音视频学习总结
从零开始做一个小播放器
—音视频学习总结
1.视频播放
1.1视频文件格式与编码格式
1.1.1文件格式
常见的视频文件格式MPG、TS、AVI、RMVB、AVI等等
他们分别是以特定的方式将音频、图像数据按顺序编码在一起,形成视频文件。
以AVI(Audio Video Interleaved)格式的视频为例,说明下关系。AVI采用的是RIFF文件结构方式。构造RIFF文件的基本单元叫做数据块(chunk),每个数据块包含三个部分:
1)数据块的ID
2) 数据块的大小
3)数据
整个RIFF文件可以看成一个数据块,其数据块ID为RIFF。一个RIFF文件中只允许存在一个RIFF块。RIFF块中包含一系列的子块,其中有一种字块的ID为"LIST",称为LIST,LIST块中可以再包含一系列的子块,但除了LIST块外的其他所有的子块都不能再包含子块。RIFF和LIST块分别比普通的数据块多一个被称为形式类型(Form Type)和列表类型(List Type)的数据域,其组成如下:
1)4字节的数据块标记(Chunk ID)
2)数据块的大小
3)4字节的形式类型或者列表类型
4)数据
AVI的RIFF块的形式类型是AVI,它包含3个子块,如下所述:
1)信息块,一个ID为”hdrl"的LIST块,定义AVI文件的数据格式。
2)数据块,一个ID为 "movi"的LIST块,包含AVI的音视频序列数据。
3)索引块,ID为 "idxl"的子块,定义 “movi”LIST块的索引数据,是可选块。
其中数据块的音视频是交叉排列的,一段video后面接一段audio,然后再接video,如此循环下去
1.1.2编码格式
编码格式指的的video数据和audio数据按照一定的方式进行编码。
常见的video编码有MPG1、MPG2、MPG4、H264、H263等等
常见的audio编码格式有AAC、MP3、WMA等等
视频中的video数据块包含若干帧图像,这些图像是按照video的编码方式存储在里面,将图像依次在屏幕上播放,利用人眼的视觉暂留特性,就形成了我们看到的视频。
H264的分层结构:VCL video coding layer 视频编码层;NAL network abstraction layer 网络提取层;
![]()
网络传输的H264是由许多的NALU组成,每个NALU又包含NAL头和RBSP。NALU头用来标识后面的RBSP是什么类型的数据,它是否会被其他帧参考以及网络传输是否有错误。RBSP是NAL传输的基本单元,包括序列参数集 SPS 和 图像参数集 PPS等。SPS 包含的是针对一连续编码视频序列的参数,如标识符 seq_parameter_set_id、帧数及 POC 的约束、参考帧数目、解码图像尺寸和帧场编码模式选择标识等等。PPS对应的是一个序列中某一幅图像或者某几幅图像,其参数如标识符 pic_parameter_set_id、可选的 seq_parameter_set_id、熵编码模式选择标识、片组数目、初始量化参数和去方块滤波系数调整标识等等。
H264中把图像分成一帧(frame)或两场(field)(来源于老式的那种隔行扫描电视的概念,奇数行算一场,偶数的算另一场,由于数据传输的问题,所以分为两场来传输新型号,这样由于人眼有信息暂留,所以不影响最后的效果),而帧又可以分成一个或几个片(Slilce);片由宏块(MB)组成。宏块是编码处理的基本单元,一个宏块由一个16×16亮度像素和附加的一个8×8 Cb和一个8×8 Cr彩色像素块组成。帧又分为I帧、P帧和B帧,分别为关键帧,预测帧和中间帧(依赖I帧、P帧或其他B帧的数据)
由此将NAL中相同的slice组成一帧图像,然后连续的I帧、P帧、B帧组合起来播放,形成了完整的video。
参考:http://blog.csdn.net/mincheat/article/details/48713047
1.2.1图像格式、数据结构
由1.2.1介绍,图像是video的基础。图像是由N多像素点组成的。像素点的色彩表示方法有两种:RBG和YUV。RBG类型的像素点,由计算机使用3个字节来分别表示一个像素里面的Red,Green和Blue的发光强度数值。YUV(YCbCr)是将色彩和亮度分离,用Y表示亮度,U和V来表示色彩信息,这样做的好处是兼容黑白电视。除了这一点外,同一图像,用RGB和YUV来表示,YUV的数据量更少。
YUV采样格式:主要的采样格式有YCbCr 4:2:0、YCbCr 4:2:2、YCbCr 4:1:1和 YCbCr 4:4:4。其中YCbCr 4:1:1 比较常用,其含义为:每个点保存一个 8bit 的亮度值(也就是Y值), 每 2 x 2 个点保存一个 Cr和Cb值, 图像在肉眼中的感觉不会起太大的变化。所以, 原来用 RGB(R,G,B 都是 8bit unsigned) 模型, 每个点需要 8x3=24 bits, 而现在仅需要 8+(8/4)+(8/4)=12bits, 平均每个点占12bits。这样就把图像的数据压缩了一半。

关于YUV和RGB的转换,按照两者之间的相互关系进行计算转换。
Y = 0.299 R + 0.587 G + 0.114 B
U = -0.1687 R - 0.3313 G + 0.5 B + 128
V = 0.5 R - 0.4187 G - 0.0813 B + 128
R = Y + 1.402 (V-128)
G= Y - 0.34414 (U-128) - 0.71414 (V-128)
B= Y + 1.772 (U-128)
不同设备所采用的参数略有不同,以上仅供参考。
1.2.2video解码、渲染
在iOS设备上显示图像一般有两种途径:将数据转换成UIIamge,通过UIImageView在屏幕上显示;图像数据通过OpenGL ES直接在屏幕上渲染。
前者将RGB格式的数据通过iOS 自带CoreGraphics framework可以直接转换成UIIamge投影到屏幕上。但是有个弊病,iOS所带的颜色空间(color space)只支持RGB的颜色空间,不支持YUV。
YUV格式的数据在iOS设备上需要通过OpenGL ES来显示,在渲染过程中,可以使用shader提高性能。shader利用GPU进行相关的计算工作,减轻了CPU的负载。
1.2.3FFmpeg之videostream
FFmpeg是一套可以用来记录、转换数字音频、视频,并能将其转化为流的开源库。主要结构体包括:AVFrame、AVFormatContext、AVCodecContext、AVIOContext、AVCodec、AVStream、AVPacket。
AVFrame:
AVFrame结构体一般用于存储原始数据(即非压缩数据,例如对视频来说是YUV,RGB,对音频来说是PCM),此外还包含了一些相关的信息:
uint8_t *data[AV_NUM_DATA_POINTERS]:解码后原始数据(对视频来说是YUV,RGB,对音频来说是PCM)
int linesize[AV_NUM_DATA_POINTERS]:data中“一行”数据的大小。注意:未必等于图像的宽,一般大于图像的宽。
int width, height:视频帧宽和高(1920x1080,1280x720...)
int nb_samples:音频的一个AVFrame中可能包含多个音频帧,在此标记包含了几个
int format:解码后原始数据类型(YUV420,YUV422,RGB24...)
int key_frame:是否是关键帧
enum AVPictureType pict_type:帧类型(I,B,P...)
AVRational sample_aspect_ratio:宽高比(16:9,4:3...)
int64_t pts:显示时间戳
int coded_picture_number:编码帧序号
int display_picture_number:显示帧序号
int8_t *qscale_table:QP表
uint8_t *mbskip_table:跳过宏块表
int16_t (*motion_val[2])[2]:运动矢量表
uint32_t *mb_type:宏块类型表
short *dct_coeff:DCT系数,这个没有提取过
int8_t *ref_index[2]:运动估计参考帧列表(貌似H.264这种比较新的标准才会涉及到多参考帧)
int interlaced_frame:是否是隔行扫描
uint8_t motion_subsample_log2:一个宏块中的运动矢量采样个数,取log的
AVFormatContext的几个主要作用变量:
struct AVInputFormat *iformat:输入数据的封装格式
AVIOContext *pb:输入数据的缓存
unsigned int nb_streams:视音频流的个数
AVStream **streams:视音频流
char filename[1024]:文件名
int64_t duration:时长(单位:微秒us,转换为秒需要除以1000000)
int bit_rate:比特率(单位bps,转换为kbps需要除以1000)
AVDictionary *metadata:元数据
AVCodecContext:
enum AVMediaType codec_type:编解码器的类型(视频,音频...)
struct AVCodec *codec:采用的解码器AVCodec(H.264,MPEG2...)
int bit_rate:平均比特率
uint8_t *extradata; int extradata_size:针对特定编码器包含的附加信息(例如对于H.264解码器来说,存储SPS,PPS等)
AVRational time_base:根据该参数,可以把PTS转化为实际的时间(单位为秒s)
int width, height:如果是视频的话,代表宽和高
int refs:运动估计参考帧的个数(H.264的话会有多帧,MPEG2这类的一般就没有了)
int sample_rate:采样率(音频)
int channels:声道数(音频)
enum AVSampleFormat sample_fmt:采样格式
int profile:型(H.264里面就有,其他编码标准应该也有)
int level:级(和profile差不太多)
AVIOContext中有以下几个变量比较重要:
unsigned char *buffer:缓存开始位置
int buffer_size:缓存大小(默认32768)
unsigned char *buf_ptr:当前指针读取到的位置
unsigned char *buf_end:缓存结束的位置
void *opaque:URLContext结构体
URLContext结构体中还有一个结构体URLProtocol。每种协议(rtp,rtmp,file等)对应一个URLProtocol,在av_regitser_all()函数中会注册所支持的URLProtocol。每种URLProtocol结构体大都包含:open、read、seek、close等通用的函数,其他的根据协议的不同,添加各自不同的功能
AVCodec最主要的几个变量:
const char *name:编解码器的名字,比较短
const char *long_name:编解码器的名字,全称,比较长
enum AVMediaType type:指明了类型,是视频,音频,还是字幕
enum AVCodecID id:ID,不重复
const AVRational *supported_framerates:支持的帧率(仅视频)
const enum AVPixelFormat *pix_fmts:支持的像素格式(仅视频)
const int *supported_samplerates:支持的采样率(仅音频)
const enum AVSampleFormat *sample_fmts:支持的采样格式(仅音频)
const uint64_t *channel_layouts:支持的声道数(仅音频)
int priv_data_size:私有数据的大小
AVStream重要的变量:
int index:标识该视频/音频流
AVCodecContext *codec:指向该视频/音频流的AVCodecContext(它们是一一对应的关系)
AVRational time_base:时基。通过该值可以把PTS,DTS转化为真正的时间。FFMPEG其他结构体中也有这个字段,但是根据我的经验,只有AVStream中的time_base是可用的。PTS*time_base=真正的时间
int64_t duration:该视频/音频流长度
AVDictionary *metadata:元数据信息
AVRational avg_frame_rate:帧率(注:对视频来说,这个挺重要的)
AVPacket attached_pic:附带的图片。比如说一些MP3,AAC音频文件附带的专辑封面。
AVPacket结构体中,重要的变量有:
uint8_t *data:压缩编码的数据。
(例如对于H.264来说。1个AVPacket的data通常对应一个NAL。在这里只是对应,而不是一模一样。他们之间有微小的差别,因此在使用FFMPEG进行视音频处理的时候,常常可以将得到的AVPacket的data数据直接写成文件,从而得到视音频的码流文件)
int size:data的大小
int64_t pts:显示时间戳
int64_t dts:解码时间戳
int stream_index:标识该AVPacket所属的视频/音频流。
ffmpeg解码的流程图:
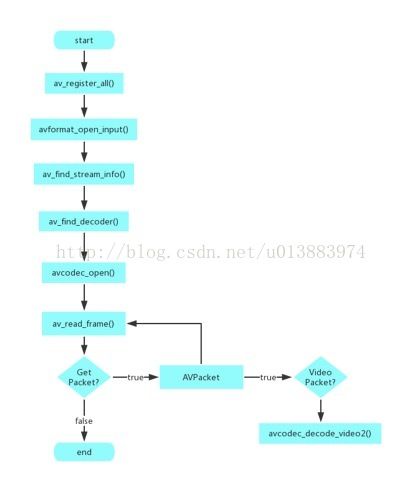
1.3.1音频格式、数据结构
音频常见的编码方式有PCM、MP3和WMA等。
关于采样率:
声音其实是一种能量波,因此也有频率和振幅的特征,频率对应于时间轴线,振幅对应于电平轴线。波是无限光滑的,弦线可以看成由无数点组成,由于存储空间是相对有限的,数字编码过程中,必须对弦线的点进行采样。采样的过程就是抽取某点的频率值,为了复原波形,一次振动中,必须有2个点的采样,人耳能够感觉到的最高频率为20kHz,因此要满足人耳的听觉要求,则需要至少每秒进行40k次采样,用40kHz表达,这个40kHz就是采样率。
有损无损:
根据采样率可知,音质只能无限接近原始信号,相对于原始信号,任何音频编码都是有损的。通常约定能达到最高水平的保真编码为PCM,PCM也只是无限接近。MP3为有损格式,是常见的音频压缩格式
1.3.2音频播放
iOS中音频播放的主要方式有两种:
1.使用AVAudioPlayer播放音频
2.使用Audio Unit(AU)或Audio Queue(AQ)播放解码后的音频
第一种系统已经集成好,直接调用上层API就可以完成了;
第二种是采用底层的音频API来完成播放,AU和AQ两种略有不同
AU步骤如下:
1)AudioSessionInitialize初始化一个iOS应用的音频会话对象
2)配置Audio Session
配置属性
kAudioSessionCategory_MediaPlayback指定为音频播放
kAudioSessionProperty_PreferredHardwareIOBufferDuration配置更小的I/O迟延,通常情况不需要设置 。
配置属性变化监听器(观察者模式的应用),非最小功能要求,可不实现。
kAudioSessionProperty_AudioRouteChange
kAudioSessionProperty_CurrentHardwareOutputVolume
AudioSessionSetActive激活音频会话
3)配置Audio Unit
描述输出单元AudioComponentDescription
获取组件AudioComponent
核对输出流格式AudioStreamBasicDescription
设置音频渲染回调结构体AURenderCallbackStruct并指定回调函数,这是真正向音频设备提供PCM数据的地方
4)音频渲染回调函数传入未播放的音频数据
5)释放资源
6)FFmpeg解码流程
7)音频重采样
注:关于“重采样”,根据雷霄骅的博客,FFmpeg 3.0 avcodec_decode_audio4函数解码出来的音频数据是单精度浮点类型,值范围为[0, 1.0]。iOS可播放Float类型的音频数据,范围和FFmpeg解码出来的PCM不同,故需要进行重采样。
AQ步骤如下:
AudioQueue的其工作模式,在其内部有一套缓冲队列(Buffer Queue)的机制。在AudioQueue启动之后需要通过AudioQueueAllocateBuffer生成若干个AudioQueueBufferRef结构,这些Buffer将用来存储即将要播放的音频数据,并且这些Buffer是受生成他们的AudioQueue实例管理的,内存空间也已经被分配(按照Allocate方法的参数),当AudioQueue被Dispose时这些Buffer也会随之被销毁。
当有音频数据需要被播放时首先需要被memcpy到AudioQueueBufferRef的mAudioData中(mAudioData所指向的内存已经被分配,之前AudioQueueAllocateBuffer所做的工作),并给mAudioDataByteSize字段赋值传入的数据大小。完成之后需要调用AudioQueueEnqueueBuffer把存有音频数据的Buffer插入到AudioQueue内置的Buffer队列中。在Buffer队列中有buffer存在的情况下调用AudioQueueStart,此时AudioQueue就回按照Enqueue顺序逐个使用Buffer队列中的buffer进行播放,每当一个Buffer使用完毕之后就会从Buffer队列中被移除并且在使用者指定的RunLoop上触发一个回调来告诉使用者,某个AudioQueueBufferRef对象已经使用完成,你可以继续重用这个对象来存储后面的音频数据。如此循环往复音频数据就会被逐个播放直到结束。
流程大致如下:
1)创建AudioQueue,创建一个自己的buffer数组BufferArray;
2)使用AudioQueueAllocateBuffer创建若干个AudioQueueBufferRef(一般2-3个即可),放入BufferArray;
3)有数据时从BufferArray取出一个buffer,memcpy数据后用AudioQueueEnqueueBuffer方法把buffer插入AudioQueue中;
4)AudioQueue中存在Buffer后,调用AudioQueueStart播放。(具体等到填入多少buffer后再播放可以自己控制,只要能保证播放不间断即可);
5)AudioQueue播放音乐后消耗了某个buffer,在另一个线程回调并送出该buffer,把buffer放回BufferArray供下一次使用;
6)返回步骤3)继续循环直到播放结束
1.4.1网络视频播放
Apple有一套自带的直播框架HLS,动态码流自适应技术,包含一个索引m3u8和若干个TS文件。主要实现方法为,将视频切为若干个ts片段,根据TS和视频信息,生成对应的m3u8文件。在播放时,播放器首先获取到m3u8文件,根据m3u8的内容依次获取ts文件,下载下来进行播放。
HLS可以用于直播和点播,直播是采集端将采集好的数据切片,制成ts和m3u8文件,存在服务器端,客户端去不断请求数据,这种直播方式延迟相对比较高。点播是服务器端已经保存有完整的视频ts和m3u8数据,客户端直接请求数据。二者的不同之处在于,直播是m3u8索引文件会不断更新,而点播获取的m3u8文件在末尾会有end标识符,不会更新。
其他的网络播放方式有rtmp、httpflv等
rtmp需要将实时获取的音视频分别使用AAC以及AVC的标准进行编码,将编码后的数据封装成flv数据流。需要发送AVC sequence header以及AAC sequence header。对于AVC的一帧的数据,是由多个NALU组成的,需要将这些NALU分开。在传输的第一帧之前,需要发送AVC sequence header,而AVC sequence header里面包含了sps和pps信息,sps以及pps是在类型分别为sps和pps的NALU中获取的,这样的NALU在每个关键帧中都会出现。音频按照类似的处理方式,得到AAC sequence header。最终,可以得到AVC sequence header、AAC sequence header、Data(Video)、Data(Audio),按照协议标准进行传输。
ffmpeg自带rtmp协议支持,可以根据直播链接初始化,然后解码获取的数据,在opengl或者imageview上播放显示
1.4.2本地视频播放
1)iOS自带avplayer播放器
2)根据上文的ffmpeg流程图,读取文件,解码数据,然后分别对应音频播放和视频播放。
2.1音视频播放线程
关于pthread线程、线程锁、信号量的使用
音频、视频各需要两个线程,一个解码线程、一个播放线程。关于线程方面具体是阅读ijkplayer的源码来理解这几个线程的工作机制。以及博客上的参考资料http://blog.csdn.net/hudashi/article/details/7709413
2.2PTS、DTS
DTS(Decoding Time Stamp)和PTS(Presentation Time Stamp)。 顾名思义,前者是解码的时间,后者是显示的时间。
FFmpeg中用AVPacket结构体来描述解码前或编码后的压缩包,用AVFrame结构体来描述解码后或编码前的信号帧。 对于视频来说,AVFrame就是视频的一帧图像。这帧图像什么时候显示给用户,就取决于它的PTS。DTS是AVPacket里的一个成员,表示这个压缩包应该什么时候被解码。 如果视频里各帧的编码是按输入顺序(也就是显示顺序)依次进行的,那么解码和显示时间应该是一致的。事实上,在大多数编解码标准(如H.264或HEVC)中,编码顺序和输入顺序并不一致。 于是才会需要PTS和DTS这两种不同的时间戳。
2.3音视频同步
由于音频数据和视频数据是单独解析单独播放的,所以存在音视频播放同步问题。
根据kun的课程,音视频同步分为三类,以系统时间为基准、以视频时间为基准、以音频时间为基准。因为人对声音比对图像的敏感度要大,所以一般常采用音频为基准。其中两个关键参数DTS和PTS,根据解码音视频得到的这两个参数来调整音视频的播放和解码关系。同时设置一个δ,当δ大于误差允许值时,根据情况,适当地通过延迟和提前视频,以使视频跟上音频的节奏。由于音视频同步比较复杂,在实际播放demo中还没具体涉及到这一块,有待后续研究。
2.4视频缓存
目前iOS上,对于支持rtmp的直播,可以在播放器和服务器之间添加一个代理,代理相当于中转的作用,播放器向代理发送datarequest,代理根据request向服务器请求数据,并将获取到的数据copy成两份,一份写入本地文件,一份返回给播放器play。主要利用的是- (BOOL)resourceLoader:(AVAssetResourceLoader *)resourceLoader shouldWaitForLoadingOfRequestedResource:(AVAssetResourceLoadingRequest *)loadingRequest函数。
对于HLS的直播,由于该函数不支持此类协议,所以目前没有合适的缓存方法。有一种不完善的方法,利用开源的服务器代码,在iOS本地搭建一个服务器,播放器向本地服务请求数据,本地服务器请求m3u8文件并下载ts,然后返回给播放器,同时储存数据,但是在两个ts之间切换时会有卡顿的现象。