Flink-1.11使用sql-client连接Hive-2.1.1
写在前面:
Sql-client连接Hive是通过客户端的形式读写hive、测试相关语句的便捷方式,也是Flink搭建后测试操作Hive的第一步。前面因为版本问题一直没有进展,Flink在1.9.1版本中只面向Hive-1.2.1、Hive-2.3.4,而在不改变Hive版本的情况下,其他实现方式较为繁琐。而Flink-1.11版本中,已经全面支持Hive的大多数版本的连接,对比源码可以发现Flink在新版本中实现了不同hive版本api的对接。
Flink-1.9.1:

Flink-1.11:

0. 环境准备
基于cdh-6.1.0编译flink-1.11-SNAPSHOT
1. Jar包准备
在{flink-home}/lib目录下放入以下jar包:
hive-2.1.0-bin/lib/hive-exec-2.1.0.jar
{flink-compile-home}/flink-connectors/flink-connector-hive/target/flink-connector-hive_2.11-1.11-SNAPSHOT.jar
{flink-shaded-9.0-compile-home}/…/flink-shaded-hadoop-2-uber-3.0.0-cdh6.1.0-9.0.jar
2. 修改配置
修改flink-1.11-SNAPSHOT/conf/sql-client-defaults.yaml配置:
#==============================================================================
# Catalogs
#==============================================================================
# Define catalogs here.
#catalogs: [] # empty list
# A typical catalog definition looks like:
# - name: myhive
# type: hive
# hive-conf-dir: /opt/hive_conf/
# default-database: ...
catalogs:
- name: myhive
type: hive
hive-conf-dir: /etc/alternatives/hive-conf
hive-version: 2.1.1
3. 启动sql-client
启动flink(因为sql-client一些任务需要提交到flink计算执行)
bin/start-cluster.sh
启动sql-client
bin/sql-client.sh
执行:
use catalog myhive;
use test_myq;
select * from mytable;
如果报以下错误,先检查flink是否正常启动:
[ERROR] Could not execute SQL statement. Reason:
org.apache.flink.runtime.rest.util.RestClientException: [Failed to deserialize JobGraph.]
执行报以下错误:
org.apache.flink.runtime.rest.util.RestClientException: [Internal server error., (JobManagerRunnerImpl.java:152)
at org.apache.flink.runtime.dispatcher.DefaultJobManagerRunnerFactory.createJobManagerRunner(DefaultJobManagerRunnerFactory.java:84)
at org.apache.flink.runtime.dispatcher.Dispatcher.lambda$createJobManagerRunner$6(Dispatcher.java:379)
at org.apache.flink.util.function.CheckedSupplier.lambda$unchecked$0(CheckedSupplier.java:34)
... 7 more
Caused by: org.apache.flink.runtime.JobException: Creating the input splits caused an error: Permission denied: user=root, access=READ_EXECUTE, inode="/user/hive/warehouse/test_myq.db/mytable":hdfs:hive:drwxrwx--t
at org.apache.hadoop.hdfs.server.namenode.FSPermissionChecker.check(FSPermissionChecker.java:400)
at org.apache.hadoop.hdfs.server.namenode.FSPermissionChecker.checkPermission(FSPermissionChecker.java:262)
at org.apache.hadoop.hdfs.server.namenode.FSPermissionChecker.checkPermission(FSPermissionChecker.java:194)
at org.apache.hadoop.hdfs.server.namenode.FSDirectory.checkPermission(FSDirectory.java:1853)
at org.apache.hadoop.hdfs.server.namenode.FSDirectory.checkPermission(FSDirectory.java:1837)
at org.apache.hadoop.hdfs.server.namenode.FSDirectory.checkPathAccess(FSDirectory.java:1787)
at org.apache.hadoop.hdfs.server.namenode.FSDirStatAndListingOp.getListingInt(FSDirStatAndListingOp.java:79)
at org.apache.hadoop.hdfs.server.namenode.FSNamesystem.getListing(FSNamesystem.java:3733)
at org.apache.hadoop.hdfs.server.namenode.NameNodeRpcServer.getListing(NameNodeRpcServer.java:1138)
at org.apache.hadoop.hdfs.protocolPB.ClientNamenodeProtocolServerSideTranslatorPB.getListing(ClientNamenodeProtocolServerSideTranslatorPB.java:708)
at org.apache.hadoop.hdfs.protocol.proto.ClientNamenodeProtocolProtos$ClientNamenodeProtocol$2.callBlockingMethod(ClientNamenodeProtocolProtos.java)
at org.apache.hadoop.ipc.ProtobufRpcEngine$Server$ProtoBufRpcInvoker.call(ProtobufRpcEngine.java:523)
at org.apache.hadoop.ipc.RPC$Server.call(RPC.java:991)
at org.apache.hadoop.ipc.Server$RpcCall.run(Server.java:869)
at org.apache.hadoop.ipc.Server$RpcCall.run(Server.java:815)
at java.security.AccessController.doPrivileged(Native Method)
at javax.security.auth.Subject.doAs(Subject.java:422)
at org.apache.hadoop.security.UserGroupInformation.doAs(UserGroupInformation.java:1729)
at org.apache.hadoop.ipc.Server$Handler.run(Server.java:2675)
at org.apache.flink.runtime.executiongraph.ExecutionJobVertex.(ExecutionJobVertex.java:271)
at org.apache.flink.runtime.executiongraph.ExecutionGraph.attachJobGraph(ExecutionGraph.java:806)
at org.apache.flink.runtime.executiongraph.ExecutionGraphBuilder.buildGraph(ExecutionGraphBuilder.java:228)
at org.apache.flink.runtime.scheduler.SchedulerBase.createExecutionGraph(SchedulerBase.java:253)
at org.apache.flink.runtime.scheduler.SchedulerBase.createAndRestoreExecutionGraph(SchedulerBase.java:225)
at org.apache.flink.runtime.scheduler.SchedulerBase.(SchedulerBase.java:213)
at org.apache.flink.runtime.scheduler.DefaultScheduler.(DefaultScheduler.java:117)
at org.apache.flink.runtime.scheduler.DefaultSchedulerFactory.createInstance(DefaultSchedulerFactory.java:105)
at org.apache.flink.runtime.jobmaster.JobMaster.createScheduler(JobMaster.java:278)
at org.apache.flink.runtime.jobmaster.JobMaster.(JobMaster.java:266)
at org.apache.flink.runtime.jobmaster.factories.DefaultJobMasterServiceFactory.createJobMasterService(DefaultJobMasterServiceFactory.java:98)
at org.apache.flink.runtime.jobmaster.factories.DefaultJobMasterServiceFactory.createJobMasterService(DefaultJobMasterServiceFactory.java:40)
at org.apache.flink.runtime.jobmaster.JobManagerRunnerImpl.(JobManagerRunnerImpl.java:146)
... 10 more
Caused by: org.apache.hadoop.security.AccessControlException: Permission denied: user=root, access=READ_EXECUTE, inode="/user/hive/warehouse/test_myq.db/mytable":hdfs:hive:drwxrwx--t
at org.apache.hadoop.hdfs.server.namenode.FSPermissionChecker.check(FSPermissionChecker.java:400)
at org.apache.hadoop.hdfs.server.namenode.FSPermissionChecker.checkPermission(FSPermissionChecker.java:262)
at org.apache.hadoop.hdfs.server.namenode.FSPermissionChecker.checkPermission(FSPermissionChecker.java:194)
at org.apache.hadoop.hdfs.server.namenode.FSDirectory.checkPermission(FSDirectory.java:1853)
at org.apache.hadoop.hdfs.server.namenode.FSDirectory.checkPermission(FSDirectory.java:1837)
at org.apache.hadoop.hdfs.server.namenode.FSDirectory.checkPathAccess(FSDirectory.java:1787)
at org.apache.hadoop.hdfs.server.namenode.FSDirStatAndListingOp.getListingInt(FSDirStatAndListingOp.java:79)
at org.apache.hadoop.hdfs.server.namenode.FSNamesystem.getListing(FSNamesystem.java:3733)
at org.apache.hadoop.hdfs.server.namenode.NameNodeRpcServer.getListing(NameNodeRpcServer.java:1138)
at org.apache.hadoop.hdfs.protocolPB.ClientNamenodeProtocolServerSideTranslatorPB.getListing(ClientNamenodeProtocolServerSideTranslatorPB.java:708)
at org.apache.hadoop.hdfs.protocol.proto.ClientNamenodeProtocolProtos$ClientNamenodeProtocol$2.callBlockingMethod(ClientNamenodeProtocolProtos.java)
at org.apache.hadoop.ipc.ProtobufRpcEngine$Server$ProtoBufRpcInvoker.call(ProtobufRpcEngine.java:523)
at org.apache.hadoop.ipc.RPC$Server.call(RPC.java:991)
at org.apache.hadoop.ipc.Server$RpcCall.run(Server.java:869)
at org.apache.hadoop.ipc.Server$RpcCall.run(Server.java:815)
at java.security.AccessController.doPrivileged(Native Method)
at javax.security.auth.Subject.doAs(Subject.java:422)
at org.apache.hadoop.security.UserGroupInformation.doAs(UserGroupInformation.java:1729)
at org.apache.hadoop.ipc.Server$Handler.run(Server.java:2675)
at sun.reflect.NativeConstructorAccessorImpl.newInstance0(Native Method)
at sun.reflect.NativeConstructorAccessorImpl.newInstance(NativeConstructorAccessorImpl.java:62)
at sun.reflect.DelegatingConstructorAccessorImpl.newInstance(DelegatingConstructorAccessorImpl.java:45)
at java.lang.reflect.Constructor.newInstance(Constructor.java:423)
at org.apache.hadoop.ipc.RemoteException.instantiateException(RemoteException.java:121)
at org.apache.hadoop.ipc.RemoteException.unwrapRemoteException(RemoteException.java:88)
at org.apache.hadoop.hdfs.DFSClient.listPaths(DFSClient.java:1607)
at org.apache.hadoop.hdfs.DistributedFileSystem$DirListingIterator.(DistributedFileSystem.java:1143)
at org.apache.hadoop.hdfs.DistributedFileSystem$DirListingIterator.(DistributedFileSystem.java:1126)
at org.apache.hadoop.hdfs.DistributedFileSystem$25.doCall(DistributedFileSystem.java:1071)
at org.apache.hadoop.hdfs.DistributedFileSystem$25.doCall(DistributedFileSystem.java:1067)
at org.apache.hadoop.fs.FileSystemLinkResolver.resolve(FileSystemLinkResolver.java:81)
at org.apache.hadoop.hdfs.DistributedFileSystem.listLocatedStatus(DistributedFileSystem.java:1085)
at org.apache.hadoop.fs.FileSystem.listLocatedStatus(FileSystem.java:2039)
at org.apache.hadoop.mapred.FileInputFormat.singleThreadedListStatus(FileInputFormat.java:275)
at org.apache.hadoop.mapred.FileInputFormat.listStatus(FileInputFormat.java:236)
at org.apache.hadoop.mapred.FileInputFormat.getSplits(FileInputFormat.java:322)
at org.apache.flink.connectors.hive.read.HiveTableInputFormat.createInputSplits(HiveTableInputFormat.java:219)
at org.apache.flink.connectors.hive.read.HiveTableInputFormat.createInputSplits(HiveTableInputFormat.java:56)
at org.apache.flink.runtime.executiongraph.ExecutionJobVertex.(ExecutionJobVertex.java:257)
... 22 more
Caused by: org.apache.hadoop.ipc.RemoteException(org.apache.hadoop.security.AccessControlException): Permission denied: user=root, access=READ_EXECUTE, inode="/user/hive/warehouse/test_myq.db/mytable":hdfs:hive:drwxrwx--t
at org.apache.hadoop.hdfs.server.namenode.FSPermissionChecker.check(FSPermissionChecker.java:400)
at org.apache.hadoop.hdfs.server.namenode.FSPermissionChecker.checkPermission(FSPermissionChecker.java:262)
at org.apache.hadoop.hdfs.server.namenode.FSPermissionChecker.checkPermission(FSPermissionChecker.java:194)
at org.apache.hadoop.hdfs.server.namenode.FSDirectory.checkPermission(FSDirectory.java:1853)
at org.apache.hadoop.hdfs.server.namenode.FSDirectory.checkPermission(FSDirectory.java:1837)
at org.apache.hadoop.hdfs.server.namenode.FSDirectory.checkPathAccess(FSDirectory.java:1787)
at org.apache.hadoop.hdfs.server.namenode.FSDirStatAndListingOp.getListingInt(FSDirStatAndListingOp.java:79)
at org.apache.hadoop.hdfs.server.namenode.FSNamesystem.getListing(FSNamesystem.java:3733)
at org.apache.hadoop.hdfs.server.namenode.NameNodeRpcServer.getListing(NameNodeRpcServer.java:1138)
at org.apache.hadoop.hdfs.protocolPB.ClientNamenodeProtocolServerSideTranslatorPB.getListing(ClientNamenodeProtocolServerSideTranslatorPB.java:708)
at org.apache.hadoop.hdfs.protocol.proto.ClientNamenodeProtocolProtos$ClientNamenodeProtocol$2.callBlockingMethod(ClientNamenodeProtocolProtos.java)
at org.apache.hadoop.ipc.ProtobufRpcEngine$Server$ProtoBufRpcInvoker.call(ProtobufRpcEngine.java:523)
at org.apache.hadoop.ipc.RPC$Server.call(RPC.java:991)
at org.apache.hadoop.ipc.Server$RpcCall.run(Server.java:869)
at org.apache.hadoop.ipc.Server$RpcCall.run(Server.java:815)
at java.security.AccessController.doPrivileged(Native Method)
at javax.security.auth.Subject.doAs(Subject.java:422)
at org.apache.hadoop.security.UserGroupInformation.doAs(UserGroupInformation.java:1729)
at org.apache.hadoop.ipc.Server$Handler.run(Server.java:2675)
at org.apache.hadoop.ipc.Client.getRpcResponse(Client.java:1499)
at org.apache.hadoop.ipc.Client.call(Client.java:1445)
at org.apache.hadoop.ipc.Client.call(Client.java:1355)
at org.apache.hadoop.ipc.ProtobufRpcEngine$Invoker.invoke(ProtobufRpcEngine.java:228)
at org.apache.hadoop.ipc.ProtobufRpcEngine$Invoker.invoke(ProtobufRpcEngine.java:116)
at com.sun.proxy.$Proxy34.getListing(Unknown Source)
at org.apache.hadoop.hdfs.protocolPB.ClientNamenodeProtocolTranslatorPB.getListing(ClientNamenodeProtocolTranslatorPB.java:654)
at sun.reflect.NativeMethodAccessorImpl.invoke0(Native Method)
at sun.reflect.NativeMethodAccessorImpl.invoke(NativeMethodAccessorImpl.java:62)
at sun.reflect.DelegatingMethodAccessorImpl.invoke(DelegatingMethodAccessorImpl.java:43)
at java.lang.reflect.Method.invoke(Method.java:498)
at org.apache.hadoop.io.retry.RetryInvocationHandler.invokeMethod(RetryInvocationHandler.java:422)
at org.apache.hadoop.io.retry.RetryInvocationHandler$Call.invokeMethod(RetryInvocationHandler.java:165)
at org.apache.hadoop.io.retry.RetryInvocationHandler$Call.invoke(RetryInvocationHandler.java:157)
at org.apache.hadoop.io.retry.RetryInvocationHandler$Call.invokeOnce(RetryInvocationHandler.java:95)
at org.apache.hadoop.io.retry.RetryInvocationHandler.invoke(RetryInvocationHandler.java:359)
at com.sun.proxy.$Proxy35.getListing(Unknown Source)
at org.apache.hadoop.hdfs.DFSClient.listPaths(DFSClient.java:1605)
... 35 more
End of exception on server side>]
根据报错初步判断是提交hive任务时root用户没有权限,但是我执行sql-client时已经切换了hdfs用户还是报错,说明该配置不是系统用户。
想通过源码寻找答案,在源码中HadoopUserOverlay类看到这么一段代码:
/**
* Configures the overlay using the current Hadoop user information (from {@link UserGroupInformation}).
*/
public Builder fromEnvironment(Configuration globalConfiguration) throws IOException {
ugi = UserGroupInformation.getCurrentUser();
return this;
}
public HadoopUserOverlay build() {
return new HadoopUserOverlay(ugi);
}
这里获得了当前运行的用户作为HadoopUser,排除sql-client的运行用户就是启动flink集群的用户了。
于是切换到hdfs用户进行启动flink
su - hdfs
/opt/flink-1.11-SNAPSHOT/bin/start-cluster.sh
然而该命令启动的时候会提示输入hdfs的密码(猜测公司集群的ssh验证机制在这台机器上没有配免密登陆?)
[hdfs@node01 flink-1.11-SNAPSHOT]$ bin/start-cluster.sh
Starting cluster.
Starting standalonesession daemon on host crop863-cloud03.
hdfs@node01's password:
这里也是到处寻找资料,发现hdfs没有密码,通过su - hdfs就可以正常使用,但是输入密码为空依然报错。
后来尝试各种办法均没有效果。
最终,在检查flink配置的时候发现我rpc调用的host(jobmanager.rpc.address)、以及slaves中的host我写的是域名,将其改为localhost后再次运行成功!(测试发现写ip也是需要密码)
这里还考虑过其他解决方式,如对root用户增加对hive、hdfs的权限等,不过没有找到合适的方法所以没有成功。
4. local模式测试
- 启动flink集群
[hdfs@node01 ~]$ cd /opt/flink-1.11-SNAPSHOT/
[hdfs@node01 flink-1.11-SNAPSHOT]$ bin/start-cluster.sh
Starting cluster.
Starting standalonesession daemon on host node01.
log4j:WARN No appenders could be found for logger (org.apache.flink.configuration.GlobalConfiguration).
log4j:WARN Please initialize the log4j system properly.
log4j:WARN See http://logging.apache.org/log4j/1.2/faq.html#noconfig for more info.
log4j:WARN No appenders could be found for logger (org.apache.flink.configuration.GlobalConfiguration).
log4j:WARN Please initialize the log4j system properly.
log4j:WARN See http://logging.apache.org/log4j/1.2/faq.html#noconfig for more info.
Starting taskexecutor daemon on host node01.
- 启动sql-client
[hdfs@crop863-cloud03 flink-1.11-SNAPSHOT]$ bin/sql-client.sh embedded
No default environment specified.
Searching for '/opt/flink-1.11-SNAPSHOT/conf/sql-client-defaults.yaml'...found.
Reading default environment from: file:/opt/flink-1.11-SNAPSHOT/conf/sql-client-defaults.yaml
No session environment specified.
2020-01-16 15:33:52,248 WARN org.apache.hadoop.hive.conf.HiveConf - HiveConf of name hive.vectorized.use.checked.expressions does not exist
2020-01-16 15:33:52,248 WARN org.apache.hadoop.hive.conf.HiveConf - HiveConf of name hive.strict.checks.no.partition.filter does not exist
2020-01-16 15:33:52,249 WARN org.apache.hadoop.hive.conf.HiveConf - HiveConf of name hive.strict.checks.orderby.no.limit does not exist
2020-01-16 15:33:52,249 WARN org.apache.hadoop.hive.conf.HiveConf - HiveConf of name hive.vectorized.adaptor.usage.mode does not exist
2020-01-16 15:33:52,249 WARN org.apache.hadoop.hive.conf.HiveConf - HiveConf of name hive.vectorized.input.format.excludes does not exist
2020-01-16 15:33:52,250 WARN org.apache.hadoop.hive.conf.HiveConf - HiveConf of name hive.strict.checks.bucketing does not exist
▒▓██▓██▒
▓████▒▒█▓▒▓███▓▒
▓███▓░░ ▒▒▒▓██▒ ▒
░██▒ ▒▒▓▓█▓▓▒░ ▒████
██▒ ░▒▓███▒ ▒█▒█▒
░▓█ ███ ▓░▒██
▓█ ▒▒▒▒▒▓██▓░▒░▓▓█
█░ █ ▒▒░ ███▓▓█ ▒█▒▒▒
████░ ▒▓█▓ ██▒▒▒ ▓███▒
░▒█▓▓██ ▓█▒ ▓█▒▓██▓ ░█░
▓░▒▓████▒ ██ ▒█ █▓░▒█▒░▒█▒
███▓░██▓ ▓█ █ █▓ ▒▓█▓▓█▒
░██▓ ░█░ █ █▒ ▒█████▓▒ ██▓░▒
███░ ░ █░ ▓ ░█ █████▒░░ ░█░▓ ▓░
██▓█ ▒▒▓▒ ▓███████▓░ ▒█▒ ▒▓ ▓██▓
▒██▓ ▓█ █▓█ ░▒█████▓▓▒░ ██▒▒ █ ▒ ▓█▒
▓█▓ ▓█ ██▓ ░▓▓▓▓▓▓▓▒ ▒██▓ ░█▒
▓█ █ ▓███▓▒░ ░▓▓▓███▓ ░▒░ ▓█
██▓ ██▒ ░▒▓▓███▓▓▓▓▓██████▓▒ ▓███ █
▓███▒ ███ ░▓▓▒░░ ░▓████▓░ ░▒▓▒ █▓
█▓▒▒▓▓██ ░▒▒░░░▒▒▒▒▓██▓░ █▓
██ ▓░▒█ ▓▓▓▓▒░░ ▒█▓ ▒▓▓██▓ ▓▒ ▒▒▓
▓█▓ ▓▒█ █▓░ ░▒▓▓██▒ ░▓█▒ ▒▒▒░▒▒▓█████▒
██░ ▓█▒█▒ ▒▓▓▒ ▓█ █░ ░░░░ ░█▒
▓█ ▒█▓ ░ █░ ▒█ █▓
█▓ ██ █░ ▓▓ ▒█▓▓▓▒█░
█▓ ░▓██░ ▓▒ ▓█▓▒░░░▒▓█░ ▒█
██ ▓█▓░ ▒ ░▒█▒██▒ ▓▓
▓█▒ ▒█▓▒░ ▒▒ █▒█▓▒▒░░▒██
░██▒ ▒▓▓▒ ▓██▓▒█▒ ░▓▓▓▓▒█▓
░▓██▒ ▓░ ▒█▓█ ░░▒▒▒
▒▓▓▓▓▓▒▒▒▒▒▒▒▒▒▒▒▒▒▒▒▒▒▒▒▒▒▒▒░░▓▓ ▓░▒█░
______ _ _ _ _____ ____ _ _____ _ _ _ BETA
| ____| (_) | | / ____|/ __ \| | / ____| (_) | |
| |__ | |_ _ __ | | __ | (___ | | | | | | | | |_ ___ _ __ | |_
| __| | | | '_ \| |/ / \___ \| | | | | | | | | |/ _ \ '_ \| __|
| | | | | | | | < ____) | |__| | |____ | |____| | | __/ | | | |_
|_| |_|_|_| |_|_|\_\ |_____/ \___\_\______| \_____|_|_|\___|_| |_|\__|
Welcome! Enter 'HELP;' to list all available commands. 'QUIT;' to exit.
Flink SQL>
这里报的一些警告,hive相关配置没有找到,是因为flink源码中使用的hive版本为2.3.4(但是针对多个hive版本做了api的适配),这里可以忽略。
- 测试读写hive
Flink SQL> show catalogs;
default_catalog
myhive
Flink SQL> use catalog myhive;
Flink SQL> show databases;
default
test_myq
Flink SQL> use test_myq;
Flink SQL> show tables;
mytable
mytest
test_jdbc
Flink SQL> describe mytable;
root
|-- name: STRING
|-- num: DOUBLE
Flink SQL> select * from mytable;
SQL Query Result (Table)
Table program finished. Page: Last of 1 Updated: 15:36:49.864
name num
Jelly 6.28
candy 3.14
test 6.33
Q Quit + Inc Refresh G Goto Page N Next Page O Open Row
R Refresh - Dec Refresh L Last Page P Prev Page
Flink SQL> insert into mytable values('flink', 6.66);
[INFO] Submitting SQL update statement to the cluster...
2020-01-16 15:37:41,228 WARN org.apache.hadoop.hive.conf.HiveConf - HiveConf of name hive.vectorized.use.checked.expressions does not exist
2020-01-16 15:37:41,229 WARN org.apache.hadoop.hive.conf.HiveConf - HiveConf of name hive.strict.checks.no.partition.filter does not exist
2020-01-16 15:37:41,229 WARN org.apache.hadoop.hive.conf.HiveConf - HiveConf of name hive.strict.checks.orderby.no.limit does not exist
2020-01-16 15:37:41,229 WARN org.apache.hadoop.hive.conf.HiveConf - HiveConf of name hive.vectorized.input.format.excludes does not exist
2020-01-16 15:37:41,229 WARN org.apache.hadoop.hive.conf.HiveConf - HiveConf of name hive.vectorized.adaptor.usage.mode does not exist
2020-01-16 15:37:41,230 WARN org.apache.hadoop.hive.conf.HiveConf - HiveConf of name hive.strict.checks.bucketing does not exist
[INFO] Table update statement has been successfully submitted to the cluster:
Job ID: 4582354f4483cae555fbb822fd342120
- Web UI:ip:8081
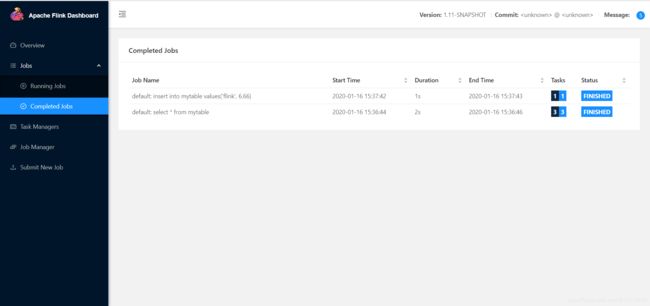
通过Web UI可以查看到任务执行情况:
参考:
https://ci.apache.org/projects/flink/flink-docs-master/zh/dev/table/hive/