SENet(Squeeze-and-Excitation Networks)算法笔记
论文:Squeeze-and-Excitation Networks
论文链接:https://arxiv.org/abs/1709.01507
代码地址:https://github.com/hujie-frank/SENet
PyTorch代码地址:https://github.com/miraclewkf/SENet-PyTorch
Sequeeze-and-Excitation(SE) block并不是一个完整的网络结构,而是一个子结构,可以嵌到其他分类或检测模型中,作者采用SENet block和ResNeXt结合在ILSVRC 2017的分类项目中拿到第一,在ImageNet数据集上将top-5 error降低到2.251%,原先的最好成绩是2.991%。
作者在文中将SENet block插入到现有的多种分类网络中,都取得了不错的效果。SENet的核心思想在于通过网络根据loss去学习特征权重,使得有效的feature map权重大,无效或效果小的feature map权重小的方式训练模型达到更好的结果。当然,SE block嵌在原有的一些分类网络中不可避免地增加了一些参数和计算量,但是在效果面前还是可以接受的。
也许通过给某一层特征配备权重的想法很多人都有,那为什么只有SENet成功了?个人认为主要原因在于权重具体怎么训练得到。就像有些是直接根据feature map的数值分布来判断;有些可能也利用了loss来指导权重的训练,不过全局信息该怎么获取和利用也是因人而异。
Figure1表示一个SE block。主要包含Squeeze和Excitation两部分,接下来结合公式来讲解Figure1。

首先Ftr这一步是转换操作(严格讲并不属于SENet,而是属于原网络,可以看后面SENet和Inception及ResNet网络的结合),在文中就是一个标准的卷积操作而已,输入输出的定义如下表示。
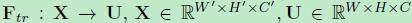
那么这个Ftr的公式就是下面的公式1(卷积操作,vc表示第c个卷积核,xs表示第s个输入)。

Ftr得到的U就是Figure1中的左边第二个三维矩阵,也叫tensor,或者叫C个大小为H*W的feature map。而uc表示U中第c个二维矩阵,下标c表示channel。
接下来就是Squeeze操作,公式非常简单,就是一个global average pooling:
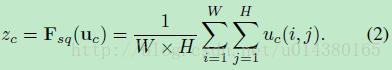
因此公式2就将HWC的输入转换成11C的输出,对应Figure1中的Fsq操作。为什么会有这一步呢?这一步的结果相当于表明该层C个feature map的数值分布情况,或者叫全局信息。
再接下来就是Excitation操作,如公式3。直接看最后一个等号,前面squeeze得到的结果是z,这里先用W1乘以z,就是一个全连接层操作,W1的维度是C/r * C,这个r是一个缩放参数,在文中取的是16,这个参数的目的是为了减少channel个数从而降低计算量。又因为z的维度是11C,所以W1z的结果就是11C/r;然后再经过一个ReLU层,输出的维度不变;然后再和W2相乘,和W2相乘也是一个全连接层的过程,W2的维度是C*C/r,因此输出的维度就是11C;最后再经过sigmoid函数,得到s。

也就是说最后得到的这个s的维度是11C,C表示channel数目。这个s其实是本文的核心,它是用来刻画tensor U中C个feature map的权重。而且这个权重是通过前面这些全连接层和非线性层学习得到的,因此可以end-to-end训练。这两个全连接层的作用就是融合各通道的feature map信息,因为前面的squeeze都是在某个channel的feature map里面操作。
在得到s之后,就可以对原来的tensor U操作了,就是下面的公式4。也很简单,就是channel-wise multiplication,什么意思呢?uc是一个二维矩阵,sc是一个数,也就是权重,因此相当于把uc矩阵中的每个值都乘以sc。对应Figure1中的Fscale。

了解完上面的公式,就可以看看在实际网络中怎么添加SE block。Figure2是在Inception中加入SE block的情况,这里的Inception部分就对应Figure1中的Ftr操作。
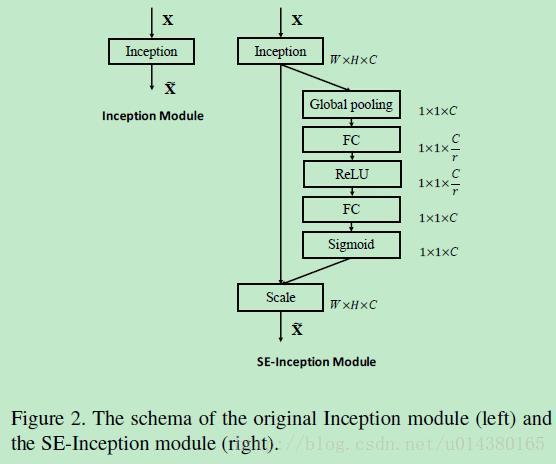
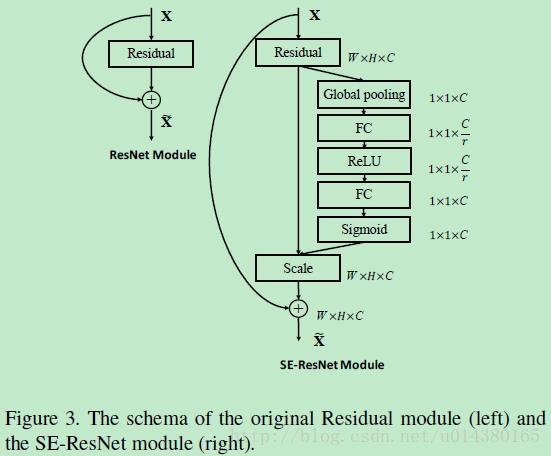
Figure3是在ResNet中添加SE block的情况。
看完结构,再来看添加了SE block后,模型的参数到底增加了多少。其实从前面的介绍可以看出增加的参数主要来自两个全连接层,两个全连接层的维度都是C/r * C,那么这两个全连接层的参数量就是2*C^2/r。以ResNet为例,假设ResNet一共包含S个stage,每个Stage包含N个重复的residual block,那么整个添加了SE block的ResNet增加的参数量就是下面的公式:

除了公式介绍,文中还举了更详细的例子来说明参数增加大概是多少百分比:In total, SE-ResNet-50 introduces 2.5 million additional parameters beyond the 25 million parameters required by ResNet-50, corresponding to a 10% increase in the total number of parameters。而且从公式5可以看出,增加的参数和C关系很大,而网络越到高层,其feature map的channel个数越多,也就是C越大,因此大部分增加的参数都是在高层。同时作者通过实验发现即便去掉最后一个stage的SE block,对模型的影响也非常小(<0.1% top-1 error),因此如果你对参数量的限制要求很高,倒是可以这么做,毕竟具体在哪些stage,哪些block中添加SE block都是自由定义的。
Table2是将SE block添加到ResNet,ResNeXt和Inception三个模型中的效果对比,数据集都是ImageNet,可以看出计算复杂度的增加并不明显(增加的主要是全连接层,全连接层其实主要还是增加参数量,对速度影响不会太大)。

既然是冠军算法,文中也介绍了当时取得冠军时的算法大致组成:Our winning entry comprised a small ensemble of SENets that employed a standard multi-scale and multi-crop fusion strategy to obtain a 2.251% top-5 error on the test set.This result represents a 25% relative improvement on the winning entry of 2016 (2.99% top-5 error). 也就是说其实是多模型做了融合。
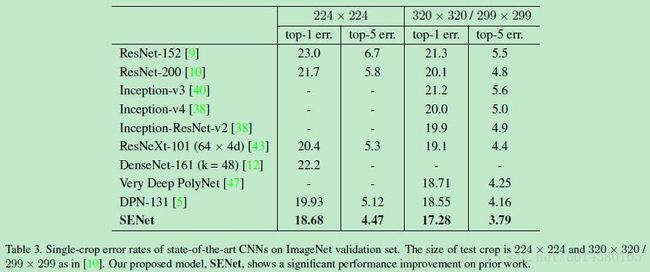
而在融合的多个模型之中:One of our high-performing networks is constructed by integrating SE blocks with a modified ResNeXt,也就是Table3中最后一行的SENet!具体而言是在64*4d 的ResNeXt-152网络中引入了SE block。而这个ResNeXt-152是在ResNeXt-101的基础上根据ResNet-152的叠加方式改造出来的,因为原来的ResNeXt文章中并没有提到152层的ResNeXt,具体改造可以看文章的附录,附录的一些细节可以在以后应用中参考。从Table3可以看出即便是单模型,SENet的效果也比其他算法要好。
另外前面提到过在SE block中第一个全连接层的维度是C/r * C,这个r在文中取的是16,作用在于将原来输入是11C的feature map缩减为11C/r的feature map,这一就降低了后面的计算量。而下面的Table5则是关于这个参数r取不同值时对结果和模型大小的影响。

最后,除了在ImageNet数据集上做实验,作者还在Places365-Challenge数据集上做了对比,更多实验结果可以参看论文。
附:看了下caffe代码(.prototxt文件),和文章的实现还有些不一样。下图是在Inception中添加SENet的可视化结果:SE-BN-Inception,在Inception中是在每个Inception的后面连上一个SENet,下图的上面一半就是一个Inception,下面一半就是一个SENet,然后这个SENet下面又连着一个新的Inception。

注意看这个SENet的红色部分都是用卷积操作代替文中的全连接层操作实现的,本质上没有什么区别。具体来说,inception_3a_11_down是输出channel为16的11卷积,其输入channel是256,这也符合文中说的缩减因子为16(256/16=16);而inception_3a_11_up是输出channel为256的11卷积。其它层都和文中描述一致,比如inception_3a_global_pool是average pooling,inception_3a_prob是sigmoid函数。
SE-ResNet-50的情况也类似,如下图。在ResNet中都是在Residual block中嵌入SENet。下图最左边的长条连线是原来Residual block的skip connection,右下角的conv2_2_global_pool到conv2_2_prob以及左边那条连线都是SENet。不过也是用两个1*1卷积代替文中的两个全连接层。
