Deeplearning4j 快速入门
课程亮点
- 机器学习经典案例基于 DL4J 的实现
- Spark 分布式场景下的模型训练及调优
- 多 GPU 环境下的并行建模
- 迁移和强化学习的模型训练
- 搭建在线服务环境实战演练
本课程是关于 Eclipse Deeplearning4j 的基础课程。Deeplearning4j 是基于 Java/JVM 的深度学习开源库,课程内容涵盖了 Deeplearning4j 生态圈中核心框架的使用(如 ND4J/DataVec/RL4J),介绍了深度神经网络在 CV/NLP 领域的建模、训练、部署、上线一站式开发流程,以及单机/并行/分布式(Apache Spark)场景下的模型训练过程,异构计算框架(CPU+GPU)硬件架构下的加速优化步骤等内容。
大咖推荐
作为最早一批加入到开源平台社区的技术人员,万老师也是在社区对 Deeplearning4j 最有经验的人之一,期间他也很努力地帮助其他社区的人。课程内容涵盖全面,完全满足入门级学员们对于 Deeplearning4j 的学习需求。
——吴书卫博士,Skymind 大中华区负责人&CTO
作者介绍
万宫玺,苏宁易购高级算法工程师。现任职于苏宁易购搜索研发中心,对机器学习/深度学习在自然语言处理、机器视觉等领域的应用开发有着丰富的经验,先后参与部门反作弊系统、智能问答机器人、Query 语义挖掘与分析系统等机器学习项目的开发。
课程大纲
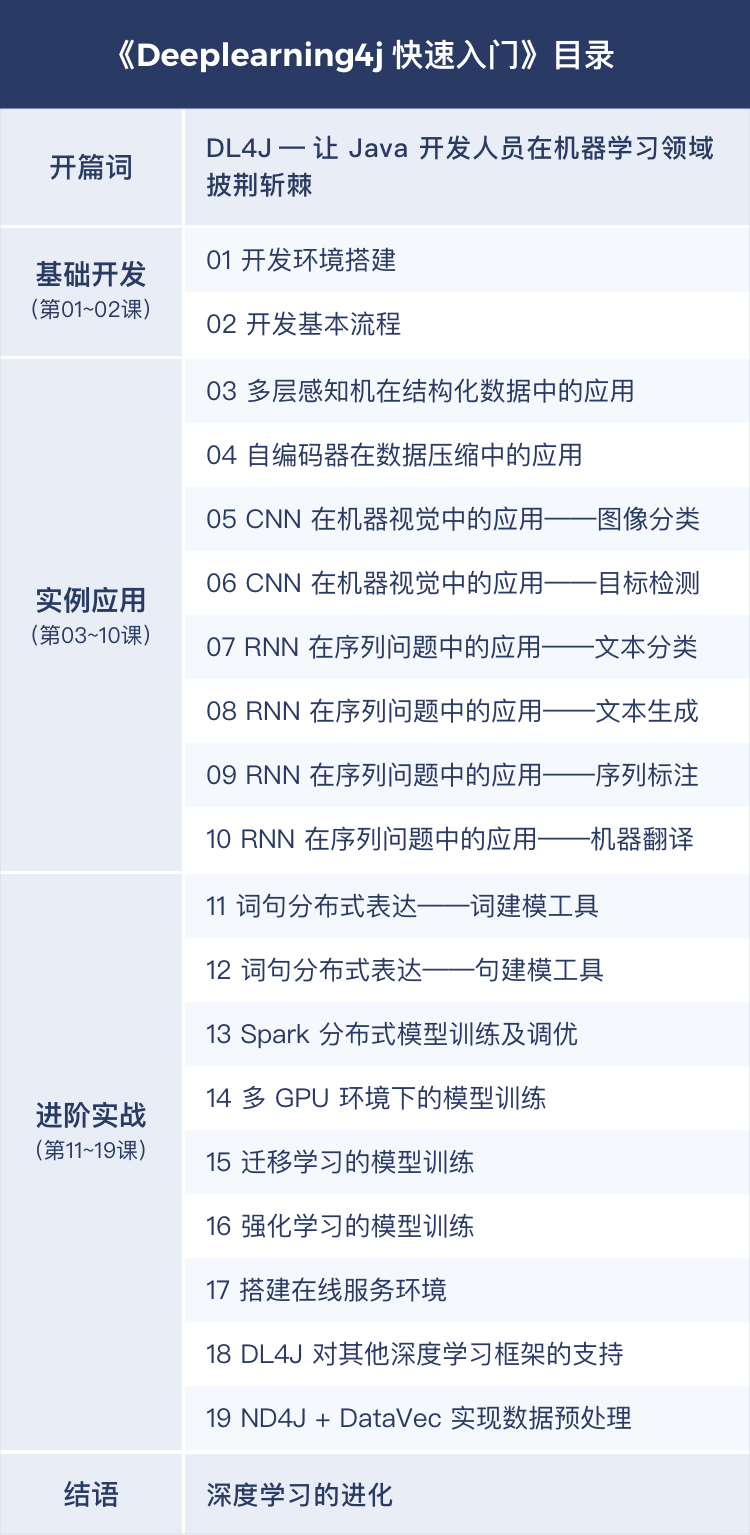
* 实际更新文章题目可能与框架略有出入
适宜人群
- 对 Deeplearning4j 入门感兴趣的初学者
- 希望转型 AI 开发的 Java 工程师
- 有科学计算背景的高校/企业工作人员
课程内容
推荐序:《Deeplearning4j 快速入门》课程,深度学习必备秘籍
从 1956 年 Dartmouth 学会上提出的“人工智能”一词,到时下火热的人脸识别技术、车牌识别技术、智能语音应答,再到未来汽车发展趋势的自动驾驶技术,“人工智能”已然成为了科技未来的发展大势。对于广大 IT 行业从业人员而言,单纯地掌握 Java 等软件编程技术是远远不够的,学习 Deeplearning4j 技术就成为了进军“人工智能”行业的敲门砖。作为 Skymind 在亚洲的 CTO,我要为广大对 Deeplearning4j 入门感兴趣的初学者、希望转型 AI 开发的 Java 工程师、有科学计算背景的高校/企业工作人员推荐一门名为《Deeplearning4j 快速入门》的课程。
推荐理由之授课教师
担任本次课程的主讲老师是苏宁易购高级算法工程师的万宫玺工程师,现任职于苏宁易购搜索研发中心,对机器学习/深度学习在自然语言处理、机器视觉等领域的应用开发有着丰富的经验,先后参与部门反作弊系统、智能问答机器人、Query 语义挖掘与分析系统等机器学习项目的开发。过硬的技术能力水平,让万老师在授课的过程中能够深入浅出的将 Deeplearning4j 的理论呈现给学员。此外,因为万老师拥有多年的行业从业经验,所以在实践方面的授课中可以让学员进一步了解 Deeplearning4j 的具体应用技巧。此外,作为最早一批加入到开源平台社区的技术人员,万老师也是在社区对 Deeplearning4j 最有经验的人之一,期间他也很努力地帮助其他社区的人。
推荐理由之课程涵盖的具体内容及课程亮点
课程内容涵盖全面,完全满足入门级学员们对于 Deeplearning4j 的学习需求。
《Deeplearning4j 快速入门》课程是关于 Eclipse Deeplearning4j 的基础课程。而课程内容中的 Deeplearning4j 是基于 Java/JVM 的深度学习开源库,课程内容涵盖了 Deeplearning4j 生态圈中核心框架的使用(如 ND4J/DataVec/RL4J),用浅显易懂的授课言语介绍了深度神经网络在 CV/NLP 领域的建模、训练、部署、上线一站式开发流程,以及单机/并行/分布式(Apache Spark)场景下的模型训练过程,异构计算框架(CPU+GPU)硬件架构下的加速优化步骤等内容,让学员们在学习的过程中感受到知识的由浅入深,技术能力的不断提高。课程的最大亮点包含以下几个方面:
- 机器学习经典案例基于 DL4J 的实现
- Spark 分布式场景下的模型训练及调优
- 多 GPU 环境下的并行建模
- 迁移和强化学习的模型训练
- 搭建在线服务环境实战演练
推荐理由之耐心细致的引导
众所周知,学习 Deeplearning4j 的过程中会不可避免地接触并学习数学和编程概念,而对于对这方面比较头痛的学员也大可放心,万宫玺老师在讲解的过程中采用了循序渐进的讲解过程,从授课伊始便能保证学员们可以对数学与代码一直保持着极高的学习热情。
推荐理由之获得更多收获
学习本门课程不仅可以让广大学员们掌握对 Deeplearning4j 基本理论及技术的应用,更可以在实际操作过程中获得顺利完成的满足感,以此刺激大脑中的多巴胺的分泌。
结语
学习是一门修行,而学习 Deeplearning4j 技术可谓是一场苦行,但有了万宫玺老师主讲的《Deeplearning4j 快速入门》课程,就可以让学员们不再畏惧 Deeplearning4j 中晦涩难懂的知识及术语,更可以让我们在之后从事的“人工智能”工作呈现出“长风破浪会有时”的气魄!
开篇词:DL4J——让 Java 开发人员在机器学习领域披荆斩棘
随着深度学习在语音、图像、自然语言等领域取得了广泛的成功,越来越多的企业、高校和科研单位开始投入大量的资源研发 AI 项目。同时,为了方便广大研发人员快速开发深度学习应用,专注于算法应用本身,避免重复造轮子的问题,各大科技公司先后开源了各自的深度学习框架,例如:TensorFlow(Google)、Torch/PyTorch(Facebook)、Caffe(BVLC)、CNTK(Microsoft)、PaddlePaddle(百度)等。
以上框架基本都是基于 Python 或者 C/C++ 开发的。而且很多基于 Python 的科学计算库,如 NumPy、Pandas 等都可以直接参与数据的建模,非常快捷高效。
然而,对于很多 IT 企业及政府网站,大量的应用都依赖于 Java 生态圈中的开源项目,如 Spring/Structs/Hibernate、Lucene、Elasticsearch、Neo4j 等。主流的分布式计算框架,如 Hadoop、Spark 都运行在 JVM 之上,很多海量数据的存储也基于 Hive、HDFS、HBase 这些存储介质,这是一个不容忽视的事实。
有鉴于此,如果有可以跑在 JVM 上的深度学习框架,那么不光可以方便更多的 Java/JVM 工程师参与到人工智能的浪潮中,更重要的是可以与企业已有的 Java 技术无缝衔接。无论是 Java EE 系统,还是分布式计算框架,都可以与深度学习技术高度集成。Deeplearning4j 正是具备这些特点的深度学习框架。
Deeplearning4j 是什么
Deeplearning4j 是由美国 AI 创业公司 Skymind 开源并维护的一个基于 Java/JVM 的深度学习框架。同时也是在 Apache Spark 平台上为数不多的,可以原生态支持分布式模型训练的框架之一。此外,Deeplearning4j 还支持多 GPU/GPU 集群,可以与高性能异构计算框架无缝衔接,从而进一步提升运算性能。在 2017 年下半年,Deeplearning4j 正式被 Eclipse 社区接收,同 Java EE 一道成为 Eclipse 社区的一员。
另外,就在今年的 4 月 7 号,Deeplearning4j 发布了最新版本 1.0.0-alpha,该版本的正式发布不仅提供了一系列新功能和模型结构,也意味着整个 Deeplearning4j 项目的趋于稳定和完善。
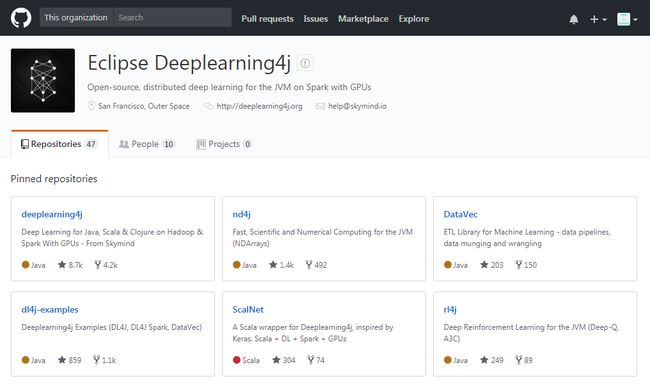
Deeplearning4j 提供了对经典神经网络结构的支持,例如:
- 多层感知机/全连接网络(MLP)
- 受限玻尔兹曼机(RBM)
- 卷积神经网络(CNN)及相关操作,如池化(Pooling)、解卷积(Deconvolution)、空洞卷积(Dilated/Atrous Convolution)等
- 循环神经网络(RNN)及其变种,如长短时记忆网络(LSTM)、双向 LSTM(Bi-LSTM)等
- 词/句的分布式表达,如 word2vec/GloVe/doc2vec 等
在最新的 1.0.0-alpha 版本中,Deeplearning4j 在开始支持自动微分机制的同时,也提供了对 TensorFlow 模型的导入,因此在新版本的 Deeplearning4j 中可以支持的网络结构将不再局限于自身框架。
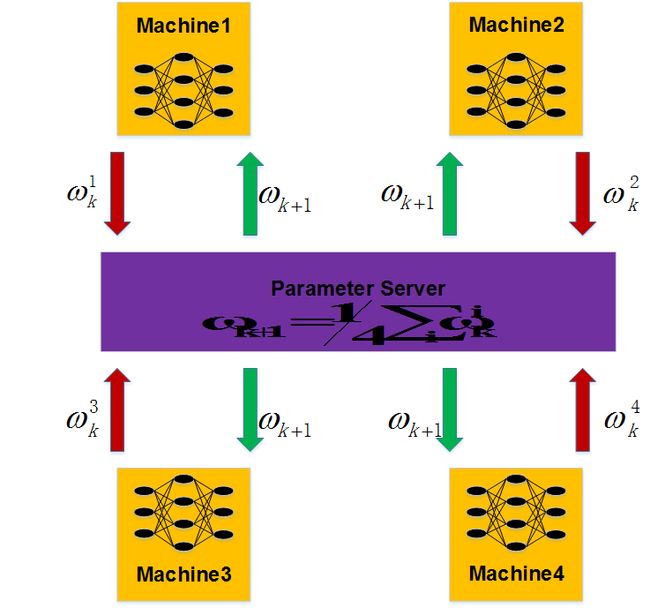
DeepLerning4j 基于数据并行化理论,对分布式建模提供了支持(准确来说是基于参数同步机制的数据并行化,并在 0.9.0 版本后新增了 Gradients Sharing 的机制)。需要注意的是,Deeplearning4j 并没有创建自己的分布式通信框架,对于 CPU/GPU 集群的分布式建模仍然需要依赖 Apache Spark。在早期的版本中,Deeplearning4j 同样支持基于 MapReduce 的 Hadoop,但由于其在模型训练期间 Shuffle 等因素导致的迭代效率低下,加上 Spark 基于内存的数据存储模型的高效性,使得其在最近版本中已经停止了对 Hadoop 的支持。
此外,Apache 基金会下另一个分布式计算的顶级项目 Flink 正在积极考虑将 Deeplearning4j 进行集成,详见这里。
Deeplearning4j 生态圈中除了深度神经网络这个核心框架以外,还包括像 DataVec、ND4J、RL4J 等一些非常实用的子项目,下面就对这些子项目的主要功能模块做下介绍。
1. ND4J & LibND4J
这两个子项目是 Deeplearning4j 所依赖的张量运算框架。其中,ND4J 提供上层张量运算的各种接口,而 LibND4J 用于适配底层基于 C++/Fortran 的张量运算库,如 OpenBLAS、MKL 等。
2. DataVec
这是数据预处理的框架,该框架提供对一些典型非结构化数据(语音、图像、文本)的读取和预处理(归一化、正则化等特征工程常用的处理方法)。此外,对于一些常用的数据格式,如 JSON/XML/MAT(MATLAB 数据格式)/LIBSVM 也都提供了直接或间接的支持。
3. RL4J
这是基于 Java/JVM 的深度强化学习框架,它提供了对大部分基于 Value-Based 强化学习算法的支持,具体有:Deep Q-leaning/Dual DQN、A3C、Async NStepQLearning。
4. dl4j-examples
这是 Deeplearning4j 核心功能的一些常见使用案例,包括经典神经网络结构的一些单机版本的应用,与 Apache Spark 结合的分布式建模的例子,基于 GPU 的模型训练的案例以及自定义损失函数、激活函数等方便开发者需求的例子。
5. dl4j-model-z
顾名思义这个框架实现了一些常用的网络结构,例如:
- ImageNet 比赛中获奖的一些网络结构 AlexNet/GoogLeNet/VGG/ResNet;
- 人脸识别的一些网络结构 FaceNet/DeepFace;
- 目标检测的网络结构 Tiny YOLO/YOLO9000。
在最近 Release 的一些版本中,dl4j-model-z 已经不再作为单独的项目,而是被纳入 Deeplearning4j 核心框架中,成为其中一个模块。
6. ScalNet
这是 Deeplearning4j 的 Scala 版本,主要是对神经网络框架部分基于 Scala 语言的封装。
对这些生态圈中子项目的使用案例,我会在后续的文章中详细地介绍,在这里就不赘述了。
为什么要学习 Deeplearning4j
在引言中我们谈到,目前开源的深度学习框架有很多,那么选择一个适合工程师自己、同时也可以达到团队业务要求的框架就非常重要了。在这个部分中,我们将从计算速度、接口设计与学习成本,和其他开源库的兼容性等几个方面,给出 Deeplearning4j 这个开源框架的特点及使用场景。
ND4J 加速张量运算
JVM 的执行速度一直为人所诟病。虽然 Hotspot 机制可以将一些对运行效率有影响的代码编译成 Native Code,从而在一定程度上加速 Java 程序的执行速度,但毕竟无法优化所有的逻辑。另外,Garbage Collector(GC)在帮助程序员管理内存的同时,其实也束缚了程序员的手脚,毕竟是否需要垃圾回收并不是程序员说了算;而在其他语言如 C/C++ 中,我们可以 free 掉内存块。
对于机器学习/深度学习来说,优化迭代的过程往往非常耗时,也非常耗资源,因此尽可能地加速迭代过程十分重要。运算速度也往往成为评价一个开源库质量高低的指标之一。鉴于 JVM 自身的局限性,Deeplearning4j 的张量运算通过 ND4J 在堆外内存(Off-Heap Memory/Direct Memory)上进行, 详见这里。大量的张量运算可以依赖底层的 BLAS 库(如 OpenBLAS、Intel MKL),如果用 GPU 的话,则会依赖 CUDA/cuBLAS。由于这些 BLAS 库多数由 Fortran 或 C/C++ 写成,且经过了细致地优化,因此可以大大提高张量运算的速度。对于这些张量对象,在堆上内存(On-Heap Memory)仅存储一个指针/引用对象,这样的处理也大大减少了堆上内存的使用。
High-Level 的接口设计
对于大多数开发者而言,开源库的学习成本是一个不可回避的问题。如果一个开源库可以拥有友好的接口、详细的文档和案例,那么无疑是容易受人青睐的。这一点对于初学者或者致力于转型 AI 的工程师尤为重要。
神经网络不同于其他传统模型,其结构与复杂度变化很多。虽然在大多数场景下,我们会参考经典的网络结构,如 GoogLeNet、ResNet 等。但自定义的部分也会很多,往往和业务场景结合得更紧密。为了使工程师可以快速建模,专注于业务本身和调优,Deeplearning4j 对常见的神经网络结构做了高度封装。以下是声明卷积层 + 池化层的代码示例,以及和 Keras 的对比。
Keras 版本
model = Sequential()model.add(Convolution2D(nb_filters, (kernel_size[0], kernel_size[1]))) #卷积层 model.add(Activation('relu')) #非线性变换 model.add(MaxPooling2D(pool_size=pool_size)) #池化层 Deeplearning4j 版本
MultiLayerConfiguration conf = new NeuralNetConfiguration.Builder()//....layer(0, new ConvolutionLayer.Builder(5, 5) //卷积层 .nIn(nChannels) .stride(1, 1) .nOut(20) .activation(Activation.RELU) //非线性激活函数 .build()).layer(1, new SubsamplingLayer.Builder(PoolingType.MAX) //最大池化 .kernelSize(2,2) .stride(2,2) .build())可以看到,Deeplearning4j 和 Keras 很相似,都是以 Layer 为基本模块进行建模,这样的方式相对基于 OP 的建模方式更加简洁和清晰。所有的模块都做成可插拔的,非常灵活。以 Layer 为单位进行建模,使得模型的整个结构高度层次化,对于刚接触深度神经网络的开发人员,可以说是一目了然。除了卷积、池化等基本操作,激活函数、参数初始化分布、学习率、正则化项、Dropout 等 trick,都可以在配置 Layer 的时候进行声明并按需要组合。
当然基于 Layer 进行建模也有一些缺点,比如当用户需要自定义 Layer、激活函数等场景时,就需要自己继承相关的基类并实现相应的方法。不过这些在官网的例子中已经有一些参考的 Demo,如果确实需要,开发人员可以参考相关的例子进行设计,详见这里。
此外,将程序移植到 GPU 或并行计算上的操作也非常简单。如果用户需要在 GPU 上加速建模的过程,只需要加入以下逻辑声明 CUDA 的环境实例即可。
CUDA 实例声明
CudaEnvironment.getInstance().getConfiguration() .allowMultiGPU(true) .setMaximumDeviceCache(10L * 1024L * 1024L * 1024L) .allowCrossDeviceAccess(true);ND4J 的后台检测程序会自动检测声明的运算后台,如果没有声明 CUDA 的环境实例,则会默认选择 CPU 进行计算。
如果用户需要在 CPU/GPU 上进行并行计算,则只需要声明参数服务器的实例,配置一些必要参数即可。整体的和单机版的代码基本相同。
参数服务器声明
ParallelWrapper wrapper = new ParallelWrapper.Builder(model) .prefetchBuffer(24) .workers(8) .averagingFrequency(3) .reportScoreAfterAveraging(true) .useLegacyAveraging(true) .build();参数服务器的相关参数配置在后续的课程中会有介绍,这里就不再详细说明了。
友好的可视化页面
为了方便研发人员直观地了解神经网络的结构以及训练过程中参数的变化,Deeplearning4j 提供了可视化页面来辅助开发。需要注意的是,如果需要使用 Deeplearning4j 的可视化功能,需要 JDK 1.8 以上的支持,同时要添加相应的依赖:
org.deeplearning4j deeplearning4j-ui_${scala.binary.version} ${dl4j.version} 并且在代码中添加以下逻辑:
//添加可视化页面监听器UIServer uiServer = UIServer.getInstance();StatsStorage statsStorage = new InMemoryStatsStorage();uiServer.attach(statsStorage);model.setListeners(new StatsListener(statsStorage));训练开始后,在浏览器中访问本地 9000 端口,默认会跳转到 Overview 的概览页面。我们可以依次选择查看网络结构的页面(Model 页面)和系统页面(System),从而查看当前训练的模型以及系统资源的使用情况。详情见下图:


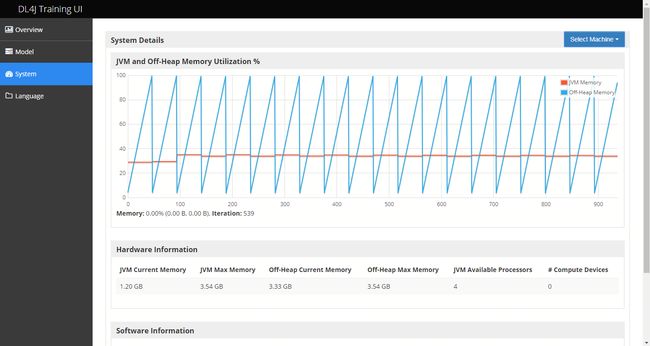
Overview 页面主要会记录模型在迭代过程中 Loss 收敛的情况,以及记录参数和梯度的变化情况。根据这些信息,我们可以判断模型是否在正常地学习。从 Model 页面,我们则可以直观地看到目前网络的结构,比如像图中有 2 个卷积层 + 2 个池化层 + 1 个全连接层。而在 System 页面中我们可以看到内存的使用情况,包括堆上内存和堆外内存。
Deeplearning4j 提供的训练可视化页面除了可以直观地看到当前模型的训练状态,也可以基于这些信息进行模型的调优,具体的方法在后续课程中我们会单独进行说明。
兼容其他开源框架
正如在引言中提到的,现在深度神经网络的开源库非常多,每个框架都有自己相对擅长的结构,而且对于开发人员,熟悉的框架也不一定都相同。因此如果能做到兼容其他框架,那么无疑会提供更多的解决方案。
Deeplearning4j 支持导入 Keras 的模型(在目前的 1.0.0-alpha 版本中,同时支持 Keras 1.x/2.x)以及 TensorFlow 的模型。由于 Keras 自身可以选择 TensorFlow、Theano、CNTK 作为计算后台,再加上第三方库支持导入 Caffe 的模型到 Keras,因此 Keras 已经可以作为一个“胶水”框架,成为 Deeplearning4j 兼容其他框架的一个接口。

兼容其他框架(准确来说是支持导入其他框架的模型)的好处有很多,比如说:
- 扩展 Model Zoo 中支持的模型结构,跟踪最新的成果;
- 离线训练和在线预测的开发工作可以独立于框架进行,减少团队间工作的耦合。
Java 生态圈助力应用的落地
Deeplearning4j 是跑在 JVM 上的深度学习框架,源码主要是由 Java 写成,这样设计的直接好处是,可以借助庞大的 Java 生态圈,加快各种应用的开发和落地。Java 生态圈无论是在 Web 应用开发,还是大数据存储和计算都有着企业级应用的开源项目,例如我们熟知的 SSH 框架、Hadoop 生态圈等。
Deeplearning4j 可以和这些项目进行有机结合,无论是在分布式框架上(Apache Spark/Flink)进行深度学习的建模,还是基于 SSH 框架的模型上线以及在线预测,都可以非常方便地将应用落地。下面这两张图就是 Deeplearning4j + Tomcat + JSP 做的一个简单的在线图片分类的应用。


总结来说,至少有以下 4 种场景可以考虑使用 Deeplearning4j:
- 如果你身边的系统多数基于 JVM,那么 Deeplearning4j 是你的一个选择;
- 如果你需要在 Spark 上进行分布式深度神经网络的训练,那么 Deeplearning4j 可以帮你做到;
- 如果你需要在多 GPU/GPU 集群上加快建模速度,那么 Deeplearning4j 也同样可以支持;
- 如果你需要在 Android 移动端加入 AI 技术,那么 Deeplearning4j 可能是你最方便的选择之一。
以上四点,不仅仅是 Deeplearning4j 自身的特性,也是一些 AI 工程师选择它的理由。
虽然 Deeplearning4j 并不是 GitHub 上 Fork 或者 Star 最多的深度学习框架,但这并不妨碍其成为 AI 工程师的一种选择。就 Skymind 官方发布的信息看,在美国有像 IBM、埃森哲、NASA 喷气推进实验室等多家明星企业和实验机构,在使用 Deeplearning4j 或者其生态圈中的项目,如 ND4J。算法团队结合自身的实际情况选择合适的框架,在多数时候可以做到事半功倍。
Deeplearning4j 的最新进展
在这里,我们主要介绍下 Deeplearning4j 最新的一些进展情况。
版本
目前 Deeplearning4j 已经来到了 1.0.0-beta3 的阶段,马上也要发布正式的 1.0.0 版本。本课程我们主要围绕 0.8.0 和 1.0.0-alpha 展开(1.0.0-beta3 核心功能部分升级不大),这里罗列下从 0.7.0 版本到 1.0.0-alpha 版本主要新增的几个功能点:
- Spark 2.x 的支持(>0.8.0)
- 支持迁移学习(>0.8.0)
- 内存优化策略 Workspace 的引入(>0.9.0)
- 增加基于梯度共享(Gradients Sharing)策略的并行化训练方式(>0.9.0)
- LSTM 结构增加 cuDNN 的支持(>0.9.0)
- 自动微分机制的支持,并支持导入 TensorFlow 模型(>1.0.0-alpha)
- YOLO9000 模型的支持(>1.0.0-aplpha)
- CUDA 9.0 的支持(>1.0.0-aplpha)
- Keras 2.x 模型导入的支持(>1.0.0-alpha)
- 增加卷积、池化等操作的 3D 版本(>1.0.0-beta)
除此之外,在已经提及的 Issue 上,已经考虑在 1.0.0 正式版本中增加对 YOLOv3、GAN、MobileNet、ShiftNet 等成果的支持,进一步丰富 Model Zoo 的直接支持范围,满足更多开发者的需求。详见 GAN、MobileNet、YOLOv3、ShiftNet。
进一步的进展情况,可以直接跟进每次的 releasenotes,查看官方公布的新特性和已经修复的 Bug 情况。
社区
Deeplearning4j 社区目前正在进一步建设和完善中,在社区官网上除了介绍 Deeplearning4j 的基本信息以外,还提供了大量有关神经网络理论的资料,方便相关研发人员的入门与进阶。Deeplearning4j 社区在 Gitter 上同时开通了英文/中文/日文/韩文频道,开发人员可以和核心源码提交者进行快速的交流以及获取最新的信息。

- Deeplearning4j 的 GitHub 地址,详见这里;
- Deeplearning4j 社区官网,详见这里;
- Deeplearning4j 英文 Gitter Channel,详见这里;
- Deeplearning4j 中文 Gitter Channel,详见这里;
- Deeplearning4j 官方 QQ 群,289058486。
关于本课程
最后我们简单介绍一下本课程涉及的内容以及一些学习建议。
本课程主要面向深度学习/深度神经网络的企业研发人员、高校以及研究机构的研究人员。同时,对于致力于转型 AI 开发的 Java 工程师也会有很大的帮助。对于那些希望构建基于 JVM 上的 AI 项目的研发人员也有着一定的参考价值。
本课程会围绕 Deeplearning4j 框架,并结合深度学习在图像、语音、自然语言处理等领域的一些经典案例(如图像的分类、压缩、主体检测,文本分类、序列标注等),给出基于 Deeplearning4j 的解决方案。此外,对于具体的实例,我们将分别介绍建模的步骤及模型的部署上线这一全栈开发的流程。我们会结合 Deeplearning4j 的一些特性,分别介绍在单机、多 CPU/GPU、CPU/GPU 集群上进行建模的步骤,以及如何与 Java Web 项目进行整合实现 AI 应用的落地。
本课程力求做到对 Deeplearning4j 及其生态圈进行详细的介绍,包括对 Deeplearning4j 现在已经支持的迁移学习(Transfer Learning)和强化学习(Reinforcement Learning)进行实例应用的介绍。同时希望通过本课程帮助真正有需要的研发人员落地 AI 项目或者提供一种可行的解决方案,尽量做到内容覆盖的全面性和语言的通俗易懂。
此外,我们给出一些学习本课程的建议:在学习本课程前,希望学员有一定的 Java 工程基础,以及对机器学习/深度学习理论的了解。如果对优化理论、微分学、概率统计有一定的认识,那么对理解神经网络的基础理论(如 BP 算法)将大有裨益。
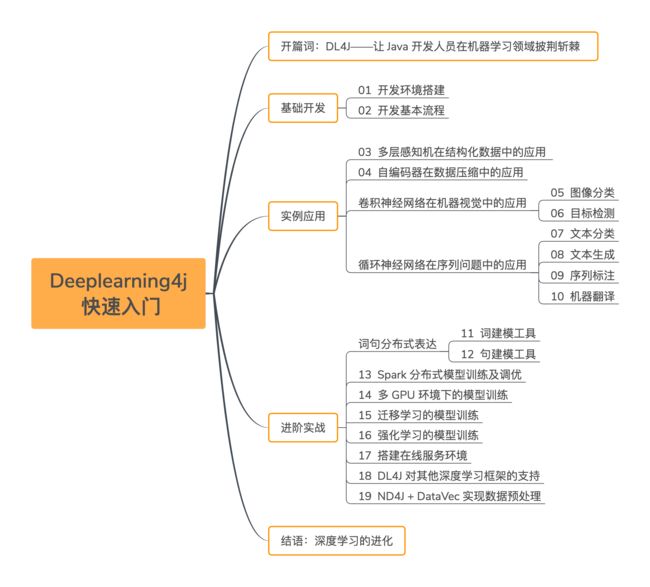
最后,下面是本课程的大纲思维导图,方便大家参考学习。顺带跟大家说一声,购买课程的读者可以加入我们成立的 DL4J 课程微信交流群,我会抽出时间,不定期回复读者的疑问。预祝大家快速上手 DL4J 开发!
第05课:CNN 在机器视觉中的应用——图像分类
从本节课开始,我们将陆续为大家介绍在工业界使用较多的几种神经网络结构。首先介绍的是卷积神经网络(Convolution Neural Network,CNN)。本节课核心内容包括:
- 卷积神经网络发展历史回顾
- 卷积与池化
- 卷积神经网络的应用(图像分类)
卷积一词来源于信号处理领域。以 1D 信号为例,$f(x)$ 和 $g(x)$ 分别代表两个信号源输出的信号,则 $f(x)$ 和 $g(x)$ 的卷积可以表示为:

卷积的数学含义可以认为是两个函数重叠部分的面积(其中一个函数需要做反褶操作)。现实生活中很多信号也可以认为是两个信号卷积的结果,例如:
回声就可以认为是声源发出的信号与反射信号的卷积。
在实际应用中,卷积/解卷积操作可用于信号的平滑、滤波等场景,而这次介绍的卷积神经网络也同样基于卷积操作。在介绍卷积神经网络的细节之前,我们先回顾下它的发展历史。
5.1 卷积神经网络发展历史回顾
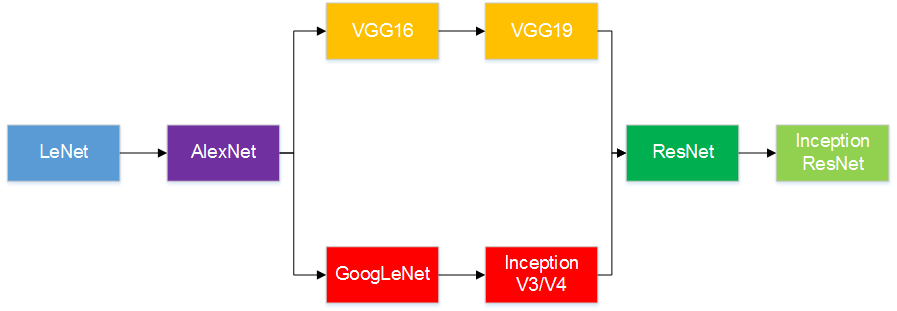
现在卷积神经网络具有代表性的工作,可以追溯到 20 世纪 90 年代 Yann LeCun 提出的 LeNet-5。事实上,后期的 AlexNet、VGG 系列、GoogLeNet 等卷积网络结构,都或多或少地借鉴了 LeCun 的工作,只不过网络的整体结构变得更深更广,或者与其他神经网络结构(如 RNN)结合使用。
LeNet-5 的结构示意图如下:
 图片来源:Gradient-Based Learning Applied to Document Recognition (Proc. IEEE 1998),论文下载链接
图片来源:Gradient-Based Learning Applied to Document Recognition (Proc. IEEE 1998),论文下载链接
LeNet-5 受限于当时硬件的计算能力,对于小规模的机器视觉问题,如 MNIST 分类问题,可以达到很高的准确率,但对于更大型的问题则显得力不从心。这一局面直到 2012 年 Hinton 以及他的学生 Alex Krizhesky 凭借 AlexNet 夺得 ImageNet 比赛冠军后才被打破。自此,卷积神经网络甚至整个神经网络领域再度受到工业界和学术界的关注,深度神经网络以及深度学习的概念也逐渐被大家所知晓。
AlexNet 其实是一种更为深刻的 LeNet。此外非线性变换函数、防止过拟合的 Dropout 等 trick 也都在后来深度学习的发展中扮演着重要的角色。此后,卷积神经网络沿着更深更广的趋势继续发展。下面是一个简单的发展历程图:
接着,我们介绍下在卷积神经网络中常见的卷积、池化操作的一些细节。
5.2 卷积与池化
在卷积神经网络中,卷积操作的目的是用于提取局部特征。参与卷积操作的信号是两个矩阵,其中一个是人为设置大小的(例如 3x3、5x5)通常被称作是卷积核或者滤波器的矩阵,另一个则是图像原始输入的像素矩阵,或上一轮卷积操作后输出的 Feature Map。我们结合 Standford 机器学习课程中关于卷积神经网络的一个动态 Demo 来直观了解下卷积的过程。下图的源地址:https://cs231n.github.io/assets/conv-demo/index.html。

截图中左侧第一列的三个矩阵可以认为是图片的 R、G、B 三个通道。原始的像素矩阵其实是 5x5 的大小。由于使用的卷积核尺寸是 3x3,并且卷积核在像素矩阵上每次移动 2 个像素,因此需要在外围补充一些像素点,也就是灰色且像素值都是 0 的那些点。截图的例子中选取了两个卷积核,因此输出的 Feature Map(图中最右侧的绿色的矩阵)也是两个。每个卷积核其实是一个 3x3x3 的三维张量,每个 3x3 的切面则用于在原始三个通道的像素矩阵中提取一些特征。当然,每个切面内部的值是可以不同的。
卷积核从像素矩阵最左上角的像素点开始进行自左向右、自上而下的滑动(例子中滑动过 2 个像素点)。在滑动的过程中,对应位置的矩阵中的值相乘(Hadmard 乘积)并线性叠加。
需要注意的是,卷积核并不需要做像刚才介绍的一维信号那样的反褶操作(其实反褶操作可以通过初始化不同的矩阵元素的值来实现,效果是一样的)。
卷积操作结束后,我们可以将输出的 Feature Map 通过非线性激活函数来获取非线性特征。我们将经过非线性处理后的结果称为 Activation Map。
在获取 Activation Map 之后,我们可以选择添加一次池化或者说下采样的操作(注意:池化操作不是必须,连续卷积操作也是可以的)。池化操作有一些具体的选择,比如说最大池化、平均池化等。我们同样以 Standford 课程中的示例图为例,解释下最大池化的概念。下图的源地址:https://cs231n.github.io/convolutional-networks/

在池化操作中,我们同样需要类似卷积核或者说滤波器的介入。只不过滤波器在这里的作用并不是做 Hadmard 乘积,而是在过滤的像素区域内根据一定的规则(如最大数值、加权平均)输出,即为池化。从截图中我们可以看到,当我们的滤波器设置成 2x2,每次滑动 2 个像素点时,就可以把 Activation Map 中 4 个区域的最大值输出成为新的 Feature Map,即为最大池化。类似地,平均池化则是求取了均值。
池化的好处有两个:
- 显著缩小了输出矩阵的大小,起到了降维的作用;
- 可以按照需要选择更有代表性的特征,比如最大池化,就可以认为是选择了一定区域内最有代表性的特征,起到了特征选择的作用。
卷积 + 池化的结构成为卷积神经网络的一种常用的搭配,但并非在所有网络中都采用这样的结构,读者在这里需要参考相关论文和著述并结合自身的实际情况进行选择。
下面我们分别介绍卷积神经网络在图像分类和目标检测任务中的应用。
5.3 卷积神经网络的应用
卷积神经网络目前广泛应用于语音、机器视觉及文本处理的算法任务中。这里我们选择机器视觉中常见的分类和目标检测任务,对如何基于 Deeplearning4j 构建 CNN 网络的应用进行详细分析。
5.3.1 图像分类
传统的图像分类往往分为特征提取和分类器构建两个阶段。特征提取常用的算法有 SIFT、SURF、HOG 等。分类器的选择集中在 SVM、基于 Boosting/Bagging 的集成学习算法。在深度学习大规模应用前,类似 SIFT 等设计精良的特征提取方式基本决定了应用的实际效果。但是不可否认的是,现实应用问题往往十分复杂,特征组合的应用非常常见,这不仅增加了工程师的工作量,最重要的是无论如何组合特征实际效果不一定有保证。
卷积神经网络的兴起在一定程度上解决了传统算法的问题。在我们使用卷积神经网络做图像分类时,并不需要设计特征算法,特征的提取和分类已嵌入到了整个神经网络中。事实上这种 end-to-end 的做法对于工程师来讲只需要将图像的原始信号(也就是像素矩阵)输入到模型,输出就是分类结果,至于神经网络在训练过程中提取了什么特征做分类,其实并不完全可见或者可理解(卷积神经网络的可视化分析可以参考:https://cs231n.github.io/understanding-cnn/)。
下面我们使用 Deeplearning4j 对 Fashion-MNIST 数据集进行分类建模。
Fashion-MNIST 数据集(https://github.com/zalandoresearch/fashion-mnist)是类似 MNIST 手写体数字数据集的一组开源的服装数据集。它除了图片内容和 MNIST 不同外,其他诸如标签数量、图片尺寸、训练/测试图片数量,甚至二进制文件名称和 MNIST 均完全一致。以下是 Fashion-MNIST 的部分截图:
我们用类似 LeNet-5 的结构,即两组 Conv+MaxPooling 构建卷积神经网络模型。
public static MultiLayerNetwork getModel(){ MultiLayerConfiguration.Builder builder = new NeuralNetConfiguration.Builder() .seed(12345) .iterations(1) .learningRate(0.01) .learningRateScoreBasedDecayRate(0.5) .weightInit(WeightInit.XAVIER) .optimizationAlgo(OptimizationAlgorithm.STOCHASTIC_GRADIENT_DESCENT) .updater(Updater.ADAM) .list() .layer(0, new ConvolutionLayer.Builder(5, 5) .nIn(1) .stride(1, 1) .nOut(32) .activation(Activation.LEAKYRELU) .build()) .layer(1, new SubsamplingLayer.Builder(SubsamplingLayer.PoolingType.MAX) .kernelSize(2,2) .stride(2,2) .build()) .layer(2, new ConvolutionLayer.Builder(5, 5) .stride(1, 1) .nOut(64) .activation(Activation.LEAKYRELU) .build()) .layer(3, new SubsamplingLayer.Builder(SubsamplingLayer.PoolingType.MAX) .kernelSize(2,2) .stride(2,2) .build()) .layer(4, new DenseLayer.Builder().activation(Activation.LEAKYRELU) .nOut(500).build()) .layer(5, new OutputLayer.Builder(LossFunctions.LossFunction.NEGATIVELOGLIKELIHOOD) .nOut(10) .activation(Activation.SOFTMAX) .build()) .backprop(true).pretrain(false) .setInputType(InputType.convolutionalFlat(28, 28, 1)); MultiLayerConfiguration conf = builder.build(); MultiLayerNetwork model = new MultiLayerNetwork(conf); return model; }我们结合上述逻辑解释下,在 Deeplearning4j 中卷积神经网络的建模过程。
首先我们需要声明一个 MultiLayerConfiguration,即多层网络的配置对象。
注意:Deeplearning4j 同时支持 MultiLayerConfiguration 和 ComputationGraphConfiguration,对于无法清晰划分为多层结构的神经网络,可以考虑使用 ComputationGraphConfiguration。
网络的第一层,是一个卷积层:
.layer(0, new ConvolutionLayer.Builder(5, 5) //卷积核大小 .nIn(1) //输入原始图片的通道数 .stride(1, 1) //步长大小 .nOut(32) //输出 Feature Map 的数量 .activation(Activation.LEAKYRELU) //非线性激活函数 .build())- 由于 Fashion-MNIST 数据集是灰度图,因此通道数为 1。如果是 RGB 彩色图片,则通道数等于 3。
- 卷积核的大小可以通过构造参数传入,也可以用 .kernelSize 来定义。
- 输出的 Feature Map 的数量这里等于 32,这个数量用户可以自定义。
网络的第二层,是一个最大池化层:
.layer(1, new SubsamplingLayer.Builder(SubsamplingLayer.PoolingType.MAX) .kernelSize(2,2) .stride(2,2) .build())- 构建器传入的参数用于定义池化的类型,池化的类型常用的有最大池化、平均池化、求和池化等。这些方式在 Deeplearning4j 都支持。
- kernelSize(2,2) 是卷积核/滤波器的尺寸大小。
- stride(2,2) 和上面卷积层的参数概念一样,是步长。步长越大,输出的 Feature Map 的尺寸也就越小了。
网络的第五层,是一个全连阶层:
.layer(4, new DenseLayer.Builder().activation(Activation.LEAKYRELU) .nOut(500).build())全连接这里的作用是将特征展开成一个 1x500 的向量。注意,输入的维度用户不一定要指定,Deeplearning4j 会根据前几层的网络输出自动计算。
网络的第六层,是一个输出层:
.layer(5, new OutputLayer.Builder(LossFunctions.LossFunction.NEGATIVELOGLIKELIHOOD) .nOut(10) .activation(Activation.SOFTMAX) .build())这一层主要用于定义输出标签的数量、损失函数等信息。由于输出有 10 个分类,我们用 Softmax 作为激活函数,损失函数使用交差熵。到此,一个卷积神经网络就基本定义好了。
接下来,我们需要将数据喂到模型中进行训练。由于 Fashion-MNIST 数据集和手写体 MNIST 数据集在图片属性层面是完全一致的,因此我们可以直接用 Deeplearning4j 内置的工具类 MnistDataSetIterator 进行直接读取。
注意:如果使用该工具类读取 Fashion-MNIST 数据集,需要将 Fashion-MNIST 的二进制数据文件拷贝到当前用户根目录下的 MNIST 目录中,二进制数据文件可以从 GitHub 上下载。
DataSetIterator mnistTrain = new MnistDataSetIterator(batchSize, true, 12345);DataSetIterator mnistTest = new MnistDataSetIterator(batchSize, false, 12345);最后,我们需要编写训练模型的逻辑。这段逻辑和之前文章中提到训练逻辑是一致的。并在训练结束后,在验证集上进行准确率验证以及模型的保存。
for( int i = 0; i < numEpochs; ++i ){ model.fit(mnistTrain);}Evaluation eval = model.evaluate(mnistTest);System.out.println(eval.stats());ModelSerializer.writeModel(model, modelSavePath, true);我们共训练了 100 轮次,最终在验证集上的准确率仅在 90% 左右。

此外,我们顺便给出 Fashion-MNIST 和 MNIST 数据集训练的比较结果。

从这张截图中,我们可以直观地看出,在使用同样网络的情况下,MNIST 数据集在第一轮训练结束后,就可以在验证集上达到 95% 左右的准确率。而反观 Fashion-MNIST 数据集,第一轮训练结束后仅仅达到 80% 左右的准确率,并且在最终的 100 轮训练完后,也只有 90% 的准确性。这说明 Fashion-MNIST 数据集的分类问题相较于 MNIST 而言更为复杂。
对于 Fashion-MNIST 数据集分类的探索,在它的 GitHub 主页上,有基于 CapsuleNet/Inception ResNet 等复杂网络结构下的分类结果,有兴趣的同学可以关注。
5.4 小结
本次课程主要介绍了卷积神经网络的原理,以及其在图像分类中的应用。我们首先回顾了卷积神经网络的历史,然后介绍了卷积神经网络中比较重要的两个概念,卷积 + 池化,随后我们基于 Deeplearning4j 的框架介绍如何构建分类模型。在下一课我们将继续围绕卷积神经网络,介绍基于 YOLO 的图像目标检测应用。
相关资料:
- Standford 机器学习课程中卷积神经网络 Demo
- 卷积神经网络的可视化分析
- Fashion-MNIST 数据集
第01课:开发环境搭建
第02课:开发基本流程
第03课:多层感知机在结构化数据中的应用
第04课:自编码器在数据压缩中的应用
第06课:CNN 在机器视觉中的应用——目标检测
第07课:RNN 在序列问题中的应用——文本分类
第08课:RNN 在序列问题中的应用——文本生成
第09课:RNN 在序列问题中的应用——序列标注
第10课:RNN 在序列问题中的应用——机器翻译
第11课:词句分布式表达——词建模工具
第12课:词句分布式表达——句建模工具
第13课:Spark 分布式模型训练及调优(原理)
第14课:Spark 分布式模型训练及调优(实战)
第15课:多 GPU 环境下的模型训练
第16课:迁移学习的模型训练
第17课:强化学习的模型训练
第18课:搭建在线服务环境
第19课:DL4J 对其他深度学习框架的支持
第20课:DL4J 建模进阶
结语:深度学习的进化
阅读全文: http://gitbook.cn/gitchat/column/5bfb6741ae0e5f436e35cd9f