展望2018音视频技术:AV1,AI,区块链,WebRTC

编者按:音视频技术的历史可能要追溯到19世纪末——特斯拉与爱迪生的伟大时代。直到今天,他们的发明依然伴随我们生活的每时每刻。2018年音视频技术将有哪些突破?来自学霸君的资深架构师袁荣喜从编解码器、客户端、传输网络、动态缓冲区以及媒体处理技术几个方面解析实时音视频技术。展望2018,区块链、AI、WebRTC、AV1将成为关键词。
本文由LiveVideoStack与《程序员》杂志联合策划,并将在《程序员》杂志2018年1月刊发布。最后,感谢《程序员》杂志主编卢鸫翔的建议与高效配合。
文 / 袁荣喜
策划 / LiveVideoStack,《程序员》杂志
责编 / 卢鸫翔
实时音视频技术是源于早期的VoIP通信,随着后来互联网的发展进程,这项技术2003年被Skype引入到PC桌面系统,开启了整个实时音视频技术新纪元。经过15年的进化,基于PC上的实时音视频技术日渐成熟,也涌现了像WebRTC这样的开源项目。但随着近几年移动互联网和4G的兴起,实时音视频领域有了更广泛的应用,引来了新的技术难题和挑战。经过2016年直播大战后,音视频应用得到了用户的认可,直接促成了2017年实时音视频应用的大爆发,在娱乐方面出现了像狼人杀、陌生人视频社交、在线抓娃娃等风口;在协作应用领域出现了Slack和Zoom等多人远程协作应用;在行业应用上也有很大的突破,例如像VIPKID、学霸君1V1等强劲的在线教育产品。在苹果8月份宣布新一代iOS浏览器Safari支持WebRTC后,实时音视频技术成为了时下热门技术体系。
但实时音视频相关技术门槛非常高,很多细节并不为人所知,其中涉及到平台硬件、编解码、网络传输、服务并发、数字信号处理、在线学习等。虽然技术体系繁多,但总体上归纳两类:1对1模式和会议模式。我从这两个分类对实时音视频相关技术做简单介绍,主要有以下几方面:
编解码器
客户端上传
实时传输网络
动态缓冲区
媒体处理技术
编解码器
谈到视频编码器,就会想到MPEG4、H.264、H.265、WMA等等,但不是所有的视频编码器都可以用来作为实时视频的编码器,因为实时视频编码器需要考虑两个因素:编码计算量和码率带宽,实时视频会运行在移动端上,需要保证实时性就需要编码足够快,码率尽量小。基于这个原因现阶段一般认为H.264是最佳的实时视频编码器,而且各个移动平台也支持它的硬编码技术。
H.264/ AVC
H.264是由ITU和MPEG两个组织共同提出的标准,整个编码器包括帧内预测编码、帧间预测编码、运动估计、熵编码等过程,支持分层编码技术(SVC)。单帧720P分辨率一般PC上的平均编码延迟10毫秒左右,码率范围1200 ~ 2400kpbs,同等视频质量压缩率是MPEG4的2倍,H.264也提供VBR、ABR、CBR、CQ等多种编码模式,各个移动平台兼容性好。
VP8/VP9
除H.264以外,适合用于实时视频的编码器还有Google提供的VP8,VP8采用了H.264相似的编码技术,计算复杂度和H.264相当,不支持SVC,相同视频质量的压缩率比H.264要小一点,不支持B帧。而后Google又在VP8的基础上研发了VP9,官方号称VP9在相同视频质量下压缩率是VP8的2倍,对标的对手是H.265,VP9已经嵌入到WebRTC当中,但VP9编码时CPU计算量比较大,对于VP9用于实时视频我个人持保留意见。不管是VP8还是VP9硬编方式只有Android支持,iOS和其他的移动平台并不支持。
音频编码器
实时音视频除了视频编码器以外还需要音频编码器,音频编码器只需要考虑编码延迟和丢包容忍度,所以一般的MP3、AAC、OGG都不太适合作为实时音频编码器。从现在市场上来使用来看, Skype研发的Opus已经成为实时音频主流的编码器。Opus优点众多,编码计算量小、编码延迟20ms、窄带编码-silk、宽带编码器CELT、自带网络自适应编码等。
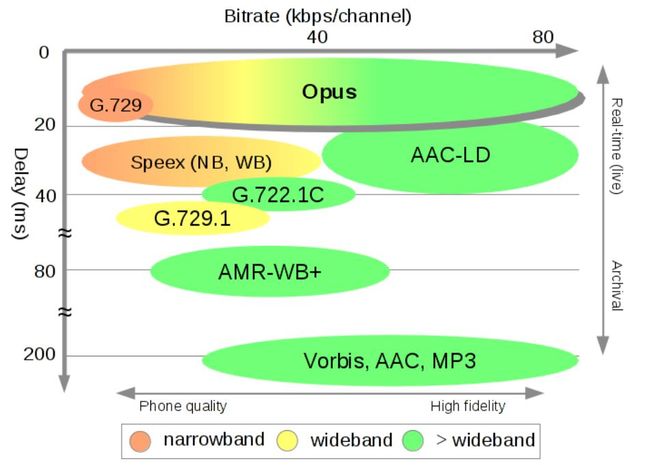
图1:语音编码器编码延迟与码率对比
客户端推流
实时音视频系统都是一个客户端到其他一个或者多个客户端的通信行为,这就意味着需要将客户端编码后的音视频数据传输到其他客户端上,一般做法是先将数据实时上传到服务器上,服务器再进行转发到其他客户端,客户端这个上传音视频数据行为称为推流。这个过程会受到客户端网络的影响,例如:Wi-Fi信号衰减、4G弱网、拥挤的宽带网络等。为了应对这个问题,实时音视频系统会设计一个基于拥塞控制和QoS策略的推流模块。
拥塞控制
因为客户端有可能在弱网环境下进行推流,音视频数据如果某一时刻发多了,就会引起网络拥塞或者延迟,如果发少了,可能视频的清晰不好。在实时音视频传输过程会设计一个自动适应本地网络变化的拥塞控制算法,像QUIC中的BBR、WebRTC中GCC和通用的RUDP。思路是通过UDP协议反馈的丢包和网络延迟(RTT)来计算当前网络的变化和最大瞬时吞吐量,根据这几个值调整上层的视频编码器的码率、视频分辨率等,从而达到适应当前网络状态的目的。
QoS策略
客户端推流除了需要考虑网络上传能力以外,还需要考虑客户端的计算能力。如果在5年前的安卓机上去编码一个分辨率为640P的高清视频流,那这个过程必然会产生延迟甚至无法工作。为此需要针对各个终端的计算能力设计一个QoS策略,不同计算能力的终端采用不同的视频编码器、分辨率、音频处理算法等,这个QoS策略会配合拥塞控制做一个状态不可逆的查找过程,直到找到最合适的QoS策略位置,图2是一个实时音频的QoS策略迁移过程实例。
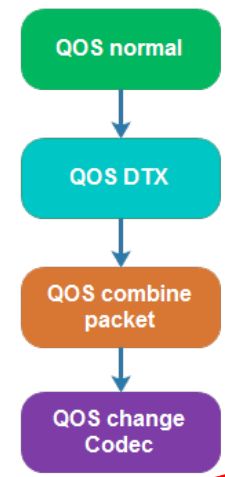
图2:实时语音的QoS状态迁移
传输路径技术
在前面我们对实时音视频归纳为:1V1模式和1对多模式,这两种模式其实传输路径设计是不一样的。1V1模式主要是怎么通过路由路径优化手段达到两点之间最优,这方面Skype首先提出基于P2P的Real-time Network模型。而1对多模式是一个分发树模型,各个客户端节点需要就近接入离自己最近的server服务器,然后在server与server构建一个实时通信网络。
P2P前向收敛技术
对于1V1模式的实时音视频通信,很多时候我们以为两点之间直连是延迟最小质量最好的通信链路,其实不是。整个骨干网的结构并不是网状,而是树状的,这个从同城网通电信之间互联的质量可以得出结论,如果涉及到国际之间互联更是复杂无比。一个好的1V1实时音视频系统会设计一个对等多点智能路由的传输算法,就是通过多节点之间的动态计算延迟、丢包等网络状态来进行路径选择,这是个下一跳原则的选择算法,只要保证每个节点自己发送包的下一跳的延迟和丢包最小,那么整个传输路径就是最小最优,一般TTL小于4。寻找下一跳的过程是一个P2P节点前向收敛技术,它需要一个函数f(x)来做收敛。图3是一个传统1V1和基于P2P relay的1V1对比示意图。
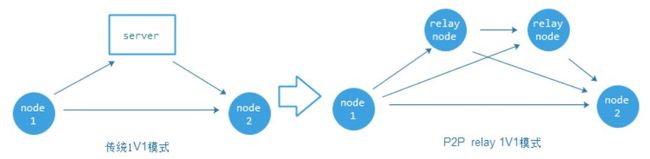
图3:P2P多路径传输示意图
proxy传输技术
对于1对多模式的实时音视频通信,需要一个中心server来控制状态和分发流数据,但参与通信的节点不都是对中心server网络友好,有可能某些节点连不上中心server或者丢包延迟很大,无法达到实时通信目标需求。所以一般会引入就近proxy机制来优化传输网络,客户端节点通过连接距离最近的proxy到中心server。这种方式不仅仅可以优化网络,还可以起到保护中心server的作用。
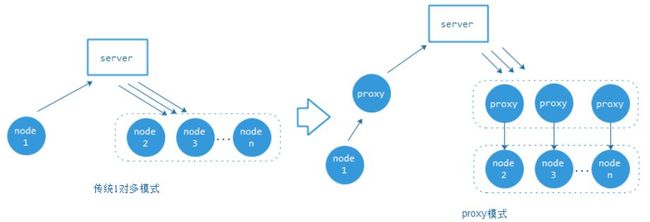
图4:proxy传输模式示意图
分段计算
不管是P2P relay模式的1v1,还是就近proxy的1V多模式,在数据传输过程会做各种传输补偿来应对丢包,例如:FEC、ARQ等,如果进行ARQ还需要对重传的数据做临时保存。这里遵循的是分段计算的原则,这个原则大致是:每一段网络上一跳节点必须独立计算到下一跳节点之间的丢包、延迟,并将接收到数据cache在内存中,根据这段网络的状态启用对应的FEC、ARQ和路由选择策略,不影响其他分段传输策略。
图5:分段计算与网络节点示意图
WebRTC网关
在实时音视频系统中需要在Web上进行实时通信,各个浏览器都已支持WebRTC,所以WebRTC是Web上实时音视频通信的首选。但WebRTC是基于浏览器的客户端点对点系统,并没有定义多路通信标准和服务中转标准,不管是1V1模式还是1对多模式,需要引入WebRTC网关来接入自定义的实时系统。网关负责将WebRTC的SDP、ICE、STUN/TURN、RTP/RTCP翻译成自定义系统中的对应协议消息,实现无缝对接WebRTC。WebRTC很多类似的开源网关,例如:licode、janus等。
动态缓冲区
在实时视频的播放端会有一个自动动态伸缩的JitterBuffer来缓冲网络上来的媒体数据,为什么要这个JitterBuffer呢?因为TCP/IP网络是一个不可靠的传输网络,音视频数据经IP网络传输时会产生延迟、丢包、抖动和乱序,JitterBuffer可以通过缓冲延迟播放来解决抖动乱序的问题。但JitterBuffer如果缓冲时间太长,会引起不必要的延迟,如果缓冲时间太短,容易引起音视频卡顿和抖动。所以JitterBuffer在工作的时候会根据网络报文的抖动时间最大方差来动态确定缓冲时间,这样能在延迟和流畅性之间取得一个平衡。
JitterBuffer除了缓冲解决抖动和乱序的问题以外,为了延迟和流畅性之间的制约关系,它还需要实现快播和慢播技术,当JitterBuffer中数据时间长度小于确定的抖动时间,需要进行慢播,让抖动缓冲区数据时间和抖动时间齐平,防止卡顿,当JitterBuffer中的数据时间长度大于确定的抖动时间,需要进行快播,接近抖动时间,防止累计延迟。
媒体处理
回声消除
在实时音视频系统中,回声消除是一个难点,尽管WebRTC提供了开源的回声消除模块,但在移动端和一些特殊的场景表现不佳。专业的实时音视频系统会进行回声消除的优化。回声消除的原理描述很简单,就是将扬声器播放的声音波形和麦克风录制的波形进行抵消,达到消除回声的作用。因为回声的回录时间不确定,所以很难确定什么时间点进行对应声音数据的抵消。在专业的回声消除模块里面通常会设计一个逼近函数,通过不断对输出和输入声音波形进行在线学习逼近,确定回声消除的时间差值点。如图6所示。
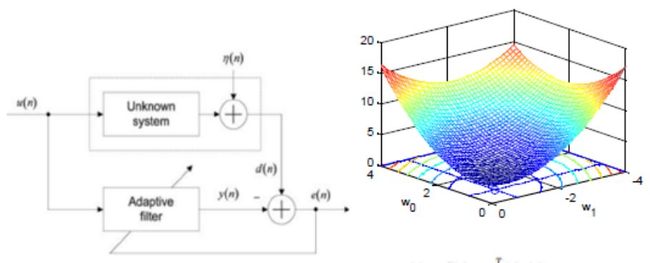
图6:回声消除模型与逼近函数
回声消除整个过程对CPU计算有一定的要求,尤其是在移动端设备上,所以在设计回声消除模块的时候会将回声消除算法设置几个计算等级,不同的等级不同的CPU计算量,根据执行设备的性能来做策略调节。
人脸与AI
直播时代人脸美颜和特效已经不再是稀奇的功能了,这得益于AI深度学习和神经网络的发展。值得一提的是,已经有通过对抗神经网络进行人脸替换的技术,这个技术是通过CycleGAN算法模型将视频中每个像素替换成目标像素,以此来达到偷梁换柱的目的。未来一个普通主播替换成明星脸的现象会越来越多。
总结与思考
实时音视频领域涉及的技术众多,有控制网络延迟的,有抗丢包的,有用于增强流畅度的,有用于减少成本的。这其中还有很多悬而未决的问题,例如跨国零延迟实时传输、大规模实时分发、超高清实时、实时VR/AR等。这个领域的技术还在不断发展,随着硬件和算法的不断升级,这些问题正在逐步被解决。在这里简单对未来这方面技术做个展望。
2017年的新一代iPhone上已经嵌入了H.265的硬编模块,接下来很多手机厂商都会植入H.265的硬编模块来提高手机的竞争力。这一局面将加快H.265在实时音视频的应用。除了H.265外,Google联合各个浏览器厂商正在加紧研发AV1新一代互联网视频编码器,预计在2018年放出alpha版测试,AV1在专利费和浏览器兼容上有很大的优势,这是个非常值得期待的事。
在实时音视频传输方面也正在与当下流行的AI和深度学习结合,基于机器学习的拥塞控制算法已经在实验阶段,基于大数据和神经网络的实时传输链路优化也在各大云厂商中开展,我个人看好利用AI和深度学习技术来进行网络调优、传输路径优化和时延控制,这块在未来几年会有相对应的突破。而与区块链的结合可能更多是基于成本上的考虑,例如迅雷的玩客币、赚钱宝等,这类技术方向会催生出新一代的CDN实时分发网络。
行业应用上,在线教育会继续在师生注意力、教育效果上对实时音视频上做深挖,很有可能会引入实时AR/VR来增强用户体验和认知感觉。实时音视频正在成为计算机视觉的下一个发展方向,会持续输出到IoT、毫秒级实时视频监控等行业领域。
关于作者
袁荣喜,学霸君资深架构师,16年的C程序员,好求甚解,善于构建高性能服务系统和系统性能调优,喜好解决系统的疑难杂症和debug技术。早年痴迷于P2P通信网络、TCP/IP通信协议栈和鉴权加密技术,曾基于P2P super node技术实现了视频实时传输系统。2015年加入学霸君,负责构建学霸君的智能路由实时音视频传输系统和网络,解决音视频通信的实时性的问题。 近几年专注于存储系统和并发编程,对paxos和raft分布式协议饶有兴趣。尤其喜欢数据库内核和存储引擎,坚持不懈对MySQL/innoDB和WiredTiger的实现和事务处理模型进行探究。热衷于开源,曾为开源社区提过些patch。业余时间喜欢写技术长文,喜欢读唐诗。
LiveVideoStack招募全职技术编辑和社区编辑
LiveVideoStack是专注在音视频、多媒体开发的技术社区,通过传播最新技术探索与应用实践,帮助技术人员成长,解决企业应用场景中的技术难题。如果你有意为音视频、多媒体开发领域发展做出贡献,欢迎成为LiveVideoStack社区编辑的一员。你可以翻译、投稿、采访、提供内容线索等。
通过[email protected]联系,或在LiveVideoStack公众号回复『技术编辑』或『社区编辑』了解详情。