使用textCNN进行文本分类的原理
CNN在计算机视觉领域取得了很好的结果,同时它可以应用在文本分类上面。
文本分类的关键在于准确提炼文档或者句子的中心思想,而提炼中心思想的方法是抽取文档或句子的关键词作为特征,基于这些特征去训练分类器并分类。因为CNN的卷积和池化过程就是一个抽取特征的过程,当我们可以准确抽取关键词的特征时,就能准确的提炼出文档或句子的中心思想。
卷积神经网络首次应用于文本分类可以说是在2014年Yoon Kim 在 “Convolutional Neural Networks for Sentence Classification” 一文中提出(虽然第一个用的并不是他,但是在这篇文章中提出了4种Model Variations,并有详细的调参),本文也是基于对这篇文章的理解。接下来将介绍text-CNN模型。
text-CNN模型
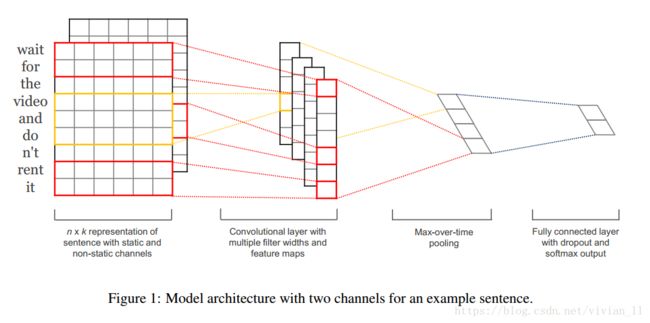
论文使用的模型主要包括五层,第一层是embedding layer,第二层是convolutional layer,第三层是max-pooling layer,第四层是fully connected layer,最后一层是softmax layer.
下图具体展示了如何使用cnn进行句子分类。

输入层
首先输入一个一维的由7个单词构成的句子,为了使其可以进行卷积,首先需要将其转化为二维矩阵表示,通常使用word2vec、glove等word embedding实现。d=5表示每个词转化为5维的向量,矩阵的形状是[sentence_matrix × 5],即[7 × 5]。
卷积层
在处理图像数据时,CNN使用的卷积核的宽度和高度的一样的,但是在text-CNN中,卷积核的宽度是与词向量的维度一致。这是因为我们输入的每一行向量代表一个词,在抽取特征的过程中,词做为文本的最小粒度,如果我们使用卷积核的宽度小于词向量的维度就已经不是以词作为最小粒度了。而高度和CNN一样,可以自行设置(通常取值2,3,4,5)。由于我们的输入是一个句子,句子中相邻的词之间关联性很高,因此,当我们用卷积核进行卷积时,不仅考虑了词义而且考虑了词序及其上下文。(类似于skip-gram和CBOW模型的思想)。
详细讲解卷积的过程:卷积层输入的是一个表示句子的矩阵,维度为n*d,即每句话共有n个词,每个词有一个d维的词向量表示。假设Xi:i+j表示Xi到Xi+j个词,使用一个宽度为d,高度为h的卷积核W与Xi:i+h-1(h个词)进行卷积操作后再使用激活函数激活得到相应的特征ci,则卷积操作可以表示为:(使用点乘来表示卷积操作)

因此经过卷积操作之后,可以得到一个n-h+1维的向量c形如:
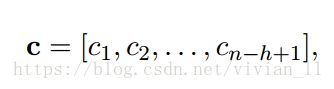
以上是一个卷积核与输入句子的卷积操作,同样的,我们也可以使用更多高度不同的卷积核,且每个高度的卷积核多个,得到更多不同特征。
如上图,这里有(2,3,4)三种size,每种size有两个filter,一共有6个filter。然后开始卷积,从图中可以看出,stride是1,对于高是4的filter,最后生成4维的向量,(7-4)/1+1=4。对于高是3的filter,最后生成5维的向量,(7-3)/1+1=5。
窄卷积 vs 宽卷积
在矩阵的中部使用卷积核滤波没有问题,在矩阵的边缘,如对于左侧和顶部没有相邻元素的元素,该如何滤波呢?解决的办法是采用补零法(zero-padding)。所有落在矩阵范围之外的元素值都默认为0。这样就可以对输入矩阵的每一个元素做滤波了,输出一个同样大小或是更大的矩阵。补零法又被称为是宽卷积,不使用补零的方法则被称为窄卷积。1D的例子如图所示:

滤波器长度为5,输入长度为7。当滤波器长度相对输入向量的长度较大时,你会发现宽卷积很有用,或者说很有必要。在上图中,窄卷积输出的长度是 (7-5)+1=3,宽卷积输出的长度是(7+2*4-5)+1=11。
步长
在文献中我们常常见到的步长是1,但选择更大的步长会让模型更接近于递归神经网络,其结构就像是一棵树。
池化层
池化的特点之一就是它输出一个固定大小的矩阵,还能降低输出结果的维度,(理想情况下)却能保留显著的特征。
因为在卷积层过程中我们使用了不同高度的卷积核,使得我们通过卷积层后得到的向量维度会不一致,所以在池化层中,我们使用1-Max-pooling对每个特征向量池化成一个值,即抽取每个特征向量的最大值表示该特征,而且认为这个最大值表示的是最重要的特征。当我们对所有特征向量进行1-Max-Pooling之后,还需要将每个值给拼接起来。得到池化层最终的特征向量。在池化层到全连接层之前可以加上dropout防止过拟合。
如上图,每个filter最后得到两个特征。将所有特征合并后,使用softmax进行分类。图中没有用到chanel,下文的实验将会使用两个通道,static和non-static,有相关的具体解释。
####NLP中CNN常见的Pooling方法
-
Max Pooling Over Time
MaxPooling Over Time是NLP中CNN模型中最常见的一种下采样操作。意思是对于某个Filter抽取到若干特征值,只取其中得分最大的那个值作为Pooling层保留值,其它特征值全部抛弃,值最大代表只保留这些特征中最强的,而抛弃其它弱的此类特征。

如上文所述,CNN中采用Max Pooling操作有几个好处:首先,这个操作可以保证特征的位置与旋转不变性,对于图像处理来说这种位置与旋转不变性是很好的特性,但是对于NLP来说,这个特性其实并不一定是好事,因为在很多NLP的应用场合,特征的出现位置信息是很重要的,比如主语出现位置一般在句子头,宾语一般出现在句子尾等等,这些位置信息其实有时候对于分类任务来说还是很重要的,但是Max Pooling 基本把这些信息抛掉了。其次,MaxPooling能减少模型参数数量,有利于减少模型过拟合问题。再者,对于NLP任务来说,Max Pooling可以把变长的输入X整理成固定长度的输入。
但是,CNN模型采取MaxPooling Over Time也有一些值得注意的缺点:首先就如上所述,特征的位置信息在这一步骤完全丢失。在卷积层其实是保留了特征的位置信息的,但是通过取唯一的最大值,现在在Pooling层只知道这个最大值是多少,但是其出现位置信息并没有保留;另外一个明显的缺点是:有时候有些强特征会出现多次,比如我们常见的TF.IDF公式,TF就是指某个特征出现的次数,出现次数越多说明这个特征越强,但是因为Max Pooling只保留一个最大值,所以即使某个特征出现多次,现在也只能看到一次,就是说同一特征的强度信息丢失了。这是Max Pooling Over Time典型的两个缺点。 -
K-Max Pooling
K-MaxPooling的意思是:原先的Max Pooling Over Time从Convolution层一系列特征值中只取最强的那个值,那么我们思路可以扩展一下,K-Max Pooling可以取所有特征值中得分在Top –K的值,并保留这些特征值原始的先后顺序(下图是2-max Pooling的示意图),就是说通过多保留一些特征信息供后续阶段使用。

很明显,K-Max Pooling可以表达同一类特征出现多次的情形,即可以表达某类特征的强度;另外,因为这些Top K特征值的相对顺序得以保留,所以应该说其保留了部分位置信息,但是这种位置信息只是特征间的相对顺序,而非绝对位置信息。
3.Chunk-Max Pooling
Chunk-MaxPooling的思想是:把某个Filter对应的Convolution层的所有特征向量进行分段,切割成若干段后,在每个分段里面各自取得一个最大特征值,比如将某个Filter的特征向量切成3个Chunk,那么就在每个Chunk里面取一个最大值,于是获得3个特征值。(如下图所示,不同颜色代表不同分段)

K-Max Pooling是一种全局取Top K特征的操作方式,而Chunk-Max Pooling则是先分段,在分段内包含特征数据里面取最大值,所以其实是一种局部Top K的特征抽取方式。
至于这个Chunk怎么划分,可以有不同的做法,比如可以事先设定好段落个数,这是一种静态划分Chunk的思路;也可以根据输入的不同动态地划分Chunk间的边界位置,可以称之为动态Chunk-Max方法(非正式称谓)。
Chunk-Max Pooling很明显也是保留了多个局部Max特征值的相对顺序信息,尽管并没有保留绝对位置信息,但是因为是先划分Chunk再分别取Max值的,所以保留了比较粗粒度的模糊的位置信息;当然,如果多次出现强特征,则也可以捕获特征强度。
全连接层
全连接层跟其他模型一样,假设有两层全连接层,第一层可以加上relu作为激活函数,对于多分类来说,第二层则使用softmax激活函数得到属于每个类的概率,并选择categorical_crossentropy 作为激活函数。如果处理的数据集为二分类问题,如情感分析的正负面时,第二层也可以使用sigmoid作为激活函数,然后损失函数使用对数损失函数binary_crossentropy。
如上图,激活函数为softmax得到2个类别的概率。
通道
我们需要了解的最后一个概念是通道。通道即是输入数据的不同“视角”。比如说,做图像识别时一般会用到RGB通道(红绿蓝)。你可以对每个通道做卷积运算,赋予相同或不同的权值。你也同样可以把NLP想象成有许多个通道:把不同类的词向量表征(例如word2vec和GloVe)看做是独立的通道,或是把不同语言版本的同一句话看作是一个通道。
在词向量构造方面可以有以下不同的方式:
- CNN-rand: 随机初始化每个单词的词向量通过后续的训练去调整。
- CNN-static: 使用预先训练好的词向量,如word2vec训练出来的词向量,在训练过程中不再调整该词向量。
- CNN-non-static: 使用预先训练好的词向量,并在训练过程进一步进行调整。
- CNN-multichannel: 将static与non-static作为两通道的词向量。
论文中采用了单通道和多通道两种方式。
##总结
搭建一个CNN模型结构需要选择许多个超参数,上文中已经提到了一些:输入表征(word2vec, GloVe, one-hot),卷积滤波器的数量和尺寸,池化策略(最大值、平均值),以及激活函数(ReLU, tanh)。文献Zhang, Y., & Wallace, B. (2015). A Sensitivity Analysis of (and Practitioners’ Guide to) Convolutional Neural Networks for Sentence Classification,通过多次重复实验,比较了不同超参数对CNN模型结构在性能和稳定性方面的影响。如果你想自己实现一个CNN用于文本分类,可以借鉴该论文的结果。其主要的结论有最大池化效果总是好于平均池化;选择理想的滤波器尺寸很重要,但也根据任务而定需;正则化在NLP任务中的作用并不明显。需要注意的一点是该研究所用文本集里的文本长度都相近,因此若是要处理不同长度的文本,上述结论可能不具有指导意义。
参考:
论文《Convolutional Neural Networks for Sentence Classification》
使用Keras进行深度学习:(三)使用text-CNN处理自然语言(下)(论文的解读和Keras实现,非常有用)
基于tensorflow的cnn文本分类(论文解读和tensorflow实现)
Understanding Convolutional Neural Networks for NLP(详细解读,非常有用)
卷积神经网络在自然语言处理的应用(上文的翻译)
自然语言处理中CNN模型几种常见的Max Pooling操作(详细)