blktrace结合btt分析IO性能
blktrace介绍
blktrace是一个针对linux内核中块设备I/O的跟踪工具,是由Linux内核块设备层的维护者开发的。通过这个工具,使用者可以获得I/O请求队列的各种详细的情况,包括进行读写的进程名称、进程号、执行时间、读写的物理块号、块的大小等等。
blktrace的工作原理
1:blktrace测试的时候,会分配给物理机上逻辑cpu个数的线程,并且每个线程绑定一个逻辑cpu来搜集数据
例如:9630的手机,有cpu0、cpu1、cpu2、cpu3,所以启动4个线程
2:blktrace在debugfs挂载的路径(默认路径:/sys/kernel/debug)下每个线程产生一个文件(就有了对应的文件描述符),然后调用ioctrl函数,
产生系统调用,将相应的参数传递给内核去调用相应的函数处理,由内核经由debugfs文件系统往此文件描述符写入数据
3:blktrace需要结合blkparse来使用,用blkparse来解析blktrace产生的特定格式的二进制数据
blktrace在手机的使用
第一步:要打开kernel的Trace功能。
步骤:1. source build/envsetup.sh
2. lunch 选择工程
3. 输入命令kuconfig,配置内核
4. 选中kernelhacking--->Tracer----->Support for tracing block IO actions 5. make systemimage -j4
6. 将新生成的system.img boot.img下载到手机
第二步: 将可执行的blktrace/blkparse的可执行程序下载到手机
步骤:1.abd root 进入root权限
2.adb remount 重新挂载
3.adb push blktrace /system/bin/
4.adb push blkparse /system/bin
5.adb shell
6.cd /system/bin
7.修改blktrace/blkparse的属性,chmod 0777 blktrace
Blktrace准备工作
1:因为手机有cpu0/cpu1/cpu2/cpu3,一共4个cpu,blktrace一共启动4个线程,一个cpu对应一个线程。所以,在运行blktrace监控命令之前保证4个cpu处于唤醒状态
2:查看方法:adb root
adb shell
cd /sys/devices/system/cpu/
cat online
如果显示0-3,代表4个cpu都处于唤醒状态,如果显示0,代表只有cpu0处于唤醒状态
3:唤醒cpu的方法:
echo 1 >/sys/devices/system/cpu/cpufreq/sprdemand/cpu_hotplug_disable
4:只要保证运行blktrace监控命令之前4个cpu处于唤醒状态即可,一旦blktrace监控命令启动,无论cpu1/cpu2/cpu3处于开启还是关闭状态,都不会影响blktrace的工作性能
使用案例
1. mount -t vfat /dev/block/mmcblk0p1 /data/temp
2. blktrace /dev/block/mmcblk1p1 -o /data/trace 此命令的意思:blktrace监控T卡,并将监控的结果输出到/data目录下,生成的文件名为trace.blktrace.0 trace.blktrace.1 trace.blktrace.2trace.blktrace.3他们的个数由cpu的个数决定
3. 重新打开一个终端 dd if=/dev/zero of=/data/temp/11bs=512 count=1024
4. 此时blktrace可监控到写,按ctrl+c可终止监控
5. 由于trace.blktrace.x 文件里面存的是二进制数据,需要blkparse来解析
6. 文件解析:blkparse -i trace 此命令的作用是将解析结果输出到屏幕,(此命令在trace.blktrace.x生成的目录执行)
此时终端,会输出
179,1 2 0 0.000361250 0 m Ncfq110A fifo= (null)
179,1 2 0 0.000364094 0 m N cfq110A dispatch_insert
179,1 2 0 0.000378047 0 m Ncfq110A dispatched a request
179,0 1 25 0.000381250 2152 A W2993285 + 1 <- (179,1) 2991237
179,1 2 0 0.000382875 0 m Ncfq110A activate rq, drv=1
179,1 1 26 0.000386313 2152 Q W2993285 + 1 [kworker/u8:1]
179,1 2 1 0.000387250 88 D W2444 + 2 [mmcqd/0]
179,1 1 27 0.000405024 2152 G W2993285 + 1 [kworker/u8:1]
179,1 1 28 0.000409250 2152 P N[kworker/u8:1]
179,0 1 29 0.001225735 2152 A W2993286 + 1024 <- (179,1) 29912
blktrace命令详解
1. blktrace /dev/block/mmcblk0p1 -o /data/trace 命令解析:监控mmcblk0p1块设备,将生成的文件存储在/data目录下,一共生成4个文件,文件以trace开头,分别为trace.blktrace.0 trace.blktrace.1 trace.blktrace.2trace.blktrace.3分别对应cpu0、cpu1、cpu2、cpu3
2. blktrace /dev/block/mmcblk0p1 -D /data/trace 命令解析:监控mmcblk0p1块设备,在/data目录下建立一个名字为trace的文件夹,trace文件夹下存放的是名字为 mmcblk0p1.blktrace.0mmcblk0p1.blktrace.1 mmcblk0p1.blktrace.2 mmcblk0p1.blktrace.3 分别对应cpu0 cpu1 cpu2 cpu3
3. blktrace /dev/block/mmcblk0p1 -o /data/trace -w 10 命令解析:-w 选项表示多长时间之后停止监控(单位:秒) -w 10 表示10秒之后停止监控
4. blktrace /dev/block/mmcblk0p1 -o /data/trace -a WRITE 命令解析:-a 代表只监控写操作
选项 -a action 表示要监控的动作,action的动作有:
READ (读)
WRITE(写)
BARRIER
SYNC
QUEUE
REQUEUE
ISSUE
COMPLETE
FS
PC
详见:http://www.cse.unsw.edu.au/~aaronc/iosched/doc/blktrace.html(blktrace user guide)
blkparse工具解析
1. 实时解析,实时数据的解析即上blktrace的“终端输出”实现实时解析的命令:blktrace -d/dev/block/mmcblk0p1 -o - |blkparse -i -
2. 文件解析,分为两种
(1) 在手机上生成解析文件
i. 实现方法:进入trace.blktrace.0 trace.blktrace.1 trace.blktrace.2 trace.blktrace.3所在的目录输入命令:blkparse -itrace -o /data/trace.txt
(2) 在PC上实现解析
ii. 实现方法,将手机上生成的trace.blktrace.0 trace.blktrace.1 trace.blktrace.2 trace.blktrace.3的文件拷贝到PC上输入命令:./blkparse -i trace -otrace.txt
blktrace解析文件格式
默认的输出内容格式为:"%D ,%8s %5T.%9t %5p * =",
如:
8,16 0 35 1.157274569 2544 GWBS 121897312 + 8 [jbd2/sdb-8]
其中:
%D 主从设备号 :8.16,CPU_id: 0 ###因为此时解析的文件是trace.blktrace.0,搜集的cpu0的信息,所以CPU_id为0###
%8s io序列号,一般从1开始 :35
%5T.%9t 此IO操作发生时的时间戳秒.纳秒:1.157274569
%5p process ID :2544
* IO action:解释见下面
= RWBS data。R表示读 W表示写D表示块被丢弃B表示barrier operation S表示同步IO:如上面的WBS,表示同步写操作
121897312是相对8,16的扇区起始号,+8,为后面连续的8个扇区(默认一个扇区512byte,所以8个扇区就是4K),后面的[jbd2/sdb-8]是程序的名字。
IO action列表
C -- complete A previouslyissued request has been completed. Theout‐
put will detail the sectorand size of that request, as well as the
success or failure of it.
D -- issued A request thatpreviously resided on the block layer queue
or in the i/o scheduler hasbeen sent to the driver.
I -- inserted A request isbeing sent to the i/o scheduler for addition
to the internal queue andlater service by the driver. The request
is fully formed at thistime.
Q -- queued This notes intent to queue i/o at the given location. No
real requests exists yet.
B -- bounced The data pagesattached to this bio are not reachable by
the hardware and must be bounced to a lower memory location. This
causes a big slowdown in i/operformance, since the data must be
copied to/from kernelbuffers. Usually this can be fixed with using
better hardware -- either abetter i/o controller, or a platform
with an IOMMU.
M -- back merge A previously inserted request exists that ends on the
boundary of where this i/obegins, so the i/o scheduler can merge
them together.
F -- front merge Same as the back merge, except this i/o ends where a
previously inserted requestsstarts.
M --front or back merge Oneof the above
G -- get request To send anytype of request to a block device, a
struct request containermust be allocated first.
S -- sleep No available request structures wereavailable, so the
issuer has to wait for oneto be freed.
P -- plug When i/o is queuedto a previously empty block device queue,
Linux will plug the queue inanticipation of future ios being added
before this data is needed.
U -- unplug Some requestdata already queued in the device, start send‐
ing requests to the driver. This may happen automatically if a
timeout period has passed (see next entry) or if a number of
requests have been added tothe queue.
T -- unplug due to timer If nobody requests the i/o that wasqueued
after plugging the queue,Linux will automatically unplug it after
a defined period has passed.
X -- split On raid or device mapper setups, anincoming i/o may strad‐
dle a device or internalzone and needs to be chopped up into
smaller pieces for service.This may indicate a performance problem
due to a bad setup of thatraid/dm device, but may also just be
part of normal boundary conditions. dm is notably bad at this and
will clone lots of i/o.
A -- remap For stackeddevices, incoming i/o is remapped to device
below it in the i/o stack.The remap action details what exactly is
being remapped to what.
详见:http://www.cse.unsw.edu.au/~aaronc/iosched/doc/blktrace.html(blktrace user guide)
实例分析
8,16 0 8 0.018543948 8191 Q W 12989792 + 24 [postgres]
8,16 0 9 0.018547191 8191 G W 12989792 + 24 [postgres]
8,16 0 10 0.018548571 8191 P N[postgres]
8,16 0 11 0.018550601 8191 I W 12989792 + 24 [postgres]
8,16 0 12 0.018551421 8191 U N [postgres] 1
8,16 0 13 0.018552618 8191 D W 12989792 + 24 [postgres]
8,16 0 14 0.018638488 8191 C W 12989792 + 24 [0]
以上就是一次IO请求的生命周期,从actions看到,分别是QGPIUDC
Q:先产生一个该位置的IO意向插入到io队列,此时并没有真正的请求
G:发送一个实际的Io请求给设备
P(plugging):插入:即等待即将到来的更多的io请求进入队列,以便系统能进行IO优化,减少执行IO请求时花的时间
I:将IO请求进行调度,到这一步请求已经完全成型(formed)好了
U (unplugging):拔出,设备决定不再等待其他的IO请求并使得系统必须响应当前IO请求,将该IO请求传给设备驱动器。可以看到,在P和U之间会等待IO,然后进行调度。这里会对IO进行一点优化,
但是程度很低,因为等待的时间很短,是纳秒级别的
D :发布刚才送入驱动器的IO请求
C:结束IO请求,这里会返回一个执行状态:失败或者成功,在进程号处为0表示执行成功,反之则反
到此一个IO的周期就结束了
利用btt分析blktrace数据
blkparse只是将blktrace数据转成可以人工阅读的格式,由于数据量通常很大,人工分析并不轻松。btt是对blktrace数据进行自动分析的工具。
btt不能分析实时数据,只能对blktrace保存的数据文件进行分析。使用方法:
把原本按CPU分别保存的文件合并成一个,合并后的文件名为sdb.blktrace.bin:
$ blkparse -i sdb -d sdb.blktrace.bin
执行btt对sdb.blktrace.bin进行分析:
$ btt -i sdb.blktrace.bin
下面是一个btt实例:
我们看到69.6173%的时间消耗在D2C,也就是硬件层,这是正常的,我们说过D2C是衡量硬件性能的指标,这里单个IO平均0.396594毫秒,已经是相
当快了,单个IO最慢10.70692毫秒,不算坏。Q2G和G2I都很小,完全正常。I2D稍微有点大,应该是cfq scheduler的调度策略造成的,你可以试试其
它scheduler,比如deadline,比较两者的差异,然后选择最适合你应用特点的那个。
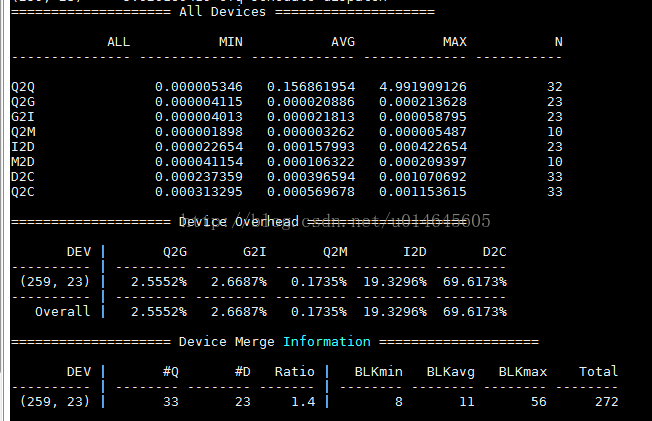
G2I – IO请求进入IO Scheduler所消耗的时间,包括merge的时间;
I2D – IO请求在IO Scheduler中等待的时间;
D2C – IO请求在driver和硬件上所消耗的时间;
Q2C – 整个IO请求所消耗的时间(Q2I + I2D + D2C = Q2C),相当于iostat的await。