使用statsd-exporter配置的一些坑
监控上使用的graphite有些不稳定,有过几次时间服务器上内存爆掉,导致监控服务器蹦掉。而graphite的升级部署真的是很多坑,每次每个版本都不一样。如果能升级的话,那是最好的。
有心替换掉graphite,备选方式是选择Prometheus,最大的问题是以前已经设置好的metric不想丢掉,再重新设计一套,幸好prometheus提供statsd转换器,配置起来碰到几个坑,记录一下
第一步:配置statsd
这一步需要statsd往statsd_exporter传递一份数据过去(复制过去,不能影响原来的统计路径)。查阅资料发现repeater具有这个特性,配置成功后的样子如下配置文件(config.js)
{
"graphiteHost": "127.0.0.1",
"graphitePort": 2003,
"port": 8125,
"flushInterval": 10000,
"dumpMessages": true ,
"debug": true ,
"backends": [ "./backends/graphite","./backends/repeater" ],// 注意这里,都配置上
"repeaterProtocol":"tcp”, // 可以使用udp和tcp协议,默认是upd4协议
"repeater":[ { host: '10.1.1.204', port: 9125 }] // stats_exporter地址,注意使用IP
}这里碰到坑为backends中一定要配置上./backends/repeater,否则的话repeater不生效,第二个坑是,由于使用的docker,{ host: '10.1.1.204', port: 9125 }这一部分中的host必须使用IP地址,不能使用127或者localhost的方式
第二步:配置statsd-exporter
配置statsd-exporter核心的工作是配置statsd-mapping.yml配置文件,主要完成把graphite格式的metric映射为符合prometheums格式的metric,具体映射方式和自己的业务相关,做的了demo如下
mappings:
- match: stats_counts.order.*
name: "stats_counts_order_total"
labels:
action: "$1"
- match: stats_counts.foods.*
name: "foods_total"
labels:
style: "$1"
- match: foods.*
name: "foods_$1"
labels:
style: "$1"详细配置说明可以参考
https://github.com/prometheus/statsd_exporter
https://werner-dijkerman.nl/2017/05/27/monitoring-consul-with-statsd-exporter-and-prometheus/
配置好文件后,可以通过docker命令启动statsd_exporter
docker run --name statsd_exporter -d -p 9102:9102 -p 9125:9125 -p 9125:9125/udp \
-v $PWD/statsd_mapping.yml:/tmp/statsd_mapping.yml \
prom/statsd-exporter --statsd.mapping-config=/tmp/statsd_mapping.yml
其中,9102端口是供Prometheus pull使用,9125是供statsd repeater的。如果上面的statsd我们配置成功,statsd-exporter启动成功后,我们可以通过http访问9102查看转换的metric信息
http://10.1.1.204:9102/metrics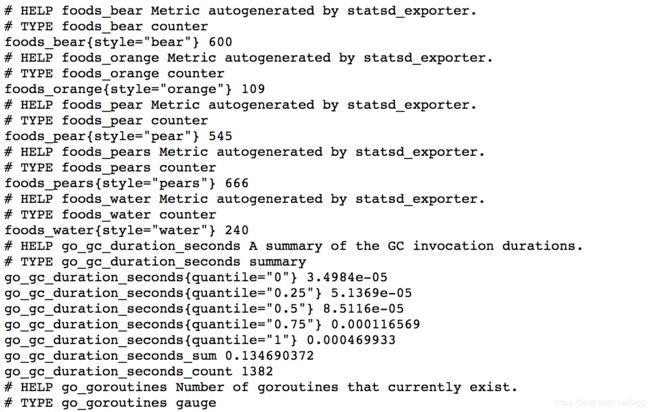
第三步:配置Prometheus,让其从statsd-exporter中拉取数据
创建prometheus.yml目录,从scrape_configs部分,配置statad-exporter的拉取源
# A scrape configuration containing exactly one endpoint to scrape:
# Here it's Prometheus itself.
scrape_configs:
# The job name is added as a label `job=` to any timeseries scraped from this config.
- job_name: 'prometheus'
# metrics_path defaults to '/metrics'
# scheme defaults to 'http'.
static_configs:
- targets: ['localhost:9090']
- job_name: statsd // 从这里开始
static_configs:
- targets: ['10.1.1.24:9102’] // 注意这里一定要写IP地址,不能使用127或者localhost
labels:
instance: stats_count 核心点是job-name和targets,如果在docker内,切记不要使用127或者localhost,使用docker启动
docker run --name prometheus -d -p 9090:9090 -v $PWD/prometheus.yml:/etc/prometheus/prometheus.yml -v $PWD/prometheus-data:/prometheus-data prom/prometheus如果能够正常启动,这时候通过访问IP:port的形式,看到相关数据了,把下面的IP替换成你的IP
http://10.1.1.24:9090/graph
看到指标数据,如果没有查询到相关metric数据,可以访问
http://10.1.1.24:9090/targets
查看配置的源是否有效,正常状态应该如下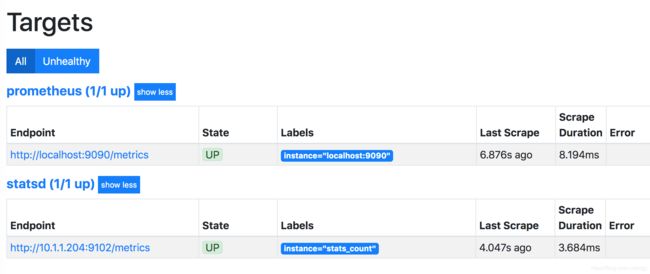
其实经过以上配置,没有使用Prometheums的。我们通过docker方式,获取最新的graphite。把statsd中的数据repeater给新graphite一份,在配置一套grafana,这种方式完成新老granphite系统的升级,毕竟现在的监控数据可以丢失一些的。
参考资料:
https://github.com/prometheus/prometheus
https://github.com/prometheus/statsd_exporter