爬虫基础(1)
网络爬虫(web crawler),(又称为网页蜘蛛,网络机器人,在FOAF社区中间,更经常的称为网页追逐者。)是一种按照一定的规则,自动地抓取万维网信息的程序或者脚本。在网页中一般有很多的超链接将许多网页信息联系在一起。网络爬虫正是利用网页中的超链接信息不断地获取网络上其它的页面。,这一数据采集的过程正类似于一个爬虫或者蜘蛛在网络上漫游,所以才被形象的称为网络爬虫或者网络蜘蛛。
一个基本的爬虫通常分为数据采集(网页下载)、数据处理(网页解析)和数据存储(将有用的信息持久化)三个部分。
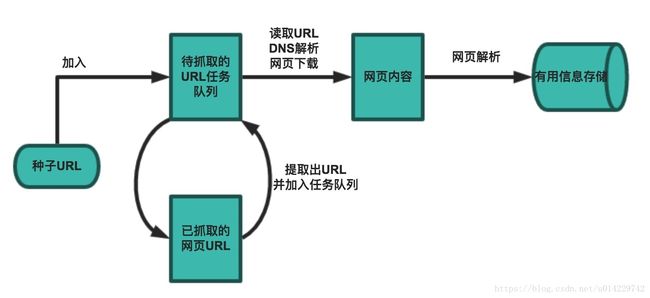
1.设定抓取的目标(种子页面)并获取网页
2.当服务器无法访问时,设置重试次数
3.在需要的时候设置用户代理(否则无法访问页面)
4.对获取的页面进行必要的解码操作
5.通过正则表达式获取页面中的链接
6.对链接进行进一步的处理
7.将有用的信息进行持久化
PS:使用网络爬虫的时候,需要遵守Robots协议,尊重网站的知识产权,同时控制网络爬虫程序抓取数据的速度。使用不当违反规则是会吃官司的!
网络爬虫的应用:
1.搜索引擎
2.新闻聚合
3.社交应用
4.舆情监控
5.行业数据
相关工具:
1.Chrome Developer Tools:谷歌浏览器自带的开发者调试工具
2.POSTMAN:
3.HTTPie
4.BuitWith:识别网站使用的技术
import builtwith
builtwith.parse('http://www/baidu.com')
{'javascript-frameworks': ['jQuery']}5.python-whois:查询网站的所有者
import whois
whois.whois('baidu')6.robotparser:解析robots.txt的工具
爬虫相关代码:
# 排序规则:1.按字母顺序。2.先写原生再写第三方3.没有from的写在前面,有from的写在后面
from enum import Enum, unique
from queue import Queue
from random import random
from threading import Thread, current_thread
from time import sleep
from urllib.parse import urlparse
import requests
from bs4 import BeautifulSoup
# enum:枚举
@unique
class SpiderStatus(Enum):
# IDLE means free
IDLE = 0
# working mean busy
WORKING = 1
def decode_page(page_bytes, charsets=('utf-8',)):
# define page_html,and the init value is None
page_html = None
for charset in charsets:
try:
page_html = page_bytes.decode(charset)
break
except UnicodeDecodeError:
pass
return page_html
# 用类来写装饰器
# 对象可以做包装器原因:该对象有魔法方法call
class Retry(object):
# 命名关键字参数(3个)
def __init__(self, *, retry_times=3,
wait_secs=5, errors=(Exception, )):
# 尝试时间
self.retry_times = retry_times
# 等待时间。(间隔时间5秒)
self.wait_secs = wait_secs
# 错误,异常
self.errors = errors
# 魔法方法
def __call__(self, fn):
# wrapper:包装器
def wrapper(*args, **kwargs):
# 用循环
for _ in range(self.retry_times):
try:
# 拿到函数fn的返回结果
return fn(*args, **kwargs)
except self.errors as e:
# 打印错误
print(e)
# 休眠时间,随机
sleep((random() + 1) * self.wait_secs)
return None
return wrapper
class Spider(object):
def __init__(self):
# init the status to be free
self.status = SpiderStatus.IDLE
# useragent伪装身份,proxies:默认隐身
# *后面表示命名关键字参数(有3个命名关键字参数)
# @Retry装饰器。装饰器可以写成一个函数
@Retry()
def fetch(self, current_url, *, charsets=('utf-8', ),
user_agent=None, proxies=None):
thread_name = current_thread().name
print(f'[{thread_name}]: {current_url}')
# useragent存在则赋值,否则为空
headers = {'user-agent': user_agent} if user_agent else {}
resp = requests.get(current_url,
headers=headers, proxies=proxies)
# 成功则返回页面,否则为None。页面需要做解码处理
return decode_page(resp.content, charsets) \
if resp.status_code == 200 else None
# 传domain域名
def parse(self, html_page, *, domain='m.sohu.com'):
# beautifulsoup使用解析器lxml进行解析
soup = BeautifulSoup(html_page, 'lxml')
url_links = []
# soup.body.select('a[href]')::选择有href的a标签
# 使用循环解析a标签
for a_tag in soup.body.select('a[href]'):
# 使用urlparse解析整个页面
parser = urlparse(a_tag.attrs['href'])
# scheme:表示http部分。如果没有取到就把http赋值给scheme
scheme = parser.scheme or 'http'
# netloc:地址
netloc = parser.netloc or domain
if scheme != 'javascript' and netloc == domain:
path = parser.path
query = '?' + parser.query if parser.query else ''
# f表示格式化字符串
full_url = f'{scheme}://{netloc}{path}{query}'
if full_url not in visited_urls:
# 如果找出地址,就加到列表
url_links.append(full_url)
return url_links
def extract(self, html_page):
pass
def store(self, data_dict):
pass
class SpiderThread(Thread):
def __init__(self, name, spider, tasks_queue):
# 继承init的方法,daemon,设置为守护线程:主线程挂掉,所有子线程就结束
super().__init__(name=name, daemon=True)
self.spider = spider
# 任务队列
self.tasks_queue = tasks_queue
def run(self):
# 上面设置了守护线程,下面程序就不会发生死循环,只要主程序结束,程序结束
while True:
# 线程启动后,开始从队列中取数据
current_url = self.tasks_queue.get()
# 将访问过的url加到visited_urls中
visited_urls.add(current_url)
# 将蜘蛛的状态标记为working
self.spider.status = SpiderStatus.WORKING
# 给爬虫发消息,爬取页面
html_page = self.spider.fetch(current_url)
# 当页面不是不存在或者为空
if html_page not in [None, '']:
# 解析页面,返回列表
url_links = self.spider.parse(html_page)
for url_link in url_links:
# 将解析后的页面加到task_queue中
self.tasks_queue.put(url_link)
# 爬取完成后,状态标记为空闲
self.spider.status = SpiderStatus.IDLE
# 该函数判断是否还有存活的蜘蛛
def is_any_alive(spider_threads):
# any函数。取每一个线程的状态是否有working状态,如果有就返回TRUE
# any列表中只要有个TRUE,结果即为TRUE
# 只要有任何一个蜘蛛是活着的,我们的任务就继续
return any([spider_thread.spider.status == SpiderStatus.WORKING
for spider_thread in spider_threads])
# 存放已访问的地址,set使得存放的地址不重复
visited_urls = set()
def main():
# 任务队列:先进先出
task_queue = Queue()
# 放初始地址,放在尾巴上。get是取操作,取东西从头部拿
task_queue.put('http://m.sohu.com/')
# 创建指定数量的线程10个。传2个参数
spider_threads = [SpiderThread('thread-%d' % i, Spider(), task_queue)
for i in range(10)]
# 循环
for spider_thread in spider_threads:
# 启动线程
spider_thread.start()
# 当队列不为空或者有任何存活的蜘蛛,程序继续
# 只要有任何一个蜘蛛是活着的,我们的任务就继续
while not task_queue.empty() or is_any_alive(spider_threads):
pass
# 否则over
print('Over!')
if __name__ == '__main__':
main()