Java枚举类型(enum)-7
EnumSet原理
有前面位向量的分析,对于了解EnumSet的实现原理就相对简单些了,EnumSet内部使用的位向量实现的,前面我们说过EnumSet是一个抽象类,事实上它存在两个子类,RegularEnumSet和JumboEnumSet。RegularEnumSet使用一个long类型的变量作为位向量,long类型的位长度是64,因此可以存储64个枚举实例的标志位,一般情况下是够用的了,而JumboEnumSet使用一个long类型的数组,当枚举个数超过64时,就会采用long数组的方式存储。先看看EnumSet内部的数据结构:
public abstract class EnumSet> extends AbstractSet
implements Cloneable, java.io.Serializable
{
//表示枚举类型
final Class elementType;
//存储该类型信息所表示的所有可能的枚举实例
final Enum[] universe;
//..........
} EnumSet中有两个变量,一个elementType用于表示枚举的类型信息,universe是数组类型,存储该类型信息所表示的所有可能的枚举实例,EnumSet是抽象类,因此具体的实现是由子类完成的,下面看看noneOf(Class静态构建方法
public static > EnumSet noneOf(Class elementType) {
//根据EnumMap中的一样,获取所有可能的枚举实例
Enum[] universe = getUniverse(elementType);
if (universe == null)
throw new ClassCastException(elementType + " not an enum");
if (universe.length <= 64)
//枚举个数小于64,创建RegularEnumSet
return new RegularEnumSet<>(elementType, universe);
else
//否则创建JumboEnumSet
return new JumboEnumSet<>(elementType, universe);
} 从源码可以看出如果枚举值个数小于等于64,则静态工厂方法中创建的就是RegularEnumSet,否则大于64的话就创建JumboEnumSet。无论是RegularEnumSet还是JumboEnumSet,其构造函数内部都间接调用了EnumSet的构造函数,因此最终的elementType和universe都传递给了父类EnumSet的内部变量。如下:
//RegularEnumSet构造
RegularEnumSet(ClasselementType, Enum[] universe) {
super(elementType, universe);
}
//JumboEnumSet构造
JumboEnumSet(ClasselementType, Enum[] universe) {
super(elementType, universe);
elements = new long[(universe.length + 63) >>> 6];
} 在RegularEnumSet类和JumboEnumSet类中都存在一个elements变量,用于记录位向量的操作,
//RegularEnumSet
class RegularEnumSet> extends EnumSet {
private static final long serialVersionUID = 3411599620347842686L;
//通过long类型的elements记录位向量的操作
private long elements = 0L;
//.......
}
//对于JumboEnumSet则是:
class JumboEnumSet> extends EnumSet {
private static final long serialVersionUID = 334349849919042784L;
//通过long数组类型的elements记录位向量
private long elements[];
//表示集合大小
private int size = 0;
//.............
} 在RegularEnumSet中elements是一个long类型的变量,共有64个bit位,因此可以记录64个枚举常量,当枚举常量的数量超过64个时,将使用JumboEnumSet,elements在该类中是一个long型的数组,每个数组元素都可以存储64个枚举常量,这个过程其实与前面位向量的分析是同样的道理,只不过前面使用的是32位的int类型,这里使用的是64位的long类型罢了。接着我们看看EnumSet是如何添加数据的,RegularEnumSet中的add实现如下
public boolean add(E e) {
//检测是否为枚举类型
typeCheck(e);
//记录旧elements
long oldElements = elements;
//执行位向量操作,是不是很熟悉?
//数组版:a[i >> SHIFT ] |= (1 << (i & MASK))
elements |= (1L << ((Enum)e).ordinal());
return elements != oldElements;
}关于elements |= (1L << ((Enum)e).ordinal());这句跟我们前面分析位向量操作是相同的原理,只不过前面分析的是数组类型实现,这里用的long类型单一变量实现,((Enum)e).ordinal()通过该语句获取要添加的枚举实例的序号,然后通过1左移再与 long类型的elements进行或操作,就可以把对应位置上的bit设置为1了,也就代表该枚举实例存在。图示演示过程如下,注意universe数组在EnumSet创建时就初始化并填充了所有可能的枚举实例,而elements值的第n个bit位1时代表枚举存在,而获取的则是从universe数组中的第n个元素值。
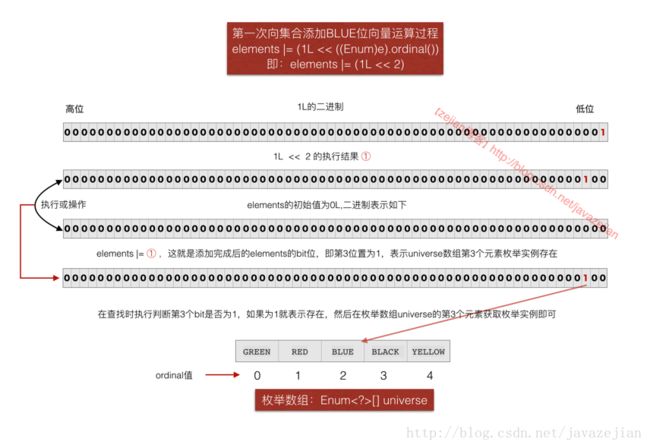
这就是枚举实例的添加过程和获取原理。而对于JumboEnumSet的add实现则是如下:
public boolean add(E e) {
typeCheck(e);
//计算ordinal值
int eOrdinal = e.ordinal();
int eWordNum = eOrdinal >>> 6;
long oldElements = elements[eWordNum];
//与前面分析的位向量相同:a[i >> SHIFT ] |= (1 << (i & MASK))
elements[eWordNum] |= (1L << eOrdinal);
boolean result = (elements[eWordNum] != oldElements);
if (result)
size++;
return result;
}关于JumboEnumSet的add实现与RegularEnumSet区别是一个是long数组类型,一个long变量,运算原理相同,数组的位向量运算与前面分析的是相同的,这里不再分析。接着看看如何删除元素
//RegularEnumSet类实现
public boolean remove(Object e) {
if (e == null)
return false;
Class eClass = e.getClass();
if (eClass != elementType && eClass.getSuperclass() != elementType)
return false;
long oldElements = elements;
//将int型变量j的第k个比特位设置为0,即j= j&~(1<>SHIFT] &= ~(1<<(i &MASK));
elements &= ~(1L << ((Enum)e).ordinal());//long遍历类型操作
return elements != oldElements;
}
//JumboEnumSet类的remove实现
public boolean remove(Object e) {
if (e == null)
return false;
Class eClass = e.getClass();
if (eClass != elementType && eClass.getSuperclass() != elementType)
return false;
int eOrdinal = ((Enum)e).ordinal();
int eWordNum = eOrdinal >>> 6;
long oldElements = elements[eWordNum];
//与a[i>>SHIFT] &= ~(1<<(i &MASK));相同
elements[eWordNum] &= ~(1L << eOrdinal);
boolean result = (elements[eWordNum] != oldElements);
if (result)
size--;
return result;
} 删除remove的实现,跟位向量的清空操作是同样的实现原理,如下: 
至于JumboEnumSet的实现原理也是类似的,这里不再重复。下面为了简洁起见,我们以RegularEnumSet类的实现作为源码分析,毕竟JumboEnumSet的内部实现原理可以说跟前面分析过的位向量几乎一样。o~,看看如何判断是否包含某个元素
public boolean contains(Object e) {
if (e == null)
return false;
Class eClass = e.getClass();
if (eClass != elementType && eClass.getSuperclass() != elementType)
return false;
//先左移再按&操作
return (elements & (1L << ((Enum)e).ordinal())) != 0;
}
public boolean containsAll(Collection c) {
if (!(c instanceof RegularEnumSet))
return super.containsAll(c);
RegularEnumSet es = (RegularEnumSet)c;
if (es.elementType != elementType)
return es.isEmpty();
//~elements取反相当于elements补集,再与es.elements进行&操作,如果为0,
//就说明elements补集与es.elements没有交集,也就是es.elements是elements的子集
return (es.elements & ~elements) == 0;
}对于contains(Object e) 方法,先左移再按位与操作,不为0,则表示包含该元素,跟位向量的get操作实现原理类似,这个比较简单。对于containsAll(Collection c)则可能比较难懂,这里分析一下,elements变量(long类型)标记EnumSet集合中已存在元素的bit位,如果bit位为1则说明存在枚举实例,为0则不存在,现在执行~elements 操作后 则说明~elements是elements的补集,那么只要传递进来的es.elements与补集~elements 执行&操作为0,那么就可以证明es.elements与补集~elements 没有交集的可能,也就是说es.elements只能是elements的子集,这样也就可以判断出当前EnumSet集合中包含传递进来的集合c了,借着下图协助理解:

图中,elements代表A,es.elements代表S,~elements就是求A的补集,(es.elements & ~elements) == 0就是在验证A’∩B是不是空集,即S是否为A的子集。接着看retainAll方法,求两个集合交集
public boolean retainAll(Collection c) {
if (!(c instanceof RegularEnumSet))
return super.retainAll(c);
RegularEnumSet es = (RegularEnumSet)c;
if (es.elementType != elementType) {
boolean changed = (elements != 0);
elements = 0;
return changed;
}
long oldElements = elements;
//执行与操作,求交集,比较简单
elements &= es.elements;
return elements != oldElements;
}最后来看看迭代器是如何取值的
public Iterator iterator() {
return new EnumSetIterator<>();
}
private class EnumSetIterator> implements Iterator {
//记录elements
long unseen;
//记录最后一个返回值
long lastReturned = 0;
EnumSetIterator() {
unseen = elements;
}
public boolean hasNext() {
return unseen != 0;
}
@SuppressWarnings("unchecked")
public E next() {
if (unseen == 0)
throw new NoSuchElementException();
//取值过程,先与本身负执行&操作得出的就是二进制低位开始的第一个1的数值大小
lastReturned = unseen & -unseen;
//取值后减去已取得lastReturned
unseen -= lastReturned;
//返回在指定 long 值的二进制补码表示形式中最低位(最右边)的 1 位之后的零位的数量
return (E) universe[Long.numberOfTrailingZeros(lastReturned)];
}
public void remove() {
if (lastReturned == 0)
throw new IllegalStateException();
elements &= ~lastReturned;
lastReturned = 0;
}
} 比较晦涩的应该是
//取值过程,先与本身负执行&操作得出的就是二进制低位开始的第一个1的数值大小
lastReturned = unseen & -unseen;
//取值后减去已取得lastReturned
unseen -= lastReturned;
return (E) universe[Long.numberOfTrailingZeros(lastReturned)];我们通过原理图来协助理解,现在假设集合中已保存所有可能的枚举实例变量,我们需要把它们遍历展示出来,下面的第一个枚举元素的获取过程,显然通过unseen & -unseen;操作,我们可以获取到二进制低位开始的第一个1的数值,该计算的结果是要么全部都是0,要么就只有一个1,然后赋值给lastReturned,通过Long.numberOfTrailingZeros(lastReturned)获取到该bit为1在64位的long类型中的位置,即从低位算起的第几个bit,如图,该bit的位置恰好是低位的第1个bit位置,也就指明了universe数组的第一个元素就是要获取的枚举变量。执行unseen -= lastReturned;后继续进行第2个元素的遍历,依次类推遍历出所有值,这就是EnumSet的取值过程,真正存储枚举变量的是universe数组,而通过long类型变量的bit位的0或1表示存储该枚举变量在universe数组的那个位置,这样做的好处是任何操作都是执行long类型变量的bit位操作,这样执行效率将特别高,毕竟是二进制直接执行,只有最终获取值时才会操作到数组universe。
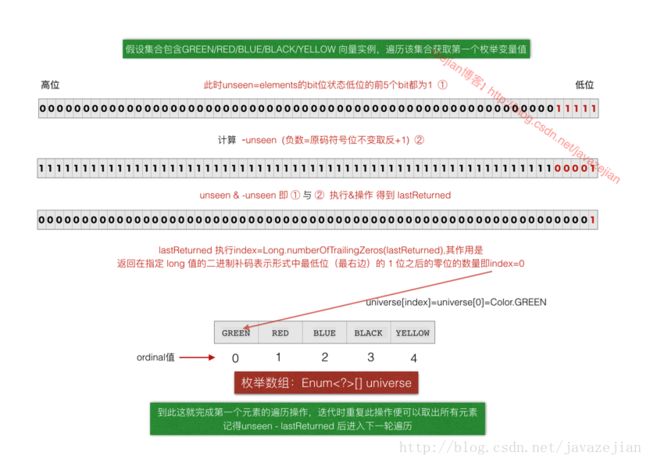
ok~,到这关于EnumSet的实现原理主要部分我们就分析完了,其内部使用位向量,存储结构很简洁,节省空间,大部分操作都是按位运算,直接操作二进制数据,因此效率极高。当然通过前面的分析,我们也掌握位向量的运算原理。好~,关于java枚举,我们暂时聊到这。