Redis常用的五种数据类型
Redis常用的五种数据类型
String (Key-Value)
String是最常用的一种数据类型,普通的key/value存储都可以归为此类。
一个Key对应一个Value,string类型是二进制安全的。
Redis的string可以包含任何数据,比如jpg图片(生成二进制)或者序列化的对象。
基本操作如下:
//基本数据类型
var client = new RedisClient("127.0.0.1", 6379);
client.Set("pwd", 1111);
int pwd=client.Get("pwd");
Console.WriteLine(pwd);
//对象
UserInfo userInfo = new UserInfo() { UserName = "zhangsan", UserPwd = "1111" };//底层使用json序列化
client.Set("userInfo", userInfo);
UserInfo user=client.Get("userInfo");
Console.WriteLine(user.UserName);
//对象集合
List list = new List() { new UserInfo(){UserName="lisi",UserPwd="111"},new UserInfo(){UserName="wangwu",UserPwd="123"} };
client.Set>("list",list);
ListuserInfoList=client.Get>("list");
foreach (UserInfo userInfo in userInfoList)
{
Console.WriteLine(userInfo.UserName);
}
Hash(Key-Value)
hash是一个string 类型的field和value的映射表。
hash特别适合存储对象。相对于将对象的每个字段存成单个string 类型。一个对象存储在hash类型中会占用更少的内存,并且可以更方便的存取整个对象。
Redis的Hash数据类型的value内部是一个HashMap,如果该Map的成员比较少,则会采用一维数组的方式来紧凑存储该MAP,省去了大量指针的内存开销,这个参数在redis.conf配置文件中下面2项。
Hash-max-zipmap-entries 64
Hash-max-zipmap-value 512.
含义是当value这个Map内部不超过多少个成员时会采用线性紧凑格式存储,默认是64,即value内部有64个以下的成员就是使用线性紧凑存储,超过该值自动转成真正的HashMap.
Hash-max-zipmap-value含义是当value这个MAP内部的每个成员值长度不超过多少字节就会采用线性紧凑存储来节省空间。以上两个条件任意一个条件超过设置值都会转成真正的HashMap,也就不会再节省内存了,这个值设置多少需要权衡,HashMap的优势就是查找和操作时间短。
采用key—field—value的方式。一个key可对应多个field,一个field对应一个value。这里同时需要注意,Redis提供了接口(hgetall)可以直接取到全部的属性数据,但是如果内部Map的成员很多,那么涉及到遍历整个内部Map的操作,由于Redis单线程模型的缘故,这个遍历操作可能会比较耗时,而令其它客户端的请求完全不响应,这点需要格外注意
建议使用对象类别和ID构成键名,使用字段表示对象属性,字段值存储属性值,
对比
1. 采用String类型的存储对象,需要将对象进行序列化。
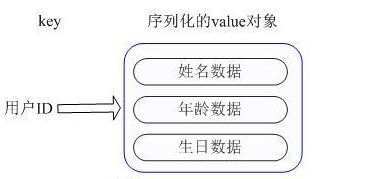
增加了序列化/反序列化的开销,并且在需要修改其中一项信息时,需要把整个对象取回。
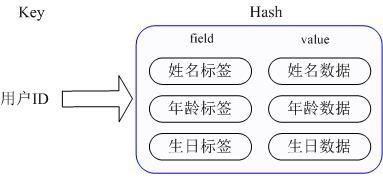
2. 使用Hash数据类型则不需要
Key仍然是用户ID, value是一个Map,这个Map的key是成员的属性名,value是属性值,这样对数据的修改和存取都可以直接通过其内部Map的Key(Redis里称内部Map的key为field), 也就是通过 key(用户ID) + field(属性标签) 就可以操作对应属性数据了,既不需要重复存储数据,也不会带来序列化和反序列化。
//SetEntryInHash key—field—value这种方式
client.SetEntryInHash("userId", "userName", “changliang");
List list = client.GetHashKeys(“userId");
List list = client.GetHashValues("userName");//获取值
List list = client.GetAllKeys();//获取所有的key。
List
list是一个链表结构,主要功能是push, pop, 获取一个范围的所有的值等。操作中key理解为链表名字。
Redis的list类型其实就是一个每个子元素都是string类型的双向链表。我们可以通过push,pop操作从链表的头部或者尾部添加删除元素,这样list既可以作为栈,又可以作为队列(栈就是insertFirst+deleteFirst,队列就是insertLast+deleteFirst)。可以支持反向查找和遍历,方便操作,不过带来了部分额外的内存开销。Redis内部的很多实现,包括发送缓冲队列等也都是用的这个数据结构。//队列使用--入队
client.EnqueueItemOnList("name", "zhangsan");
client.EnqueueItemOnList("name", "lisi");
int count= client.GetListCount("name");
for (int i = 0; i < count; i++)
{
Console.WriteLine(client.DequeueItemFromList("name"));
}
//栈使用--压栈
client.PushItemToList("name2", "wangwu");
client.PushItemToList("name2", "maliu");
int count = client.GetListCount("name2");
for (int i = 0; i < count; i++)
{
Console.WriteLine(client.PopItemFromList("name2"));
}
Set
它是string类型的无序集合。set是通过hash table实现的,可以进行添加、删除和查找。对集合我们可以取并集,交集,差集.
集合可以进行 交集、并集 如新浪微博中获取两个用户共同的关注人
新浪微博使用redis有两种应用场景:
1. 直接把数据放到redis中进行存储,这些数据是独立的
2. 有些数据包含表与表之间的逻辑关系,这些数据又访问比较频繁,如果直接从数据库中进行查询性能比较差。先将数据写到redis中,再将数据保存到mysql数据库
//对Set类型进行操作 集合名 后面可以放key-value对,也可以是基本类型
client.AddItemToSet("a3", "ddd");
client.AddItemToSet("a3", "ccc");
client.AddItemToSet("a3", "tttt");
client.AddItemToSet("a3", "sssh");
client.AddItemToSet("a3", "hhhh");
System.Collections.Generic.HashSethashset=client.GetAllItemsFromSet("a3");
foreach (string str in hashset)
{
Console.WriteLine(str);
}
求并集
//集合1 a3集合
client.AddItemToSet("a3", "ddd");
client.AddItemToSet("a3", "ccc");
client.AddItemToSet("a3", "tttt");
client.AddItemToSet("a3", "sssh");
client.AddItemToSet("a3", "hhhh");
//集合2 a4集合
client.AddItemToSet("a4", "hhhh");
client.AddItemToSet("a4", "h777");
System.Collections.Generic.HashSethashset= client.GetUnionFromSets(new string[] { "a3","a4"});
foreach (string str in hashset)
{
Console.WriteLine(str);
}
//求交集
System.Collections.Generic.HashSet hashset = client.GetIntersectFromSets(new string[] { “a3”, “a4” });
//求差集.
//返回存在于第一个集合,但是不存在于其他集合的数据。差集
System.Collections.Generic.HashSet hashset = client.GetDifferencesFromSet("a3",new string[] { "a4"});
zset
Redis sorted set的使用场景与set类似,区别是set不是自动有序的,而sorted set可以通过用户额外提供一个优先级(score)的参数来为成员排序,并且是插入有序的,即自动排序。
可以理解为一列存 value,一列存顺序。操作中key理解为zset的名字.
当你需要一个有序的并且不重复的集合列表,那么可以选择sorted set数据结构
//保存插入时的顺序,并放到集合a5中
client.AddItemToSortedSet("a5","ffff");
client.AddItemToSortedSet("a5","bbbb");
client.AddItemToSortedSet("a5","gggg");
client.AddItemToSortedSet("a5","cccc");
client.AddItemToSortedSet("a5","waaa");
System.Collections.Generic.Listlist =client.GetAllItemsFromSortedSet("a5");
foreach (string str in list)
{
Console.WriteLine(str);
} 总结
| 数据类型 |
Key |
value |
| String |
正常的key |
正常的value |
| Hash |
正常的Key 如用户ID |
HashMap(field,value) 代表对象 |
| List |
链表名字 |
每个子元素都是string类型的双向链表 |
| Set |
Set名字 |
string类型的无序集合 |
| Zset |
Zset名字 |
一列存 value,一列存顺序 |