【今日CV 计算机视觉论文速览 第99期】Fri, 12 Apr 2019
今日CS.CV 计算机视觉论文速览
Fri, 12 Apr 2019
Totally 50 papers
?上期速览 ✈更多精彩请移步主页

Interesting:
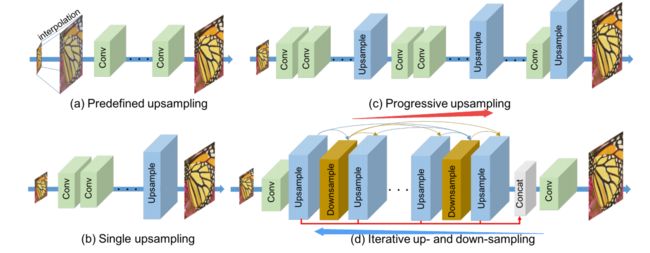
?DBPN基于深度方向传播的图像超分辨,基于前向传播的超分辨模型并不能很好地解决 高低分辨率图像间的相互依存问题,研究人员提出了深度方向网络,采用迭代的上下采样层来提高模型的性能。这种方法为前传单元提供了误差反馈机制。研究中为不同的图像退化过程建立了双向链接的上下采样过程。并并这种思想拓展到了递归网络、稠密网络和残差学习中来提高模型表现。(from 丰田技术研究院 芝加哥 )
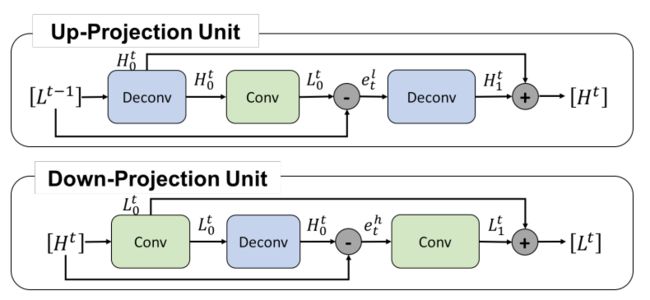
提出的迭代上下采样及上下映射单元:
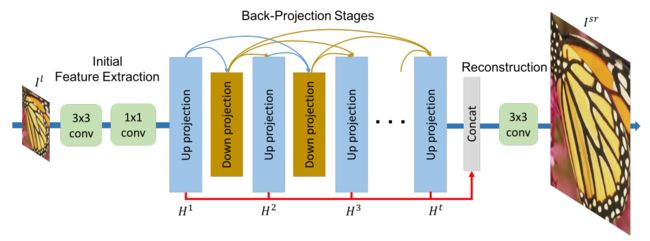
基于稠密连接的架构图,反传使得特征可以复用:
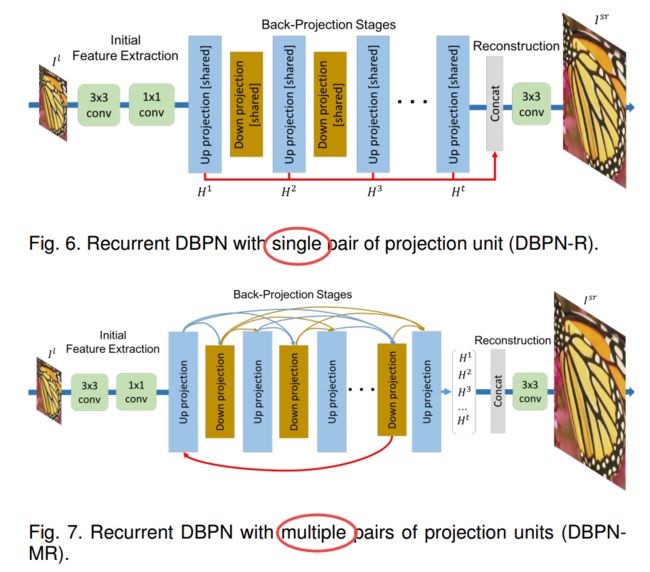
单对和多对映射:
模型的表现和结果:


与一系列其他方法的比较:
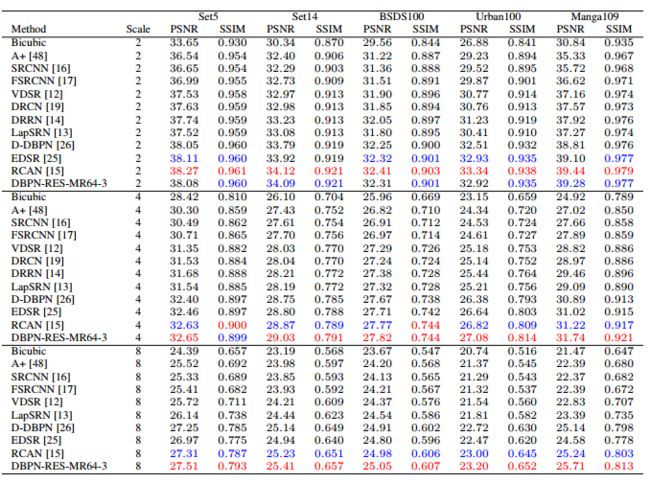
?基于图卷积的稠密人脸对齐, 3D人脸重建和对齐逐渐整合到单一任务中来,这篇文章提出了一种基于图卷积神经网络的人脸坐标回归系统,并直接在3D人脸网格上进行操作,并保持了几何结构和细节信息。(from 华为、旷视 )
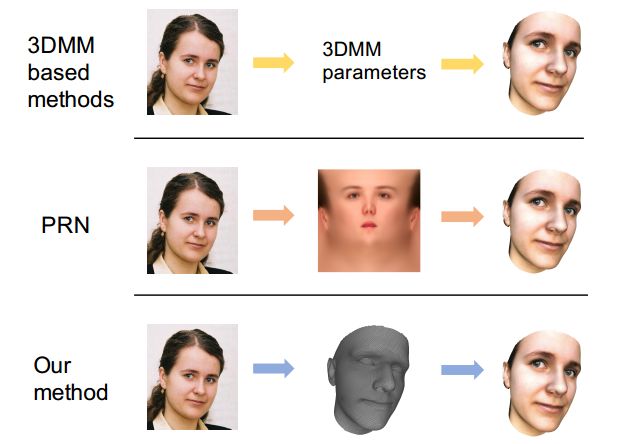
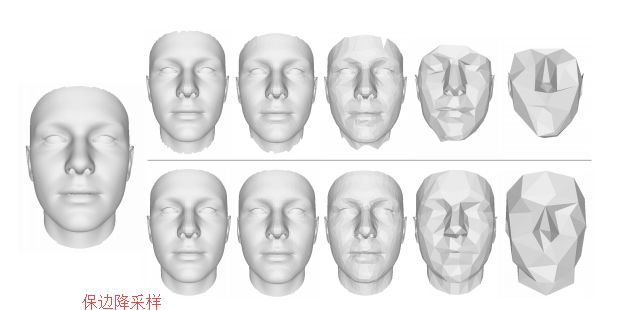
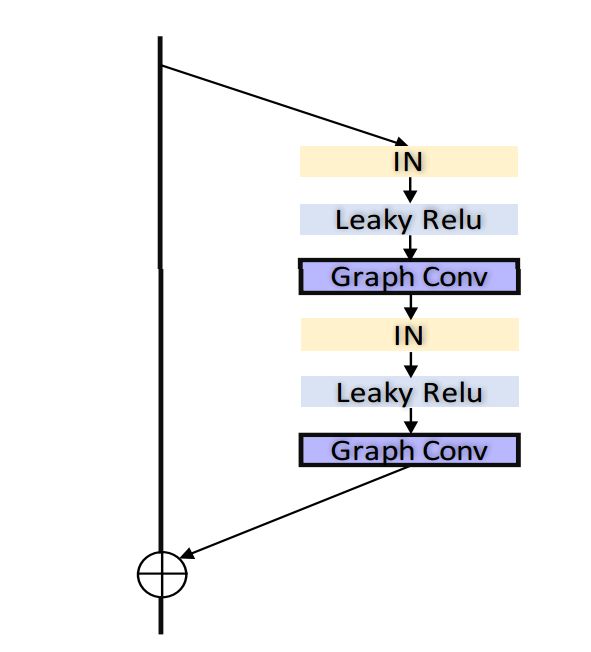
解码器细节和图卷积残差模块:

dataset:AFLW2000-3D AFLW-LFPA Florence
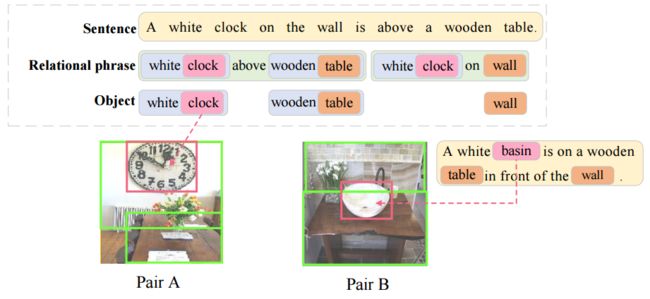
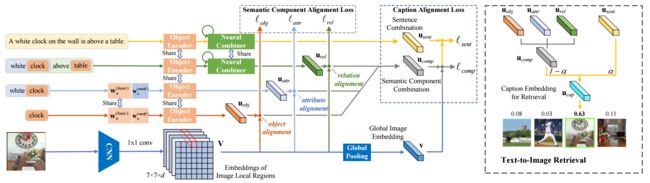
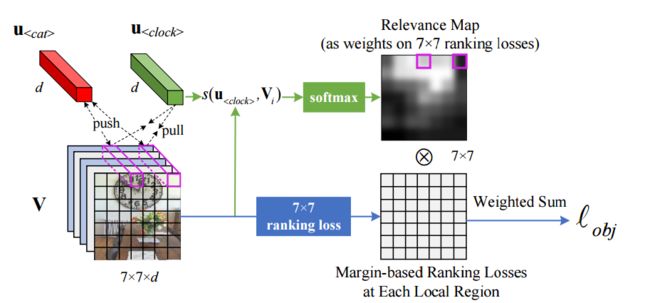
?Unified Visual-Semantic Embeddings, 提出了一个视觉与语义联合的嵌入空间,搭建起了视觉图像和语言沟通的桥梁。从对象、属性、关系和全景等层次展开,并将语义序列视为不同语义元素的结合,并将其匹配到不同的图像区域。(from 复旦大学)
语义与图像的匹配:
VSE的架构图:
相关权重匹配和一些结果:

Common Crawl dataset
?多标签分类问题的探究, 基于五个数据集(VOC, COCO, NUSWIDE,
ADE20k and Recipe1M)分析了针对多任务分类问题的适用性。研究发现,图像中出现多个共生标签以及预测的标签数十分重要,超参数调参会带来明显的提升,并在3个数据集上得到了最优秀的结果。(from facebook)
不同数据集的预测及结构:

·code:http://anonymous.url/
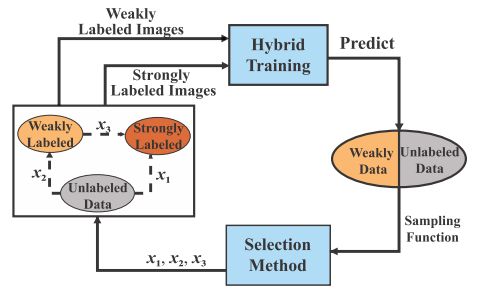
?BAOD: Budget-Aware Object Detection, (from 洛斯安第斯大学 加州)
Daily Computer Vision Papers
| Factor Graph Attention Authors Idan Schwartz, Seunghak Yu, Tamir Hazan, Alexander Schwing 对话是交换信息的有效方式,但细微的细节和细微差别非常重要。尽管取得了重大进展,但已经为解决算法的视觉对话铺平了道路,但细节和细微差别仍然是一个挑战。注意机制已经证明了在视觉问题回答中提取细节的令人信服的结果,并且由于其可解释性和有效性而为视觉对话提供了令人信服的框架。然而,伴随视觉对话的许多数据工具挑战了现有的注意力技术。我们解决了这个问题,并开发了一个可视对话的一般注意机制,可以在任意数量的数据工具上运行。为此,我们设计了一个基于因子图的注意机制,它结合了任意数量的效用表示。我们说明了所提出的方法对具有挑战性和最近引入的VisDial数据集的适用性,在VisDial0.9上优于1.1的最新技术方法,在MRR上优于VisDial1.0的2。我们的集合模型将VisDial1.0的MRR得分提高了6个以上。 |
| Two Body Problem: Collaborative Visual Task Completion Authors Unnat Jain, Luca Weihs, Eric Kolve, Mohammad Rastegari, Svetlana Lazebnik, Ali Farhadi, Alexander Schwing, Aniruddha Kembhavi 协作是执行超出一个代理功能的任务的必要技能。广泛应用于传统和现代AI,多代理协作通常在简单的网格世界中进行研究。我们认为合作存在固有的视觉方面,应该在视觉丰富的环境中进行研究。协作中的一个关键要素是通过显示,通过消息或隐式,通过对其他代理和视觉世界的感知来进行通信。学习在视觉环境中进行协作需要学习1来执行任务,2何时和什么进行交流,以及3如何基于这些通信和视觉世界的感知来行动。在本文中,我们研究了直接从AI2 THOR中的像素进行协作的问题,并展示了显式和隐式通信模式执行视觉任务的好处。有关详细信息,请参阅我们的项目页面 |
| A Simple Baseline for Audio-Visual Scene-Aware Dialog Authors Idan Schwartz, Alexander Schwing, Tamir Hazan 最近提出的视听场景感知对话任务为学习虚拟助手,智能扬声器和汽车导航系统的更加数据驱动的方式铺平了道路。然而,迄今为止,关于如何从过多的传感器中有效地提取有意义的信息以及这些设备的计算引擎的知识,我们知之甚少。因此,在本文中,我们提供并仔细分析了一个端到端训练的视听场景感知对话的简单基线。我们的方法使用注意机制以数据驱动的方式区分来自分散注意力的信号的有用信号。我们在最近推出的具有挑战性的视听场景知识数据集上评估了所提出的方法,并展示了在CIDEr上超过现有技术水平超过20的关键特性。 |
| An Empirical Study of Spatial Attention Mechanisms in Deep Networks Authors Xizhou Zhu, Dazhi Cheng, Zheng Zhang, Stephen Lin, Jifeng Dai 注意机制已成为深度神经网络中的一个流行组件,但很少有人研究不同的影响因素和计算这些因素影响性能的方法如何影响性能。为了更好地理解注意力机制,我们提出了一个实证研究,该研究消除了广义注意力公式中的各种空间注意力元素,包括主要的变压器注意以及普遍的可变形卷积和动态卷积模块。该研究针对各种应用进行了研究,得出了深层网络空间关注的重要发现,其中一些与传统理解背道而驰。例如,我们发现Transformer关注中的查询和关键内容比较对于自我关注是微不足道的,但对编码器解码器的关注至关重要。可变形卷积与关键内容的适当组合仅显着性实现了自我关注中的最佳准确性效率权衡。我们的研究结果表明,注意机制的设计存在很大的改进空间。 |
| An Analysis of Pre-Training on Object Detection Authors Hengduo Li, Bharat Singh, Mahyar Najibi, Zuxuan Wu, Larry S. Davis 我们提供了对卷积神经网络的详细分析,这些网络是在对象检测任务上预先训练过的。为此,我们在大型数据集上训练检测器,如OpenImagesV4,ImageNet Localization和COCO。我们分析了它们的特征在PASCAL VOC,Caltech 256,SUN 397,Flowers 102等小数据集上的图像分类,语义分割和对象检测等任务的概括性。我们分析的一些重要结论是1大型检测数据集的预训练是对于小型检测数据集的微调至关重要,尤其是在需要精确定位时。例如,我们在OpenImagesV4预培训后,在0.7 IoU的PASCAL VOC数据集上获得81.1 mAP,比最近提出的使用ImageNet预训练的DeformableConvNetsV2好7.6。 2检测预训练也有利于其他定位任务,如语义分割,但会对图像分类产生不利影响。 3平均图像的功能。在物体检测特征空间中类似的汇集Conv5在图像分类特征空间中可能是相似的,但反之则不然。 4特征的可视化揭示了检测神经元在整个物体上具有激活,而分类网络的激活通常集中在部分上。因此,当图像中存在多个实例或者实例仅覆盖图像的一小部分时,检测网络在分类方面较差。 |
| Improved training of binary networks for human pose estimation and image recognition Authors Adrian Bulat, Georgios Tzimiropoulos, Jean Kossaifi, Maja Pantic 在大型数据集上训练的大型神经网络已经为各种具有挑战性的问题提升了现有技术水平,大大提高了性能。然而,在低内存和有限的计算能力限制下,相同问题的准确性下降很多。在本文中,我们提出了一系列技术,可以显着提高二值化神经网络的准确性,即特征和权重都是二进制的网络。我们评估了两种不同任务的细粒度识别人体姿态估计和大规模图像识别ImageNet分类的建议改进。具体而言,我们引入了一系列新的方法变化,包括更合适的激活函数,b逆序初始化,c渐进量化和d网络堆叠,并且显示这些添加显着改善了现有技术的网络二值化技术。此外,我们还首次研究了网络二值化和知识蒸馏可以结合的程度。在具有挑战性的MPII数据集上进行测试时,我们的方法显示绝对值的性能提升超过4。最后,我们通过在Imagenet数据集上应用所提出的大规模目标识别技术来进一步验证我们的发现,我们在其上报告错误率降低了4。 |
| Expressive Body Capture: 3D Hands, Face, and Body from a Single Image Authors Georgios Pavlakos, Vasileios Choutas, Nima Ghorbani, Timo Bolkart, Ahmed A. A. Osman, Dimitrios Tzionas, Michael J. Black 为了便于分析人类行为,交互和情感,我们从单个单眼图像计算人体姿势,手姿势和面部表情的3D模型。为了实现这一目标,我们使用数以千计的3D扫描来训练人体SMPL X的全新统一3D模型,该模型通过完全清晰的双手和富有表情的脸部来扩展SMPL。如果没有配对图像和3D基础事实,学习直接从图像中回归SMPL X的参数是一项挑战。因此,我们遵循SMPLify的方法,该方法估计2D特征,然后优化模型参数以适合特征。我们以几个重要的方式改进SMPLify 1我们检测对应于面部,手部和脚部的2D特征并将完整的SMPL X模型拟合到这2个我们在使用大型MoCap数据集之前训练新的神经网络姿势3我们定义了一个新的快速和准确的互穿惩罚4我们自动检测性别和适当的身体模型男性,女性或中性5我们的PyTorch实现比Chumpy实现超过8倍的加速。我们使用新方法SMPLify X将SMPL X适用于野外的受控图像和图像。我们在包含100个具有伪基础事实的图像的新策划数据集上评估3D准确度。这是从单眼RGB数据向自动表达人类捕获迈出的一步。模型,代码和数据可用于研究目的 |
| MAIN: Multi-Attention Instance Network for Video Segmentation Authors Juan Leon Alcazar, Maria A. Bravo, Ali K. Thabet, Guillaume Jeanneret, Thomas Brox, Pablo Arbelaez, Bernard Ghanem 实例级视频分段需要空间和时间信息的可靠集成。然而,当前的方法主要依赖于在线学习的领域特定信息来产生准确的实例级分割。我们提出了一种新颖的方法,它完全依赖于通用空间时间关注线索的整合。我们的策略名为Multi Attention Instance Network MAIN,可以克服任意视频中具有挑战性的分段场景,而无需建模序列或实例特定知识。我们设计MAIN以在单个前向传递中分割多个实例,并使用新的损失函数对其进行优化,该函数有利于类别不可知的预测并分配实例特定的惩罚。我们在具有挑战性的Youtube VOS数据集和基准测试中实现了最先进的性能,分别将看不见的Jaccard和F Metric提高了6.8和12.7,同时实时运行30.3 FPS。 |
| Variational Information Distillation for Knowledge Transfer Authors Sungsoo Ahn, Shell Xu Hu, Andreas Damianou, Neil D. Lawrence, Zhenwen Dai 将来自在相同或类似任务上预先训练的教师神经网络的知识传递给学生神经网络可以显着改善学生神经网络的性能。现有的知识转移方法与教师和学生网络的激活或相应的手工制作特征相匹配。我们提出了一种知识转移的信息理论框架,它将知识转移制定为最大化教师与学生网络之间的互信息。我们将我们的方法与现有知识转移方法在知识蒸馏和转移学习任务上进行比较,并表明我们的方法始终优于现有方法。我们通过将来自卷积神经网络CNN的知识转移到CIFAR 10上的多层感知器MLP,进一步证明了我们的方法在跨异构网络架构的知识转移方面的优势。得到的MLP明显优于现有技术方法,并且实现了类似的性能使用单个卷积层到CNN。 |
| Learning Single Camera Depth Estimation using Dual-Pixels Authors Rahul Garg, Neal Wadhwa, Sameer Ansari, Jonathan T. Barron 深度学习技术使单眼深度估计得以迅速发展,但其质量受到问题的不良性质和高质量数据集的稀缺性的限制。我们通过利用现代相机传感器中越来越常见的双像素自动对焦硬件,从单个相机估算深度。当应用于这种双像素数据时,经典立体算法和基于先验学习的深度估计技术正在执行,前者由于对RGB图像匹配的过于强烈的假设,而后者由于缺乏对双像素图像形成的光学的理解。为了使基于学习的方法能够很好地处理双像素图像,我们确定了从双像素线索估计的深度中的固有模糊度,并开发了一种估计深度到达这种模糊度的方法。使用我们的方法,现有的单眼深度估计技术可以有效地应用于双像素数据,并且可以构建仍然推断高质量深度的更小的模型。为了证明这一点,我们捕获了与对应的双像素数据配对的野生5视点RGB图像的大型数据集,并展示了如何使用该数据进行视图监督来学习深度到未知的模糊度。在我们的新任务中,我们的模型比基于学习的单眼或立体深度估计的任何先前工作更准确30。 |
| Probabilistic Permutation Synchronization using the Riemannian Structure of the Birkhoff Polytope Authors Tolga Birdal, Umut im ekli 我们提出了一种全新的几何和概率方法,用于跨多组对象或图像的对应同步。特别地,我们提出了两种算法1 Birkhoff Riemannian L BFGS,用于以原则方式优化组合式难处理循环一致性损失的松弛版本,2 Birkhoff Riemannian Langevin Monte Carlo用于在Birkhoff Polytope上生成样本并估计找到的解决方案的置信度。为此,我们首先介绍最近开发的Birkhoff Polytope的黎曼几何。接下来,我们以马尔可夫随机场MRF的形式引入新的概率同步模型。最后,基于一阶回归算子,我们将问题表达为模拟随机微分方程并设计新的积分器。我们在合成和真实数据集上显示,我们实现了高质量的多图匹配结果,具有更快的收敛性和可靠的置信度不确定性估计。 |
| Difficulty-aware Image Super Resolution via Deep Adaptive Dual-Network Authors Jinghui Qin, Ziwei Xie, Yukai Shi, Wushao Wen 近来,基于深度学习的单图像超分辨率SR方法取得了很大的发展。现有技术的SR方法通常采用前馈流水线来建立低分辨率LR和高分辨率HR图像之间的非线性映射。然而,由于在不考虑难度多样性的情况下平等地处理所有图像区域,这些方法满足优化的上限。为了解决这个问题,我们提出了一种新颖的SR方法,该方法通过其难度区分地处理图像内的每个图像区域。具体来说,我们提出了一种双向SR网络,其中一种方式被训练以专注于简单的图像区域而另一种方式被训练以处理硬图像区域。为了识别区域是容易还是硬,我们提出了一种基于PSNR先验的新型图像难度识别网络。我们使用区域掩码自适应地实施双向SR网络的SR方法产生了优异的结果。几个标准基准测试的广泛实验,例如Set5,Set14,BSD100和Urban100,表明我们的方法达到了最先进的性能。 |
| Learning joint reconstruction of hands and manipulated objects Authors Yana Hasson, G l Varol, Dimitrios Tzionas, Igor Kalevatykh, Michael J. Black, Ivan Laptev, Cordelia Schmid 估计手部物体操纵对于解释和模仿人类行为至关重要。以前的工作在单独重建手部姿势和物体形状方面取得了重大进展。然而,由于手和物体的明显闭塞,在操纵期间重建手和物体是更具挑战性的任务。在提出挑战时,操作也可以简化问题,因为接触物理限制了有效手对象配置的空间。例如,在操纵过程中,手和物体应该接触但不能相互穿透。在这项工作中,我们通过操纵约束来规范手和物体的联合重建。我们提出了一种端到端的可学习模型,该模型利用了一种有利于物理上可信的手对象星座的新型接触损失。我们的方法使用RGB图像作为输入,提高了基线的抓取质量指标。为了训练和评估模型,我们还提出了一个新的大规模合成数据集ObMan,它具有手对象操作。我们证明了ObMan训练模型对实际数据的可转移性。 |
| A Relation-Augmented Fully Convolutional Network for Semantic Segmentationin Aerial Scenes Authors Lichao Mou, Yuansheng Hua, Xiao Xiang Zhu 大多数当前的语义分割方法依赖于深度卷积神经网络CNN。然而,他们使用具有局部感受域的卷积运算导致对建模上下文空间关系的失败。先前的工作已经试图通过在网络中使用图形模型或空间传播模块来解决该问题。但是这样的模型经常无法捕获实体之间的长距离空间关系,这导致空间碎片化的预测。此外,最近的工作已经证明渠道明智的信息也是CNN中的关键部分。在这项工作中,我们引入了两个简单但有效的网络单元,即空间关系模块和信道关系模块,以学习和推理任何两个空间位置或特征图之间的全局关系,然后产生关系增强特征表示。空间和信道关系模块是通用的和可扩展的,并且可以与现有的完全卷积网络FCN框架一起以即插即用的方式使用。我们使用两个航空图像数据集评估关系模块配置网络的语义分割任务,这些数据集从根本上依赖于远程空间关系推理。这些网络取得了非常有竞争力的成果,在基线方面取得了重大进 |
| FTGAN: A Fully-trained Generative Adversarial Networks for Text to Face Generation Authors Xiang Chen, Lingbo Qing, Xiaohai He, Xiaodong Luo, Yining Xu 作为文本到图像合成的子领域,文本到面世代在公共安全领域具有巨大的潜力。由于缺乏数据集,几乎没有相关的研究侧重于文本面对综合。在本文中,我们提出了一个训练有素的生成性对抗网络FTGAN,它同时训练文本编码器和图像解码器,以生成细粒度文本。通过一个新颖的完全训练的生成网络,FTGAN可以合成更高质量的图像,并敦促FTGAN的输出与输入句子更相关。此外,我们构建了一个名为SCU Text2face的数据集,用于文本到面部合成。通过大量实验,FTGAN展示了其在提高生成的图像质量和与输入描述的相似性方面的优势。拟议的FTGAN优于先前的技术水平,在CUB数据集上将报告的最佳初始分数提高到4.63。在SCU text2face上,我们提出的FTGAN仅根据输入描述生成的人脸图像与基础事实平均具有相似性,这为文本面对综合设置了基线。 |
| Reconstructing Network Inputs with Additive Perturbation Signatures Authors Nick Moran, Chiraag Juvekar 在这项工作中,我们提出初步结果,证明能够恢复关于秘密模型输入的大量信息,因为只能非常有限地访问模型输出,并且能够评估模型对输入的加性扰动。 |
| Elucidating image-to-set prediction: An analysis of models, losses and datasets Authors Luis Pineda, Amaia Salvador, Michal Drozdzal, Adriana Romero 近年来,我们在多标签分类文献中经历了一系列的贡献。从预测独立标签到通过建筑和/或损失功能设计建模标签共现,这个问题在不同的视角下构建。尽管取得了很大进展,但仍然不清楚哪种建模选择最适合解决这一任务,部分原因是缺乏明确的基准。因此,在本文中,我们提供了五种不同的计算机视觉数据集的深入分析,这些数据集的任务复杂度增加,适用于多标签分类VOC,COCO,NUS WIDE,ADE20k和Recipe1M。我们的结果表明,1个建模标签共同出现并预测出现在图像中的标签数量很重要,特别是在高维输出空间中2仔细调整非常简单基线的超参数可以带来显着的改进,与之前报告的结果相当,3作为我们分析的结果,我们在3个数据集上实现了最先进的结果,与之前公布的方法的公平比较是可行的。 |
| Deep Back-Projection Networks for Single Image Super-resolution Authors Muhammad Haris, Greg Shakhnarovich, Norimichi Ukita 最近提出的深度超分辨率网络的先前前馈架构学习了低分辨率输入的特征以及从那些到高分辨率输出的非线性映射。然而,这种方法并未完全解决低分辨率图像和高分辨率图像的相互依赖性。我们提出深度反投影网络DBPN,它是两个图像超分辨率挑战NTIRE2018和PIRM2018的赢家,它们利用迭代的上下采样层。这些层形成为提供投影误差的误差反馈机制的单元。我们构造相互连接的上下采样单元,每个单元代表不同类型的图像劣化和高分辨率组件。我们还展示了将这一想法扩展到应用最新深度网络趋势的多种变体,例如循环网络,密集连接和残差学习,以提高性能。实验结果产生了优异的结果,特别是在多个数据集中建立新的现有技术结果,特别是对于诸如8x的大比例因子。 |
| YUVMultiNet: Real-time YUV multi-task CNN for autonomous driving Authors Thomas Boulay, Said El Hachimi, Mani Kumar Surisetti, Pullarao Maddu, Saranya Kandan 在本文中,我们提出了一种针对低功率汽车级SoC优化的多任务卷积神经网络CNN架构。我们引入了基于统一架构的网络,其中编码器在两个任务之间共享,即检测和分段。专业网络以25FPS运行,分辨率为1280x800。我们简要讨论了用于优化网络架构的方法,例如直接使用原生YUV图像,优化层特征图和应用量化。我们还专注于设计中的内存带宽,因为卷积是数据密集型的,大多数SOC都是带宽瓶颈。然后,我们展示了我们提出的专用CNN加速器网络的效率,该加速器显示了从硬件执行和相应的运行时间获得的检测和分段任务的关键性能指标KPI。 |
| Software Based Higher Order Structural Foot Abnormality Detection Using Image Processing Authors Arnesh Sen, Kaustav Sen, Jayoti Das 人体的整个运动经历一个名为步态循环的周期性过程。人脚结构是成功完成周期的关键因素。这种足部结构的异常是一种令人担忧的先天性疾病形式,其导致基于人类足印图像的几何形状的分类。图像处理是确定多个足迹参数以检测疾病严重性的最有效方式之一。本文旨在通过生物医学图像处理使用改良布鲁肯指数的足迹参数之一来检测扁平足和高拱足异常。 |
| C-MIL: Continuation Multiple Instance Learning for Weakly Supervised Object Detection Authors Fang Wan, Chang Liu, Wei Ke, Xiangyang Ji, Jianbin Jiao, Qixiang Ye 弱监督对象检测WSOD在提供图像类别监督时是一项具有挑战性的任务,但需要同时学习对象位置和对象检测器。许多WSOD方法采用多实例学习MIL并且具有非凸损失函数,这些函数容易陷入局部最小值,错误地定位对象部分,同时在训练期间缺少完整对象范围。在本文中,我们将继续优化方法引入MIL,从而创建连续多实例学习C MIL,旨在系统地减轻非凸性问题。我们将实例划分为空间相关和类相关的子集,并使用在子集内定义的一系列平滑损失函数来近似原始损失函数。优化平滑损失函数可防止训练过程过早地进入局部最小值,并有助于发现指示完整对象范围的稳定语义极值区域SSER。在PASCAL VOC 2007和2012数据集中,C MIL改进了弱监督对象检测和弱监督对象定位的大规模边缘技术。 |
| Retinal Vessels Segmentation Based on Dilated Multi-Scale Convolutional Neural Network Authors Yun Jiang, Ning Tan, Tingting Peng, Hai Zhang 准确分割视网膜血管是糖尿病视网膜病变DR检测的基本步骤。大多数基于深度卷积神经网络DCNN的方法具有较小的感受野,因此它们无法捕获较大区域的全局背景信息,难以识别病变。最终分割的视网膜血管包含更多噪声,分类精度低。因此,在本文中,我们提出了一个名为D Net的DCNN结构。在所提出的D网中,扩张卷积用于骨干网络中以获得更大的感受野而不损失空间分辨率,从而减少特征信息的丢失并减少细小血管分割的难度。大的感受野可以更好地区分病变区域和血管区域。在所提出的多尺度信息融合模块MSIF中,使用具有不同扩张率的并行卷积层,使得该模型可以获得更密集的特征信息并且更好地捕获不同尺寸的视网膜血管信息。在解码模块中,跳过层连接用于将上下文信息传播到更高分辨率的层,以防止低级信息通过整个网络结构。最后,我们的方法在DRIVE,STARE和CHASE数据集上得到验证。实验结果表明,我们的网络结构在准确性,灵敏度,特异性和AUCROC方面优于N4领域,U Net和DRIU等现有技术方法。特别是,D Net在DRIVE,STARE和CHASE三数据集中的U Net分别优于1.04,1.23和2.79。 |
| Detecting Repeating Objects using Patch Correlation Analysis Authors Inbar Huberman, Raanan Fattal 在本文中,我们描述了一种检测和计算图像中重复对象的新方法。虽然该方法依赖于相当复杂的可变形零件模型,但与现有技术不同,它以无监督的方式估计模型参数,因此减轻了对用户注释的训练数据的需要并避免了相关的特异性。通过利用与重复对象相关联的小图像块的重现并分析它们的空间相关性来执行该自动拟合过程。分析允许我们拒绝异常补丁,恢复零件模型的视觉和形状参数,并有效地检测对象实例。为了实现能够处理各种图像的实用系统,我们描述了一种简单直观的主动学习过程,通过在极少数精心选择的边际分类上查询用户来更新对象分类。针对现有技术的新方法的评估证明了其通过更好的用户体验实现更高准确度的能力。 |
| Reducing Lateral Visual Biases in Displays Authors Inbar Huberman, Raanan Fattal 人类视觉系统由多个生理组件组成,这些组件应用多种机制以应对它遇到的丰富的视觉内容。这个系统的复杂性导致了我们所看到的和我们所感知的,特别是我们展示的图像的原始强度和我们所感知的各种视觉偏见和幻想被引入的图像之间的非平凡关系。在本文中,我们描述了一种减少与人视网膜中侧向抑制机制相关的大类偏倚的方法,其中神经元抑制邻近受体的活性。在这些偏差中,众所周知的马赫带和晕圈出现在平滑和清晰的图像梯度周围以及相同区域之间的假对比的出现。新方法通过计算包含反偏差的图像来消除这些视觉偏差,使得当在显示器上观看该横向补偿图像时,插入的偏差取消在视网膜中产生的偏差。 |
| Recurrent Space-time Graphs for Video Understanding Authors Andrei Nicolicioiu, Iulia Duta, Marius Leordeanu 在时空领域的视觉学习仍然是人工智能中非常具有挑战性的问题。用于理解视频数据的当前计算模型深深扎根于基于经典单图像的范例。如何将来自空间和时间的视觉信息整合到单个通用模型中尚不清楚。我们提出了一种神经图模型,在空间和时间上反复出现,适用于捕捉不断变化的世界场景中不同实体和物体的外观和复杂的相互作用。我们图中的节点和链接具有专用的神经网络来处理信息。边缘处理不同位置和比例的连接节点之间或过去和当前时间之间的消息。节点计算从空间和时间的本地部分提取的特征以及从其邻居和先前的存储器状态接收的消息。消息以迭代方式传递,以便全局传输信息并建立长距离交互。我们的模型是通用的,可以学习识别各种高级时空概念,并应用于不同的学习任务。我们通过广泛的实验证明,在识别视频中复杂的运动模式的任务中,在强大的基线上具有竞争性。 |
| FRNET: Flattened Residual Network for Infant MRI Skull Stripping Authors Qian Zhang, Li Wang, Xiaopeng Zong, Weili Lin, Gang Li, Dinggang Shen 脑部MR图像的头骨剥离是一项基本的分割任务。虽然已经提出了许多方法,但是大多数方法主要集中在成人MR图像上。由于早期脑组织的小尺寸和动态强度变化,颅骨剥离婴儿MR图像更具挑战性。在本文中,我们提出了一种新的基于CNN的框架,可以在没有任何人工辅助的情况下从婴儿MR图像中稳健地提取大脑区域。具体而言,我们提出了一种简化但更稳健的扁平剩余网络架构FRnet。我们还引入了一种新的边界损失函数来突出大脑和非大脑区域之间的模糊和低对比度区域。为了使整个框架对具有不同成像质量的MR图像更加鲁棒,我们进一步引入了用于数据增强的伪像模拟器。我们已经在大型数据集N 343上培训和测试了我们提出的框架,涵盖了48个月大的新生儿,并且在所有年龄组中获得了比最先进方法更好的表现。 |
| 3D Dense Face Alignment via Graph Convolution Networks Authors Huawei Wei, Shuang Liang, Yichen Wei 最近,3D面部重建和面部对齐任务逐渐组合成一个任务3D密集面部对齐。其目标是用姿势信息重建脸部的3D几何结构。在本文中,我们提出了一个图形卷积网络来回归3D面部坐标。我们的方法直接在3D面部网格上进行特征学习,其中几何结构和细节得到很好的保留。大量实验表明,我们的方法在几个具有挑战性的数据集上获得了优于现有技术方法的卓越性能。 |
| Reasoning Visual Dialogs with Structural and Partial Observations Authors Zilong Zheng, Wenguan Wang, Siyuan Qi, Song Chun Zhu 我们提出了一种新颖的模型来解决Visual Dialog的任务,它展示了复杂的对话结构。为了基于当前问题和对话历史获得合理的答案,对话实体之间的基础语义依赖性是必不可少的。在本文中,我们明确地将此任务形式化为图形模型中的推断,其中在对话框中具有部分观察到的节点和未知的图形结构关系。给定的对话框实体被视为观察到的节点。给定问题的答案由具有缺失值的节点表示。我们首先引入期望最大化算法来推断底层对话结构和缺失节点值所需的答案。基于此,我们继续提出一个近似于该过程的可微图神经网络GNN解决方案。 VisDial和VisDial Q数据集的实验结果表明,我们的模型优于比较方法。还观察到我们的方法可以推断出底层对话结构,以便更好地进行对话推理。 |
| Generating Multiple Hypotheses for 3D Human Pose Estimation with Mixture Density Network Authors Chen Li, Gim Hee Lee 由于深度模糊和闭塞关节,来自单眼图像或2D关节的3D人体姿势估计是不适当的问题。我们认为单眼输入的3D人体姿态估计是一个反问题,其中可存在多个可行解。在本文中,我们提出了一种从二维关节生成三维姿态的多个可行假设的新方法。与现有的基于单峰高斯分布最小化均方误差的深度学习方法相比,我们的方法能够生成多个可行的基于多峰混合密度网络的3D姿态假设。我们的实验表明,通过我们的方法从2D关节输入估计的3D姿势在2D重投影中是一致的,这支持了我们的论点,即2D到3D反问题存在多种解决方案。此外,我们在最佳假设和多视图设置中显示了Human3.6M数据集的最新性能,并且我们通过测试MPII和MPI INF 3DHP数据集来证明我们模型的泛化能力。我们的代码可在项目网站上获得。 |
| Direct Fitting of Gaussian Mixture Models Authors Leonid Keselman, Martial Hebert 将高斯混合模型拟合到三维几何时,模型通常适合点云,即使形状是作为三维网格获得的。在这里,我们提出了一种用于将高斯混合模型GMM直接拟合到几何对象的公式,使用三角形网格的三角形而不是使用从其表面采样的点。我们证明了这种修改能够在更广泛的初始化条件下拟合更高质量的GMM。另外,从该拟合方法获得的模型显示出对网格和RGB D帧的3D配准的改进。 |
| Unified Visual-Semantic Embeddings: Bridging Vision and Language with Structured Meaning Representations Authors Hao Wu, Jiayuan Mao, Yufeng Zhang, Yuning Jiang, Lei Li, Weiwei Sun, Wei Ying Ma 我们提出统一视觉语义嵌入统一VSE,用于学习视觉表示和文本语义的联合空间。该模型统一了不同级别对象,属性,关系和完整场景中概念的嵌入。我们将句子语义视为不同语义组件的组合,例如对象和关系,它们的嵌入与不同的图像区域对齐。提出了一种对比学习方法,用于仅从图像标题对有效地学习这种细粒度对齐。我们还提出了一种简单而有效的方法,可以强制覆盖句子嵌入在句子中出现的语义成分。我们证明统一VSE优于交叉模态检索任务的基线,语义覆盖的实施提高了模型在防御文本域对抗性攻击中的鲁棒性。此外,我们的模型使用视觉线索来准确地解决新颖句子中的词依赖性。 |
| Efficient and Robust Registration on the 3D Special Euclidean Group Authors Uttaran Bhattacharya, Venu Madhav Govindu 我们提供了一种准确,稳健,快速的3D扫描配准方法。我们的运动估计优化了刚性运动的内在表示的稳健成本函数,即特殊欧几里德群数学SE 3。我们利用李群的几何性质以及迭代重加权最小二乘优化所提供的鲁棒性。我们还概括了我们对联合多视图方法的方法,该方法同时解决了一组扫描的注册问题。我们通过彻底的实验验证证明了我们的方法的功效。我们的方法在速度和准确性方面明显优于基于线性过程的最先进的稳健3D配准方法。我们还表明,这种线处理方法是我们原理几何解决方案的一个特例。最后,我们还提出了基于特征对应的全局注册失败但基于我们的稳健运动估计的多视图ICP成功的场景。 |
| Generalizing Monocular 3D Human Pose Estimation in the Wild Authors Luyang Wang, Yan Chen, Zhenhua Guo, Keyuan Qian, Mude Lin, Hongsheng Li, Jimmy S. Ren Human3.6M数据集中大规模标记3D姿势的可用性在推进静止图像的3D人体姿势估计算法中起重要作用。我们观察到,该领域的最新创新主要集中在使用该数据集时明确解决泛化问题的新技术,因为该数据库是在人为主题和背景变化有限的高度受控环境中构建的。尽管做了这些努力,但我们可以证明当前方法的结果仍然容易出错,特别是在针对野外拍摄的图像进行测试时。在本文中,我们的目标是从不同的角度解决这个问题。我们提出了一种有原则的方法来生成高质量的3D姿势地面实况,并在内部人员的野外图像中给出。我们通过首先设计一种新颖的立体灵感神经网络来直接将任何2D姿势映射到高质量3D对应物来实现这一目标。然后,我们执行精心设计的几何搜索方案,以进一步细化关节。基于此方案,我们构建了一个大型数据集,其中包含400,000个野外图像及其相应的3D姿势基础事实。这使得能够训练高质量的神经网络模型,而没有专门的训练方案和辅助损失函数,其有利地对抗现有技术的3D姿态估计方法。我们还定量和定性地评估了模型的泛化能力。结果表明,我们的方法令人信服地优于以前的方法。我们公开提供数据集和代码。 |
| Predicting Progression of Age-related Macular Degeneration from Fundus Images using Deep Learning Authors Boris Babenko, Siva Balasubramanian, Katy E. Blumer, Greg S. Corrado, Lily Peng, Dale R. Webster, Naama Hammel, Avinash V. Varadarajan 背景新生血管性年龄相关性黄斑变性患者AMD可通过某些治疗避免视力丧失。然而,缺乏预测新生血管性年龄相关性黄斑变性nvAMD进展的方法。目的利用彩色眼底照片CFP,开发并验证深度学习DL算法,以预测没有,早期或中期AMD到nvAMD的眼睛的1年进展。设计开发和验证DL算法。方法我们训练DL算法预测1年nvAMD进展,并使用10倍交叉验证来评估年龄相关眼病研究AREDS无早期中期AMD和仅中间AMD iAMD的两组眼睛的这种方法。我们将DL算法与AREDS数据集中的手动分级4类和9步比例进行了比较。主要结果测量DL算法的性能使用80特异性的灵敏度来评估进展至nvAMD。结果DL算法对于从非早期iAMD 78 6预测进展为nvAMD的敏感性高于来自9步骤67 8或4类别量表48 3的手动等级。为了特别地从iAMD预测进展,与9步骤等级36 8和4等级等级20 0相比,DL算法的灵敏度57 6也更高。结论我们的DL算法在预测nvAMD进展方面比手动评分更好。需要进一步的研究来测试该DL算法在现实世界临床环境中的应用。 |
| Learning to Generate Synthetic Data via Compositing Authors Shashank Tripathi, Siddhartha Chandra, Amit Agrawal, Ambrish Tyagi, James M. Rehg, Visesh Chari 我们提出了一种合成数据生成的任务感知方法。我们的框架采用可训练的合成器网络,通过评估目标网络的优势和劣势,优化产生有意义的训练样本。合成器和目标网络以对抗方式进行训练,其中每个网络的更新目标是超越另一个。此外,我们确保合成器通过将其与在真实世界图像上训练的鉴别器配对来生成逼真的数据。此外,为了使目标分类器对于混合人工制品不变,我们将这些人工制品引入训练图像的背景区域,使得目标不会过度适应它们。 |
| Instance Segmentation based Semantic Matting for Compositing Applications Authors Guanqing Hu, James J. Clark 图像合成是电影制作和图像编辑中的关键步骤,旨在分割前景对象并将其与新背景相结合。当背景为纯蓝色或绿色时,可以使用色度键控在工作室中轻松完成自动图像合成。然而,在具有复杂背景的自然场景中进行图像合成仍然是一项繁琐的工作,需要经验丰富的艺术家进行分段。为了在自然场景中实现自动合成,我们提出了一种全自动方法,该方法集成了实例分割和图像消光过程,以生成可用于图像编辑任务的高质量语义遮罩。我们的方法既可以作为现有实例分割算法的改进,也可以作为全自动语义图像消光方法。它将自动图像合成技术(如色度键控)扩展到具有复杂自然背景的场景,而无需任何类型的用户交互。我们的方法的输出可以被认为是精确的实例分割和具有语义含义的alpha遮罩。与现有方法相比,我们提供的实验结果显示出改进的性能结果。 |
| Analyzing Dynamical Brain Functional Connectivity As Trajectories on Space of Covariance Matrices Authors Mengyu Dai, Zhengwu Zhang, Anuj Srivastava 人脑功能连接FC通常被测量为当大脑休息或执行任务时跨大脑区域的功能性MRI响应的相似性。本文旨在通过在一组大脑区域上表示集体时间序列数据,作为协方差矩阵空间或对称正定矩阵SPDM的轨迹来统计分析FC的动态性质。我们在SPDM空间上使用新开发的度量来量化FC观测的差异以及FC轨迹的聚类和分类。为了促进大规模和高维数据分析,我们提出了一种新的基于度量的降维技术,以减少从大型SPDM到小型SPDM的数据。我们使用来自Human Connectome Project HCP数据库的数据来说明这个全面的框架,用于多个主题和任务,分类率与最新技术相匹配或优于最新技术。 |
| Predicting Future Pedestrian Motion in Video Sequences using Crowd Simulation Authors Cliceres dal Bianco, Soraia Raupp Musse 虽然人类和群体分析已成为过去几十年的重要领域,但一些当前和相关的应用涉及估计真实视频序列中行人的未来运动。本文提出了一种使用人群模拟在下一秒提供真实行人运动估计的方法。我们的方法基于物理学和启发式,并使用BioCrowds作为人群模拟方法来估计视频序列中人们的未来位置。结果表明,即使对于可能发生事件的复杂视频,我们的估算方法也能很好地工作。当估计32名行人的未来运动超过2秒时,最大达到的平均误差为2.72厘米。本文讨论了这个和其他结果。 |
| BAOD: Budget-Aware Object Detection Authors Alejandro Pardo, Mengmeng Xu, Ali Thabet, Pablo Arbelaez, Bernard Ghanem 我们从一个新的角度研究了对象检测的问题,其中考虑了注释预算约束,适当地创造了预算感知对象检测BAOD。当提供固定预算时,我们提出了一种策略,用于构建多样化且信息丰富的数据集,可用于优化训练强大的检测器。我们研究了基于优化和学习的方法,以便对哪些图像进行注释以及哪种类型的注释强烈或弱地监督以对其进行注释。我们采用混合监督学习框架来训练来自这两种类型的注释的对象检测器。我们进行了一项全面的实证研究,表明手工优化方法优于其他选择技术,包括随机抽样,不确定性抽样和主动学习。通过将最佳图像标注选择方案与混合监督学习相结合来解决BAOD问题,我们表明可以在PASCAL VOC 2007上实现强监督检测器的性能,同时节省其原始注释预算的12.8。此外,当使用100个预算时,它超过了这个性能2.0个百分点。 |
| Attentive Action and Context Factorization Authors Yang Wang, Vinh Tran, Gedas Bertasius, Lorenzo Torresani, Minh Hoai 我们提出了一种人类行为识别方法,可以定位定义行动的时空区域。由于视频中人类行为的微妙性以及上下文元素的共同发生,这是一项具有挑战性的任务。为了应对这一挑战,我们利用人类行动的共轭样本,这些样本是与人类行动样本在上下文相似但不包含该行动的视频剪辑。我们引入了一种新颖的注意机制,可以在空间上和时间上将人类行为与共同发生的情境因素分开。行动和背景因素的分离受到微弱监督,消除了在训练样本中对这两个因素进行费力详细注释的需要。我们的方法可用于构建具有更高准确性和更好解释性的人类动作分类器。几个人类行为识别数据集的实验证明了我们方法的定量和定性优势。 |
| Sliced Wasserstein Generative Models Authors Jiqing Wu, Zhiwu Huang, Dinesh Acharya, Wen Li, Janine Thoma, Danda Pani Paudel, Luc Van Gool 在生成建模中,Wasserstein距离WD已成为衡量生成和实际数据分布之间差异的有用指标。不幸的是,近似高维分布的WD具有挑战性。相反,切片的Wasserstein距离SWD将高维分布分解为它们的多个一维边缘分布,因此更容易近似。 |
| Spherical Regression: Learning Viewpoints, Surface Normals and 3D Rotations on n-Spheres Authors Shuai Liao, Efstratios Gavves, Cees G. M. Snoek 许多计算机视觉挑战需要连续输出,但往往通过离散分类来解决。原因是在概率n单形内分类自然遏制,如流行的softmax激活函数所定义。规则回归缺乏这种封闭的几何形状,导致不稳定的训练和收敛到次优的局部最小值。从这种洞察力开始,我们重新审视卷积神经网络中的回归。我们观察到计算机视觉中的许多连续输出问题自然包含在封闭的几何流形中,如视点估计中的欧拉角或表面法线估计中的法线。构成这种连续输出问题的自然框架是n个球体,它们是在mathbb R n 1空间中定义的自然闭合的几何流形。通过在回归输出处引入n球上的球形指数映射,我们获得了良好的梯度,从而导致稳定的训练。我们展示了我们的球形回归如何用于多种计算机视觉挑战,特别是视点估计,表面法线估计和3D旋转估计。对于所有这些问题,我们的实验证明了球形回归的好处。所有纸质资源均可在 |
| Pixel-Adaptive Convolutional Neural Networks Authors Hang Su, Varun Jampani, Deqing Sun, Orazio Gallo, Erik Learned Miller, Jan Kautz 卷积是CNN的基本组成部分。它们的权重在空间上共享这一事实是其广泛使用的主要原因之一,但它也是一个主要限制,因为它使得卷积内容不可知。我们提出了一种像素自适应卷积PAC操作,这是对标准卷积的简单而有效的修改,其中滤波器权重乘以取决于可学习的局部像素特征的空间变化内核。 PAC是几种流行的过滤技术的概括,因此可用于广泛的用例。具体而言,我们展示了当PAC用于深度联合图像上采样时的最新性能。 PAC还提供了一种完全连接的CRF Full CRF的有效替代方案,称为PAC CRF,它具有竞争力,同时速度更快。此外,我们还证明PAC可以用作替代预训练网络中的卷积层,从而实现一致的性能改进。 |
| Max-Sliced Wasserstein Distance and its use for GANs Authors Ishan Deshpande, Yuan Ting Hu, Ruoyu Sun, Ayis Pyrros, Nasir Siddiqui, Sanmi Koyejo, Zhizhen Zhao, David Forsyth, Alexander Schwing 生成对抗网络GAN和变分自动编码器显着改善了我们的分布建模功能,显示了数据集增强,图像到图像转换和特征学习的前景。然而,为了模拟高维分布,顺序训练和堆叠架构是常见的,增加了可调超参数的数量以及训练时间。尽管如此,距离度量的样本复杂性仍然是影响GAN训练的因素之一。我们首先表明,与Wasserstein距离相比,最近提出的切片Wasserstein距离具有引人注目的样本复杂性。为了进一步改善切片Wasserstein距离,我们然后分析其投影复杂度并开发最大切片Wasserstein距离,其具有引人注目的样本复杂性,同时降低投影复杂度,尽管需要最大估计。我们最终说明所提出的距离训练GAN在高维图像上容易达到256x256的分辨率。 |
| KeyIn: Discovering Subgoal Structure with Keyframe-based Video Prediction Authors Karl Pertsch, Oleh Rybkin, Jingyun Yang, Kosta Derpanis, Joseph Lim, Kostas Daniilidis, Andrew Jaegle 真实世界的图像序列通常可以自然地分解成少量的帧,描绘其文本关键帧和它们之间的低方差帧的有趣的,高度随机的时刻。在描绘到目标的轨迹的图像序列中,关键帧可被视为捕获序列的文本子目标,因为它们描绘了最终导致目标的感兴趣的高方差矩。在本文中,我们介绍了一种视频预测模型,该模型以无监督的方式发现图像序列的关键帧结构。我们使用分层关键帧中间模型KeyIn来实现这一点,该模型随机地随机预测关键帧及其偏移,然后使用这些预测来确定性地预测中间帧。我们提出了这个问题的可微分公式,它允许我们使用序列重建损失训练完整的分层模型。我们展示了我们的模型能够在机器人演示的模拟数据集中找到有意义的关键帧结构,并且这些关键帧可以作为计划的子目标。我们的模型优于其他分层预测方法,用于规划模拟推送任务。 |
| Diagnosis of Celiac Disease and Environmental Enteropathy on Biopsy Images Using Color Balancing on Convolutional Neural Networks Authors Kamran Kowsari, Rasoul Sali, Marium N. Khan, William Adorno, S. Asad Ali, Sean R. Moore, Beatrice C. Amadi, Paul Kelly, Sana Syed, Donald E. Brown 乳糜泻CD和环境肠病EE是营养不良的常见原因,并对正常的儿童发育产生不利影响。 CD是一种自身免疫性疾病,在全世界普遍存在,并且是由对麸质的敏感性增加引起的。麸质暴露破坏小肠上皮屏障,导致营养吸收不良和童年营养。 EE也导致屏障功能障碍,但被认为是由感染易感性增加引起的。 EE被认为是低收入和中等收入国家营养不足,口服疫苗失败和认知发展受损的主要原因。这两种情况都需要进行组织活检以进行诊断,并且解释临床活检图像以区分这些胃肠疾病的主要挑战是它们之间的组织病理学重叠。在目前的研究中,我们提出了一种卷积神经网络CNN,用于对来自CD,EE和健康对照的受试者的十二指肠活检图像进行分类。我们使用包含1000个活组织检查图像的大型队列评估了我们提出的模型的性能。我们的评估表明,对于CD,EE和健康对照,所提出的模型分别达到ROC分别为0.99,1.00和0.97的面积。这些结果证明了所提出的模型在十二指肠活组织检查分类中的辨别力。 |
| FrameRank: A Text Processing Approach to Video Summarization Authors Zhuo Lei, Chao Zhang, Qian Zhang, Guoping Qiu 在过去的几十年中,视频摘要已得到广泛研究。然而,由于缺乏大规模视频数据集,在其中人类生成的视频摘要被明确定义和注释,因此用户生成的视频摘要的探索要少得多。为此,我们提出了一个用户生成的视频摘要数据集UGSum52,其中包含52个视频207分钟。在构建数据集时,由于用户生成的视频摘要的主观性,我们手动为每个视频注释25个摘要,总共1300个摘要。据我们所知,它是目前用户生成的视频摘要的最大数据集。 |
| Mitigating Information Leakage in Image Representations: A Maximum Entropy Approach Authors Proteek Chandan Roy, Vishnu Naresh Boddeti 图像识别系统在过去几十年中取得了巨大的进步,部分原因在于我们学习紧凑而强大的图像表示的能力。当我们目睹这些系统的广泛采用时,必须考虑图像表示中意外泄漏信息的问题,这可能会损害数据所有者的隐私。本文研究了学习图像表示的问题,该图像表示最小化了用户信息的这种泄漏。我们将问题表述为一种对抗性非零和游戏,即找到具有两个竞争目标的良好嵌入函数,以尽可能多地保留任务相关的判别图像信息,同时最小化通过熵测量的关于其他敏感属性的信息量用户。我们使用来自非线性系统理论的工具分析所提出的公式的稳定性和收敛动态,并与相应的对抗零和游戏公式进行比较,该公式将可能性优化为信息内容的度量。 UCI,Extended Yale B,CIFAR 10和CIFAR 100数据集的数值实验表明,我们提出的方法能够学习具有高任务性能的图像表示,同时减少预定义敏感信息的泄漏。 |
| CNN-Based Deep Architecture for Reinforced Concrete Delamination Segmentation Through Thermography Authors Chongsheng Cheng, Zhexiong Shang, Zhigang Shen 桥面板的分层评估对桥梁健康监测起着至关重要的作用。作为用于分层检测的非破坏性技术之一的热成像具有有效数据采集的优点。但是对于精确分层形状分析的数据解释存在挑战。由于环境变化和分层尺寸和深度的不规则存在,基于温度对比的传统处理方法在准确的分层分割方面不足。受最近用于图像分割的深度学习架构的启发,基于卷积神经网络CNN的框架研究了在温度对比度和形状扩散变化下分层分割的适用性。这些模型是基于密集卷积网络DenseNet开发的,并在实验装置下对不同深度的混凝土板中模拟分层所收集的热图像进行了训练。结果表明,准确分析分层形状的性能令人满意。 |
| Chinese Abs From Machine Translation |
Papers from arxiv.org
更多精彩请移步主页

pic from pixels.com