从“零”开发一款知识图谱应用产品
课程介绍
本达人课展现了从“零”开始完成一个知识图谱应用产品开发过程的完整实录。
这里的“零”,意味着对读者的“零 Python 编程语言基础”以及“零知识图谱知识基础”的要求。本次课程的学习,犹如读者与作者共同进行的一次徒手攀岩历程,只要读者按着作者的思路,边学边实践,最终将勇攀知识和技术的悬崖,提升自我,斩获下面技能:
- 学会利用 Python 驾驭实际项目;
- 破除对知识图谱知识的神秘感;
- 掌握一套极具应用开发潜力的知识图谱应用开发基础资源。
当然,除了收获编程知识与成果之外,那种面向未知领域发起冲击和攀登的刺激体验,或许会成为我们意外的收获。
作者介绍
邱嘉文,历任多家 IT 公司技术带头人。做过软、硬件产品研发,主导过 DCS、MES、ERP、ITSM、FMS 和智慧城市领域的信息化项目。擅长通过总结归纳和创新思维解决实际问题。
课程内容
第01课:原来这就是知识图谱
攀岩怎能是种生活方式?
记得,在我读大学时的一个暑假中,那是一个风和日丽的晴朗夏日,我和几个同学一起穿越了青岛崂山。就在接近山脚海边之处,一座凸耸的峭壁将我吸引住了,我突然冒出了一个冲动的想法:站在这峭壁的顶上看对面的大海,一定会很美,我要攀上去!
我三蹦两跳,感觉自己身轻如燕,没几分钟就爬到了半山腰。当我快接近山顶时却遇到了一处绝境:脚下是一块倾斜向下的卧牛之地,勉强能站立,向左上方是凸出的断崖,向右岩石上下一片光滑,往上是倒倾斜约5度的绝壁,绝壁上仅有一道被雨水侵蚀出来的像刀锋般的石缝。我因为看不到这块岩石上面到底还有多高,始终不敢上攀,直到岩石上面传来一个游客的声音,让我发现岩石上面并没有多高时,我才屏住呼吸,双手交替钳住“刀锋石”向上牵拉身体,身体紧贴岩石,像只壁虎一样向上蹭了半米左右,终于攀上了岩石。我在岩石上瘫软了足有五分钟,仰望着无比美丽的蓝天白云,却没有丝毫的征服后的喜悦感,有的只是后怕和自责。我发誓:今生决不再用生命来冒险,去换取大自然的美景。
我从此确实再没有攀过真实的悬崖了。然而,时至今日,蓦然回首,我却惊异地发现,自己的整个人生,从那一刻起,原来早就注定成为了一次漫长的徒手攀岩。从参与我们国家第一套国产电力调度自动化系统的研发,到独自践行一套面向资源的应用软件开发方法;再到独创事脉顺(Smarthings)——万事互联架构;然后就是攻克电子式互感器 10kv 高压计量系统技术的难关,解决了小电流接地故障点判别行业难题;后来,提出对智慧城市的整体建模技术,开启对人工心灵模型的探索等。一路走来,我总是会选择一条未来目标明确,却又前路模糊的道路前行,似乎总是在贪恋那种独自历经艰险之后的“这边风景独好”的感觉。事实上,对我来说,从对大自然转移到对知识和技术领域中来的探险冲动,已经不再是一种精神,而是自己的一种生活方式了。
沟通平台软件路在何方?
今天,在大数据敲醒人工智能技术之时,知识图谱不知不觉再次进入了我的视野,我突然又冒出了一个冲动的想法:运用知识图谱解决人们在沟通中的问题,一定会有好的结果,我要试一下!刚好 CSDN 旗下的 GitChat 给我提供了一个高端的场地,徒手攀知识和技术的悬崖,不管是攀上了顶峰还是摔了下来,都会是种美妙的感觉,何不再来一试身手?
说起沟通软件,自然免不了要提到 QQ 和微信,它们都是非常成功的即时通讯软件。它们成功的根本原因在于,能让使用者以极小的代价,与亲朋好友同事进行联络通讯。其中微信已经不知不觉地从一款社交应用变成了承载社会应用和职场应用的平台。令人司空见惯的是,几乎每次有一个叫做“项目”事情被启动,无论是 IT 项目还是基建项目,或是其他项目,参与项目的人聚到一起就必定至少建一个微信群。几乎每个公司的每个部门的员工、全体员工都会拉起一个群。
微信强大的用户群成就了它似乎不可撼动的社会地位和高贵价值。也正因如此,业界诸多公司,包括腾讯自己都在想尽一切办法,寻找下一个能颠覆微信的新社交软件霸主。
但遗憾的是:即便微信用于职场有诸多的不便,如传不了大文件,文件不能保留查询,不能和办公系统对接等,但是多数人还是宁愿忍受这些问题的折磨,也不愿意放弃微信,甚至都不太愿意用回已经解决这些问题的 QQ。即便阿里(A)做出了强大的钉钉,可以更完美解决这些微信用户职场应用的痛点,依然还是无法在职场应用上替代微信的霸主地位。看来,在社交平台领域,靠细分市场的做法来赢得竞争似乎是无法奏效的。
未来新社交平台软件霸主将出自何方?我做过的一个“攀岩式项目”或显示出了些许端倪。
“项目通”奇葩需求的启发
那是在某集团公司的一次创新项目申报的活动中,我建议做一个基于微信进行项目沟通管理的小项目,叫“项目通”。本来只是想把集团公司众多的在建项目在项目微信群中传来传去的工程档案资料,保存到集团自己的服务器上可供查找。可集团的领导却提出了一个奇葩要求:要让我能根据他大脑中仅存的一些蛛丝马迹的记忆碎片,就能随时随地从“在建和已建的工程项目”的档案资料中,迅速准确地找出他要找的、曾经存在的某一份工程档案。
要用全文检索?搜索引擎?“对不起,”这位领导说:“我都试过百度、谷歌,关键字是不太可能被大概率记住的,你要假设,留下的碎片记忆是要找的文档的特殊内容和关键字的概率都非常低,这样,会导致查准率低到无法令人满意的程度,这可不行!”。
这个作业猛一听是有点难,这是一个多悬的崖啊!
难道我还能强过百度(B)、谷歌(G)?,哦,不,还要外加强过阿里(A)、腾讯(T),别忘了,要找的工程档案文件,可能还只是临时存在微信里呢!而阿里的钉钉,可正是最想颠覆微信的主,要是能做到,BGAT 不早就做出来了吗?但是,曾经都徒手攀过岩的我,还会害怕这个吗?
“蛛丝马迹的记忆碎片”让我自然联想起“外祖母神经元”的猜想:说是放学出校门的小朋友在众多接小孩的人群中,一眼就认出了来接自己的外祖母,这个事实背后的神经系统的构造和活动原理,是不是小朋友的大脑中早先已经建立的一个独立的“外祖母神经元”被激活了呢?
我知道对这个猜想的结果,可以说“不是”,也可以说“也是”。
说“不是”,是因为,神经系统不可能为每个事物单独生长出一个神经元来记忆,解剖学告诉我们,如果是的话,就需要大脑必须有超出实际体积的 N 多倍的空间,来容纳所需要的神经元的个数。
说“也是”,是因为,如果把大脑中每个神经元受到的激励大小当作是一个变量,那么,只需数量不多的“几个变量”的取值组合,就能产生极大数量的“多激励组合情况”。好比每个神经元代表一个“数轴”,多个神经元就组成了一个“多维空间”,那么,多维空间中的“点”的个数将会是无穷多的。“外祖母神经元”会不会就是其中的一个“点”呢?也就是说,是外祖母的形象正好赋予了小朋友大脑中的几个特定神经元各自一个特定量的激励,是以它们的激励量为“坐标”的组合,代表了那个“外祖母神经元”。
原来这就是知识图谱
回到我的任务,我不就是被要求用“蛛丝马迹的记忆碎片”的刺激,去激活出要搜索的文档这个“外祖母神经元”吗?于是,我想到一个方案:能不能自动根据这个片言只语展开“联想”?再尝试把联想得到的新词当关键字去做搜索或递进搜索?搜索结果可反过来启发搜索者寻找更准确的词汇联想路径,更准确的联想词汇又能搜出更精确的结果,这个正反馈是可能建立的,要是这个过程能自动完成,哪怕是经过简单几次交互就能完成的话,那么,最终搜索查准率的结果应该会比直接进行搜索好很多的。
怎么来建立词汇间的“联想”呢?不是说,全世界任何两个陌生人之间,最多通过六个熟人就能建立联络关系吗?如果我们能构建出一个所有词汇之间的“熟词”关系网,那么,要在任何两个“陌生词汇”之间建立关联,不是也可以通过少数几个词语的“熟词”关系,很快就能建立一条联络通道吗?
也就是说,假设关于这个集团所有工程文档的关键词,都包含到这个“熟词关系网”中了,那么,只要领导记住的片言只语也包含在这个网中,就可能通过少数几步的联想,找到所需搜索文档的关键词,如果说,领导要找的文件是“瓜”,那么“熟词关系网”就是“藤”,“顺藤摸瓜”的感觉就出来了。而“蛛丝马迹的记忆碎片”或许只是“藤”上的某一片叶子,或是叶子上的一条小虫子。
很好,现在来考究“熟词关系”是什么东西?
为什么两个词之间可以存在“熟词关系”?,因为,从一个词汇的含义可以联想到另一个词汇的含义。如果每个词汇的含义可称之为“语义”,那么,“熟词关系”,就表达了“语义关系”,熟词关系网,就是“语义关系网”。
再来看,就集团公司的工程项目档案所包含的所有词汇数据来说,经过“同义词合并”与“同词义的聚集”的神操作(以后你会明白的)而造出来的“语义关系网”,实际又会是什么东西呢?实际就是关于集团公司所有工程项目的情况描述、工程结构信息,建设者信息,施工过程信息、管理者信息,机器设备信息等等等等,一切关于工程项目的所有信息,以及这些信息之间的关系。
说这么多,简而言之,就是工程项目的知识。所以,要建的,就是这么一张所有集团公司工程信息,通过可联想的语义关系组成的,一个实际工程项目知识的关系网。
网的数学术语称为“图”。原来,这,就是知识图谱。
......
长话短说,终于,经过半年的努力,我带领一个5人团队完成了这个奇葩项目,这个“岩”我还是攀上去了。
回到本文,有哪位读者从项目通中,看出了颠覆目前社交平台的端倪了吗?
没看出来?恭喜您,您得到了继续跟随本教程学习的机会。
接下来,我会用“飞行预览”的方式,试着带领您用 Python 重新“攀登”一次这道岩,或许不用攀到最后,您就可以看出这个端倪了。
第02课:如何实现一个简单的语义网引擎?
最少可以做什么?
说白了,“项目通”只是在搜索引擎的基础上,附加了一个“语义网”,通过这个“语义网”做语义导航来进行关键字的筛选,然后再用选取的关键字集合来锁定目标文档。“语义网”在这里,只是起到了查找关键字的作用。
项目通同时还启发了我:如果将一个语义网中内聚程度较高的一个子网“打包”起来的话,得到的就是一个“知识块”,如果将语义网中所有的知识块都打包出来,语义网就变成了“知识图谱”,这说明语义网是知识图谱的底层实现。所以,要是能将这个“语义网”独立出来做成一个通用服务组件,用处一定会很大。
那么,如何来构建一个这样的“语义网”服务组件呢?
按照我的经验,如果想要做一个新玩意,第一步一定要尽可能地做小,只要保证符合我们心目中的用处,做的越小,越容易做好,结果就是:未来的组件内核就越牢靠,所以,“我们最少可以做什么?”就成了我的口头禅之一了。当然,你可以说,奥卡姆剃刀原理早就说明了这个道理,我不会在乎,我只在乎这个道理本身。
我也曾学习过人工智能教科书提到的语义网,但我只记得其中的这个结论——描述这个世界的所有的语句,最终都可以简化为这两种形式的语句的连接:“A 是 B 的一种”和“ X 是 Y 的一部分”。举例说就是,牛是动物的一种,牛头是牛的一部分。这个结论实际告诉我们的是:这个世界的所有事实都可以分解为上述两类“原子事实”。这提示我,最少要做的就是先描述事实,语义网,实际就是一个事实关系网。
从知识图谱的知识来说,其对“原子事实”的表述形式更为简单,就是“A 的 B 是 C”。举例说,牛的种类是动物,牛的前部是牛头,小明的年龄是12岁,……。我忽然“通灵”了一下,类似这样的结论,在图形学上也似曾相识:任何三维表面都可以简化表述成是 N 个三角形连成的一个网格。所以,我选择相信这一点——对这个世界的所有可描述的事实,最终从含义上来讲,都可以分解为形如这样的“原子事实”的组合:A 的 B 是 C。
就是它了,我们最少可以做一个“原子事实描述记录器”,专门用来记录形如“A 的 B 是 C”这样的原子事实描述(注意,我已经不给它加引号了,表示这个概念已经被我确认)。
普通程序员看到这里或许会觉得:So asy!,不就是一个三个字段的表吗?
呵呵,请先别着急。
如何在计算机里表示“语义”这种东西?
第一个问题出现了,请思考一下:我们要构建的是“描述关系网”,还是“语义关系网”?
有没有注意到:“描述”和“语义”的区别?
“描述”是由词汇连接而成的,说的更抽象一点,是图形符号串。而“语义”,则是词汇所表达的含义,不用严格思维都知道,二者是不同的概念。不用说,在计算机里,一个描述,就是一个字符串,那么,一个“语义”呢?
这个问题实际就是:如何在计算机里面表示“语义”这种东西?
这可不是个小问题,不信你去百度一下。
毋庸置疑,在计算机里表示任何事物,都是用数字的,所以,对语义这种东西也不例外,在计算机里,一个语义,必定是一个数字,而且每个语义,都有一个特定的数字对应。
问题是:如何在“表示语义的数字”和“描述语义的字符串”之间建立联系呢?
一个词语可能有多个含义;而一个含义又可能用多个词语来表达。
以上是语言应用上的基本事实,也就是存在“多义词”和“同义词”的事实。这两个基本事实说明了“描述”和“语义”这两类事物之间的关系。
所以,答案竟如此精确而简单:
给一组同义词建立一个数字标识,这个数字标识,就是一个“语义”。
“语义三角形网格”长啥样?
有了对语义的精确表达的定义,一个最简单的语义网就就可以写成这个样子:
A 的 B 是 C,D 的 A 是 E,B 的 F 是 G,E 的 C 是 H,G 的 H 是 I……
画成图,就是这样子的:
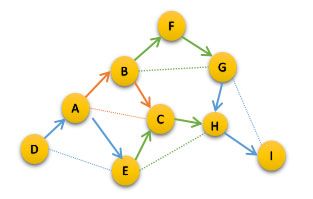
像不像描述三维曲面的三角形网格?真像!对应的语义网事实就是:对于任何的事物的描述(任何的知识),都可以用一个“语义三角形网格”来逼近。
其中的任何一个带字母的结点,代表的是一个唯一的同义词集合,也就是一个“语义网结点”,整张图,就是所谓的“同义词合并”构成的“语义网”。
在这个语义网中,一个词汇可能同时存在于多个结点之中,这意味着:语义网结点之间,除了存在显式的语义连接关系之外,还存在隐含的“多义词近邻关系”。也就是说,有多义词出现的多个语义结点之间的“语义距离”是相对较近的,在语义网中,它们应该聚集在相互接近的区域内,这就是所谓的“同词义聚集”的神操作。
这样的一个语义网,既可以用来进行词汇联想,又可以用来进行语义联想。
为啥这是本次攀岩的顶峰?
这个语义网成功地将语义从语言中形式化地剥离出来了,清晰而准确地描绘出了在“语言的世界”这个外壳下,浓缩的“语义的世界”。这两个世界是以“同义词”为“虫洞”来相互沟通的平行世界。在语言的世界里,符号关系是显在的,而语义关系是隐含的;而在“语义世界”里,则正好相反。人们日常的沟通,只能通过在语言世界交流,来达到彼此在语义世界的同步,即所谓“心有灵犀”,而苦于语义世界的隐藏不可见,导致“一点通”来之不易。关于沟通的理论告诉我们,此乃沟通的头号障碍。
关键是:这两个平行世界,现在可以精准地在计算机中实现了!
这意味着,人们之间的沟通难以从语言世界穿透到语义世界的困难,可以用电脑来帮助解决。借助电脑,人们可以将各自的“语义世界”同步展现出来,每个人内心的语义世界从此可以显式地相互透明,从而易于融合,易于最终达成一致!
这个,就是我的这次“攀岩”活动希望到达的顶峰。
就让我们立即着手准备攀登!
设计一个最简单的语义网
第一步,我们要在电脑中,构建这样一个最简单的语义网。

我们暂且抛开语义结点内的同义词集合,仅考虑如何构建这样的一个网络结构。
如果把形如“A 的 B 是 C”这样的三元语义关系称为一个“语义事实”,把“A”,“B”,“C”称为“语义原子”,那么,语义网的对象模型就是这样的:
- 一个语义事实包含三个语义原子;
- 一个语义原子可参与陈述一到多个语义事实;
- 一个语义原子可能出现在一个语义事实陈述的三个序位中的一个上。
如果用一个整数代表一个语义原子,那么,一个语义事实就是3个整数组成的一个链表,整个语义网,就是多个链表的集合。
对这样超级简单的对象模型编程,简直就是小菜一碟,毫无挑战性可言。
为了加大挑战,我决定这次采用我比较陌生的 Python 来写它,背后的原因,是我隐约可以感觉到,这个项目未来会是一个大数据的应用,而 Python 在这方面的优势,自然给了我强大的吸引力。
从下篇开始,你会看到一开始的身轻如燕,预示着可能到最后的绝境难生。
第03课:怎么用 Python 来做?
第04课:用 Python 实现语义原子
第05课:用 Python 实现语义分子
第06课:用 Python 实现语义细胞
第07课:用 Python 实现语义小生命
第08课:语义对象池的实现
第09课:测试语义网服务器小生命
第10课:接下来可以怎么做?
阅读全文: http://gitbook.cn/gitchat/column/5b4445fb88bf540ab6007339