Spark Streaming消费Kafka数据的两种方案
下午的时候翻微信看到大家在讨论Spark消费Kafka的方式,官网中就有答案,只不过是英文的,当然很多博客也都做了介绍,正好我的收藏夹中有一篇文章供大家参考。文章写的通俗易懂,搭配代码,供大家参考。
本文的作者是来自TalkingData的数据工程师张伟。
SS 是 Spark 上的一个流式处理框架,可以面向海量数据实现高吞吐量、高容错的实时计算。SS 支持多种类型数据源,包括 Kafka、Flume、twitter、zeroMQ、Kinesis 以及 TCP sockets 等。SS 实时接收数据流,并按照一定的时间间隔(下文称为“批处理时间间隔”)将连续的数据流拆分成一批批离散的数据集;然后应用诸如 map、reduce、join 和 window 等丰富的 API 进行复杂的数据处理;最后提交给 Spark 引擎进行运算,得到批量结果数据,因此其也被称为准实时处理系统。而结果也能保存在很多地方,如 HDFS,数据库等。另外 SS 也能和 MLlib(机器学习)以及 GraphX(图计算)完美融合。

Spark Streaming 支持多种类型数据源
Spark Streaming 基础概念
DStream
Discretized Stream 是 SS 的基础抽象,代表持续性的数据流和经过各种 Spark 原语操作后的结果数据流。DStream 本质上是一个以时间为键,RDD 为值的哈希表,保存了按时间顺序产生的 RDD,而每个 RDD 封装了批处理时间间隔内获取到的数据。SS 每次将新产生的 RDD 添加到哈希表中,而对于已经不再需要的 RDD 则会从这个哈希表中删除,所以 DStream 也可以简单地理解为以时间为键的 RDD 的动态序列。如下图:

窗口时间间隔
窗口时间间隔又称为窗口长度,它是一个抽象的时间概念,决定了 SS 对 RDD 序列进行处理的范围与粒度,即用户可以通过设置窗口长度来对一定时间范围内的数据进行统计和分析。假如设置批处理时间间隔为 1s,窗口时间间隔为 3s。如下图,DStream 每 1s 会产生一个 RDD,红色边框的矩形框就表示窗口时间间隔,一个窗口时间间隔内最多有 3 个 RDD,Spark Streaming 在一个窗口时间间隔内最多会对 3 个 RDD 中的数据进行统计和分析。
滑动时间间隔
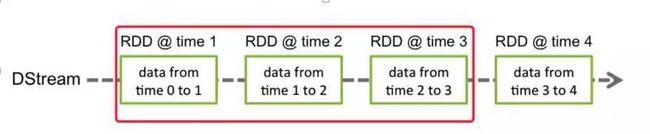
滑动时间间隔决定了 SS 程序对数据进行统计和分析的频率。它指的是经过多长时间窗口滑动一次形成新的窗口,滑动时间间隔默认情况下和批处理时间间隔相同,而窗口时间间隔一般设置的要比它们两个大。在这里必须注意的一点是滑动时间间隔和窗口时间间隔的大小一定得设置为批处理时间间隔的整数倍。
如下图,批处理时间间隔是 1 个时间单位,窗口时间间隔是 3 个时间单位,滑动时间间隔是 2 个时间单位。对于初始的窗口 time 1-time 3,只有窗口时间间隔满足了才触发数据的处理。这里需要注意的一点是,初始的窗口有可能覆盖的数据没有 3 个时间单位,但是随着时间的推进,窗口最终会覆盖到 3 个时间单位的数据。当每个 2 个时间单位,窗口滑动一次后,会有新的数据流入窗口,这时窗口会移去最早的两个时间单位的数据,而与最新的两个时间单位的数据进行汇总形成新的窗口(time3-time5)。
Spark Streaming 读取 Kafka 数据
Spark Streaming 与 Kafka 集成接收数据的方式有两种:
Receiver-based Approach
Direct Approach (No Receivers)
Receiver-based Approach
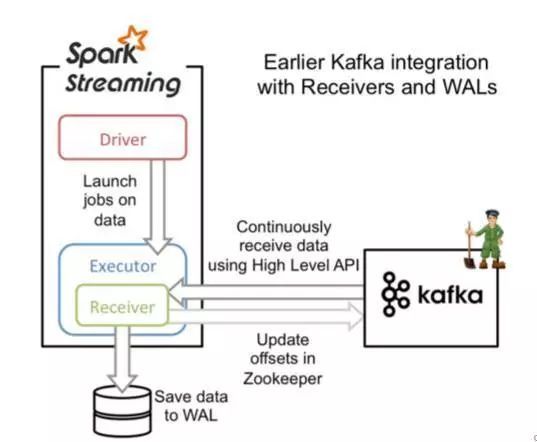
这个方法使用了 Receivers 来接收数据。Receivers 的实现使用到 Kafka 高级消费者 API。对于所有的 Receivers,接收到的数据将会保存在 Spark executors 中,然后由 SS 启动的 Job 来处理这些数据。
然而,在默认的配置下,这种方法在失败的情况下会丢失数据,为了保证零数据丢失,你可以在 SS 中使用 WAL 日志,这是在 Spark 1.2.0 才引入的功能,这使得我们可以将接收到的数据保存到 WAL 中(WAL 日志可以存储在 HDFS 上),所以在失败的时候,我们可以从 WAL 中恢复,而不至于丢失数据。
架构图如下:
使用方式:
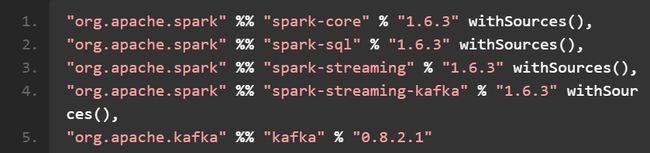
(1) 导入 Kafka 的 Spark Streaming 整合包
(2) 创建 DStream

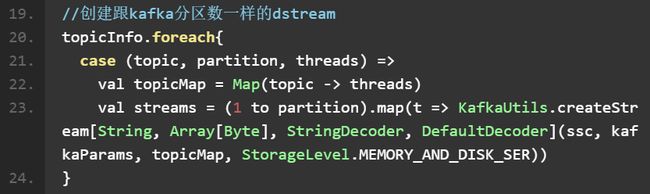
需要注意的几点:
1) Kafka 的 topic 和 partition 并不和 SS 生成的 RDD 的 partition 相对应,所以上面代码中 topicMap 里增加 threads 只能增加使用一个 receiver 消费这个 topic 的线程数,它并不能增加 Spark 处理数据的并行数,因为每个 input DStream 在一个 worker 机器上只创建一个接受单个数据流的 receiver。
2) 可以为不同 topic 和 group 创建多个 DStream 来使用多个 receiver 并行的接受数据。例如:一个单独的 Kafka input DStream 接受两个 topic 的数据可以分为两个 Kafka input DStream,每个只接受一个 topic 的数据,这样可以并行的接受速度从而提高整体吞吐量。
3) 如果开启了 wal 来保证数据不丢失话,需要设置 checkpoint 目录,并且像上面代码一样指定数据序列化到 hdfs 上的方式(比如:StorageLevel.MEMORY_AND_DISK_SER)
4) 建议每个批处理时间间隔周期接受到的数据最好不要超过接受 Executor 的内存 (Storage) 的一半。
要描述清楚 Receiver-based Approach ,我们需要了解其接收流程,分析其内存使用,以及相关参数配置对内存的影响。
数据接收流程
当执行 SS 的 start 方法后,SS 会标记 StreamingContext 为 Active 状态,并且单独起个线程通过 ReceiverTracker 将从 ReceiverInputDStreams 中获取的 receivers 以并行集合的方式分发到 worker 节点,并运行他们。worker 节点会启动 ReceiverSupervisor。接着按如下步骤处理:
1) ReceiverSupervisor 会启动对应的 Receiver(这里是 KafkaReceiver)
2) KafkaReceiver 会根据配置启动新的线程接受数据,在该线程中调用 ReceiverSupervisor.pushSingle 方法填充数据,注意,这里是一条一条填充的。
3) ReceiverSupervisor 会调用 BlockGenerator.addData 进行数据填充。
到目前为止,整个过程不会有太多内存消耗,正常的一个线性调用。所有复杂的数据结构都隐含在 BlockGenerator 中。
BlockGenerator 存储结构
BlockGenerator 会复杂些,重要的数据存储结构有四个:
1) 维护了一个缓存 currentBuffer ,这是一个变长的数组的 ArrayBuffer。currentBuffer 并不会被复用,而是每个 spark.streaming.blockInterval 都会新建一个空的变长数据替换老的数据作为新的 currentBuffer,然后把老的对象直接封装成 Block 放入到 blocksForPushing 的队列里,BlockGenerator 会负责保证 currentBuffer 只有一个。currentBuffer 填充的速度是可以被限制的,以秒为单位,配置参数为 spark.streaming.receiver.maxRate,是单个 Receiver 每秒钟允许添加的条数。这个是 Spark 内存控制的第一步,填充 currentBuffer 是阻塞的,消费 Kafka 的线程直接做填充。
2) 维护了一个 blocksForPushing 的阻塞队列,size 默认为 10 个 (1.6.3 版本),可通过 spark.streaming.blockQueueSize 进行配置。该队列主要用来实现生产 - 消费模式,每个元素其实是一个 currentBuffer 形成的 block。
3) blockIntervalTimer 是一个定时器。其实是一个生产者,负责将当前 currentBuffer 的数据放到 blocksForPushing 中,并新建一个 currentBuffer。通过参数 spark.streaming.blockInterval 设置,默认为 200ms。放的方式很简单,直接把 currentBuffer 做为 Block 的数据源。这就是为什么 currentBuffer 不会被复用。
4) blockPushingThread 也是一个定时器,负责将 Block 从 blocksForPushing 取出来,
然后交给 BlockManagerBasedBlockHandler.storeBlock。10 毫秒会取一次,不可配置。到这一步,才真的将数据放到了 Spark 的 BlockManager 中。
下面我们会详细分析每一个存储对象对内存的使用情况:
currentBuffer
首先自然要说下 currentBuffer,它缓存的数据会被定时器每隔 spark.streaming.blockInterval(默认 200ms)的时间拿走,这个缓存用的是 Spark 的运行时内存(我们使用的是静态内存管理模式,默认应该是 heap *0.2,如果是统一内存管理模式的话应该是 heap*0.25),而不是 storage 内存。如果 200ms 期间你从 Kafka 接受的数据足够大,则这部分内存很容易 OOM 或者进行大量的 GC,导致 receiver 所在的 Executor 极容易挂掉或者处理速度也很慢。如果你在 SparkUI 发现 Receiver 挂掉了,考虑有没有可能是这个问题。
blocksForPushing
blocksForPushing 这个是作为 currentBuffer 和 BlockManager 之间的中转站。默认存储的数据最大可以达到 10*currentBuffer 大小。一般不大可能有问题,除非你的 spark.streaming.blockInterval 设置的比 10ms 还小,官方推荐最小也要设置成 50ms,只要你不设置的过大,这块不用太担心。
blockPushingThread
blockPushingThread 负责从 blocksForPushing 获取数据,并且写入 BlockManager。blockPushingThread 只写他自己所在的 Executor 的 blockManager, 也就是一个 receiver 每个批处理时间间隔周期的数据都会被一个 Executor 接收。 这是导致内存被撑爆的最大风险,在数据量很大的情况下,会导致 Receiver 所在的 Executor 直接挂掉。
对应的解决方案在上面需要注意的建议 4) 有提到,也可以使用多个 Receiver 来消费同一个 topic,降低每个 receiver 接收的数据量, 使用类似下面的代码
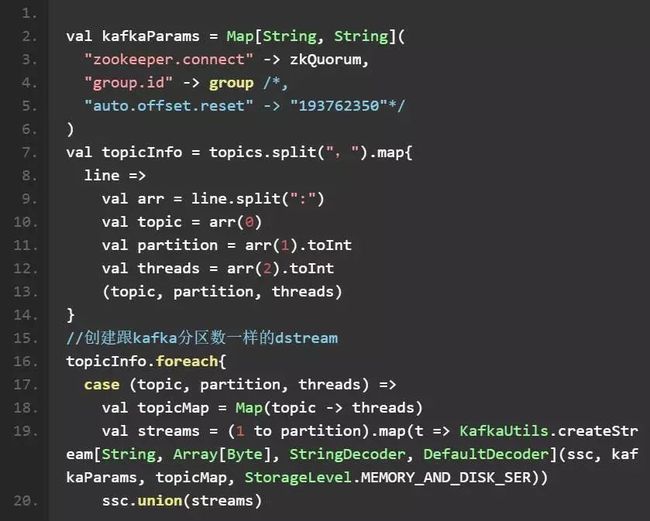
前面我们提到,SS 的消费速度可以设置上限,其实 SS 也可以根据之前的周期处理情况来自动调整下一个周期处理的数据量。你可以通过将 spark.streaming.backpressure.enabled 设置为 true 打开该功能。算法的论文可参考: Socc 2014: Adaptive Stream Processing using Dynamic Batch Sizing , 还是有用的,我现在也都开启着。 另外,Spark 里除了这个 Dynamic, 还有一个就是 Dynamic Allocation, 也就是 Executor 数量会根据资源使用情况,自动分配资源。具体见官网文档。
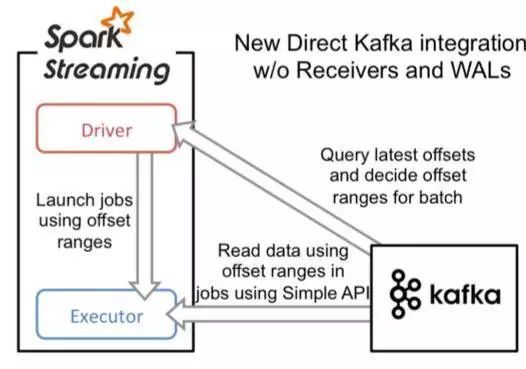
Direct Approach (No Receivers)
和基于 Receiver 接收数据不一样,这种方式定期地从 Kafka 的 topic+partition 中查询最新的偏移量,再根据定义的偏移量范围在每个批处理时间间隔里面处理数据。当作业需要处理的数据来临时,Spark 通过调用 Kafka 的低级消费者 API 读取一定范围的数据。这个特性目前还处于试验阶段,而且仅仅在 Scala 和 Java 语言中提供相应的 API。
和基于 Receiver 方式相比,这种方式主要有一些几个优点:
(1)简化并行。
我们不需要创建多个 Kafka 输入流,然后 union 他们。而使用 DirectStream,SS 将会创建和 Kafka 分区一样的 RDD 分区个数,而且会从 Kafka 并行地读取数据,也就是说 Spark 分区将会和 Kafka 分区有一一对应的关系,这对我们来说很容易理解和使用;
(2)高效。
第一种实现零数据丢失是通过将数据预先保存在 WAL 中,这将会复制一遍数据,这种方式实际上很不高效,因为这导致了数据被拷贝两次:一次是被 Kafka 复制;另一次是写到 WAL 中。但是本方法因为没有 Receiver,从而消除了这个问题,所以不需要 WAL 日志;
(3)恰好一次语义(Exactly-once semantics)。
第一种实现中通过使用 Kafka 高层次的 API 把偏移量写入 Zookeeper 中,这是读取 Kafka 中数据的传统方法。虽然这种方法可以保证零数据丢失,但是还是存在一些情况导致数据会丢失,因为在失败情况下通过 SS 读取偏移量和 Zookeeper 中存储的偏移量可能不一致。而本文提到的方法是通过 Kafka 低层次的 API,并没有使用到 Zookeeper,偏移量仅仅被 SS 保存在 Checkpoint 中。这就消除了 SS 和 Zookeeper 中偏移量的不一致,而且可以保证每个记录仅仅被 SS 读取一次,即使是出现故障。
但是本方法唯一的坏处就是没有更新 Zookeeper 中的偏移量,所以基于 Zookeeper 的 Kafka 监控工具将会无法显示消费的状况。但是你可以通过自己手动地将偏移量写入到 Zookeeper 中。
架构图如下:
使用方式:
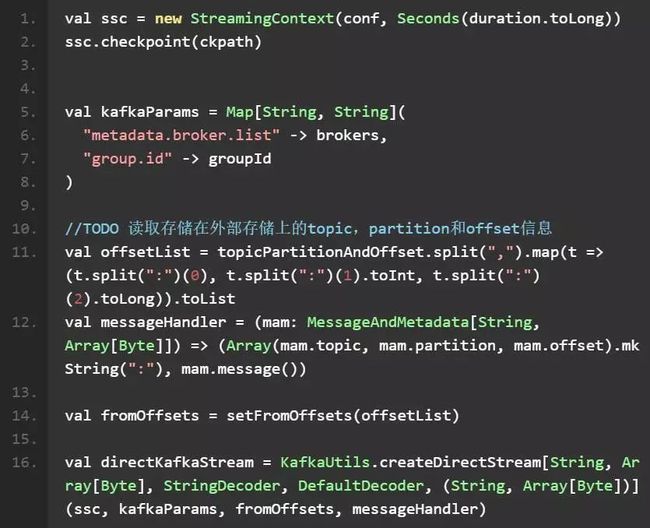
其中 fromOffsets 是指定的 topic 和 partition 开始读取的 offset 起始值,方法如下:
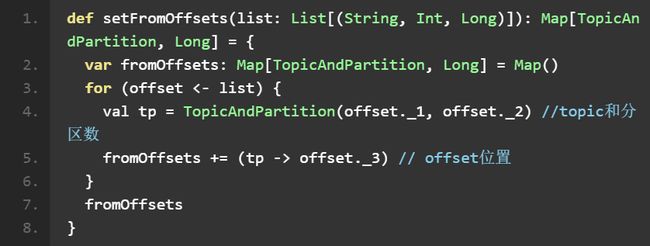
个人认为,DirectApproach 更符合 Spark 的思维。我们知道,RDD 的概念是一个不变的,分区的数据集合。我们将 Kafka 数据源包裹成了一个 KafkaRDD,RDD 里的 partition 对应的数据源为 Kafka 的 partition。唯一的区别是数据在 Kafka 里而不是事先被放到 Spark 内存里。其实包括 FileInputStream 里也是把每个文件映射成一个 RDD, 比较好奇,为什么一开始会有 Receiver-based Approach,额外添加了 Receiver 这么一个概念。
DirectKafkaInputDStream
SS 通过 Direct Approach 接收数据的入口自然是 KafkaUtils.createDirectStream 了。在调用该方法时,会先创建protected val kc = new KafkaCluster(KafkaParams)
KafkaCluster 这个类是真实负责和 Kafka 交互的类,该类会获取 Kafka 的 partition 信息, 接着会创建 DirectKafkaInputDStream。 此时会获取每个 Topic 的每个 partition 的 offset。 如果配置成 smallest 则拿到最早的 offset, 否则拿最近的 offset。
每个 DirectKafkaInputDStream 也会持有一个 KafkaCluster 实例。到了计算周期后,对应的 DirectKafkaInputDStream .compute 方法会被调用, 此时做下面几个操作:
1) 获取对应 Kafka Partition 的 untilOffset。这样就确定了需要获取数据的 offset 的范围,同时也就知道了需要计算多少数据了
2) 构建一个 KafkaRDD 实例。这里我们可以看到,每个计算周期里,DirectKafkaInputDStream 和 KafkaRDD 是一一对应的
3) 将相关的 offset 信息报给 InputInfoTracker
4) 返回该 RDD
KafkaRDD 的组成结构
KafkaRDD 包含 N(N=Kafka 的 partition 数目) 个 KafkaRDDPartition, 每个 KafkaRDDPartition 其实只是包含一些信息,譬如 topic,offset 等,真正如果想要拉数据,是通过 KafkaRDDIterator 来完成,一个 KafkaRDDIterator 对应一个 KafkaRDDPartition。整个过程都是延时过程,也就是说数据其实都还在 Kafka 里,直到有实际的 action 被触发,才会主动去 Kafka 拉数据。
限速
Direct Approach (NoReceivers) 的接收方式也是可以限制接受数据的量的。你可以通过设置 spark.streaming.kafka.maxRatePerPartition 来完成对应的配置。需要注意的是,这里是对每个 Partition 进行限速。所以你需要事先知道 Kafka 有多少个分区,才好评估系统的实际吞吐量,从而设置该值。
相应的,spark.streaming.backpressure.enabled 参数在 Direct Approach 中也是继续有效的。
Receiver-based Approach VS Direct Approach (No Receivers)
经过上面对两种数据接收方案的介绍,我们发现, Receiver-based Approach 存在各种内存折腾,对应的 Direct Approach (No Receivers) 则显得比较纯粹简单些,这也给其带来了较多的优势,主要有如下几点:
1) 因为按需要拉数据,所以不存在缓冲区,就不用担心缓冲区把内存撑爆了。这个在 Receiver-based Approach 就比较麻烦,你需要通过 spark.streaming.blockInterval 等参数来调整。
2) 数据默认就被分布到了多个 Executor 上。Receiver-based Approach 你需要做特定的处理,才能让 Receiver 分不到多个 Executor 上。
3) Receiver-based Approach 的方式,一旦你的 Batch Processing 被 delay 了,或者被 delay 了很多个 batch, 那估计你的 Spark Streaming 程序离崩溃也就不远了。 Direct Approach (No Receivers) 则完全不会存在类似问题。就算你 delay 了很多个 batch time, 你内存中的数据只有这次处理的。
4) Direct Approach (No Receivers) 直接维护了 Kafka offset, 可以保证数据只有被执行成功了,才会被记录下来,通过 checkpoint 机制。如果采用 Receiver-based Approach,消费 Kafka 和数据处理是被分开的,这样就很不好做容错机制,比如系统宕掉了。所以你需要开启 WAL, 但是开启 WAL 带来一个问题是,数据量很大,对 HDFS 是个很大的负担,而且也会给实时程序带来比较大延迟。
我原先以为 Direct Approach 因为只有在计算的时候才拉取数据,可能会比 Receiver-based Approach 的方式慢,但是经过我自己的实际测试,总体性能 Direct Approach 会更快些,因为 Receiver-based Approach 可能会有较大的内存隐患,GC 也会影响整体处理速度。
如何保证数据接收的可靠性
SS 自身可以做到 at least once 语义, 具体方式是通过 CheckPoint 机制。
CheckPoint 机制
CheckPoint 会涉及到一些类,以及他们之间的关系:DStreamGraph 类负责生成任务执行图,而 JobGenerator 则是任务真实的提交者。任务的数据源则来源于 DirectKafkaInputDStream,checkPoint 一些相关信息则是由类 DirectKafkaInputDStreamCheckpointData 负责。
好像涉及的类有点多,其实没关系,我们完全可以不用关心他们。先看看 checkpoint 都干了些啥,checkpoint 其实就序列化了一个类而已:
以下是其中的类成员:
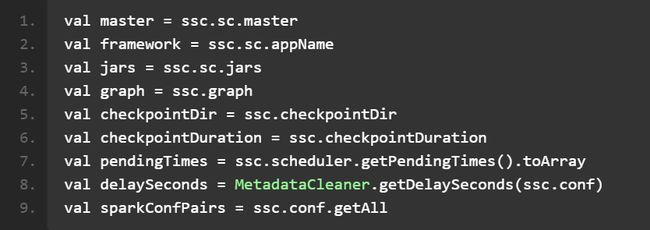
其他的都比较容易理解,最重要的是 graph,该类全路径名是:
里面有两个核心的数据结构是:

inputStreams 对应的就是 DirectKafkaInputDStream 了。
再进一步,DirectKafkaInputDStream 有一个重要的对象:

checkpointData 里则有一个 data 对象,里面存储的内容也很简单

就是每个 batch 的唯一标识 time 对象,以及每个 KafkaRDD 对应的的 Kafka 偏移信息。
而 outputStreams 里则是 RDD, 如果你存储的时候做了 foreach 操作,那么应该就是 forEachRDD 了,他被序列化的时候是不包含数据的。
经过上面的分析,我们发现:
1) checkpoint 是非常高效的。没有涉及到实际数据的存储。一般大小只有几十 K,因为只存了 Kafka 的偏移量等信息。
2) checkpoint 采用的是序列化机制,尤其是 DStreamGraph 的引入,里面包含了可能如 ForeachRDD 等,而 ForeachRDD 里面的函数应该也会被序列化。如果采用了 CheckPoint 机制,而你的程序包做了做了变更,恢复后可能会有一定的问题(这个在测试过程中碰到过)。
接着我们看看 JobGenerator 是怎么提交一个真实的 batch 任务的,分析在什么时间做 checkpoint 操作,从而保证数据的高可用:
1) 产生 jobs
2) 成功则提交 jobs 然后异步执行
3) 失败则会发出一个失败的事件
4) 无论成功或者失败,都会发出一个 DoCheckpoint 事件。
5) 当任务运行完成后,还会再调用一次 DoCheckpoint 事件。
只要任务运行完成后没能顺利执行完 DoCheckpoint 前 crash, 都会导致这次 Batch 被重新调度。也就说无论怎样,不存在丢数据的问题,而这种稳定性是靠 checkpoint 机制以及 Kafka 的可回溯性来完成的。
那现在会产生一个问题,假设我们的业务逻辑会对每一条数据都处理,则:
1) 我们没有处理一条数据
2) 我们可能只处理了部分数据
3) 我们处理了全部数据
根据我们上面的分析,无论如何,这次失败了,都会被重新调度,那么我们可能会重复处理数据。有可能事最后失败的那一批次数据的一部分,也可能是全部,但不会更多了。
业务需要做事务,保证 Exactly Once 语义
这里业务场景被区分为两个:
1) 幂等操作
2) 业务代码需要自身添加事物操作
所谓幂等操作就是重复执行不会产生问题,如果是这种场景下,你不需要额外做任何工作。但如果你的应用场景是不允许数据被重复执行的,那只能通过业务自身的逻辑代码来解决了。
这个 SS 倒是也给出了官方方案:

这代码什么含义呢? 就是说针对每个 partition 的数据,产生一个 uniqueId, 只有这个 partion 的所有数据被完全消费,则算成功,否则算失败,要回滚。下次重复执行这个 uniqueId 时,如果已经被执行成功过的,则 skip 掉。这样,就能保证数据 Exactly Once 语义了。
总结
根据我的实际经验,目前 Direct Approach 稳定性个人感觉比 Receiver-based Approach 更好些,推荐使用 Direct Approach 方式和 Kafka 进行集成,并且开启相应的 checkpoint 功能,保证数据接收的稳定性,Direct Approach 模式本身可以保证数据 at least once 语义,如果你需要 Exactly Once 语义时,需要保证你的业务是幂等,或者保证了相应的事务。
