logstash+grok+json+elasticsearch解析复杂日志数据(一)
这几天学习了logstash写配置文件conf解析包含部分json数据格式的日志数据,并在elasticsearch以及kibana进行直观的数据浏览。对于logstash有了更加深入的了解,logstash在运维方面是开源的日志收集框架,其中包含了许多插件,下载的时候就包含在其中了,比较常用的有输入插件,输出插件,codec编码插件,filter过滤器插件,输出插件等等,甚至还有许多美未能进入官方的插件就不再一一赘述了。
我这几天主要接触了grok,json格式插件,还有一些input,output一些配置参数的熟悉等等。待处理的日志数据有两部分组成:一部分是原本工程师添加的时间戳、ip、出错类型,另一部分是较为复杂包含嵌套,list等等的json数据,es api上面有关于嵌套类型的解决办法,比如重改mapping,将对应字段的type设置为"nested",我也是在这个博客上学习的:
Elasticsearch之Nested(嵌套)系列
对了,es是基于lucene框架的,本身是会嵌套数据平坦化的,没办法改,只能改索引,将nested作为一个新的隐藏索引。
1.至于如何内部直接解析json(比如json数据中的嵌套,数据list,将这些内容单独出来作为字段),这些我还没找到太好的办法,估计只能在代码段(开发阶段进行数据分析吧),我目前还是没找到太好的办法。
2.这几天我又遇到json解析,好气,非得改json内部数据的格式,将string=>float,只能硬上正则了,还好json格式固定,不太长。
正则将其内部数据作为单独的字段显示出来,就能mutate随意操纵了,嘿嘿
数据:
2016-12-05 15:19:52 [ http-nio-1560-exec-2:67538 ] - [ INFO ] {"hardwarebean":{"timeStamp":1480922392859,"total":"1714490352","used":"1075686180","free":"638804172"}}
格式:
%{TIMESTAMP_ISO8601:timestamp}\s+\[%{DATA:ip}\]\s-\s\[%{DATA:delltype}\]\s+\{\"hardwarebean\":\{\"timeStamp\":%{NUMBER:time},\"total\":%{DATA:jvmtotal},\"used\":%{DATA:jvmused},\"free\":%{DATA:jvmfree}\}\}
不过这些复杂的json数据虽然不能直接作为字段展示,但是在elasticsearch还是有比较清晰的展示的。下面是两张结果图片:一张是es搜索结果,一张是kibana中索引的状态。
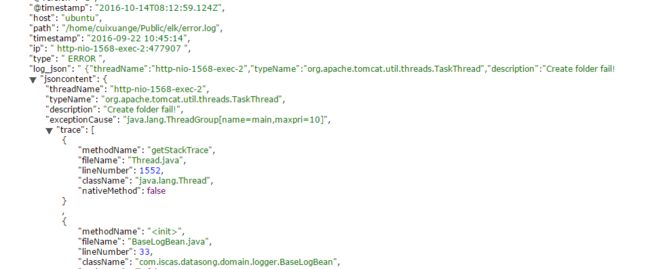
日志数据的如下(单独一条):
2016-09-22 10:37:16 [ http-nio-1568-exec-1:0 ] - [ ERROR ] {"threadName":"http-nio-1568-exec-1","typeName":"org.apache.tomcat.util.threads.TaskThread","description":"Create folder fail!","exceptionCause":"java.lang.ThreadGroup[name=main,maxpri=10]","trace":[{"methodName":"getStackTrace","fileName":"Thread.java","lineNumber":1552,"className":"java.lang.Thread","nativeMethod":false},{"methodName":"","fileName":"BaseLogBean.java","lineNumber":33,"className":"com.iscas.datasong.domain.logger.BaseLogBean","nativeMethod":false}, 我是这么处理的:时间戳+ip+类型+json数据按照这个格式进行的解析,后面全部交个logstash中json插件进行解析,好处是方便,坏处似乎是不能直接处理json中内部嵌套的字段,仍需其它的方式多进行一步的查询。(比如说A.B形式)
logstsh中解析日志数据的配置文件如下:
grok是正则捕获过滤器,我进行了正则表达式的匹配。(grok debugger很好用,推荐测试您的正则表达式;熟悉grok的内置正则会方便不少)
json处理json数据的过滤器,source来自logstash字段,也就是上面日志数据的json格式数据字段名称
elasticsearch插件进行了输出,前面if进行判断如果不是时间戳格式不进行输出,预防某些日志中的网址参数换行导致输入中断
input {
file{
path => ["/home/cuixuange/Public/elk/error.log"]
start_position=>"beginning"
}
}
filter{
grok{
match=>{ "message" => "%{DATA:timestamp} \[%{DATA:ip}\] . \[%{DATA:type}\] %{GREEDYDATA:log_json}"
}
}
json {
source => "log_json"
target => "log_json_content"
remove_field=>["logjson"]
}
# json {
# source => "trace"
# target => "trace_content"
# remove_field=>["trace"]
# } #本来想在json数据内部再来一次json处理似乎没有成功
}
output {
if[timestamp]=~/^\d{4}-\d{2}-\d{2}/{
elasticsearch {
host => "192.168.172.128"
index => "test_index"
workers=>5
template_overwrite =>true
}
}
#stdout{codec=>json_lines}
}kibana查看建立的索引状态:
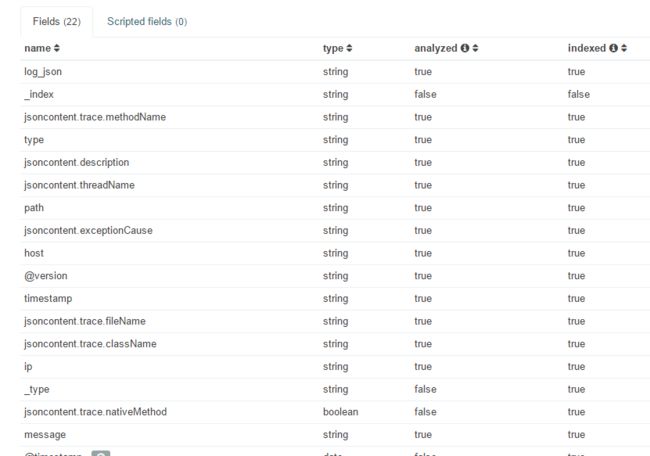
elasticsearch查看:(复合查询中输入http://localhost/test_index(这是索引名称)/_search?pretty)
其中一条数据:

附带更深入内容链接:
基础知识:logstash最佳实践
logstash使用grok日志解析
新手一枚,欢迎指正~~