Hadoop2.7.3和Spark2.1.0集群详细搭建教程
1.本文介绍
本文包括如下内容
- Ubuntu虚拟机安装过程
- Ubuntu配置静态IP
- 配置SSH免密登录
- Ubuntu国内APT软件源的配置
- JDK,Scala,MySQL软件安装
- Hadoop集群安装
- Spark集群安装
- Anaconda安装
使用到的软件的版本及下载地址
- VMware Workstation 12.5.2
- ubuntu-14.04.1-server-amd64
- XShell 5
- XFTP 5
- JDK 1.8
- Scala 2.12.1
- Hadoop 2.7.3
- Spark-2.1.0-bin-hadoop2.7
- Anaconda2-4.3.1-Linux-x86_64
2.准备虚拟机
本次搭建的集群包含2台机器,一台master,一台slaver,所以需要安装2台虚拟机,步骤如下:
2.1新建虚拟机
打开VMware Workstation,点击文件->新建虚拟机
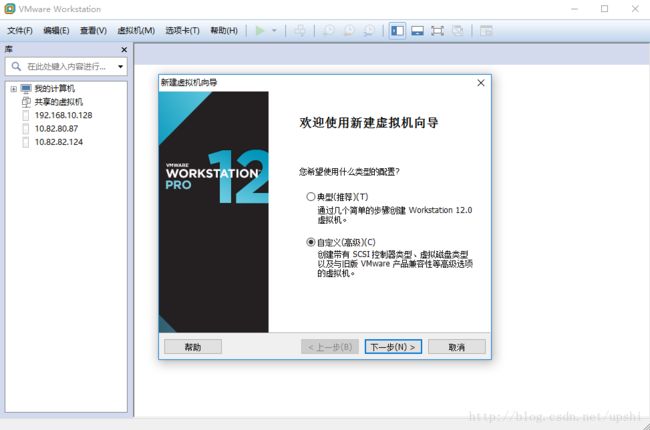
连续点击下一步,在这里选择稍后安装操作系统
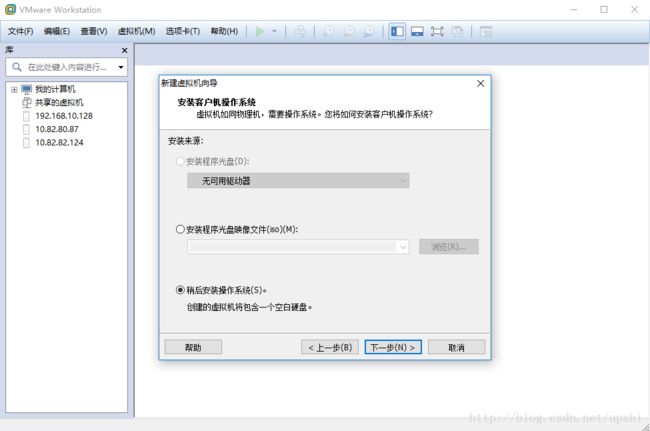
下一步,选择客户机操作系统,这里我选择的是Ubuntu 64位
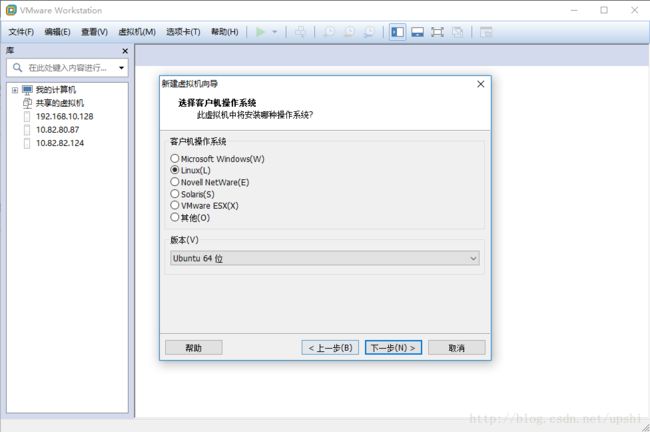
下一步,命名虚拟机
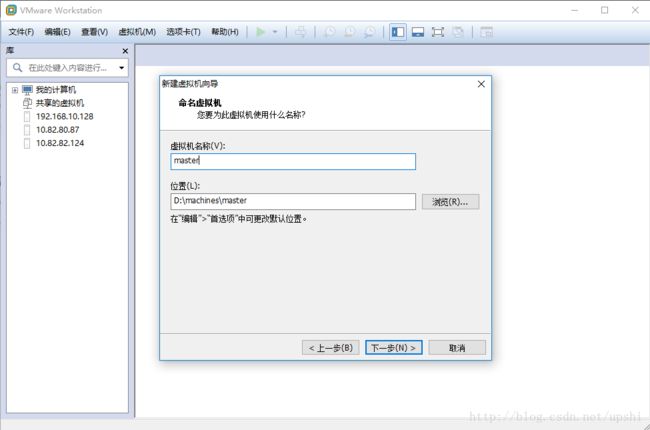
下一步,CPU和内存配置,根据自己的机器性能决定,我选择了双核和2G内存

下一步,网络类型,默认使用NAT

下一步,IO控制器类型吗,默认LSI Logic(L)
下一步,磁盘类型,默认SCSI(S)
下一步,选择磁盘,默认创建新的虚拟磁盘
下一步,指定磁盘容量,默认分配20GB,将虚拟磁盘拆分成多个文件
下一步,指定磁盘文件,默认即可

下一步,点击完成,新建结束
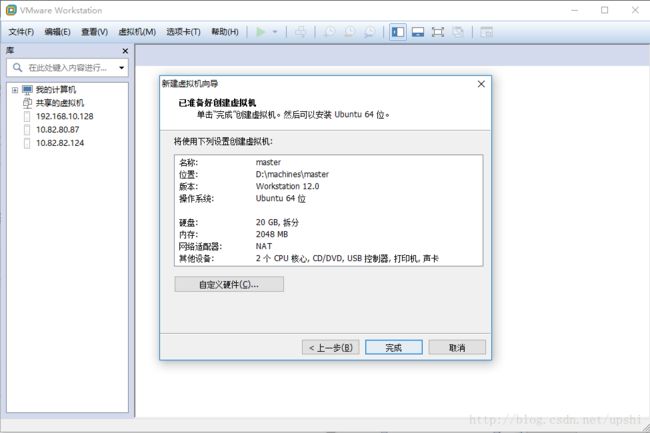
2.1 安装虚拟机
下一步,点击编辑虚拟机设置
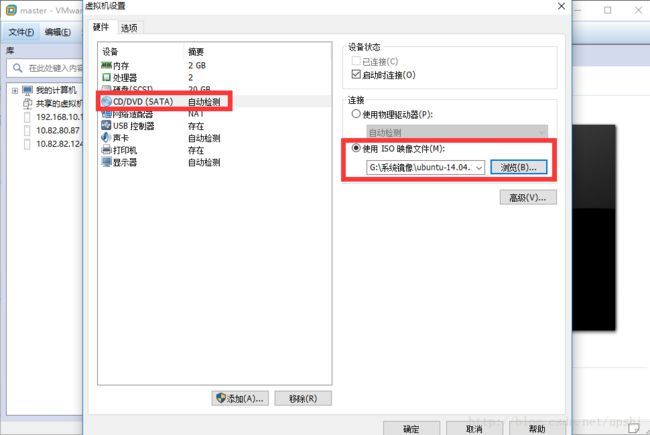
下一步,选择下载好的选择下载好的虚拟机ISO镜像
接下里,就可以开启虚拟机了
选择系统语言,默认English

选择Install Ubuntu Server
再次选择语言,默认English
选择位置,Other->Asia->China
配置键盘,默认不检测即可,选择English(US)即可
现在开始它会自动执行一些操作,大约半分钟
配置Hostname,我这里配置为master

创建新用户,我这里使用的用户名还是master

设置密码,并确认密码,我这里设置的是123456

因为密码太简单,所以会询问是否使用弱密码,选择YES即可
是否加密家目录,默认选择NO即可
再等待半分钟左右的,系统自动配置一些操作
确认时区
选择磁盘分区方式,默认即可,选择唯一的那个默认分区
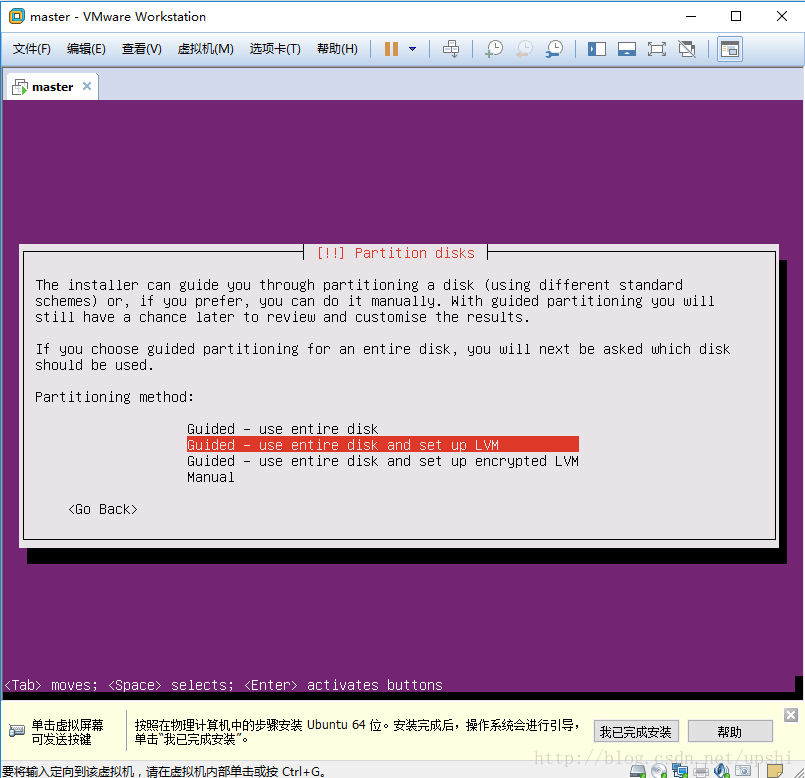
写入分区
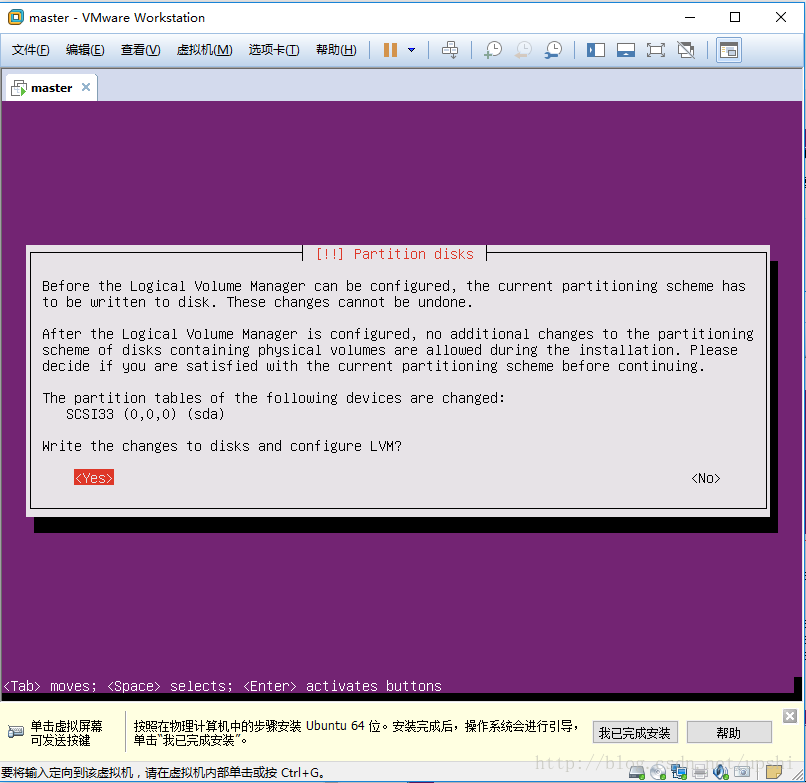
接下来就点击Continue和确认即可,开始真正安装系统
默认为空,不配置代理
关闭自动更新
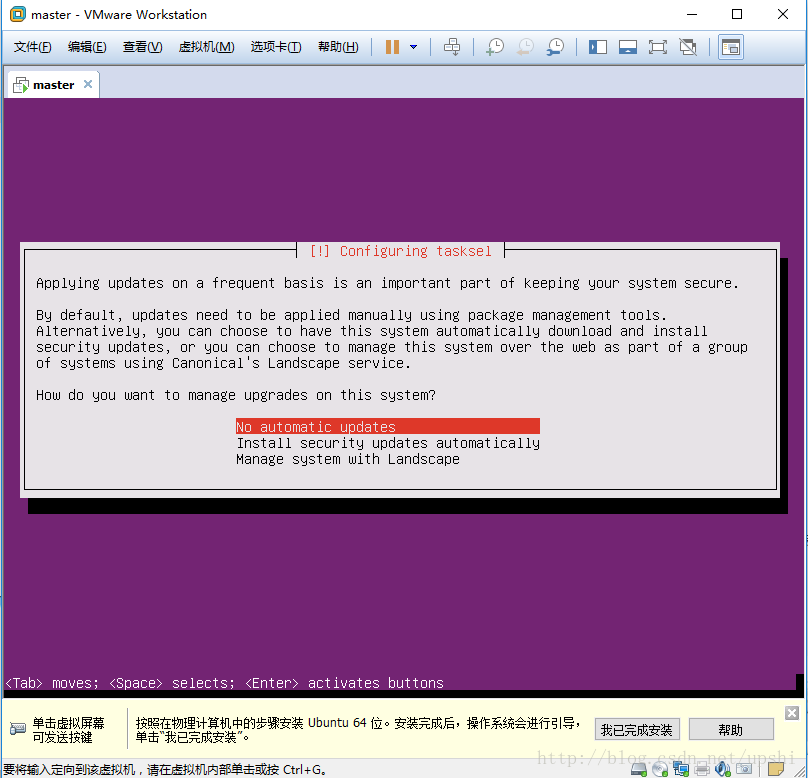
选择安装的软件,这里选择了OpenSSH Server
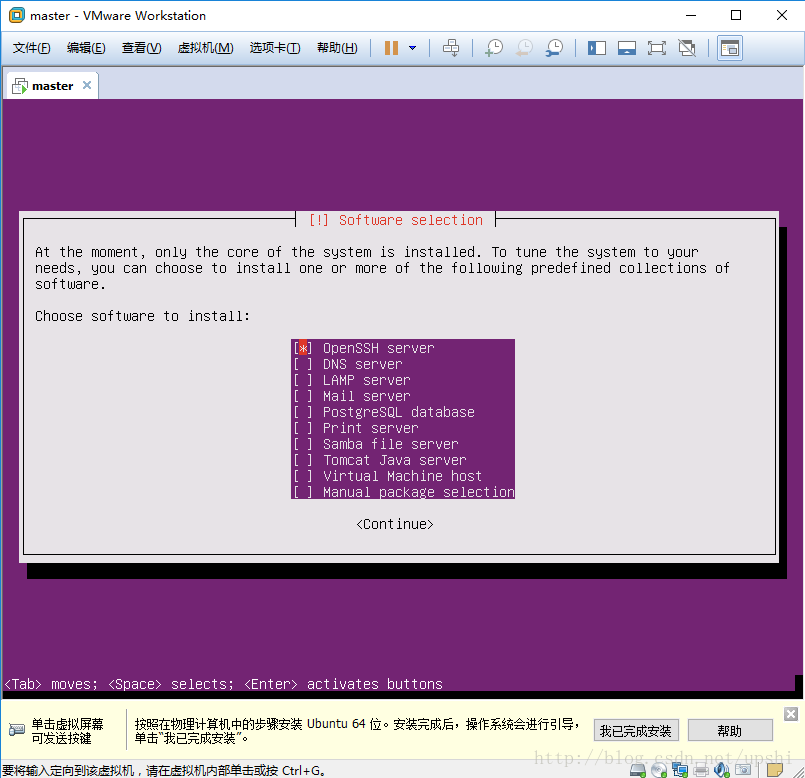
安装启动引导
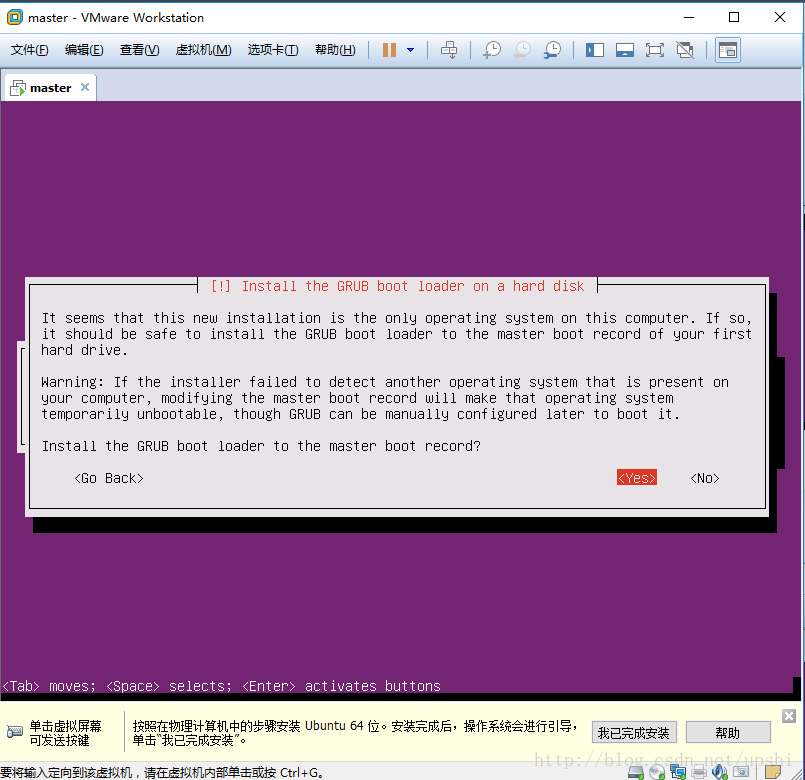
安装完成,选择Continue进行重启
看见如下界面,安装启动完成,输入用户名和密码即可登录。按照相同的步骤,再安装一台虚拟机,Hostnaem设置成slaver,作为从节点,这里不再重复安装过程。
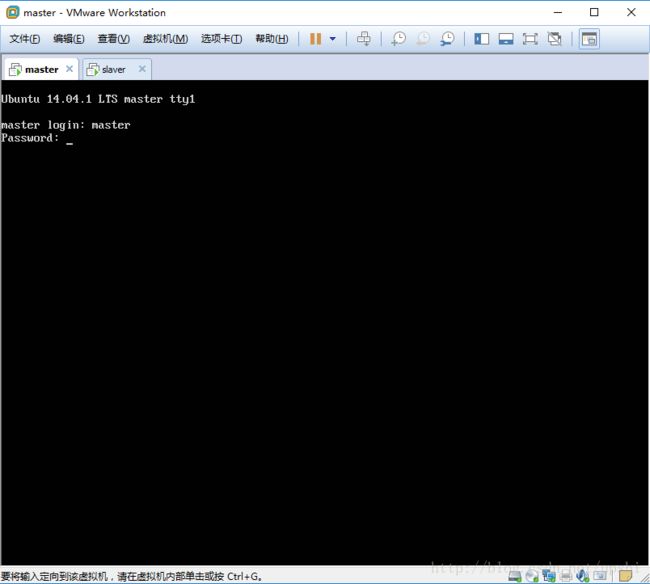
登录进系统后,配置root用户密码,输入sudo passwd命令,然后先输入master用户密码,然后就可以设置root用户密码了
2.3 Ubuntu配置静态IP
安装完系统后,默认使用的是DHCP分配的动态IP地址,为了使用方便,给机器配置一个静态的IP地址。
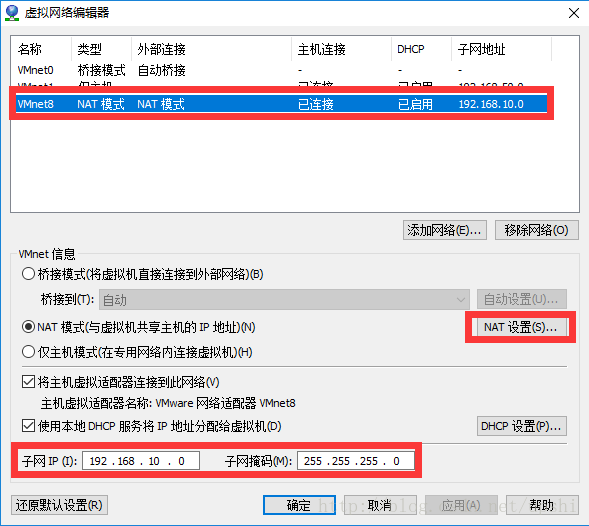
打开VMWare Workstation,点击编辑->虚拟网络编辑器,点击更改设置

选择VMnet8,查看子网IP和子网掩码,如果需要修改,可以点击NAT设置
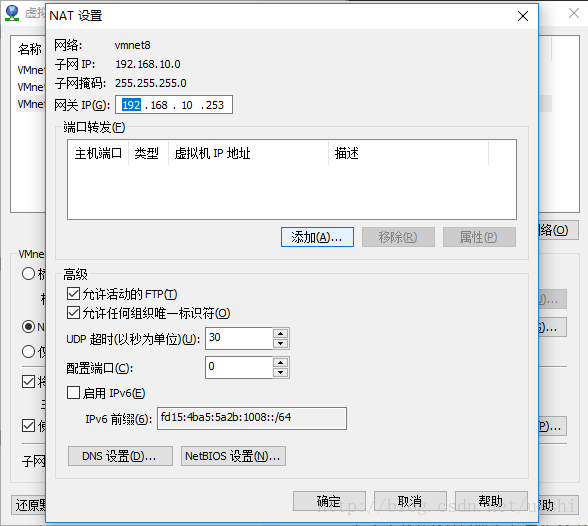
在NAT设置中,也可以看到子网IP和子网掩码等信息,还可以配置网关IP
输入命令vi /etc/network/interfaces,编辑网卡配置文件
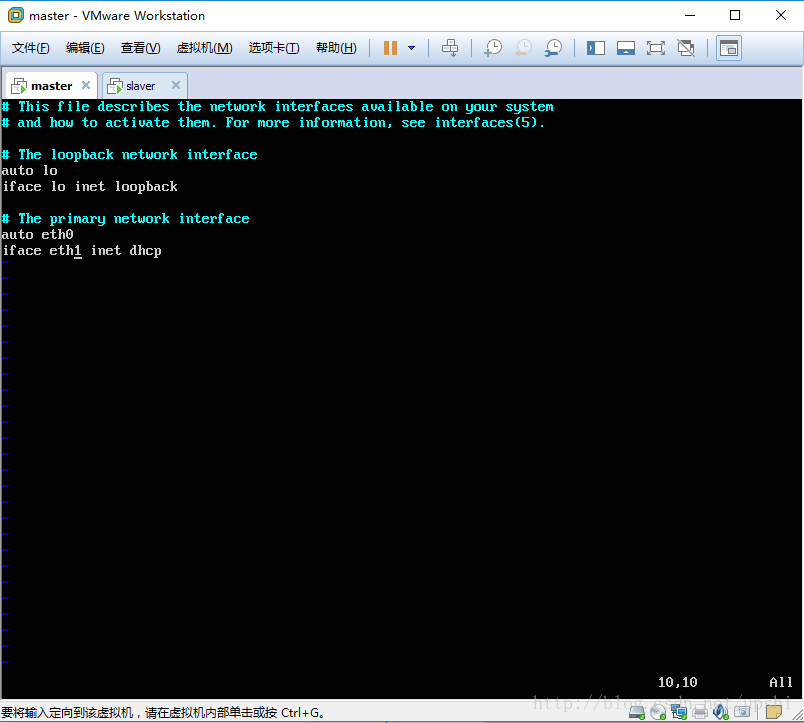
设置静态IP地址,根据上面查到的子网信息,子网掩码,和网关来设置。这里master的IP设置成192.168.10.51
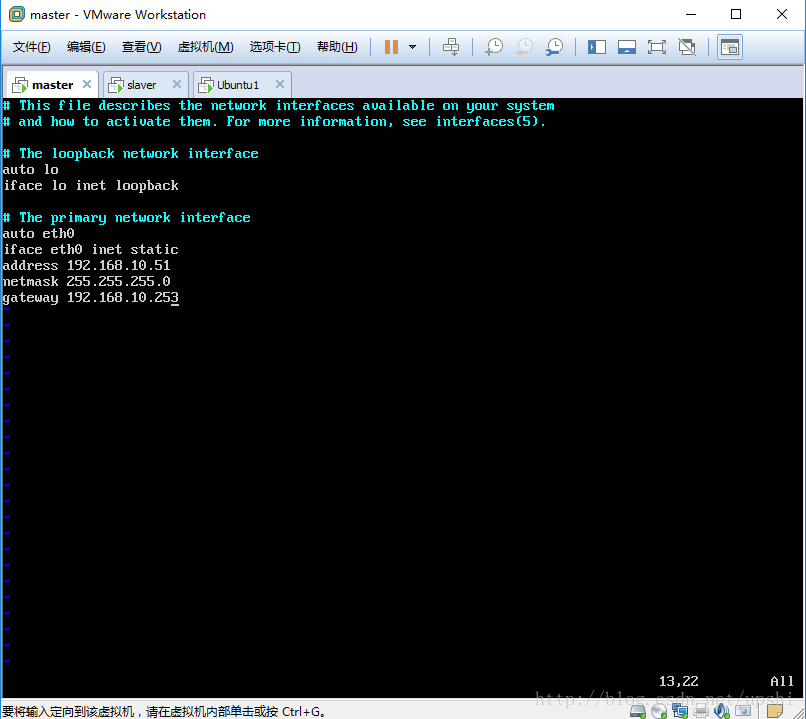
配置好以后,:wq保存,reboot重启虚拟机,用root用户登录。
接下里配置SSH连接,输入命令vi /etc/ssh/sshd_config/,编辑SSH配置文件,将PermitRootLogin 设置为yes
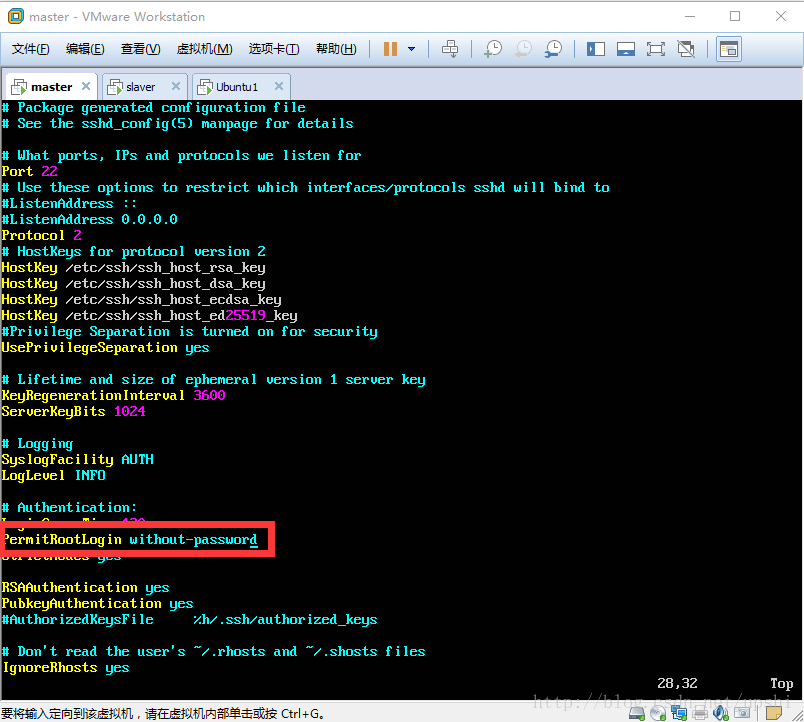
输入命令service ssh restart来重启SSH服务
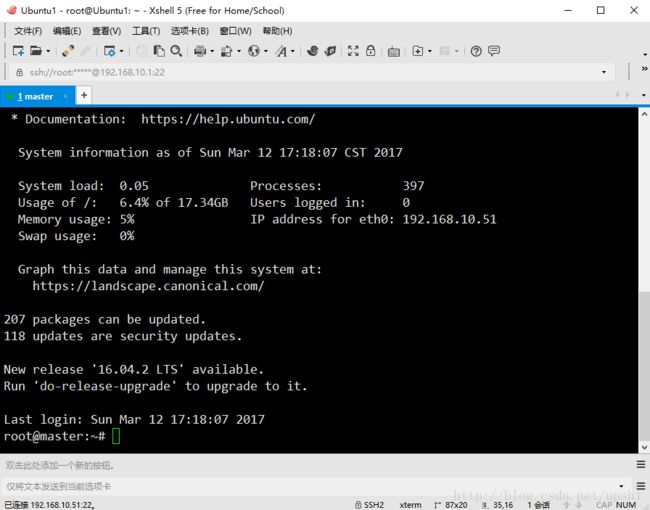
这里我使用一款比较好用的SSH客户端软件xshell,来连接虚拟机,新建一个连接
成功连接xshell
以同样的方式来设置salver虚拟机。
宿主机的IP可以通过控制面板->网络和 Internet->网络连接->VMware Network Adapter VMnet8来设置
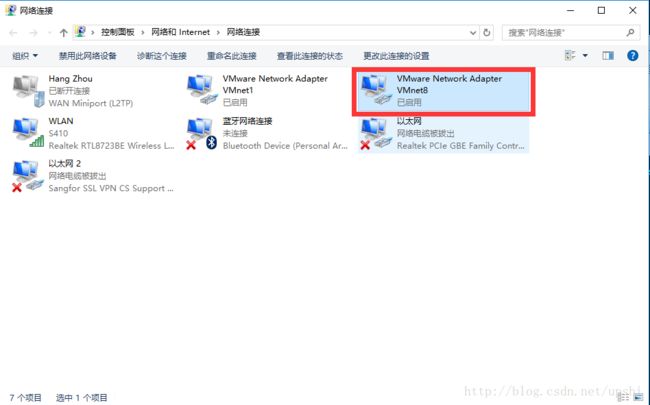
我这里设置成了静态IP:192.168.10.10

2.4 配置SSH免密登录
首先配置2台虚拟机的hosts,打开hosts文件
root@master:~/.ssh# vi /etc/hosts加入以下配置
192.168.10.51 master
192.168.10.52 slaver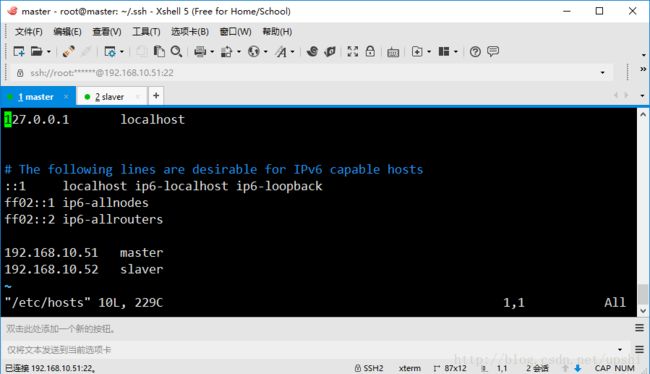
登录master机器,创建密钥,一直按回车键即可,此时会在/root/.ssh目录下生成2个文件id_rsa 和 id_rsa.pub
root@master:~# ssh-keygen -t rsa
复制公钥id_rsa.pub,并重命名为authorized_keys
root@master:~/.ssh# cp id_rsa.pub authorized_keys在slaver的root目录下创建.ssh文件夹
root@slaver:~# cd /root
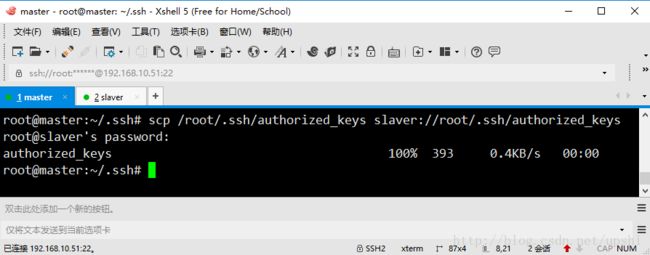
root@slaver:~# mkdir .ssh复制authorized_keys到slaver虚拟机的/root/.ssh目录下
root@master:~/.ssh# scp /root/.ssh/authorized_keys slaver://root/.ssh/authorized_keys 第一次要确认连接,并输入slaver虚拟机root用户的密码
完成后尝试ssh到slaver,不用输密码即可成功
root@master:~/.ssh# ssh root@slaver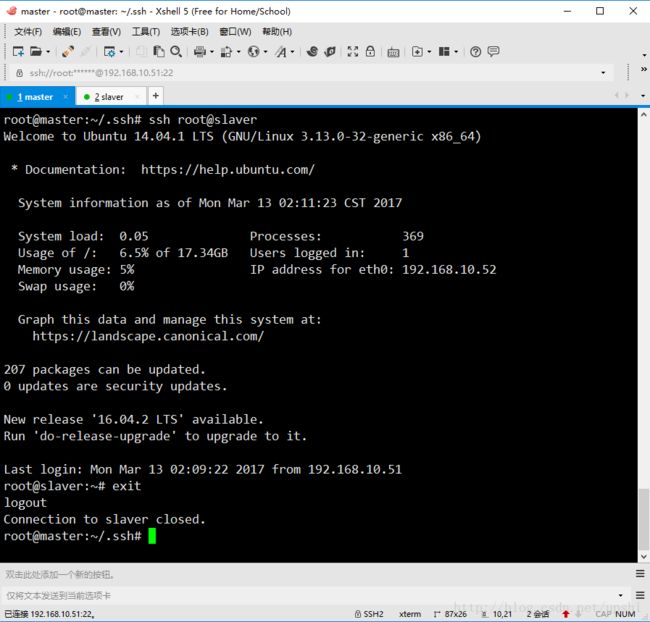
4. Ubuntu国内APT源配置
首先设置一下DNS服务器
root@master:~/.ssh# echo "nameserver 221.12.1.227" > /etc/resolv.conf备份原来的文件
root@slaver:~# cp /etc/apt/sources.list /etc/apt/sources.list.old修改文件/etc/apt/sources.list的内容如下
deb http://mirrors.163.com/ubuntu/ trusty main restricted universe multiverse
deb http://mirrors.163.com/ubuntu/ trusty-security main restricted universe multiverse
deb http://mirrors.163.com/ubuntu/ trusty-updates main restricted universe multiverse
deb http://mirrors.163.com/ubuntu/ trusty-proposed main restricted universe multiverse
deb http://mirrors.163.com/ubuntu/ trusty-backports main restricted universe multiverse
deb-src http://mirrors.163.com/ubuntu/ trusty main restricted universe multiverse
deb-src http://mirrors.163.com/ubuntu/ trusty-security main restricted universe multiverse
deb-src http://mirrors.163.com/ubuntu/ trusty-updates main restricted universe multiverse
deb-src http://mirrors.163.com/ubuntu/ trusty-proposed main restricted universe multiverse
deb-src http://mirrors.163.com/ubuntu/ trusty-backports main restricted universe multiverse更新软件
apt-get update
apt-get upgrade5. 安装JDK,Scala,MySQL
先上传所有用到的软件,这里使用xftp软件进行操作,上传到/opt目录下
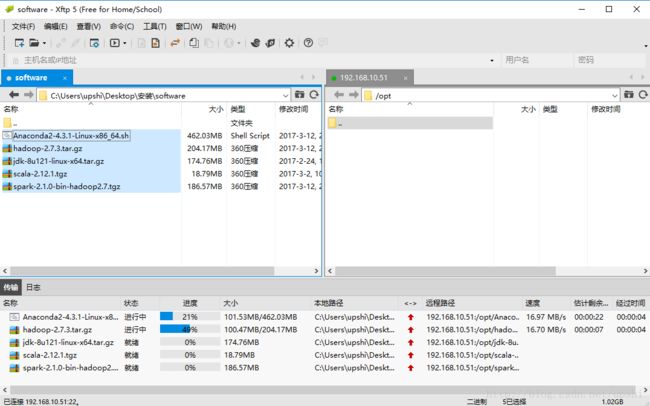
5.1 安装JDK
进入/opt目录,解压jdk-8u121-linux-x64.tar.gz
root@master:/opt# cd /opt/
root@master:/opt# tar -zxvf jdk-8u121-linux-x64.tar.gz配置环境变量
root@master:/opt# vi /etc/profile在最后加上下面几行配置
export JAVA_HOME=/opt/jdk1.8.0_121
export JRE_HOME=$JAVA_HOME/jre
export CLASSPATH=$JAVA_HOME/lib:$JRE_HOME/lib:$CLASSPATH
export PATH=$JAVA_HOME/bin:$JRE_HOME/bin:$PATH
刷新/etc/profile文件
root@master:/opt# source /etc/profile判断环境变量是否生效
root@master:/opt# java -version
java version "1.8.0_121"
Java(TM) SE Runtime Environment (build 1.8.0_121-b13)
Java HotSpot(TM) 64-Bit Server VM (build 25.121-b13, mixed mode)从节点安装同上
5.2 安装Scala
进入/opt目录,解压scala-2.12.1.tgz
root@master:/opt# cd /opt/
root@master:/opt# tar -zxvf scala-2.12.1.tgz配置环境变量
root@master:/opt# vi /etc/profile更改最下面几行配置
export JAVA_HOME=/opt/jdk1.8.0_121
export JRE_HOME=$JAVA_HOME/jre
export CLASSPATH=$JAVA_HOME/lib:$JRE_HOME/lib:$CLASSPATH
export SCALA_HOME=/opt/scala-2.12.1
export PATH=$JAVA_HOME/bin:$JRE_HOME/bin:$SCALA_HOME/bin:$PATH刷新/etc/profile文件
root@master:/opt# source /etc/profile判断环境变量是否生效
root@master:/opt# scala -version
Scala code runner version 2.12.1 -- Copyright 2002-2016, LAMP/EPFL and Lightbend, Inc.从节点安装同上
5.3 安装MySQL
root@master:/opt# apt-get install mysql-server输入root用户密码,并重复
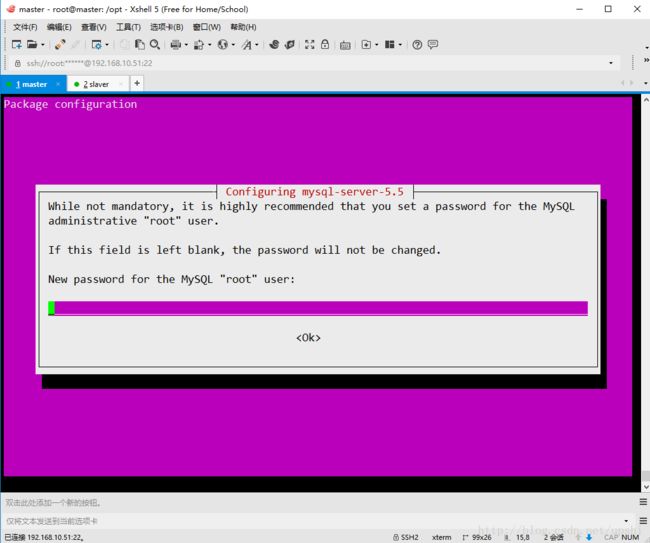
设置MySQL字符集,先查看一下当前字符集情况,有一些latin1格式
root@slaver:/opt# mysql -uroot -p123456
Welcome to the MySQL monitor. Commands end with ; or \g.
Your MySQL connection id is 43
Server version: 5.5.54-0ubuntu0.14.04.1 (Ubuntu)
Copyright (c) 2000, 2016, Oracle and/or its affiliates. All rights reserved.
Oracle is a registered trademark of Oracle Corporation and/or its
affiliates. Other names may be trademarks of their respective
owners.
Type 'help;' or '\h' for help. Type '\c' to clear the current input statement.
mysql> show variables like '%char%';
+--------------------------+----------------------------+
| Variable_name | Value |
+--------------------------+----------------------------+
| character_set_client | utf8 |
| character_set_connection | utf8 |
| character_set_database | latin1 |
| character_set_filesystem | binary |
| character_set_results | utf8 |
| character_set_server | latin1 |
| character_set_system | utf8 |
| character_sets_dir | /usr/share/mysql/charsets/ |
+--------------------------+----------------------------+
8 rows in set (0.00 sec)编辑配置文件
root@master:/opt# vi /etc/mysql/my.cnf在[mysql]和[client]标签下加入配置
default-character-set=utf8在[mysqld]标签下加入配置
character-set-server=utf8在bind-address = 127.0.0.1前加上#号,以注释掉这行,便于客户端连接
重启MySQL服务
root@master:/opt# service mysql restart连接MySQL命令行终端查看当前字符集情况
root@master:/opt# mysql -uroot -p123456
Welcome to the MySQL monitor. Commands end with ; or \g.
Your MySQL connection id is 36
Server version: 5.5.54-0ubuntu0.14.04.1 (Ubuntu)
Copyright (c) 2000, 2016, Oracle and/or its affiliates. All rights reserved.
Oracle is a registered trademark of Oracle Corporation and/or its
affiliates. Other names may be trademarks of their respective
owners.
Type 'help;' or '\h' for help. Type '\c' to clear the current input statement.
mysql> show variables like '%char%';
+--------------------------+----------------------------+
| Variable_name | Value |
+--------------------------+----------------------------+
| character_set_client | utf8 |
| character_set_connection | utf8 |
| character_set_database | utf8 |
| character_set_filesystem | binary |
| character_set_results | utf8 |
| character_set_server | utf8 |
| character_set_system | utf8 |
| character_sets_dir | /usr/share/mysql/charsets/ |
+--------------------------+----------------------------+
8 rows in set (0.00 sec)配置远程连接
mysql> use mysql
Reading table information for completion of table and column names
You can turn off this feature to get a quicker startup with -A
Database changed
mysql> select host, user from user;
+-----------+------------------+
| host | user |
+-----------+------------------+
| 127.0.0.1 | root |
| ::1 | root |
| localhost | debian-sys-maint |
| localhost | root |
| master | root |
+-----------+------------------+
5 rows in set (0.00 sec)
mysql> update user set host = '%' where user = 'root' and host='localhost';
Query OK, 1 row affected (0.00 sec)
Rows matched: 1 Changed: 1 Warnings: 0
mysql> flush privileges;
Query OK, 0 rows affected (0.00 sec)关键语句
use mysql;
update user set host = '%' where user = 'root' and host='localhost';
flush privileges;从节点安装同上
6. Hadoop集群安装
6.1 安装
进入/opt目录,解压hadoop-2.7.3.tar.gz
root@master:/opt# cd /opt/
root@master:/opt# tar -zxvf hadoop-2.7.3.tar.gz配置环境变量
root@master:/opt# vi /etc/profile更新最下面几行配置
export JAVA_HOME=/opt/jdk1.8.0_121
export JRE_HOME=$JAVA_HOME/jre
export CLASSPATH=$JAVA_HOME/lib:$JRE_HOME/lib:$CLASSPATH
export SCALA_HOME=/opt/scala-2.12.1
export HADOOP_HOME=/opt/hadoop-2.7.3
export PATH=$JAVA_HOME/bin:$JRE_HOME/bin:$SCALA_HOME/bin:$HADOOP_HOME/bin:$PATH刷新/etc/profile文件
root@master:/opt# source /etc/profile判断环境变量是否生效
root@master:/opt# hadoop version
Hadoop 2.7.3
Subversion https://git-wip-us.apache.org/repos/asf/hadoop.git -r baa91f7c6bc9cb92be5982de4719c1c8af91ccff
Compiled by root on 2016-08-18T01:41Z
Compiled with protoc 2.5.0
From source with checksum 2e4ce5f957ea4db193bce3734ff29ff4
This command was run using /opt/hadoop-2.7.3/share/hadoop/common/hadoop-common-2.7.3.jar从节点安装同上
6.2 配置
配置hadoop的环境,设置JAVA_HOME
root@master:/opt# vi /opt/hadoop-2.7.3/etc/hadoop/hadoop-env.sh更改export JAVA_HOME=/opt/jdk1.8.0_77
先创建一些目录,结构如下图
/root
/hadoop
/dfs
/name
/data接下来配置/opt/hadoop-2.7.3/etc/hadoop/目录下的配置文件
6.2.1 配置 core-site.xml
<configuration>
<property>
<name>hadoop.tmp.dirname>
<value>/root/hadoop/tmpvalue>
<description>Abase for other temporary directories.description>
property>
<property>
<name>fs.defaultFSname>
<value>hdfs://master:9000value>
property>
<property>
<name>io.file.buffer.sizename>
<value>4096value>
property>
configuration>6.2.2 配置 hdfs-site.xml
<configuration>
<property>
<name>dfs.namenode.secondary.http-addressname>
<value>master:9001value>
property>
<property>
<name>dfs.namenode.name.dirname>
<value>file:/root/hadoop/dfs/namevalue>
property>
<property>
<name>dfs.datanode.data.dirname>
<value>file:/root/hadoop/dfs/datavalue>
property>
<property>
<name>dfs.replicationname>
<value>3value>
property>
<property>
<name>dfs.webhdfs.enabledname>
<value>truevalue>
property>
configuration>
6.2.3 配置 mapred-site.xml
复制mapred-site.xml.template 并重命名为 mapred-site.xml
root@master:/opt/hadoop-2.7.3/etc/hadoop# cp mapred-site.xml.template mapred-site.xml配置如下
<configuration>
<property>
<name>mapreduce.framework.namename>
<value>yarnvalue>
<final>truefinal>
property>
<property>
<name>mapreduce.jobtracker.http.addressname>
<value>master:50030value>
property>
<property>
<name>mapreduce.jobhistory.addressname>
<value>master:10020value>
property>
<property>
<name>mapreduce.jobhistory.webapp.addressname>
<value>master:19888value>
property>
<property>
<name>mapred.job.trackername>
<value>http://master:9001value>
property>
configuration>6.2.4 配置 yarn-site.xml
<configuration>
<property>
<name>yarn.resourcemanager.hostnamename>
<value>mastervalue>
property>
<property>
<name>yarn.nodemanager.aux-servicesname>
<value>mapreduce_shufflevalue>
property>
<property>
<name>yarn.nodemanager.aux-services.mapreduce.shuffle.classname>
<value>org.apache.hadoop.mapred.ShuffleHandlervalue>
property>
<property>
<name>yarn.resourcemanager.addressname>
<value>master:8032value>
property>
<property>
<name>yarn.resourcemanager.scheduler.addressname>
<value>master:8030value>
property>
<property>
<name>yarn.resourcemanager.resource-tracker.addressname>
<value>master:8035value>
property>
<property>
<name>yarn.resourcemanager.admin.addressname>
<value>master:8033value>
property>
<property>
<name>yarn.resourcemanager.webapp.addressname>
<value>master:8088value>
property>
configuration>6.2.5 配置slaves
master
slaver6.3 将上述配置复制一份到从节点相应目录
在slaver节点也创建相应目录
/root
/hadoop
/dfs
/name
/data
root@master:/opt# scp -r /opt/hadoop-2.7.3 slaver://opt/6.4 格式化NameNode
启动Hadoop之前必须执行此操作,每个节点上都执行一下
root@master:/opt# hadoop namenode -format6.5 在master节点启动Hadoop集群
进入/opt/hadoop-2.7.3/sbin 目录下
启动 ./start-all.sh(Deprecated) 或者 ./start-dfs.sh & ./start-yarn.sh
停止 ./stop-all.sh(Deprecated) 或者 ./stop-dfs.sh & ./stop-yarn.sh
root@master:/opt# cd /opt/hadoop-2.7.3/sbin/
root@master:/opt/hadoop-2.7.3/sbin# ./start-all.sh执行结果如下
This script is Deprecated. Instead use start-dfs.sh and start-yarn.sh
Starting namenodes on [master]
master: starting namenode, logging to /opt/hadoop-2.7.3/logs/hadoop-root-namenode-master.out
master: starting datanode, logging to /opt/hadoop-2.7.3/logs/hadoop-root-datanode-master.out
slaver: starting datanode, logging to /opt/hadoop-2.7.3/logs/hadoop-root-datanode-slaver.out
Starting secondary namenodes [master]
master: starting secondarynamenode, logging to /opt/hadoop-2.7.3/logs/hadoop-root-secondarynamenode-master.out
starting yarn daemons
starting resourcemanager, logging to /opt/hadoop-2.7.3/logs/yarn-root-resourcemanager-master.out
slaver: starting nodemanager, logging to /opt/hadoop-2.7.3/logs/yarn-root-nodemanager-slaver.out
master: starting nodemanager, logging to /opt/hadoop-2.7.3/logs/yarn-root-nodemanager-master.out6.6 访问http://192.168.10.51:50070 可以查看Hadoop集群的节点数、NameNode及整个分布式文件系统的状态
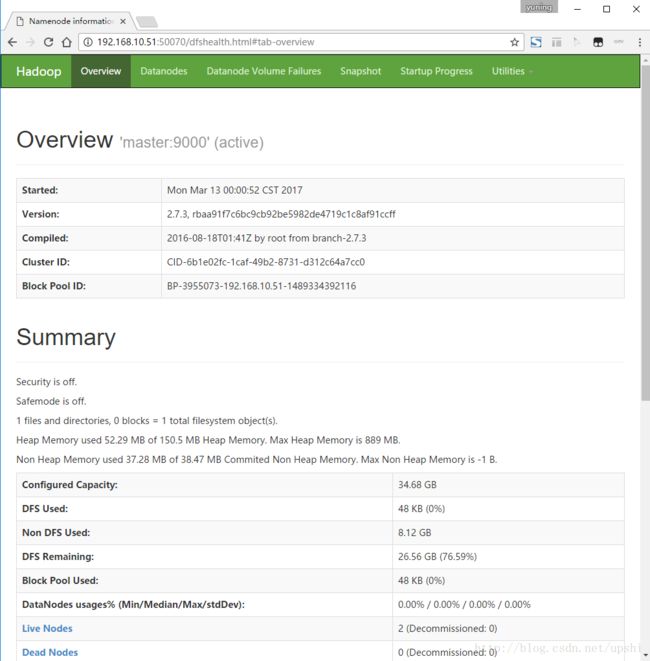
7. Spark集群安装
7.1 安装Spark
进入/opt目录,解压spark-2.1.0-bin-hadoop2.7.tgz
root@master:/opt# cd /opt/
root@master:/opt# tar -zxvf spark-2.1.0-bin-hadoop2.7.tgz配置环境变量
root@master:/opt# vi /etc/profile更新最下面几行配置
export JAVA_HOME=/opt/jdk1.8.0_121
export JRE_HOME=$JAVA_HOME/jre
export CLASSPATH=$JAVA_HOME/lib:$JRE_HOME/lib:$CLASSPATH
export SCALA_HOME=/opt/scala-2.12.1
export HADOOP_HOME=/opt/hadoop-2.7.3
export SPARK_HOME=/opt/spark-2.1.0
export PATH=$JAVA_HOME/bin:$JRE_HOME/bin:$SCALA_HOME/bin:$HADOOP_HOME/bin:$PATH:$SPARK_HOME/bin:$PATH刷新/etc/profile文件
root@master:/opt# source /etc/profile从节点安装同上
7.2 配置Spark
7.2.1 配置 spark-env.sh
进入 Spark 安装目录下的 conf 目录, 拷贝 spark-env.sh.template 到 spark-env.sh
root@master:/opt/spark-2.1.0/conf# cp spark-env.sh.template spark-env.sh编辑 spark-env.sh,在其中添加以下配置信息
export SCALA_HOME=/opt/scala-2.12.1
export JAVA_HOME=/opt/jdk1.8.0_121
export SPARK_MASTER_IP=192.168.10.51
export SPARK_WORKER_MEMORY=1g
export HADOOP_CONF_DIR=/opt/hadoop-2.7.3/etc/hadoopJAVA_HOME 指定 Java 安装目录;
SCALA_HOME 指定 Scala 安装目录;
SPARK_MASTER_IP 指定 Spark 集群 Master 节点的 IP 地址;
SPARK_WORKER_MEMORY 指定的是 Worker 节点能够分配给 Executors 的最大内存大小;
HADOOP_CONF_DIR 指定 Hadoop 集群配置文件目录。
7.2.2 配置 slaves
将 slaves.template 拷贝到 slaves, 编辑其内容为
master
slaver7.2.3 将上述所有文件复制一份到从节点
root@master:/opt# scp -r spark-2.1.0 slaver://opt/7.3 启动Spark集群
进入spark的sbin目录
root@master:/# cd /opt/spark-2.1.0/sbin/
root@master:/opt/spark-2.1.0/sbin# ./start-all.sh启动成功,访问http://192.168.10.51:8080/
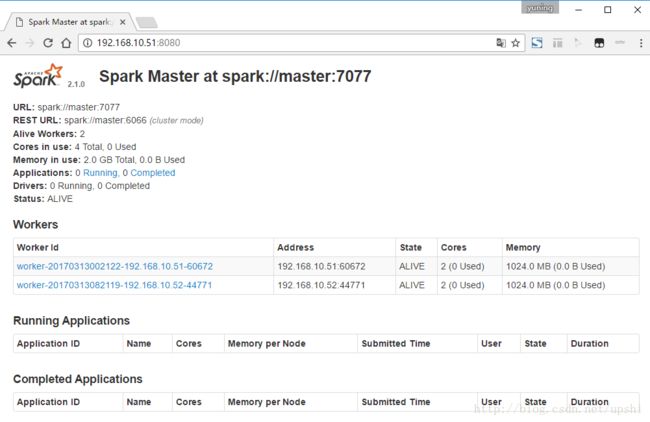
7.4 运行Spark示例
7.4.1 脚本示例
进入spark-shell
root@master:/opt/spark-2.1.0# bin/spark-shell输出如下
Setting default log level to "WARN".
To adjust logging level use sc.setLogLevel(newLevel). For SparkR, use setLogLevel(newLevel).
17/03/13 08:56:16 WARN util.NativeCodeLoader: Unable to load native-hadoop library for your platform... using builtin-java classes where applicable
17/03/13 08:56:23 WARN metastore.ObjectStore: Version information not found in metastore. hive.metastore.schema.verification is not enabled so recording the schema version 1.2.0
17/03/13 08:56:23 WARN metastore.ObjectStore: Failed to get database default, returning NoSuchObjectException
17/03/13 08:56:26 WARN metastore.ObjectStore: Failed to get database global_temp, returning NoSuchObjectException
Spark context Web UI available at http://192.168.10.51:4040
Spark context available as 'sc' (master = local[*], app id = local-1489366577140).
Spark session available as 'spark'.
Welcome to
____ __
/ __/__ ___ _____/ /__
_\ \/ _ \/ _ `/ __/ '_/
/___/ .__/\_,_/_/ /_/\_\ version 2.1.0
/_/
Using Scala version 2.11.8 (Java HotSpot(TM) 64-Bit Server VM, Java 1.8.0_121)
Type in expressions to have them evaluated.
Type :help for more information.
scala>执行一些交互式命令测试一下
scala> val txt = sc.textFile("file:///opt/spark-2.1.0/README.md")
txt: org.apache.spark.rdd.RDD[String] = file:///opt/spark-2.1.0/README.md MapPartitionsRDD[5] at textFile at :24
scala> txt.take(5).foreach(println)
# Apache Spark
Spark is a fast and general cluster computing system for Big Data. It provides
high-level APIs in Scala, Java, Python, and R, and an optimized engine that
supports general computation graphs for data analysis. It also supports a 7.4.2 集群任务示例
root@master:/opt# cd /opt/spark-2.1.0/
root@master:/opt/spark-2.1.0# bin/run-example SparkPi 10运行结果如下,Pi is roughly 3.1426071426071425
17/03/13 08:40:35 INFO spark.SparkContext: Running Spark version 2.1.0
17/03/13 08:40:36 WARN util.NativeCodeLoader: Unable to load native-hadoop library for your platform... using builtin-java classes where applicable
17/03/13 08:40:36 INFO spark.SecurityManager: Changing view acls to: root
17/03/13 08:40:36 INFO spark.SecurityManager: Changing modify acls to: root
17/03/13 08:40:36 INFO spark.SecurityManager: Changing view acls groups to:
17/03/13 08:40:36 INFO spark.SecurityManager: Changing modify acls groups to:
17/03/13 08:40:36 INFO spark.SecurityManager: SecurityManager: authentication disabled; ui acls disabled; users with view permissions: Set(root); groups with view permissions: Set(); users with modify permissions: Set(root); groups with modify permissions: Set()
17/03/13 08:40:37 INFO util.Utils: Successfully started service 'sparkDriver' on port 40080.
17/03/13 08:40:37 INFO spark.SparkEnv: Registering MapOutputTracker
17/03/13 08:40:37 INFO spark.SparkEnv: Registering BlockManagerMaster
17/03/13 08:40:37 INFO storage.BlockManagerMasterEndpoint: Using org.apache.spark.storage.DefaultTopologyMapper for getting topology information
17/03/13 08:40:37 INFO storage.BlockManagerMasterEndpoint: BlockManagerMasterEndpoint up
17/03/13 08:40:37 INFO storage.DiskBlockManager: Created local directory at /tmp/blockmgr-d960b5d4-e2f6-44f0-b01b-7aa3001b7d27
17/03/13 08:40:37 INFO memory.MemoryStore: MemoryStore started with capacity 366.3 MB
17/03/13 08:40:37 INFO spark.SparkEnv: Registering OutputCommitCoordinator
17/03/13 08:40:37 INFO util.log: Logging initialized @2891ms
17/03/13 08:40:37 INFO server.Server: jetty-9.2.z-SNAPSHOT
17/03/13 08:40:37 INFO handler.ContextHandler: Started o.s.j.s.ServletContextHandler@7997b197{/jobs,null,AVAILABLE}
17/03/13 08:40:37 INFO handler.ContextHandler: Started o.s.j.s.ServletContextHandler@11dee337{/jobs/json,null,AVAILABLE}
17/03/13 08:40:37 INFO handler.ContextHandler: Started o.s.j.s.ServletContextHandler@460f76a6{/jobs/job,null,AVAILABLE}
17/03/13 08:40:37 INFO handler.ContextHandler: Started o.s.j.s.ServletContextHandler@55f3c410{/jobs/job/json,null,AVAILABLE}
17/03/13 08:40:37 INFO handler.ContextHandler: Started o.s.j.s.ServletContextHandler@11acdc30{/stages,null,AVAILABLE}
17/03/13 08:40:37 INFO handler.ContextHandler: Started o.s.j.s.ServletContextHandler@770d4269{/stages/json,null,AVAILABLE}
17/03/13 08:40:37 INFO handler.ContextHandler: Started o.s.j.s.ServletContextHandler@4a8ab068{/stages/stage,null,AVAILABLE}
17/03/13 08:40:37 INFO handler.ContextHandler: Started o.s.j.s.ServletContextHandler@1922e6d{/stages/stage/json,null,AVAILABLE}
17/03/13 08:40:37 INFO handler.ContextHandler: Started o.s.j.s.ServletContextHandler@76a82f33{/stages/pool,null,AVAILABLE}
17/03/13 08:40:37 INFO handler.ContextHandler: Started o.s.j.s.ServletContextHandler@6bab2585{/stages/pool/json,null,AVAILABLE}
17/03/13 08:40:37 INFO handler.ContextHandler: Started o.s.j.s.ServletContextHandler@74bdc168{/storage,null,AVAILABLE}
17/03/13 08:40:37 INFO handler.ContextHandler: Started o.s.j.s.ServletContextHandler@644c78d4{/storage/json,null,AVAILABLE}
17/03/13 08:40:37 INFO handler.ContextHandler: Started o.s.j.s.ServletContextHandler@532a02d9{/storage/rdd,null,AVAILABLE}
17/03/13 08:40:37 INFO handler.ContextHandler: Started o.s.j.s.ServletContextHandler@611f8234{/storage/rdd/json,null,AVAILABLE}
17/03/13 08:40:37 INFO handler.ContextHandler: Started o.s.j.s.ServletContextHandler@7bb3a9fe{/environment,null,AVAILABLE}
17/03/13 08:40:37 INFO handler.ContextHandler: Started o.s.j.s.ServletContextHandler@7cbee484{/environment/json,null,AVAILABLE}
17/03/13 08:40:37 INFO handler.ContextHandler: Started o.s.j.s.ServletContextHandler@7f811d00{/executors,null,AVAILABLE}
17/03/13 08:40:37 INFO handler.ContextHandler: Started o.s.j.s.ServletContextHandler@62923ee6{/executors/json,null,AVAILABLE}
17/03/13 08:40:37 INFO handler.ContextHandler: Started o.s.j.s.ServletContextHandler@4089713{/executors/threadDump,null,AVAILABLE}
17/03/13 08:40:37 INFO handler.ContextHandler: Started o.s.j.s.ServletContextHandler@f19c9d2{/executors/threadDump/json,null,AVAILABLE}
17/03/13 08:40:37 INFO handler.ContextHandler: Started o.s.j.s.ServletContextHandler@7807ac2c{/static,null,AVAILABLE}
17/03/13 08:40:37 INFO handler.ContextHandler: Started o.s.j.s.ServletContextHandler@b91d8c4{/,null,AVAILABLE}
17/03/13 08:40:37 INFO handler.ContextHandler: Started o.s.j.s.ServletContextHandler@4b6166aa{/api,null,AVAILABLE}
17/03/13 08:40:37 INFO handler.ContextHandler: Started o.s.j.s.ServletContextHandler@a77614d{/jobs/job/kill,null,AVAILABLE}
17/03/13 08:40:37 INFO handler.ContextHandler: Started o.s.j.s.ServletContextHandler@4fd4cae3{/stages/stage/kill,null,AVAILABLE}
17/03/13 08:40:37 INFO server.ServerConnector: Started ServerConnector@74717975{HTTP/1.1}{0.0.0.0:4040}
17/03/13 08:40:37 INFO server.Server: Started @3127ms
17/03/13 08:40:37 INFO util.Utils: Successfully started service 'SparkUI' on port 4040.
17/03/13 08:40:37 INFO ui.SparkUI: Bound SparkUI to 0.0.0.0, and started at http://192.168.10.51:4040
17/03/13 08:40:37 INFO spark.SparkContext: Added JAR file:/opt/spark-2.1.0/examples/jars/scopt_2.11-3.3.0.jar at spark://192.168.10.51:40080/jars/scopt_2.11-3.3.0.jar with timestamp 1489365637717
17/03/13 08:40:37 INFO spark.SparkContext: Added JAR file:/opt/spark-2.1.0/examples/jars/spark-examples_2.11-2.1.0.jar at spark://192.168.10.51:40080/jars/spark-examples_2.11-2.1.0.jar with timestamp 1489365637719
17/03/13 08:40:37 INFO executor.Executor: Starting executor ID driver on host localhost
17/03/13 08:40:37 INFO util.Utils: Successfully started service 'org.apache.spark.network.netty.NettyBlockTransferService' on port 42058.
17/03/13 08:40:37 INFO netty.NettyBlockTransferService: Server created on 192.168.10.51:42058
17/03/13 08:40:37 INFO storage.BlockManager: Using org.apache.spark.storage.RandomBlockReplicationPolicy for block replication policy
17/03/13 08:40:37 INFO storage.BlockManagerMaster: Registering BlockManager BlockManagerId(driver, 192.168.10.51, 42058, None)
17/03/13 08:40:37 INFO storage.BlockManagerMasterEndpoint: Registering block manager 192.168.10.51:42058 with 366.3 MB RAM, BlockManagerId(driver, 192.168.10.51, 42058, None)
17/03/13 08:40:37 INFO storage.BlockManagerMaster: Registered BlockManager BlockManagerId(driver, 192.168.10.51, 42058, None)
17/03/13 08:40:37 INFO storage.BlockManager: Initialized BlockManager: BlockManagerId(driver, 192.168.10.51, 42058, None)
17/03/13 08:40:38 INFO handler.ContextHandler: Started o.s.j.s.ServletContextHandler@5bdaf2ce{/metrics/json,null,AVAILABLE}
17/03/13 08:40:38 INFO internal.SharedState: Warehouse path is 'file:/opt/spark-2.1.0/spark-warehouse'.
17/03/13 08:40:38 INFO handler.ContextHandler: Started o.s.j.s.ServletContextHandler@2f4919b0{/SQL,null,AVAILABLE}
17/03/13 08:40:38 INFO handler.ContextHandler: Started o.s.j.s.ServletContextHandler@75b21c3b{/SQL/json,null,AVAILABLE}
17/03/13 08:40:38 INFO handler.ContextHandler: Started o.s.j.s.ServletContextHandler@2c42b421{/SQL/execution,null,AVAILABLE}
17/03/13 08:40:38 INFO handler.ContextHandler: Started o.s.j.s.ServletContextHandler@deb3b60{/SQL/execution/json,null,AVAILABLE}
17/03/13 08:40:38 INFO handler.ContextHandler: Started o.s.j.s.ServletContextHandler@4c060c8f{/static/sql,null,AVAILABLE}
17/03/13 08:40:38 INFO spark.SparkContext: Starting job: reduce at SparkPi.scala:38
17/03/13 08:40:38 INFO scheduler.DAGScheduler: Got job 0 (reduce at SparkPi.scala:38) with 10 output partitions
17/03/13 08:40:38 INFO scheduler.DAGScheduler: Final stage: ResultStage 0 (reduce at SparkPi.scala:38)
17/03/13 08:40:38 INFO scheduler.DAGScheduler: Parents of final stage: List()
17/03/13 08:40:38 INFO scheduler.DAGScheduler: Missing parents: List()
17/03/13 08:40:39 INFO scheduler.DAGScheduler: Submitting ResultStage 0 (MapPartitionsRDD[1] at map at SparkPi.scala:34), which has no missing parents
17/03/13 08:40:39 INFO memory.MemoryStore: Block broadcast_0 stored as values in memory (estimated size 1832.0 B, free 366.3 MB)
17/03/13 08:40:39 INFO memory.MemoryStore: Block broadcast_0_piece0 stored as bytes in memory (estimated size 1172.0 B, free 366.3 MB)
17/03/13 08:40:39 INFO storage.BlockManagerInfo: Added broadcast_0_piece0 in memory on 192.168.10.51:42058 (size: 1172.0 B, free: 366.3 MB)
17/03/13 08:40:39 INFO spark.SparkContext: Created broadcast 0 from broadcast at DAGScheduler.scala:996
17/03/13 08:40:39 INFO scheduler.DAGScheduler: Submitting 10 missing tasks from ResultStage 0 (MapPartitionsRDD[1] at map at SparkPi.scala:34)
17/03/13 08:40:39 INFO scheduler.TaskSchedulerImpl: Adding task set 0.0 with 10 tasks
17/03/13 08:40:39 INFO scheduler.TaskSetManager: Starting task 0.0 in stage 0.0 (TID 0, localhost, executor driver, partition 0, PROCESS_LOCAL, 6088 bytes)
17/03/13 08:40:39 INFO scheduler.TaskSetManager: Starting task 1.0 in stage 0.0 (TID 1, localhost, executor driver, partition 1, PROCESS_LOCAL, 6088 bytes)
17/03/13 08:40:39 INFO executor.Executor: Running task 1.0 in stage 0.0 (TID 1)
17/03/13 08:40:39 INFO executor.Executor: Running task 0.0 in stage 0.0 (TID 0)
17/03/13 08:40:39 INFO executor.Executor: Fetching spark://192.168.10.51:40080/jars/scopt_2.11-3.3.0.jar with timestamp 1489365637717
17/03/13 08:40:39 INFO client.TransportClientFactory: Successfully created connection to /192.168.10.51:40080 after 36 ms (0 ms spent in bootstraps)
17/03/13 08:40:39 INFO util.Utils: Fetching spark://192.168.10.51:40080/jars/scopt_2.11-3.3.0.jar to /tmp/spark-235f31a2-48ab-461a-a7c9-8cc778d189f0/userFiles-bf07bd73-08bb-46f0-b0c8-2bd10851b982/fetchFileTemp8748171460005515438.tmp
17/03/13 08:40:39 INFO executor.Executor: Adding file:/tmp/spark-235f31a2-48ab-461a-a7c9-8cc778d189f0/userFiles-bf07bd73-08bb-46f0-b0c8-2bd10851b982/scopt_2.11-3.3.0.jar to class loader
17/03/13 08:40:39 INFO executor.Executor: Fetching spark://192.168.10.51:40080/jars/spark-examples_2.11-2.1.0.jar with timestamp 1489365637719
17/03/13 08:40:39 INFO util.Utils: Fetching spark://192.168.10.51:40080/jars/spark-examples_2.11-2.1.0.jar to /tmp/spark-235f31a2-48ab-461a-a7c9-8cc778d189f0/userFiles-bf07bd73-08bb-46f0-b0c8-2bd10851b982/fetchFileTemp9148668076438309566.tmp
17/03/13 08:40:39 INFO executor.Executor: Adding file:/tmp/spark-235f31a2-48ab-461a-a7c9-8cc778d189f0/userFiles-bf07bd73-08bb-46f0-b0c8-2bd10851b982/spark-examples_2.11-2.1.0.jar to class loader
17/03/13 08:40:40 INFO executor.Executor: Finished task 0.0 in stage 0.0 (TID 0). 1041 bytes result sent to driver
17/03/13 08:40:40 INFO executor.Executor: Finished task 1.0 in stage 0.0 (TID 1). 1128 bytes result sent to driver
17/03/13 08:40:40 INFO scheduler.TaskSetManager: Starting task 2.0 in stage 0.0 (TID 2, localhost, executor driver, partition 2, PROCESS_LOCAL, 6088 bytes)
17/03/13 08:40:40 INFO executor.Executor: Running task 2.0 in stage 0.0 (TID 2)
17/03/13 08:40:40 INFO scheduler.TaskSetManager: Starting task 3.0 in stage 0.0 (TID 3, localhost, executor driver, partition 3, PROCESS_LOCAL, 6088 bytes)
17/03/13 08:40:40 INFO executor.Executor: Running task 3.0 in stage 0.0 (TID 3)
17/03/13 08:40:40 INFO scheduler.TaskSetManager: Finished task 0.0 in stage 0.0 (TID 0) in 689 ms on localhost (executor driver) (1/10)
17/03/13 08:40:40 INFO scheduler.TaskSetManager: Finished task 1.0 in stage 0.0 (TID 1) in 634 ms on localhost (executor driver) (2/10)
17/03/13 08:40:40 INFO executor.Executor: Finished task 2.0 in stage 0.0 (TID 2). 1041 bytes result sent to driver
17/03/13 08:40:40 INFO scheduler.TaskSetManager: Starting task 4.0 in stage 0.0 (TID 4, localhost, executor driver, partition 4, PROCESS_LOCAL, 6088 bytes)
17/03/13 08:40:40 INFO executor.Executor: Running task 4.0 in stage 0.0 (TID 4)
17/03/13 08:40:40 INFO executor.Executor: Finished task 3.0 in stage 0.0 (TID 3). 1041 bytes result sent to driver
17/03/13 08:40:40 INFO scheduler.TaskSetManager: Finished task 2.0 in stage 0.0 (TID 2) in 160 ms on localhost (executor driver) (3/10)
17/03/13 08:40:40 INFO scheduler.TaskSetManager: Starting task 5.0 in stage 0.0 (TID 5, localhost, executor driver, partition 5, PROCESS_LOCAL, 6088 bytes)
17/03/13 08:40:40 INFO executor.Executor: Running task 5.0 in stage 0.0 (TID 5)
17/03/13 08:40:40 INFO scheduler.TaskSetManager: Finished task 3.0 in stage 0.0 (TID 3) in 172 ms on localhost (executor driver) (4/10)
17/03/13 08:40:40 INFO executor.Executor: Finished task 4.0 in stage 0.0 (TID 4). 1041 bytes result sent to driver
17/03/13 08:40:40 INFO scheduler.TaskSetManager: Starting task 6.0 in stage 0.0 (TID 6, localhost, executor driver, partition 6, PROCESS_LOCAL, 6088 bytes)
17/03/13 08:40:40 INFO scheduler.TaskSetManager: Finished task 4.0 in stage 0.0 (TID 4) in 89 ms on localhost (executor driver) (5/10)
17/03/13 08:40:40 INFO executor.Executor: Running task 6.0 in stage 0.0 (TID 6)
17/03/13 08:40:40 INFO executor.Executor: Finished task 5.0 in stage 0.0 (TID 5). 1041 bytes result sent to driver
17/03/13 08:40:40 INFO scheduler.TaskSetManager: Starting task 7.0 in stage 0.0 (TID 7, localhost, executor driver, partition 7, PROCESS_LOCAL, 6088 bytes)
17/03/13 08:40:40 INFO scheduler.TaskSetManager: Finished task 5.0 in stage 0.0 (TID 5) in 120 ms on localhost (executor driver) (6/10)
17/03/13 08:40:40 INFO executor.Executor: Running task 7.0 in stage 0.0 (TID 7)
17/03/13 08:40:40 INFO executor.Executor: Finished task 6.0 in stage 0.0 (TID 6). 1041 bytes result sent to driver
17/03/13 08:40:40 INFO scheduler.TaskSetManager: Starting task 8.0 in stage 0.0 (TID 8, localhost, executor driver, partition 8, PROCESS_LOCAL, 6088 bytes)
17/03/13 08:40:40 INFO scheduler.TaskSetManager: Finished task 6.0 in stage 0.0 (TID 6) in 118 ms on localhost (executor driver) (7/10)
17/03/13 08:40:40 INFO executor.Executor: Running task 8.0 in stage 0.0 (TID 8)
17/03/13 08:40:40 INFO executor.Executor: Finished task 7.0 in stage 0.0 (TID 7). 1128 bytes result sent to driver
17/03/13 08:40:40 INFO scheduler.TaskSetManager: Starting task 9.0 in stage 0.0 (TID 9, localhost, executor driver, partition 9, PROCESS_LOCAL, 6088 bytes)
17/03/13 08:40:40 INFO executor.Executor: Running task 9.0 in stage 0.0 (TID 9)
17/03/13 08:40:40 INFO scheduler.TaskSetManager: Finished task 7.0 in stage 0.0 (TID 7) in 88 ms on localhost (executor driver) (8/10)
17/03/13 08:40:40 INFO executor.Executor: Finished task 8.0 in stage 0.0 (TID 8). 1041 bytes result sent to driver
17/03/13 08:40:40 INFO scheduler.TaskSetManager: Finished task 8.0 in stage 0.0 (TID 8) in 106 ms on localhost (executor driver) (9/10)
17/03/13 08:40:40 INFO executor.Executor: Finished task 9.0 in stage 0.0 (TID 9). 1041 bytes result sent to driver
17/03/13 08:40:40 INFO scheduler.TaskSetManager: Finished task 9.0 in stage 0.0 (TID 9) in 105 ms on localhost (executor driver) (10/10)
17/03/13 08:40:40 INFO scheduler.DAGScheduler: ResultStage 0 (reduce at SparkPi.scala:38) finished in 1.161 s
17/03/13 08:40:40 INFO scheduler.TaskSchedulerImpl: Removed TaskSet 0.0, whose tasks have all completed, from pool
17/03/13 08:40:40 INFO scheduler.DAGScheduler: Job 0 finished: reduce at SparkPi.scala:38, took 1.764144 s
Pi is roughly 3.1426071426071425
17/03/13 08:40:40 INFO server.ServerConnector: Stopped ServerConnector@74717975{HTTP/1.1}{0.0.0.0:4040}
17/03/13 08:40:40 INFO handler.ContextHandler: Stopped o.s.j.s.ServletContextHandler@4fd4cae3{/stages/stage/kill,null,UNAVAILABLE}
17/03/13 08:40:40 INFO handler.ContextHandler: Stopped o.s.j.s.ServletContextHandler@a77614d{/jobs/job/kill,null,UNAVAILABLE}
17/03/13 08:40:40 INFO handler.ContextHandler: Stopped o.s.j.s.ServletContextHandler@4b6166aa{/api,null,UNAVAILABLE}
17/03/13 08:40:40 INFO handler.ContextHandler: Stopped o.s.j.s.ServletContextHandler@b91d8c4{/,null,UNAVAILABLE}
17/03/13 08:40:40 INFO handler.ContextHandler: Stopped o.s.j.s.ServletContextHandler@7807ac2c{/static,null,UNAVAILABLE}
17/03/13 08:40:40 INFO handler.ContextHandler: Stopped o.s.j.s.ServletContextHandler@f19c9d2{/executors/threadDump/json,null,UNAVAILABLE}
17/03/13 08:40:40 INFO handler.ContextHandler: Stopped o.s.j.s.ServletContextHandler@4089713{/executors/threadDump,null,UNAVAILABLE}
17/03/13 08:40:40 INFO handler.ContextHandler: Stopped o.s.j.s.ServletContextHandler@62923ee6{/executors/json,null,UNAVAILABLE}
17/03/13 08:40:40 INFO handler.ContextHandler: Stopped o.s.j.s.ServletContextHandler@7f811d00{/executors,null,UNAVAILABLE}
17/03/13 08:40:40 INFO handler.ContextHandler: Stopped o.s.j.s.ServletContextHandler@7cbee484{/environment/json,null,UNAVAILABLE}
17/03/13 08:40:40 INFO handler.ContextHandler: Stopped o.s.j.s.ServletContextHandler@7bb3a9fe{/environment,null,UNAVAILABLE}
17/03/13 08:40:40 INFO handler.ContextHandler: Stopped o.s.j.s.ServletContextHandler@611f8234{/storage/rdd/json,null,UNAVAILABLE}
17/03/13 08:40:40 INFO handler.ContextHandler: Stopped o.s.j.s.ServletContextHandler@532a02d9{/storage/rdd,null,UNAVAILABLE}
17/03/13 08:40:40 INFO handler.ContextHandler: Stopped o.s.j.s.ServletContextHandler@644c78d4{/storage/json,null,UNAVAILABLE}
17/03/13 08:40:40 INFO handler.ContextHandler: Stopped o.s.j.s.ServletContextHandler@74bdc168{/storage,null,UNAVAILABLE}
17/03/13 08:40:40 INFO handler.ContextHandler: Stopped o.s.j.s.ServletContextHandler@6bab2585{/stages/pool/json,null,UNAVAILABLE}
17/03/13 08:40:40 INFO handler.ContextHandler: Stopped o.s.j.s.ServletContextHandler@76a82f33{/stages/pool,null,UNAVAILABLE}
17/03/13 08:40:40 INFO handler.ContextHandler: Stopped o.s.j.s.ServletContextHandler@1922e6d{/stages/stage/json,null,UNAVAILABLE}
17/03/13 08:40:40 INFO handler.ContextHandler: Stopped o.s.j.s.ServletContextHandler@4a8ab068{/stages/stage,null,UNAVAILABLE}
17/03/13 08:40:40 INFO handler.ContextHandler: Stopped o.s.j.s.ServletContextHandler@770d4269{/stages/json,null,UNAVAILABLE}
17/03/13 08:40:40 INFO handler.ContextHandler: Stopped o.s.j.s.ServletContextHandler@11acdc30{/stages,null,UNAVAILABLE}
17/03/13 08:40:40 INFO handler.ContextHandler: Stopped o.s.j.s.ServletContextHandler@55f3c410{/jobs/job/json,null,UNAVAILABLE}
17/03/13 08:40:40 INFO handler.ContextHandler: Stopped o.s.j.s.ServletContextHandler@460f76a6{/jobs/job,null,UNAVAILABLE}
17/03/13 08:40:40 INFO handler.ContextHandler: Stopped o.s.j.s.ServletContextHandler@11dee337{/jobs/json,null,UNAVAILABLE}
17/03/13 08:40:40 INFO handler.ContextHandler: Stopped o.s.j.s.ServletContextHandler@7997b197{/jobs,null,UNAVAILABLE}
17/03/13 08:40:40 INFO ui.SparkUI: Stopped Spark web UI at http://192.168.10.51:4040
17/03/13 08:40:40 INFO spark.MapOutputTrackerMasterEndpoint: MapOutputTrackerMasterEndpoint stopped!
17/03/13 08:40:40 INFO memory.MemoryStore: MemoryStore cleared
17/03/13 08:40:40 INFO storage.BlockManager: BlockManager stopped
17/03/13 08:40:40 INFO storage.BlockManagerMaster: BlockManagerMaster stopped
17/03/13 08:40:40 INFO scheduler.OutputCommitCoordinator$OutputCommitCoordinatorEndpoint: OutputCommitCoordinator stopped!
17/03/13 08:40:40 INFO spark.SparkContext: Successfully stopped SparkContext
17/03/13 08:40:40 INFO util.ShutdownHookManager: Shutdown hook called
17/03/13 08:40:40 INFO util.ShutdownHookManager: Deleting directory /tmp/spark-235f31a2-48ab-461a-a7c9-8cc778d189f08. Anaconda安装
先进入/opt目录
安装Anaconda
root@slaver:~# cd /opt/
root@slaver:/opt# bash Anaconda2-4.3.1-Linux-x86_64.sh按回车
Welcome to Anaconda2 4.3.1 (by Continuum Analytics, Inc.)
In order to continue the installation process, please review the license
agreement.
Please, press ENTER to continue
>>> 看完协议后,输入yes
Do you approve the license terms? [yes|no]
>>>按回车默认安装,或者输入安装目录
Anaconda2 will now be installed into this location:
/root/anaconda2
- Press ENTER to confirm the location
- Press CTRL-C to abort the installation
- Or specify a different location below
[/root/anaconda2] >>> 是否配置到环境变量,输入yes
Do you wish the installer to prepend the Anaconda2 install location
to PATH in your /root/.bashrc ? [yes|no]
>>>安装成功!