalived@localhost #发件人地址,可以随便冒充,有没有该用户都可以
smtp_server 127.0.0.1 #指定真正的邮件服务器,这里实验以本机ip为例
smtp_connect_timeout 30
router_id k1 #当前物理设备的物理主机名
vrrp_skip_check_adv_addr #跳过检查通告地址
vrrp_strict #工作于严格模式下
vrrp_garp_interval 0
vrrp_iptables #当启动keepalived服务时,会自动在iptables中INPUT链增加一条防火墙规则:拒绝所有ip地址访问本机,防止其他主机通过访问本机对后端主机产生危害。添加vrrp_iptables 表示不会自动添加iptables规则
vrrp_gna_interval 0
vrrp_mcast_group4 224.0.45.1 #组播地址
}
注意:要查看本机是否支持组播,使用ifconfig查看是否出现MULTICAST字样,如果没有出现,进行以下设置开启组播:ip link set ens32
vrrp_instance VI_1 { #定义虚拟路由器实例VI_1,名称可自定义
state MASTER #定义初始状态,该节点为MASTER,其他节点必须为BACKUP
interface ens33 #虚拟ip地址接口
virtual_router_id 55 #虚拟路由id
priority 100 #主节点权限为100,其他节点必须低于该权限值
advert_int 1
authentication {
auth_type PASS #明文认证
auth_pass 1212 #密码默认为1111,可自定义
}
virtual_ipaddress { #配置VIP地址
192.168.32.200/16 brd 192.168.255.255 dev ens33 label ens33:0 #指定VIP地址,广播地址,网卡,别名
}
}
从节点配置:
! Configuration File for keepalived
global_defs {
notification_email {
root@localhost
}
notification_email_from keepalived@localhost
smtp_server 127.0.0.1
smtp_connect_timeout 30
router_id k1
vrrp_skip_check_adv_addr
vrrp_strict
vrrp_garp_interval 0
vrrp_iptables
vrrp_gna_interval 0
vrrp_mcast_group4 224.0.45.1
}
vrrp_instance VI_1 {
state BACKUP #指定初始状态
interface ens33
virtual_router_id 55
priority 98
advert_int 1
authentication {
auth_type PASS
auth_pass 1212
}
virtual_ipaddress {
192.168.32.200/16 brd 192.168.255.255 dev ens33 label ens33:0 #VIP地址不变,网卡名称根据本机网卡名称进行更改
}
}
测试:
在从节点抓取本地ens33网卡的信息,查看报文信息
tcpdump -i ens33 -nn host 224.0.45.1
启动从节点keepalived服务,报文信息:
16:20:27.176316 IP 192.168.32.130 > 224.0.45.1: VRRPv2, Advertisement, vrid 55, prio 98, authtype simple, intvl 1s, length 20
在从节点使用ifconfig命令查看ip地址
发现存在ens33:0,ip地址为192.168.32.200
注意:当启动keepalived服务时,会自动在iptables中INPUT链增加一条防火墙规则:拒绝所有ip地址访问本机,防止其他主机通过访问本机对后端主机产生危害。可以在全局配置文件中添加vrrp iptables 表示不会自动添加iptables规则
在主节点启动keepalived服务
查看从节点主机抓取的报文信息:
16:26:42.725777 IP 192.168.32.130 > 224.0.45.1: VRRPv2, Advertisement, vrid 55, prio 98, authtype simple, intvl 1s, length 20
16:26:43.728074 IP 192.168.32.129 > 224.0.45.1: VRRPv2, Advertisement, vrid 55, prio 100, authtype simple, intvl 1s, length 20
发现主节点会自动代替从节点,因为其权限为100
查看从节点主机keepalived服务状态
Nov 17 16:26:42 k2.magedu.com Keepalived_vrrp[50032]: VRRP_Instance(VI_1) Received advert with higher priority 100, ours 98 #接收优先级100的通告报文
Nov 17 16:26:42 k2.magedu.com Keepalived_vrrp[50032]: VRRP_Instance(VI_1) Entering BACKUP STATE #自动进入从节点状态
Nov 17 16:26:42 k2.magedu.com Keepalived_vrrp[50032]: VRRP_Instance(VI_1) removing protocol VIPs. #自动移除vip地址
Nov 17 16:26:42 k2.magedu.com Keepalived_vrrp[50032]: VRRP_Instance(VI_1) removing protocol iptable drop rule #自动移动添加的iptables规则
此时vip地址192.168.32.200自动转移到主节点上
KeepAlived双主配置
示例:KeepAlived双主配置
主节点配置:
! Configuration File for keepalived
global_defs {
notification_email {
root@localhost #接收邮件通知的地址
}
notification_email_from keepalived@localhost #发件人地址,可以随便冒充,有没有该用户都可以
smtp_server 127.0.0.1 #指定真正的邮件服务器,这里实验以本机ip为例
smtp_connect_timeout 30
router_id k1 #当前物理设备的物理主机名
vrrp_skip_check_adv_addr #跳过检查通告地址
vrrp_strict #工作于严格模式下
vrrp_garp_interval 0
vrrp_iptables #当启动keepalived服务时,会自动在iptables中INPUT链增加一条防火墙规则:拒绝所有ip地址访问本机,防止其他主机通过访问本机对后端主机产生危害。添加vrrp_iptables 表示不会自动添加iptables规则
vrrp_gna_interval 0
vrrp_mcast_group4 224.0.45.1 #组播地址
}
注意:要查看本机是否支持组播,使用ifconfig查看是否出现MULTICAST字样,如果没有出现,进行以下设置开启组播:ip link set ens32
vrrp_instance VI_1 { #定义虚拟路由器实例VI_1的主节点,名称可自定义
state MASTER #定义初始状态,该节点为MASTER,其他节点必须为BACKUP
interface ens33 #虚拟ip地址接口
virtual_router_id 55 #虚拟路由id
priority 100 #主节点权限为100,其他节点必须低于该权限值
advert_int 1
authentication {
auth_type PASS #明文认证
auth_pass 1212 #密码默认为1111,可自定义
}
virtual_ipaddress { #配置VIP地址
192.168.32.200/16 brd 192.168.255.255 dev ens33 label ens33:0 #指定实例1的VIP地址,广播地址,网卡,别名
}
}
vrrp_instance VI_2 { #定义虚拟路由器实例VI_2的从节点
state BACKUP #初始状态必须与示例1不同为,作为实例2的BACKUP
interface ens33
virtual_router_id 57 #虚拟路由器id号必须与实例1区分开
priority 98 #定义实例2的优先级,从节点需要小于100
advert_int 1
authentication {
auth_type PASS
auth_pass 3232
}
virtual_ipaddress {
192.168.32.201/16 brd 192.168.255.255 dev ens33 label ens33:1 #指定示例2的VIP地址,广播地址,网卡,别名。注意VIP地址,别名要与实例1区分开
}
}
从节点配置:
! Configuration File for keepalived
global_defs {
notification_email {
root@localhost
}
notification_email_from keepalived@localhost
smtp_server 127.0.0.1
smtp_connect_timeout 30
router_id k1
vrrp_skip_check_adv_addr
vrrp_strict
vrrp_garp_interval 0
vrrp_iptables
vrrp_gna_interval 0
vrrp_mcast_group4 224.0.45.1
}
vrrp_instance VI_1 {
state BACKUP #指定初始状态
interface ens33
virtual_router_id 55
priority 98
advert_int 1
authentication {
auth_type PASS
auth_pass 1212
}
virtual_ipaddress {
192.168.32.200/16 brd 192.168.255.255 dev ens33 label ens33:0 #VIP地址不变,网卡名称根据本机网卡名称进行更改
}
}
vrrp_instance VI_2 {
state MASTER
interface ens33
virtual_router_id 57
priority 100
advert_int 1
authentication {
auth_type PASS
auth_pass 3232
}
virtual_ipaddress {
192.168.32.201/16 brd 192.168.255.255 dev ens33 label ens33:1
}
}
注意:双主模式中,192.168.32.200为实例1的VIP地址,且192.168.32.129主机在实例1权限为100,因此该vip地址在192.168.32.129主机上;
而192.168.32.201为实例2的VIP地址,且192.168.32.130主机在实例2权限为100,因此该vip地址在192.168.32.130主机上
keepalived可以高可用不需要存储服务的调度器服务,如haproxy,nginx,或者高可用其他集群服务中用于接入用户请求,但本地不存储状态的无状态服务,如k8s中的API server
- 邮件通知告警
全局邮件告警
自定义脚本,调用脚本进行通知 - 通知脚本的使用方式:
通知脚本
cd /etc/keepalived/
vim notify.sh
#!/bin/bash
#
contact='root@localhost' #邮件接收者
notify() { #定义函数
local mailsubject="$(hostname) to be $1, vip floating" #定义邮件标题
local mailbody="$(date +'%F %T'): vrrp transition, $(hostname) changed to be $1" #定义邮件实体
echo "$mailbody" | mail -s "$mailsubject" $contact
}
case $1 in
master)
notify master
;;
backup)
notify backup
;;
fault)
notify fault
;;
*)
echo "Usage: $(basename $0) {master|backup|fault}"
exit 1
;;
esac
- 脚本的调用方法:
在主从节点配置文件中vrrp_instance VI_1 语句块最后面加下面行
notify_master “/etc/keepalived/notify.sh master”
notify_backup “/etc/keepalived/notify.sh backup”
notify_fault “/etc/keepalived/notify.sh fault”
示例:使用邮件告警
主节点配置文件:
vrrp_instance VI_1 {
state MASTER
interface ens33
virtual_router_id 55
priority 100
advert_int 1
authentication {
auth_type PASS
auth_pass 1212
}
virtual_ipaddress {
192.168.32.200/16 brd 192.168.255.255 dev ens33 label ens33:0
}
notify_master "/etc/keepalived/notify.sh master"
notify_master "/etc/keepalived/notify.sh master"
notify_fault "/etc/keepalived/notify.sh fault"
}
重启服务
systemctl restart keepalived
从节点配置文件:
vrrp_instance VI_1 {
state BACKUP
interface ens33
virtual_router_id 55
priority 98
advert_int 1
authentication {
auth_type PASS
auth_pass 1212
}
virtual_ipaddress {
192.168.32.200/16 brd 192.168.255.255 dev ens33 label ens33:0
}
notify_master "/etc/keepalived/notify.sh master"
notify_master "/etc/keepalived/notify.sh master"
notify_fault "/etc/keepalived/notify.sh fault"
}
重启服务
systemctl restart keepalived
当keepalived服务状态发生变化时,查看邮件服务器或本机(以实验为例)的邮件,可以看到通过脚本发送得状态转换信息
4、KeepAlived支持IPVS
- 虚拟服务器:
- 配置参数:
virtual_server IP port | virtual_server fwmark int
{
…
real_server {
…
}
…
} - 常用参数
delay_loop:检查后端服务器的时间间隔
lb_algo rr|wrr|lc|wlc|lblc|sh|dh:定义调度方法
lb_kind NAT|DR|TUN:集群的类型
persistence_timeout:持久连接时长
protocol TCP:服务协议,仅支持TCP
sorry_server:所有RS故障时,备用服务器地址
real_server
{
weightRS权重
notify_up| RS上线通知脚本
notify_down| RS下线通知脚本
HTTP_GET|SSL_GET|TCP_CHECK|SMTP_CHECK|MISC_CHEC K { … }:定义当前主机的健康状态检测方法
}
KeepAlived配置检测
- HTTP_GET|SSL_GET:应用层检测
HTTP_GET|SSL_GET {
url {
path:定义要监控的URL
status_code:判断上述检测机制为健康状态的响应码
digest:判断为健康状态的响应的内容的校验码
}
connect_timeout:连接请求的超时时长
nb_get_retry:重试次数
delay_before_retry:重试之前的延迟时长
connect_ip:向当前RS哪个IP地址发起健康状态检测请求
connect_port:向当前RS的哪个PORT发起健康状态检测请求
bindto:发出健康状态检测请求时使用的源地址
bind_port:发出健康状态检测请求时使用的源端口
} - 传输层检测 TCP_CHECK
TCP_CHECK {
connect_ip:向当前RS的哪个IP地址发起健康状态检测请求
connect_port:向当前RS的哪个PORT发起健康状态检测请求
bindto:发出健康状态检测请求时使用的源地址
bind_port:发出健康状态检测请求时使用的源端口
connect_timeout:连接请求的超时时长
}
示例:单主模型IPVS集群
以集群lvs-dr模式为例
实验环境:
虚拟路由器中两台物理服务器充当物理路由器分别是K1,K2
K1 192.168.32.129
K2 192.168.32.130
后端服务器RS1 192.168.32.131
后端服务器RS2 192.168.32.132
客户端:192.168.32.128
准备工作:
在keepalived主从节点(lvs调度器本身)设置sorry server
当启用nginx服务时,会自动监听80端口,这样还能否通过80端口做集群服务呢。
是可以的,因为客户端通过80端口访问后端服务器的所有请求首先通过VIP地址,通过PREROUTING链,然后才到达INPUT链,最后到达用户空间被nginx进程收到,但是一旦配置集群服务后,访问请求在达到INPUT之前就被ipvs模块转发出去,因此nginx无论是否监听80端口,都收不到报文请求,只有在后端服务器全部down掉之后,才会被转发给lvs调度器自身的nginx进程,因此本机开启nginx服务监听80端口并不影响集群服务
设置sorry server测试页面
K1:
安装nginx服务
设置测试页:
vim /usr/share/nginx/html/index.html
K1 Sorry Server!
K2:
安装nginx服务
设置测试页:
vim /usr/share/nginx/html/index.html
K2 Sorry Server!
设置后端服务器测试页面
RS1:
安装nginx服务
设置测试页:
vim /usr/share/nginx/html/index.html
RS1 Sorry Server!
RS2:
安装nginx服务
设置测试页:
vim /usr/share/nginx/html/index.html
RS2 Sorry Server!
测试:测试集群服务能够正常工作
配置脚本完成配置工作
vim lvs_dr_rs.sh
#!/bin/bash
#Author:wangxiaochun
#Date:2017-08-13
vip=192.168.32.200 #指定VIP地址变量
mask='255.255.255.255' #指定掩码的变量,为32位,本网段只有一个ip地址
dev=lo:1 #指定本地环回接口的变量
case $1 in
start) #写配置文件使环回接口不宣告不回应arp广播包
echo 1 > /proc/sys/net/ipv4/conf/all/arp_ignore
echo 1 > /proc/sys/net/ipv4/conf/lo/arp_ignore
echo 2 > /proc/sys/net/ipv4/conf/all/arp_announce
echo 2 > /proc/sys/net/ipv4/conf/lo/arp_announce
ifconfig $dev $vip netmask $mask broadcast $vip up #把VIP地址绑定到本地lo网卡,并启用广播功能
route add -host $vip $dev #添加路由:如果是请求VIP地址的请求通过lo网卡进入(可省略)
echo "The RS Server is Ready!"
;;
stop) #取消写入配置文件的参数
ifconfig $dev down
echo 0 > /proc/sys/net/ipv4/conf/all/arp_ignore
echo 0 > /proc/sys/net/ipv4/conf/lo/arp_ignore
echo 0 > /proc/sys/net/ipv4/conf/all/arp_announce
echo 0 > /proc/sys/net/ipv4/conf/lo/arp_announce
echo "The RS Server is Canceled!"
;;
*)
echo "Usage: $(basename $0) start|stop"
exit 1
;;
esac
在RS1和RS2上分别执行此脚本
bash bash lvs_dr_rs.sh start
在K1服务器配置lvs调度规则,测试是否能通
在K1服务器绑定VIP到ens33网卡子接口
ifconfig ens33:0 192.168.32.200 netmask 255.255.255.255 broadcast 192.168.32.200 up
配置ipvs规则
ipvsadm -A -t 192.168.32.200:80 -s wrr
ipvsadm -a -t 192.168.32.200:80 -r 192.168.32.131 -g
ipvsadm -a -t 192.168.32.200:80 -r 192.168.32.132 -g
在客户端测试是否能够正常工作
while true ;do curl http://192.168.32.200;sleep 0.5;done;
如果能够通过wrr算法调度成功说明K1作为lvs调度器没有问题
删除ipvs规则,删除绑定ens33:0接口的ip地址
在K2服务器上做同样的操作以测试K2作为lvs服务器是否可以正常调度
K1服务器(lvs调度器1)配置:
[root@k1 ~]# vim /etc/keepalived/keepalived.conf
! Configuration File for keepalived
global_defs {
notification_email {
root@localhost
}
notification_email_from keepalived@localhost
smtp_server 127.0.0.1
smtp_connect_timeout 30
router_id k1
vrrp_skip_check_adv_addr
vrrp_strict
vrrp_garp_interval 0
vrrp_iptables
vrrp_gna_interval 0
vrrp_mcast_group4 224.0.45.1
}
vrrp_instance VI_1 {
state MASTER
interface ens33
virtual_router_id 55
priority 100
advert_int 1
authentication {
auth_type PASS
auth_pass 1212
}
virtual_ipaddress {
192.168.32.200/16 brd 192.168.255.255 dev ens33 label ens33:0
}
notify_master "/etc/keepalived/notify.sh master"
notify_master "/etc/keepalived/notify.sh master"
notify_fault "/etc/keepalived/notify.sh fault"
}
virtual_server 192.168.32.200 80 {
delay_loop 2
lb_algo wrr
lb_kind DR
protocol TCP
sorry_server 127.0.0.1 80
real_server 192.168.32.131 80 {
weight 1
HTTP_GET {
url {
path /
status_code 200
}
connect_timeout 1
nb_get_retry 3
delay_before_retry 1
}
}
real_server 192.168.32.132 80 {
weight 1
HTTP_GET {
url {
path /
status_code 200
}
connect_timeout 1
nb_get_retry 3
delay_before_retry 1
}
}
}
K2服务器(lvs调度器2)配置:
[root@k2 html]# vim /etc/keepalived/keepalived.conf
! Configuration File for keepalived
global_defs { #全局配置
notification_email {
root@localhost
}
notification_email_from keepalived@localhost
smtp_server 127.0.0.1
smtp_connect_timeout 30
router_id k1
vrrp_skip_check_adv_addr
vrrp_strict
vrrp_garp_interval 0
vrrp_iptables
vrrp_gna_interval 0
vrrp_mcast_group4 224.0.45.1
}
vrrp_instance VI_1 { #虚拟路由器实例1配置
state BACKUP
interface ens33
virtual_router_id 55
priority 98
advert_int 1
authentication {
auth_type PASS
auth_pass 1212
}
virtual_ipaddress {
192.168.32.200/16 brd 192.168.255.255 dev ens33 label ens33:0
}
notify_master "/etc/keepalived/notify.sh master"
notify_master "/etc/keepalived/notify.sh master"
notify_fault "/etc/keepalived/notify.sh fault"
}
virtual_server 192.168.32.200 80 { #虚拟服务器配置
delay_loop 2
lb_algo wrr
lb_kind DR
protocol TCP
sorry_server 127.0.0.1 80
real_server 192.168.32.131 80 { #后端服务器(real server)1配置
weight 1
HTTP_GET {
url {
path /
status_code 200
}
connect_timeout 1
nb_get_retry 3
delay_before_retry 1
}
}
real_server 192.168.32.132 80 { #后端服务器(real server)2配置
weight 1
HTTP_GET {
url {
path /
status_code 200
}
connect_timeout 1
nb_get_retry 3
delay_before_retry 1
}
}
}
注意:如果想要实现双主模型,则需要配置两个虚拟路由实例,使用两个虚拟ip地址(即VIP),在后端服务器配置基于FQDN的网页
在客户端基于域名访问时,能够实现负载均衡
重启keepalived服务
查看vip地址是否存在
查看ipvs规则是否已经生成
测试:
测试ipvs调度规则
关闭后端服务器,查看调度情况
关闭所有后端服务器,查看sorry server情况
测试keepalived主备
关闭K1或K2中keepalived服务,查看是否能够实现ip地址转移
关闭后端服务器,查看是否能够实现健康状态检测,自动切换
注意:
如果是集群lvs-nat模式,要配置同步组,在面对互联网的接口配置VIP,在面对内网的接口也要配置VIP,并且两个VIP要在同一个主机之上
如果使用lvs-nat的场景,推荐使用nginx或haproxy,复杂度更低,使用更高级的其他功能
同步组
- LVS NAT模型VIP和DIP需要同步,需要同步组
vrrp_sync_group VG_1 {
group {
VI_1 # name of vrrp_instance (below)
VI_2 # One for each moveable IP.
}
}
vrrp_instance VI_1 {
eth0
vip
}
vrrp_instance VI_2 {
eth1
dip
}
双主模式的lvs集群
双主模式的lvs集群,拓扑、实现过程;
配置示例(一个节点):
! Configuration File for keepalived
global_defs {
notification_email {
root@localhost
}
notification_email_from kaadmin@localhost
smtp_server 127.0.0.1
smtp_connect_timeout 30
router_id node1
vrrp_mcast_group4 224.0.100.100
}
vrrp_instance VI_1 {
state MASTER
interface eth0
virtual_router_id 6
priority 100
advert_int 1
authentication {
auth_type PASS
auth_pass f1bf7fde
}
virtual_ipaddress {
172.16.0.80/16 dev eth0 label eth0:0
}
track_interface {
eth0
}
notify_master "/etc/keepalived/notify.sh master"
notify_backup "/etc/keepalived/notify.sh backup"
notify_fault "/etc/keepalived/notify.sh fault"
}
vrrp_instance VI_2 {
state BACKUP
interface eth0
virtual_router_id 8
priority 98
advert_int 1
authentication {
auth_type PASS
auth_pass f2bf7ade
}
virtual_ipaddress {
172.16.0.90/16 dev eth0 label eth0:1
}
track_interface {
eth0
}
notify_master "/etc/keepalived/notify.sh master"
notify_backup "/etc/keepalived/notify.sh backup"
notify_fault "/etc/keepalived/notify.sh fault"
}
virtual_server fwmark 3 {
delay_loop 2
lb_algo rr
lb_kind DR
nat_mask 255.255.0.0
protocol TCP
sorry_server 127.0.0.1 80
real_server 172.16.0.11 80 {
weight 1
HTTP_GET {
url {
path /
status_code 200
}
connect_timeout 2
nb_get_retry 3
delay_before_retry 3
}
}
real_server 172.16.0.12 80 {
weight 1
HTTP_GET {
url {
path /
status_code 200
}
connect_timeout 2
nb_get_retry 3
delay_before_retry 3
}
}
}
KeepAlived调用脚本进行资源监控
- 查看man帮助
VRRP script(s)
# Adds a script to be executed periodically. Its exit code will be
# recorded for all VRRP instances which are monitoring it.
vrrp_script { #脚本名称
script | #指定脚本内容,可以是命令本身,如果是复杂脚本,需要指定脚本路径
interval #每隔多久执行一次,周期性执行脚本,监测外部关键资源是否正常
timeout #每一次监测请求超时时长
weight #权重-254~254,默认为0。
针对于某一实例来说,根据当前设置调整当前节点优先级是多少,这里的优先级是指虚拟路由器中节点的优先级。
如,定义优先级为10,如果脚本执行失败,那么该节点的优先级减去10
rise #至少有几次启动时状态监测为成功才会判定为成功
fall #至少有几次启动时状态检测为不成功才会判定为失败
user USERNAME [GROUPNAME] #以哪个用户的身份执行脚本
init_fail #认为脚本初始状态应该为失败状态,只有检查以后为成功,才会将其置为成功状态
}
- keepalived调用外部的辅助脚本进行资源监控,并根据监控的结果状态能实现优先动态调整
- vrrp_script:自定义资源监控脚本,vrrp实例根据脚本返回值,公共定义,可被多个实例调用,定义在vrrp实例之外
- track_script:调用vrrp_script定义的脚本去监控资源,定义在实例之内,调用事先定义的vrrp_script
- 分两步:(1) 先定义一个脚本;(2) 调用此脚本
vrrp_script {
script ""
interval INT
weight -INT
rise 2
fall 3
}
track_script {
SCRIPT_NAME_1
SCRIPT_NAME_2
...
}
注意:
vrrp_script chk_down {
script "/bin/bash -c '[[ -f /etc/keepalived/down ]]' && exit 1 || exit 0"
interval 1
weight -10
}
[[ -f /etc/keepalived/down ]]要特别地作为bash的参数的运行!
示例:使用脚本进行资源监控
主节点配置:
[root@k1 ~]# vim /etc/keepalived/keepalived.conf
global_defs {
notification_email {
root@localhost
}
notification_email_from keepalived@localhost
smtp_server 127.0.0.1
smtp_connect_timeout 30
router_id k1
vrrp_skip_check_adv_addr
vrrp_strict
vrrp_garp_interval 0
vrrp_iptables
vrrp_gna_interval 0
vrrp_mcast_group4 224.0.45.1
}
vrrp_script maint { #定义脚本maint
script " "/bin/bash -c '[[ -e /etc/keepalived/down ]]' && exit 1
|| exit 0" #当存在/etc/keepalived/down文件时返回1(失败),否则返回0(成功)。注意:"-e /etc/keepalived/down"命令字串在新版本keepalived配置文件中,默认不会开启shell执行,因此需要'/bin/bash -c'指定
interval 1
fall 3
rise 2
weight -5 #如果返回失败,则权重值减5,结果为95小于从节点优先级98,即实现自动降级
timeout 1
}
vrrp_instance VI_1 {
state MASTER
interface ens33
virtual_router_id 55
priority 100
advert_int 1
authentication {
auth_type PASS
auth_pass 1212
}
virtual_ipaddress {
192.168.32.200/16 brd 192.168.255.255 dev ens33 label ens33:0
}
track script { #在虚拟路由器实例1中调用脚本
maint
}
notify_master "/etc/keepalived/notify.sh master"
notify_master "/etc/keepalived/notify.sh master"
notify_fault "/etc/keepalived/notify.sh fault"
}
从节点配置:
[root@k2 ~]# vim /etc/keepalived/keepalived.conf
global_defs {
notification_email {
root@localhost
}
notification_email_from keepalived@localhost
smtp_server 127.0.0.1
smtp_connect_timeout 30
router_id k1
vrrp_skip_check_adv_addr
vrrp_strict
vrrp_garp_interval 0
vrrp_iptables
vrrp_gna_interval 0
vrrp_mcast_group4 224.0.45.1
}
vrrp_script maint { #定义脚本
script " "/bin/bash -c '[[ -e /etc/keepalived/down ]]' && exit 1
|| exit 0" #当存在/etc/keepalived/down文件时返回1(失败),否则返回0(成功)。注意:"-e /etc/keepalived/down"命令字串在新版本keepalived配置文件中,默认不会开启shell执行,因此需要'/bin/bash -c'指定
interval 1
fall 3
rise 2
weight -5 #如果返回失败,则权重值减5,结果为95小于从节点优先级98,即实现自动降级
timeout 1
}
vrrp_instance VI_1 {
state BACKUP
interface ens33
virtual_router_id 55
priority 98
advert_int 1
authentication {
auth_type PASS
auth_pass 1212
}
virtual_ipaddress {
192.168.32.200/16 brd 192.168.255.255 dev ens33 label ens33:0
}
track script { #调用脚本
maint
}
notify_master "/etc/keepalived/notify.sh master"
notify_master "/etc/keepalived/notify.sh master"
notify_fault "/etc/keepalived/notify.sh fault"
}
测试:
在K1服务抓包查看报文转发信息
tcpdump -i ens33 -nn host 224.0.45.1
在主节点K1服务器
在/etc/keepalived目录下创建down文件
cd /etc/keepalived
touch down
查看是否会实现自动降级(查看抓包信息或日志信息)
K1服务器抓包信息如下:
09:54:43.889550 IP 192.168.32.129 > 224.0.45.1: VRRPv2, Advertisement, vrid 55, prio 100, authtype simple, intvl 1s, length 20
09:54:44.891154 IP 192.168.32.129 > 224.0.45.1: VRRPv2, Advertisement, vrid 55, prio 95, authtype simple, intvl 1s, length 20
09:54:44.892227 IP 192.168.32.130 > 224.0.45.1: VRRPv2, Advertisement, vrid 55, prio 98, authtype simple, intvl 1s, length 20
K1服务器日志信息如下:
Nov 18 09:54:41 centos7 Keepalived_vrrp[12448]: /bin/bash -c '[[ -e /etc/keepalived/down ]]' && exit 1 || exit 0 exited with status 1
Nov 18 09:54:42 centos7 Keepalived_vrrp[12448]: /bin/bash -c '[[ -e /etc/keepalived/down ]]' && exit 1 || exit 0 exited with status 1
Nov 18 09:54:43 centos7 Keepalived_vrrp[12448]: /bin/bash -c '[[ -e /etc/keepalived/down ]]' && exit 1 || exit 0 exited with status 1
Nov 18 09:54:43 centos7 Keepalived_vrrp[12448]: VRRP_Script(maint) failed
Nov 18 09:54:44 centos7 Keepalived_vrrp[12448]: VRRP_Instance(VI_1) Changing effective priority from 100 to 95 #权限减5
Nov 18 09:54:44 centos7 Keepalived_vrrp[12448]: /bin/bash -c '[[ -e /etc/keepalived/down ]]' && exit 1 || exit 0 exited with status 1 #退出码为1
Nov 18 09:54:44 centos7 Keepalived_vrrp[12448]: VRRP_Instance(VI_1) Received advert with higher priority 98, ours 95 #从节点权限98高于降级后的主节点权限95
Nov 18 09:54:44 centos7 Keepalived_vrrp[12448]: VRRP_Instance(VI_1) Entering BACKUP STATE #主节点切换为BACKUP状态
Nov 18 09:54:44 centos7 Keepalived_vrrp[12448]: VRRP_Instance(VI_1) removing protocol VIPs. #转移VIP
Nov 18 09:54:44 centos7 avahi-daemon[575]: Withdrawing address record for 192.168.32.200 on ens33. #VIP地址192.168.32.200从ens33解除绑定
Nov 18 09:54:44 centos7 Keepalived_vrrp[12448]: VRRP_Instance(VI_1) removing protocol iptable drop rule #删除自动添加的iptables规则
在K2服务器(从节点)查看虚拟ip地址是否自动转移
[root@k2 ~]# ifconfig
ens33:0: flags=4163 mtu 1500
inet 192.168.32.200 netmask 255.255.0.0 broadcast 192.168.255.255
ether 00:0c:29:ca:4f:3d txqueuelen 1000 (Ethernet)
在/etc/keepalived目录下删除down文件,然后查看状态转换
cd /etc/keepalived
rm -rf down
示例:高可用nginx服务
使用nginx做代理服务器,如何实现nginx的高可用
写一个脚本,当nginx进程出现故障,自动实现对主节点自动降级,启动从节点代替主节点进行nginx代理
killall -0 相当于检测进程状态,如果有nginx进程存在能够承接kill操作(接收该信号),退出码为0,如果没有nginx进程能够承接kill操作(不能接收该信号),则退出码为非0值
该命令来自于psmisc软件包
示例:
[root@k1 keepalived]# systemctl start nginx
[root@k1 keepalived]# killall -0 nginx && echo $?
0
[root@k1 keepalived]# systemctl stop nginx
[root@k1 keepalived]# killall -0 nginx && echo $?
nginx: no process found
因此可利用'killall -0'检测nginx进程是否存在,如果存在返回码为0,主节点不变,一旦检测到nginx进程不存在,则返回码为非0,将主节点自动降级,实现VIP地址自动转移
另外,当主从节点状态切换时,会执行脚本(/etc/keepalived/notify.sh)自动发送邮件通知用户
并执行脚本发送邮件,我们可以在脚本(/etc/keepalived/notify.sh)中添加一条启动nginx进程的命令。
这样就可以实现,当nginx进程出现问题后,会自动切换状态并自行脚本发送邮件,当执行脚本时会执行重启nginx进程的命令,实现自动修复的效果
当主节点nginx服务重启不起来,那么从节点会成为主节点,代替主节点进行工作
主节点配置:
[root@k1 keepalived]# vim keepalived.conf
! Configuration File for keepalived
global_defs {
notification_email {
root@localhost
}
notification_email_from keepalived@localhost
smtp_server 127.0.0.1
smtp_connect_timeout 30
router_id k1
vrrp_skip_check_adv_addr
vrrp_iptables
vrrp_gna_interval 0
vrrp_mcast_group4 224.0.45.1
}
vrrp_script ngxchk { #添加nginx检测脚本
script "killall -0 nginx"
interval 1
fall 3
rise 2
weight -5
timeout 1
user root
}
vrrp_script maint {
script "/bin/bash -c '[[ -e /etc/keepalived/down ]]' && exit 1 ||
exit 0"
interval 1
fall 3
rise 2
weight -5
timeout 1
}
vrrp_instance VI_1 {
state MASTER
interface ens33
virtual_router_id 55
priority 100
advert_int 1
authentication {
auth_type PASS
auth_pass 1212
}
virtual_ipaddress {
192.168.32.200/16 brd 192.168.255.255 dev ens33 label ens33:0
}
track_script { #调用ngxchk脚本
maint
ngxchk
}
notify_master "/etc/keepalived/notify.sh master"
notify_master "/etc/keepalived/notify.sh backup"
notify_fault "/etc/keepalived/notify.sh fault"
}
从节点配置:
! Configuration File for keepalived
global_defs {
notification_email {
root@localhost
}
notification_email_from keepalived@localhost
smtp_server 127.0.0.1
smtp_connect_timeout 30
router_id k1
vrrp_skip_check_adv_addr
vrrp_iptables
vrrp_gna_interval 0
vrrp_mcast_group4 224.0.45.1
}
vrrp_script ngxchk { #nginx进程检测脚本
script "killall -0 nginx"
interval 1
fall 3
rise 2
weight -5
timeout 1
user root
}
vrrp_script maint {
script "/bin/bash -c '[[ -e /etc/keepalived/down ]]' && exit 1 ||
exit 0"
interval 1
fall 3
rise 2
weight -5
timeout 1
}
vrrp_instance VI_1 {
state BACKUP
interface ens33
virtual_router_id 55
priority 98
advert_int 1
authentication {
auth_type PASS
auth_pass 1212
}
virtual_ipaddress {
192.168.32.200/16 brd 192.168.255.255 dev ens33 label ens33:0
}
track_script { #调用ngxchk脚本
maint
ngxchk
}
notify_master "/etc/keepalived/notify.sh master"
notify_master "/etc/keepalived/notify.sh backup"
notify_fault "/etc/keepalived/notify.sh fault"
}
分别在主从节点上更改发送邮件的脚本
[root@k1 keepalived]# vim notify.sh
#!/bin/bash
#
contact='root@localhost'
notify() {
local mailsubject="$(hostname) to be $1, vip floating"
local mailbody="$(date +'%F %T'): vrrp transition, $(hostnam
e) changed to be $1"
echo "$mailbody" | mail -s "$mailsubject" $contact
}
case $1 in
master)
notify master
;;
backup)
notify backup
systemctl restart nginx #添加重启命令
;;
fault)
notify fault
;;
*)
echo "Usage: $(basename $0) {master|backup|fault}"
exit 1
;;
esac
注意:在这种情况下,当测试时我们关闭nginx服务进程,主节点K1服务器会自动降级,权限更改为95,从节点K2服务器会代替主节点K1,VIP地址从主节点K1转移到从节点K2,但当主节点K1转换状态并发送邮件时,会自动执行重启nginx服务的命令,此时原主节点K1的权限又会恢复到100重新成为主节点,VIP地址又会回到主节点K1。这样一来就会出现K1主节点上的VIP地址丢失,然后又获取的现象
启动K1 K2服务器中的nginx反向代理服务
重启主从节点的keepalived服务
测试:
停止主节点的nginx服务
killall nginx
在K1服务器查看抓包信息
11:28:17.154637 IP 192.168.32.129 > 224.0.45.1: VRRPv2, Advertisement, vrid 55, prio 100, authtype simple, intvl 1s, length 20
11:28:18.155907 IP 192.168.32.129 > 224.0.45.1: VRRPv2, Advertisement, vrid 55, prio 95, authtype simple, intvl 1s, length 20
11:28:18.157329 IP 192.168.32.130 > 224.0.45.1: VRRPv2, Advertisement, vrid 55, prio 98, authtype simple, intvl 1s, length 20
11:28:19.157937 IP 192.168.32.130 > 224.0.45.1: VRRPv2, Advertisement, vrid 55, prio 98, authtype simple, intvl 1s, length 20
11:28:20.161351 IP 192.168.32.130 > 224.0.45.1: VRRPv2, Advertisement, vrid 55, prio 98, authtype simple, intvl 1s, length 20
11:28:21.162631 IP 192.168.32.130 > 224.0.45.1: VRRPv2, Advertisement, vrid 55, prio 98, authtype simple, intvl 1s, length 20
11:28:21.162854 IP 192.168.32.129 > 224.0.45.1: VRRPv2, Advertisement, vrid 55, prio 100, authtype simple, intvl 1s, length 20
发现主节点权限从100变为95,然后从节点98权限变为主节点,但随后,主节点又重新变为100权限,说明nginx进程实现重启
注意:当在双主模式下,不能通过更改脚本来实现nginx进程的重启,因此双主模型中,涉及到多个实例,一个实例出现问题,并不意味着另外一个实例也出现问题,因此通过更改脚本方式实现nginx进程的重启会带来风险,不推荐此种做法