Doc2vec论文阅读及源码理解
《Distributed representationss of Sentences and Documents》
Quoc Le and Tomas Mikolov, 2014
文章目录
- 《Distributed representationss of Sentences and Documents》
- 1. Distributed Memory Model of Paragraph Vectors (PV-DM).
- 1.1 模型架构图
- 1.2 相关代码阅读
- 2. Distributed Bag ofWords version of Paragraph Vector (PV-DBOW)
- 2.1 模型架构图
- 2.2 相关代码理解
- 3. Doc2vec的预测过程
- 3.1 预测原理
- 3.2 相关代码阅读
1. Distributed Memory Model of Paragraph Vectors (PV-DM).
1.1 模型架构图
有点类似word2vec中的CBOW模型,根据上下文预测当前词。
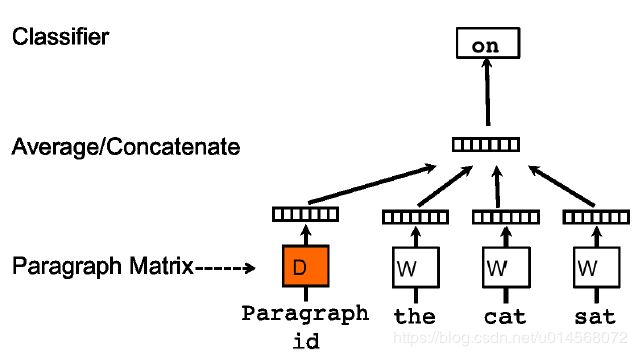
在PV-DM模型中,矩阵 W W W为词向量矩阵,矩阵 D D D为段落向量矩阵。
每一个段落被映射为矩阵 D D D中的一个唯一的向量,每个单词同样被映射为矩阵 W W W中的一个唯一向量。
paragraph向量和词向量通过取平均(average)或者连接(concatenate)的方法结合,预测目标词向量。
这里的context上下文是从当前段落中的滑动窗口内采样得到的固定长度的(代码中应该是通过reduced_window来实现采样的,见下面代码阅读),段落向量只在同一个paragraph中共享,词向量在paragraph之间共享。
1.2 相关代码阅读
gensim3.8.0中Doc2vec-DM模型相关代码阅读如下(如果之前学习过Word2vec的源码,那么对doc2vec源码的理解会更加容易一些)
- 通过average计算上下文向量
def train_document_dm(model, doc_words, doctag_indexes, alpha, work=None, neu1=None,
learn_doctags=True, learn_words=True, learn_hidden=True,
word_vectors=None, word_locks=None, doctag_vectors=None, doctag_locks=None):
"""Update distributed memory model ("PV-DM") by training on a single document.
使用一篇doc对PV-DM模型进行更新
Called internally from :meth:`~gensim.models.doc2vec.Doc2Vec.train` and
:meth:`~gensim.models.doc2vec.Doc2Vec.infer_vector`. This method implements
the DM model with a projection (input) layer that is either the sum or mean of
the context vectors, depending on the model's `dm_mean` configuration field.
Notes
-----
This is the non-optimized, Python version. If you have cython installed, gensim
will use the optimized version from :mod:`gensim.models.doc2vec_inner` instead.
Parameters
----------
model : :class:`~gensim.models.doc2vec.Doc2Vec`
The model to train.
doc_words : list of str
The input document as a list of words to be used for training. Each word will be looked up in
the model's vocabulary.
doctag_indexes : list of int
Indices into `doctag_vectors` used to obtain the tags of the document.
alpha : float
Learning rate.
work : object
UNUSED.
neu1 : object
UNUSED.
learn_doctags : bool, optional
Whether the tag vectors should be updated.
learn_words : bool, optional
Word vectors will be updated exactly as per Word2Vec skip-gram training only if **both**
`learn_words` and `train_words` are set to True.
learn_hidden : bool, optional
Whether or not the weights of the hidden layer will be updated.
word_vectors : iterable of list of float, optional
Vector representations of each word in the model's vocabulary.
word_locks : list of float, optional
Lock factors for each word in the vocabulary.
doctag_vectors : list of list of float, optional
Vector representations of the tags. If None, these will be retrieved from the model.
doctag_locks : list of float, optional
The lock factors for each tag.
Returns
-------
int
Number of words in the input document that were actually used for training (they were found in the
vocabulary and they were not discarded by negative sampling).
"""
# 获取模型中的词向量
if word_vectors is None:
word_vectors = model.wv.syn0
if word_locks is None:
word_locks = model.syn0_lockf
# 获取模型中的doc向量
if doctag_vectors is None:
doctag_vectors = model.docvecs.doctag_syn0
if doctag_locks is None:
doctag_locks = model.docvecs.doctag_syn0_lockf
# 当前段落中词的词表信息(该词必须存在于词表中)
word_vocabs = [model.wv.vocab[w] for w in doc_words if w in model.wv.vocab
and model.wv.vocab[w].sample_int > model.random.rand() * 2 ** 32]
# 遍历每一个词
for pos, word in enumerate(word_vocabs):
# 对窗口进行reduce
reduced_window = model.random.randint(model.window) # `b` in the original doc2vec code
# 计算窗口的起止位置
start = max(0, pos - model.window + reduced_window)
window_pos = enumerate(word_vocabs[start:(pos + model.window + 1 - reduced_window)], start)
# 获取窗口内,除预测目标词之外,其他上下文词的id
word2_indexes = [word2.index for pos2, word2 in window_pos if pos2 != pos]
# 将词向量和doc向量求和成为上下文向量
l1 = np_sum(word_vectors[word2_indexes], axis=0) + np_sum(doctag_vectors[doctag_indexes], axis=0)
# 计算求和的向量总数
count = len(word2_indexes) + len(doctag_indexes)
# 这里是取向量求和之后的均值
if model.cbow_mean and count > 1:
l1 /= count
# 计算更新的梯度,这里是复用了word2vec模型中train_cbow_pair的方法
# 设置learn_vectors=False,表示不在train_cbow_pair方法内更新上下文向量
# 而是获取到计算的梯度之后在本方法内更新
neu1e = train_cbow_pair(model, word, word2_indexes, l1, alpha,
learn_vectors=False, learn_hidden=learn_hidden)
# 如果当前的方法不是取平均,说明计算的梯度是所有向量的共同梯度
# 则要对梯度取平均
if not model.cbow_mean and count > 1:
neu1e /= count
# 更新doc的向量
if learn_doctags:
for i in doctag_indexes:
doctag_vectors[i] += neu1e * doctag_locks[i]
# 更新词向量
if learn_words:
for i in word2_indexes:
word_vectors[i] += neu1e * word_locks[i]
return len(word_vocabs)
- 通过concatenate计算上下文向量
2. Distributed Bag ofWords version of Paragraph Vector (PV-DBOW)
2.1 模型架构图
有点类似word2vec中的Skip-gram模型,根据paragraph向量来预测窗口内的词向量。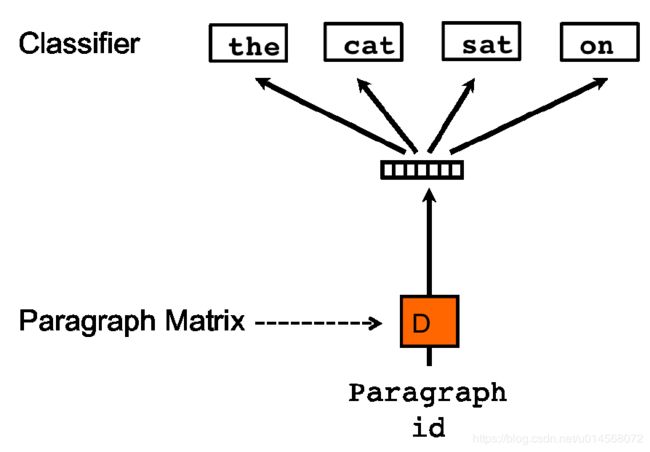
2.2 相关代码理解
def train_document_dbow(model, doc_words, doctag_indexes, alpha, work=None,
train_words=False, learn_doctags=True, learn_words=True, learn_hidden=True,
word_vectors=None, word_locks=None, doctag_vectors=None, doctag_locks=None):
"""Update distributed bag of words model ("PV-DBOW") by training on a single document.
Called internally from :meth:`~gensim.models.doc2vec.Doc2Vec.train` and
:meth:`~gensim.models.doc2vec.Doc2Vec.infer_vector`.
Notes
-----
This is the non-optimized, Python version. If you have cython installed, gensim
will use the optimized version from :mod:`gensim.models.doc2vec_inner` instead.
Parameters
----------
model : :class:`~gensim.models.doc2vec.Doc2Vec`
The model to train.
doc_words : list of str
The input document as a list of words to be used for training. Each word will be looked up in
the model's vocabulary.
doctag_indexes : list of int
Indices into `doctag_vectors` used to obtain the tags of the document.
alpha : float
Learning rate.
work : np.ndarray
Private working memory for each worker.
train_words : bool, optional
Word vectors will be updated exactly as per Word2Vec skip-gram training only if **both**
`learn_words` and `train_words` are set to True.
learn_doctags : bool, optional
Whether the tag vectors should be updated.
learn_words : bool, optional
Word vectors will be updated exactly as per Word2Vec skip-gram training only if **both**
`learn_words` and `train_words` are set to True.
learn_hidden : bool, optional
Whether or not the weights of the hidden layer will be updated.
word_vectors : object, optional
UNUSED.
word_locks : object, optional
UNUSED.
doctag_vectors : list of list of float, optional
Vector representations of the tags. If None, these will be retrieved from the model.
doctag_locks : list of float, optional
The lock factors for each tag.
Returns
-------
int
Number of words in the input document.
"""
# doctag_vectors是否为空的判断,是为了区分当前是训练模式还是预测模式
# 为空表示训练过程,从模型中直接读入
# 不为空是预测过程,会预先生成一个随机向量传入
if doctag_vectors is None:
doctag_vectors = model.docvecs.doctag_syn0
if doctag_locks is None:
doctag_locks = model.docvecs.doctag_syn0_lockf
# 这里复用的是word2vec中train_batch_sg方法,原理是通过当前词来预测上下文
# 但是对于Docvec模型来说,当前词就是当前的paragraph vector,上下文就是段落中的每一个词
# 因此context_vectors指定为当前的paragraph vector
if train_words and learn_words:
train_batch_sg(model, [doc_words], alpha, work)
for doctag_index in doctag_indexes:
for word in doc_words:
train_sg_pair(
model, word, doctag_index, alpha, learn_vectors=learn_doctags, learn_hidden=learn_hidden,
context_vectors=doctag_vectors, context_locks=doctag_locks
)
return len(doc_words)
3. Doc2vec的预测过程
3.1 预测原理
先给新的doc分配一个随机的向量,根据指定的模型,使用固定词向量和隐藏单元的向量不更新,
3.2 相关代码阅读
def infer_vector(self, doc_words, alpha=None, min_alpha=None, epochs=None, steps=None):
"""Infer a vector for given post-bulk training document.
Notes
-----
Subsequent calls to this function may infer different representations for the same document.
For a more stable representation, increase the number of steps to assert a stricket convergence.
Parameters
----------
doc_words : list of str
A document for which the vector representation will be inferred.
预测的doc,是一个string类型的list
alpha : float, optional
The initial learning rate. If unspecified, value from model initialization will be reused.
min_alpha : float, optional
Learning rate will linearly drop to `min_alpha` over all inference epochs. If unspecified,
value from model initialization will be reused.
epochs : int, optional
Number of times to train the new document. Larger values take more time, but may improve
quality and run-to-run stability of inferred vectors. If unspecified, the `epochs` value
from model initialization will be reused.
steps : int, optional, deprecated
Previous name for `epochs`, still available for now for backward compatibility: if
`epochs` is unspecified but `steps` is, the `steps` value will be used.
Returns
-------
np.ndarray
The inferred paragraph vector for the new document.
"""
if isinstance(doc_words, string_types):
raise TypeError("Parameter doc_words of infer_vector() must be a list of strings (not a single string).")
alpha = alpha or self.alpha
min_alpha = min_alpha or self.min_alpha
epochs = epochs or steps or self.epochs
# 给一个新的doc生成一个随机的向量
doctag_vectors, doctag_locks = self.trainables.get_doctag_trainables(doc_words, self.docvecs.vector_size)
doctag_indexes = [0]
work = zeros(self.trainables.layer1_size, dtype=REAL)
if not self.sg:
neu1 = matutils.zeros_aligned(self.trainables.layer1_size, dtype=REAL)
alpha_delta = (alpha - min_alpha) / max(epochs - 1, 1)
# 根据参数选择对应的模型:DM/DM-CONCAT/DBOW
for i in range(epochs):
# 预测的过程中,固定词向量和隐藏单元不更新,只更新doc的向量:doctag_vectors
if self.sg:
train_document_dbow(
self, doc_words, doctag_indexes, alpha, work,
learn_words=False, learn_hidden=False, doctag_vectors=doctag_vectors, doctag_locks=doctag_locks
)
# neu1参数目前是没有用的:unused
elif self.dm_concat:
train_document_dm_concat(
self, doc_words, doctag_indexes, alpha, work, neu1,
learn_words=False, learn_hidden=False, doctag_vectors=doctag_vectors, doctag_locks=doctag_locks
)
else:
train_document_dm(
self, doc_words, doctag_indexes, alpha, work, neu1,
learn_words=False, learn_hidden=False, doctag_vectors=doctag_vectors, doctag_locks=doctag_locks
)
alpha -= alpha_delta
# 返回更新完成的paragraph vector
return doctag_vectors[0]