使用python爬取全国所有热门景点数据---去哪儿网
要爬取去哪儿上面的所有的热门景点的数据 可以先再 搜索出 搜索 热门景点
http://piao.qunar.com/ticket/list.htm?keyword=%E7%83%AD%E9%97%A8%E6%99%AF%E7%82%B9®ion=&from=mpl_search_suggest
可以看到 有几千页 的景点数据,我们要爬取的就是这些数据;

最好是从分类开始爬取:
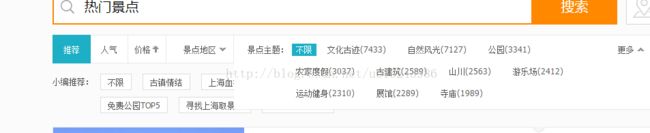
分析完之后现在就开始写python代码 爬取所有热门景点的数据 :
# -*- coding: utf-8 -*-
import requests
from bs4 import BeautifulSoup
import csv
from multiprocessing import Queue
import threading
import random
from time import sleep
User_Agent=["Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/51.0.2704.106 Safari/537.36","Mozilla/5.0 (Macintosh; U; Intel Mac OS X 10_6_8; en-us) AppleWebKit/534.50 (KHTML, like Gecko) Version/5.1 Safari/534.50","Mozilla/5.0 (Windows; U; Windows NT 6.1; en-us) AppleWebKit/534.50 (KHTML, like Gecko) Version/5.1 Safari/534.50","Mozilla/5.0 (Macintosh; Intel Mac OS X 10.6; rv:2.0.1) Gecko/20100101 Firefox/4.0.1","Mozilla/5.0 (Windows NT 6.1; rv:2.0.1) Gecko/20100101 Firefox/4.0.1"]
HEADERS = {
'User-Agent': User_Agent[random.randint(0,4)],
# 'User-Agent':'Mozilla/5.0 (Windows NT 6.1; WOW64; rv:55.0) Gecko/201002201 Firefox/55.0',
'Accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,*/*;q=0.8',
'Accept-Language': 'zh-CN,zh;q=0.8,en-US;q=0.5,en;q=0.3',
'Accept-Encoding': 'gzip, deflate, br',
'Cookie': '',
'Connection': 'keep-alive',
'Pragma': 'no-cache',
'Cache-Control': 'no-cache'
}
csvfile = open('去哪儿景点.csv','w',encoding='utf-8', newline='')
writer = csv.writer(csvfile)
writer.writerow(["区域","名称","景点id","类型","级别","热度","地址","特色","经纬度"])
def download_page(url): # 下载页面
try:
data = requests.get(url, headers=HEADERS, allow_redirects=True).content # 请求页面,获取要爬取的页面内容
return data
except:
pass
#下载页面 如果没法下载就 等待1秒 再下载
def download_soup_waitting(url):
try:
response= requests.get(url,headers=HEADERS,allow_redirects=False,timeout=5)
if response.status_code==200:
html=response.content
html=html.decode("utf-8")
soup = BeautifulSoup(html, "html.parser")
return soup
else:
sleep(1)
print("等待ing")
return download_soup_waitting(url)
except:
return ""
def getTypes():
types=["文化古迹","自然风光","公园","古建筑","寺庙","遗址","古镇","陵墓陵园","故居","宗教"] #实际不止这些分组 需要自己补充
for type in types:
url="http://piao.qunar.com/ticket/list.htm?keyword=%E7%83%AD%E9%97%A8%E6%99%AF%E7%82%B9®ion=&from=mpl_search_suggest&subject="+type+"&page=1"
getType(type,url)
def getType(type,url):
soup=download_soup_waitting(url)
search_list=soup.find('div', attrs={'id': 'search-list'})
sight_items=search_list.findAll('div', attrs={'class': 'sight_item'})
for sight_item in sight_items:
name=sight_item['data-sight-name']
districts=sight_item['data-districts']
point=sight_item['data-point']
address=sight_item['data-address']
data_id=sight_item['data-id']
level=sight_item.find('span',attrs={'class':'level'})
if level:
level=level.text
else:
level=""
product_star_level=sight_item.find('span',attrs={'class':'product_star_level'})
if product_star_level:
product_star_level=product_star_level.text
else:
product_star_level=""
intro=sight_item.find('div',attrs={'class':'intro'})
if intro:
intro=intro['title']
else:
intro=""
writer.writerow([districts.replace("\n",""),name.replace("\n",""),data_id.replace("\n",""),type.replace("\n",""),level.replace("\n",""),product_star_level.replace("\n",""),address.replace("\n",""),intro.replace("\n",""),point.replace("\n","")])
next=soup.find('a',attrs={'class':'next'})
if next:
next_url="http://piao.qunar.com"+next['href']
getType(type,next_url)
if __name__ == '__main__':
getTypes()
之后只要让它执行就好 如果发现 控制台中一直打印 等待ing 很有可能 ip被封了 只要使用代理换个ip就会继续爬取,
最后爬取出来的数据总共有 4,5万的数据:

如果需要这份数据 请联系 [email protected]